 基于单张RGB图像定位被遮挡行人设计案例
基于单张RGB图像定位被遮挡行人设计案例
摘要
基于单张RGB图像在3D场景空间中定位行人对于各种下游应用至关重要。目前的单目定位方法要么利用行人的包围盒,要么利用他们身体的可见部分进行定位。这两种方法在现实场景中都引入了额外的误差—拥挤的环境中有多个行人被遮挡。为了克服这一局限性,本文提出了一种新颖的人体姿态感知行人定位框架来模拟被遮挡行人的姿态,从而实现在图像和地面空间中的精确定位。这是通过提出一个轻量级的神经网络架构来完成的,确保了快速和准确的预测缺失的身体部分的下游应用。在两个真实世界的数据集上进行的综合实验证明了该框架在预测行人丢失身体部位以及行人定位方面的有效性。
引言
为了缓解以往研究的局限性,本研究的目的是:
(1)从可见身体部位的位置有效地估计出被遮挡的身体部位;
(2)使用该估计器准确地定位地面上被遮挡的行人。为此,受最近关于姿态估和单目行人定位的研究启发,本文提出了一种新颖的人体姿态感知行人定位框架。
首先提出了一种在图像空间中模拟被遮挡行人姿态的方法。这是通过基于他们其他可见的身体部位或关节(如鼻子、肩膀、手腕或膝盖)来估计他们身体缺失部分在图像中的位置来完成的。为此,我们提出了一个轻量级的前馈神经网络,并在Microsoft COCO中对被检测行人的身体结构关键点进行训练,这是行人检测中广泛使用的开放基准数据集。受martinez等人(2017)启发,脚部预测器的轻量化结构使该框架能够准确有效地估计地面上行人的位置。为了估计行人可见关节,我们使用了OpenPifPaf (Kreiss等人,2019年),一种最先进的人体姿势检测器。这为我们提供了图像空间中行人姿态的抽象表现。然后,对足部位置应用单应性变换,将坐标从图像平面转换到地平面。
在两个真实世界的数据集上进行的实证明了本文提出的方法在估计行人在图像空间中的位置方面的有效性。我们的评估还表明,与目前最先进的方法相比,本文提出的方法在定位精度方面提高了60%以上。提出的框架是作为一种实用的解决方案,以在常见安装场景的监控摄像头中准确地定位行人。然而,正如KITTI数据集所示,它也可以应用于其他相机设置,如自动驾驶汽车中估算单应性变换的实用解决方案。
综上所述,本文的贡献如下:
(1)提出了一种基于其他可见部位的方法来估计被遮挡的身体部位(如脚)的位置。
(2)使用真实世界的数据进行了一系列全面的实验,并证明我们提出的框架可以准确地估计脚的位置,并在定位精度方面优于之前的方法。
方法
本研究旨在利用人体结构,改进基于单一图像的步行者定位方法。这是通过预测行人丢失的身体部位来实现的。为了实现这一目标,本文提出了一个包括三个主要步骤的框架。如下图所示,首先使用最先进的姿态检测方法检测图像中的行人可见的身体部位和关节。然后对于每一个被检测到的行人,我们从可见部分识别并预测他们的脚的位置,从而实现准确定位。最后应用单应性变换来估计被测足的地平面坐标。这些步骤在这个阶段是分开的,但是它们有可能形成一个端到端系统。
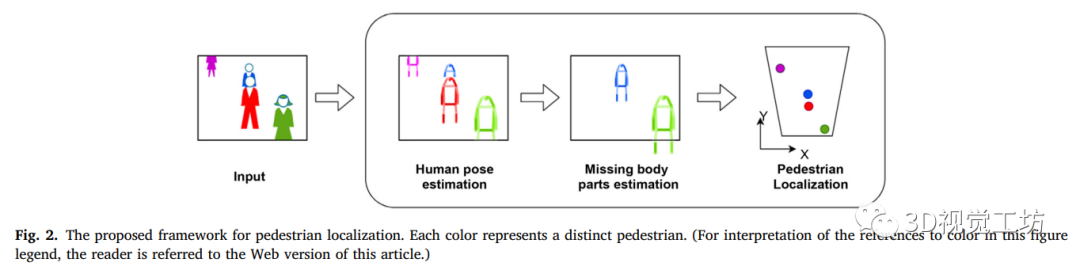
