 大模型现存的10个问题和挑战
大模型现存的10个问题和挑战
大模型现存的问题和挑战这篇文章介绍了关于大型语言模型(LLMs)研究中的十个主要方向和问题:
1. 减少和度量幻觉:幻觉指的是AI模型虚构信息的情况,可能是创意应用的一个特点,但在其他应用中可能是一个问题。这个方向涉及减少幻觉和开发衡量幻觉的度量标准。
2. 优化上下文长度和构造:针对大多数问题,上下文信息是必需的,文章介绍了在RAG(Retrieval Augmented Generation)架构中优化上下文长度和构造的重要性。
3. 整合其他数据形式:多模态是强大且被低估的领域,文章探讨了多模态数据的重要性和潜在应用,如医疗预测、产品元数据分析等。
4. 使LLMs更快、更便宜:讨论了如何使LLMs更高效、更节约资源,例如通过模型量化、模型压缩等方法。
5. 设计新的模型架构:介绍了开发新的模型架构以取代Transformer的尝试,以及挑战和优势。
6. 开发GPU替代方案:讨论了针对深度学习的新硬件技术,如TPUs、IPUs、量子计算、光子芯片等。
7. 使代理人更易用:探讨了训练能够执行动作的LLMs,即代理人,以及其在社会研究和其他领域的应用。
8. 提高从人类偏好中学习的效率:讨论了从人类偏好中训练LLMs的方法和挑战。
9. 改进聊天界面的效率:讨论了聊天界面在任务处理中的适用性和改进方法,包括多消息、多模态输入、引入生成AI等。
10. 为非英语语言构建LLMs:介绍了将LLMs扩展到非英语语言的挑战和必要性。
1. 减少和衡量幻觉
幻觉是一个广受关注的话题,指的是当AI模型编造信息时发生的情况。在许多创造性的应用场景中,幻觉是一种特性。然而,在大多数其他用例中,幻觉是一个缺陷。一些大型企业近期在关于大型语言模型的面板上表示,影响企业采用LLMs的主要障碍是幻觉问题。
减轻幻觉问题并开发用于衡量幻觉的度量标准是一个蓬勃发展的研究课题。有许多初创公司专注于解决这个问题。还有一些降低幻觉的方法,例如在提示中添加更多的上下文、思维链、自我一致性,或要求模型在回答中保持简洁。
要了解更多关于幻觉的信息,可以参考以下文献:
- Survey of Hallucination in Natural Language Generation (Ji et al., 2022)
- How Language Model Hallucinations Can Snowball (Zhang et al., 2023)
- A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity (Bang et al., 2023)
- Contrastive Learning Reduces Hallucination in Conversations (Sun et al., 2022)
- Self-Consistency Improves Chain of Thought Reasoning in Language Models (Wang et al., 2022)
- SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (Manakul et al., 2023)
- NVIDIA’s NeMo-Guardrails中关于事实核查和幻觉的简单示例
2. 优化上下文长度限制
大部分问题需要上下文信息。例如,如果我们询问ChatGPT:“哪家越南餐厅最好?”,所需的上下文将是“在哪里”,因为越南在越南和美国的最佳越南餐厅不同。
在这篇论文中提到,许多信息寻求性的问题都有依赖于上下文的答案,例如Natural Questions NQ-Open数据集中约占16.5%。对于企业用例,这个比例可能会更高。例如,如果一家公司为客户支持构建了一个聊天机器人,为了回答客户关于任何产品的问题,所需的上下文可能是该客户的历史或该产品的信息。由于模型“学习”来自提供给它的上下文,这个过程也被称为上下文学习。
3. 合并其他数据模态
多模态是非常强大但常常被低估的概念。它具有许多优点:
首先,许多用例需要多模态数据,特别是在涉及多种数据模态的行业,如医疗保健、机器人、电子商务、零售、游戏、娱乐等。例如,医学预测常常需要文本(如医生的笔记、患者的问卷)和图像(如CT、X射线、MRI扫描)。
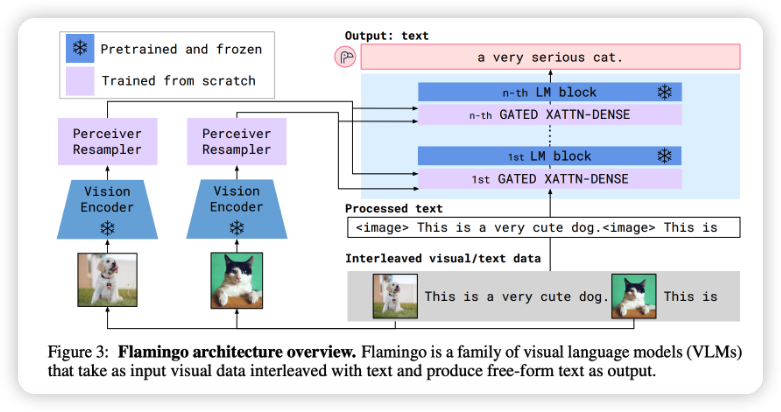
其次,多模态承诺可以显著提高模型的性能。一个能够理解文本和图像的模型应该比只能理解文本的模型表现更好。基于文本的模型需要大量的文本数据,因此有现实担忧称我们可能会很快用完训练基于文本的模型的互联网数据。一旦我们用完了文本数据,我们需要利用其他数据模态。
其中一个特别令人兴奋的用例是,多模态可以帮助视障人士浏览互联网和导航现实世界。