接下来详细介绍了该框架的三个步骤。
1、行人姿态估计
本文采用了一种名为OpenPifPaf (Kreiss et al.,2019)的最先进的姿势检测器来检测行人,并在图像空间中找到他们对应的身体部位和关节。让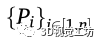 表示为图像空间中被检测到的行人的集合。这里,n表示图像中检测到的人类总数。每一个
表示为图像空间中被检测到的行人的集合。这里,n表示图像中检测到的人类总数。每一个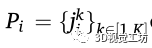 表示身体特定部位或关节在图像空间中的位置。这里K表示姿势检测器可以识别的身体部位和关节的数量——在OpenPifPaf的情况下,最多可以识别17个关节。采用姿势检测器的优点是,它通过将脚的位置投射到地平面上,从而便于精确定位。
表示身体特定部位或关节在图像空间中的位置。这里K表示姿势检测器可以识别的身体部位和关节的数量——在OpenPifPaf的情况下,最多可以识别17个关节。采用姿势检测器的优点是,它通过将脚的位置投射到地平面上,从而便于精确定位。
为了准确估计行人的位置,我们认为在定位时应考虑行人的脚位置。这是因为在一般情况下,相机可能对现场有一个倾斜的透视视角,考虑到bertoni等人(2019)提出的行人身体的中心点,将会给他们在地面上的估计位置增加一个显著的误差。此外,遮挡导致关节可能丢失。为了克服这一挑战,我们建议从检测到的关节中估计缺失的位置。
2、估计缺失的身体部位
本文方法可以基于行人在图像空间中的其他可见身体部位,有效地预测行人缺失关节的位置。这种方法可以帮助我们解决基于包围盒的定位方法对行人遮挡的局限性,通过可见的关节来估计遮挡的身体部位。该网络能够学习和预测身体各部位之间的协同模式,以及不同关节或身体各部位之间的距离。
下图显示了所提议的解决方案的总体流程。该网络以人体可用部位的位置向量作为输入,并估计缺失部位的位置。为了训练网络,我们提供一套完整的关节,让网络学习不同身体部位的相对位置。该网络架构受到martinez等人(2017)的启发,因为提出的架构受益于深度学习领域的各种改进,同时它仍然保持简单和轻量级,以确保对下游应用的快速响应。我们进行了消融研究,以发现适合我们应用的最佳网络架构。在消融研究的基础上,提出了一个具有两个线性层和2048输出特征的深度前馈神经网络。我们还在每个全连接层后采用了退出(Srivastava等人,2014年)和批处理标准化(Ioffe和Szegedy, 2015年),以防止过拟合。为了给我们的适应网络添加非线性,我们使用矫正线性单元(ReLus) (Nair和Hinton, 2010)作为神经网络中最常用的激活函数。
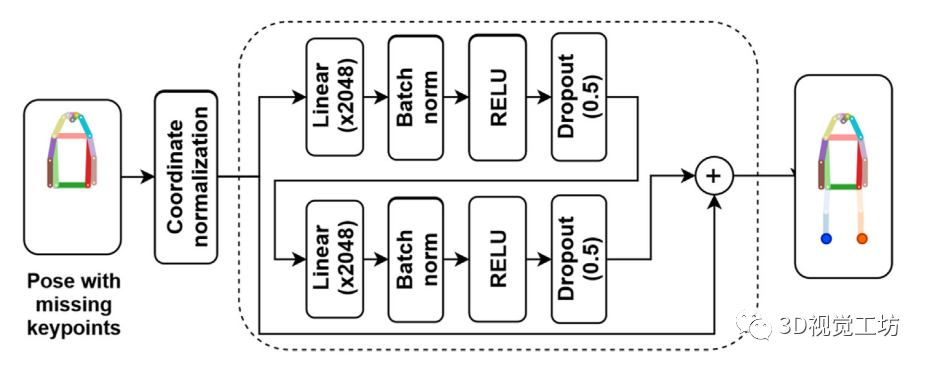
为了在拥挤环境中实现单目行人定位,我们使用该模型来预测行人的脚的位置。在COCO数据集上训练和评估模,首先选择数据集中现有脚位置的那些检测到的行人。接下来,我们开发了一种数据增强技术,并应用于模拟现实场景,在这种场景中,摄像机对身体不同部位和关节的视角可能会被周围的行人或物体遮挡。因此,我们随机生成不同的行人解剖关键点组合,并将其增加到原始数据集,以丰富训练,并使网络适应真实的遮挡场景。通过这种方式,在保留实例的解剖约束的同时,我们设法模拟在真实场景中发生的不同类型的遮挡。然后将所有检测到的行人的边界框左上角移动到图像坐标的原点,对关键点坐标进行归一化,以标准化预测。
作为损失函数,我们利用常用的二范数来学习行人脚在图像空间中的坐标,从而最小化位置估计误差。给定一组已知的非脚的关键点,如鼻子、左肩或右手腕,以及它们相应的左、右脚踝关键点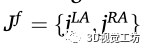 ,表示损失函数为:
,表示损失函数为:
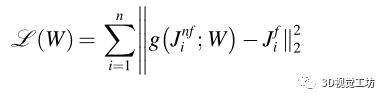
其中,w为网络的导出权值,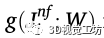 为模型估计的行人i在图像空间中的脚位置,n是图像中检测到的行人数量。
为模型估计的行人i在图像空间中的脚位置,n是图像中检测到的行人数量。
3、地面位置估计
在第三阶段,我们对估计的足部位置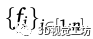 应用单应变换以确定地面空间坐标
应用单应变换以确定地面空间坐标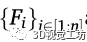 :
:
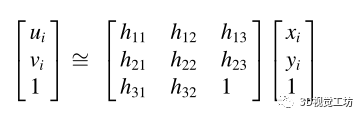
在这里,ui和vi反映了行人i在图像空间中的位置,xi和yi代表了相应的地面二维坐标。单应矩阵的8个未知参数,可以使用一组在图像空间和地面空间中手工测量的特征点来估计。
然后将最小二乘模型应用于投影空间中相应的线性方程组,确定估计的单应性变换参数。求解齐次线性投影至少需要四个控制点。最后,给定一个行人的每个脚的位置,即可以在地面空间估计相应的坐标。
实验
为了准确估计行人丢失的身体部位,我们在2017年COCO训练数据集(Lin et al.,2014)上训练我们提出的网络。此外,在SCS和KITTI两个数据集上对所提出的框架进行评估。
在这项工作中,我们将提出的框架与Monoloco方法和几何基线方法进行了比较。为了评估模块的性能,使用了两个常用的评估指标,即均方根误差(RMSE)和平均绝对误差(MAE)。
下图显示了KITTI数据集上被遮挡行人的预测脚位置的三个例子。如图所示,我们提出的网络可以有效地预测图像空间中被遮挡的行人脚的位置(绿圈)。同时,可以看到,在遮挡行人的情况下,包围框的底部中心点(黄圈)是完全偏离的。

此外,我们研究了估计行人缺失部分位置的误差分布,这里称为位置估计误差。如下图(a)所示,在图像空间中,距离摄像机较近的行人的位置估计误差明显高于距离平台较远的其他行人。这可能是由于相机角度的影响,接近相机的行人看起来更大但更短,这使得估计脚的位置不太准确。