4. 使LLMs更快且更便宜
当GPT-3.5于2022年底首次发布时,很多人对在生产中使用它的延迟和成本表示担忧。这是一个复杂的问题,牵涉到多个层面,例如:
训练成本:训练LLMs的成本随着模型规模的增大而增加。目前,训练一个大型的LLM可能需要数百万美元。
推理成本:在生产中使用LLMs的推理(生成)可能会带来相当高的成本,这主要是因为这些模型的巨大规模。
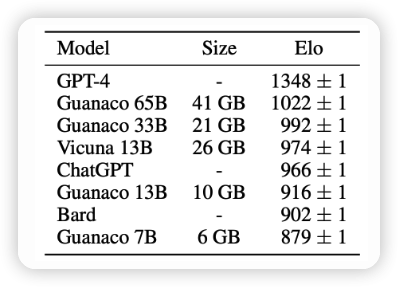
解决这个问题的一种方法是研究如何减少LLMs的大小,而不会明显降低性能。这是一个双重的优势:首先,更小的模型需要更少的成本来进行推理;其次,更小的模型也需要更少的计算资源来进行训练。这可以通过模型压缩(例如蒸馏)或者采用更轻量级的架构来实现。
5. 设计新的模型架构
尽管Transformer架构在自然语言处理领域取得了巨大成功,但它并不是唯一的选择。近年来,研究人员一直在探索新的模型架构,试图超越Transformer的限制。
这包括设计更适用于特定任务或问题的模型,以及从根本上重新考虑自然语言处理的基本原理。一些方向包括使用图神经网络、因果推理架构、迭代计算模型等等。
新的架构可能会在性能、训练效率、推理速度等方面带来改进,但也需要更多的研究和实验来验证其实际效果。
6. 开发GPU替代方案
当前,大多数深度学习任务使用GPU来进行训练和推理。然而,随着模型规模的不断增大,GPU可能会遇到性能瓶颈,也可能无法满足能效方面的要求。
因此,研究人员正在探索各种GPU替代方案,例如:
TPUs(张量处理器):由Google开发的专用深度学习硬件,专为加速TensorFlow等深度学习框架而设计。
IPUs(智能处理器):由Graphcore开发的硬件,旨在提供高度并行的计算能力以加速深度学习模型。
量子计算:尽管仍处于实验阶段,但量子计算可能在未来成为处理复杂计算任务的一种有效方法。
光子芯片:使用光学技术进行计算,可能在某些情况下提供更高的计算速度。
这些替代方案都有其独特的优势和挑战,需要进一步的研究和发展才能实现广泛应用。
7. 使代理人更易于使用
研究人员正在努力开发能够执行动作的LLMs,也被称为代理人。代理人可以通过自然语言指令进行操作,这在社会研究、可交互应用等领域具有巨大潜力。
然而,使代理人更易于使用涉及到许多挑战。这包括:
指令理解和执行:确保代理人能够准确理解和执行用户的指令,避免误解和错误。
多模态交互:使代理人能够在不同的输入模态(文本、语音、图像等)下进行交互。
个性化和用户适应:使代理人能够根据用户的个性、偏好和历史进行适应和个性化的交互。
这个方向的研究不仅涉及到自然语言处理,还涉及到机器人学、人机交互等多个领域。
8. 提高从人类偏好中学习的效率
从人类偏好中学习是一种训练LLMs的方法,其中模型会根据人类专家或用户提供的偏好进行学习。然而,这个过程可能会面临一些挑战,例如:
数据采集成本:从人类偏好中学习需要大量的人类专家或用户提供的标注数据,这可能会非常昂贵和耗时。
标注噪声:由于人类标注的主观性和误差,数据中可能存在噪声,这可能会影响模型的性能。
领域特异性:从人类偏好中学习的模型可能会在不同领域之间表现不佳,因为偏好可能因领域而异。
研究人员正在探索如何在从人类偏好中学习时提高效率和性能,例如使用主动学习、迁移学习、半监督学习等方法。
9. 改进聊天界面的效率
聊天界面是LLMs与用户交互的方式之一,但目前仍然存在一些效率和可用性方面的问题。例如:
多消息对话:在多轮对话中,模型可能会遗忘之前的上下文,导致交流不连贯。
多模态输入:用户可能会在消息中混合文本、图像、声音等不同模态的信息,模型需要适应处理这些多样的输入。
对话历史和上下文管理:在长时间对话中,模型需要有效地管理对话历史和上下文,以便准确回应用户的问题和指令。
改进聊天界面的效率和用户体验是一个重要的研究方向,涉及到自然语言处理、人机交互和设计等多个领域的知识。
-
AI
+关注
关注
87文章
30805浏览量
268952 -
人工智能
+关注
关注
1791文章
47229浏览量
238345 -
模型
+关注
关注
1文章
3233浏览量
48821
发布评论请先 登录
相关推荐
【「大模型启示录」阅读体验】对大模型更深入的认知

国产大模型发展的经验与教训

当前主流的大模型对于底层推理芯片提出了哪些挑战

在PyTorch中搭建一个最简单的模型
AI大模型的发展历程和应用前景

助听器降噪神经网络模型
【大语言模型:原理与工程实践】大语言模型的应用
【大语言模型:原理与工程实践】大语言模型的评测
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》

大模型时代,国产GPU面临哪些挑战






 工商网监
工商网监
评论