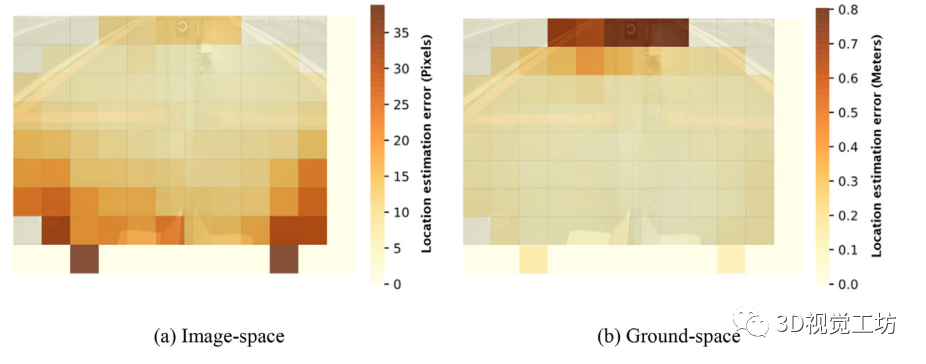
此外,利用单应性变换将误差投影到地面,在真实尺度上检测定位误差。从上图(b)可以看出,虽然图像空间的误差较大,但距离摄像机更近的行人相对于距离更远的行人,其位置估计误差较小,在图像最远的部分,误差可达1 m。这是由于倾斜图像的尺度变化,图像的尺度在上部较小,导致定位误差在图像空间中投影到地面上的误差更大。
下表比较了我们提出的方法与两种基线方法在行人定位中的RMSE和MAE。可以观察到,我们的方法在两个数据集的评估指标方面都显著优于Monoloco和几何基线。

特别是,在行人完全可见的情况下,我们提出的框架实现了几乎类似或略好于几何基线的定位精度;在遮挡行人的情况下,我们的方法明显优于其他两种基线方法,并且这种改进随着遮挡程度的提高而增加。
与最先进的基线相比,我们的方法的更好的性能可以通过以下论点来证明。Monoloco将图像平面中每个实例的边界框的中心点反向投影到该实例的3D位置。几何基线也使用实例边界框的底部中心来定位行人。然而,这种方法可能不是特别准确,因为在许多现实世界的情况下,四肢可能是不对称的延伸,或者包围框可能没有紧紧围绕行人的轮廓。这种情况加上行人遮挡的情况会在位置估计过程中造成额外的误差。另一方面,我们的方法不依赖于包围框,而是使用各种可见关键点的共现来估计地面坐标。
结论
本文提出了一种基于单目视觉的行人定位框架,为了解决拥挤环境下行人遮挡的问题,我们使用一种轻量级的深度神经网络来估计人体姿势缺失的部分。在两个真实世界的数据集上进行的实验表明,与现有的最先进的方法相比,该方法是有效的。我们提出的框架在实际情况下显示了很好的性能,以准确估计单应性变换。这项工作的一个局限性是缺乏一种方法来估计预测位置的不确定性。因此,未来的研究方向可以是使用热力图或贝叶斯深度学习来量化预测位置的不确定性。作为另一个未来方向,可以利用行人在连续帧中的时间相关性来进一步提高人体缺失部位的预测。
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4789浏览量
101593 -
摄像机
+关注
关注
3文章
1649浏览量
60543 -
RGB
+关注
关注
4文章
801浏览量
58925 -
SCS
+关注
关注
0文章
20浏览量
10634 -
自动驾驶汽车
+关注
关注
4文章
379浏览量
40973
原文标题:基于单张RGB图像定位被遮挡行人
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
RGB数字图像显示中错误图像分析
阿里巴巴介绍行人检测与识别技术
基于姿态和并行化学习任务的行人再识别
基于多级梯度特征的红外图像行人检测算法
基于视点与姿态估计的视频监控行人再识别
一种基于RGB-D图像序列的协同隐式神经同步定位与建图(SLAM)系统
从单张图像中揭示全局几何信息:实现高效视觉定位的新途径

如何应对UWB室内定位信号被遮挡





 工商网监
工商网监
评论