1. 1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
原文:https://mp.weixin.qq.com/s/B3KycAYJ2bLWctvoWOAxHQ
一夜之间,世界最强开源大模型Falcon 180B引爆全网!
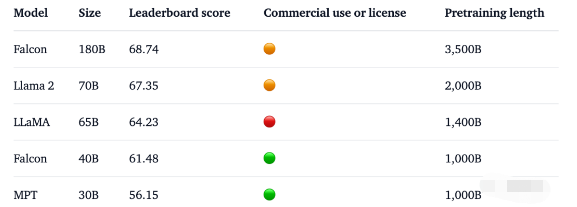
1800亿参数,Falcon在3.5万亿token完成训练,直接登顶Hugging Face排行榜。
基准测试中,Falcon 180B在推理、编码、熟练度和知识测试各种任务中,一举击败Llama 2。
甚至,Falcon 180B能够与谷歌PaLM 2不差上下,性能直逼GPT-4。不过,英伟达高级科学家Jim Fan对此表示质疑,- Falcon-180B的训练数据中,代码只占5%。而代码是迄今为止对提高推理能力、掌握工具使用和增强AI智能体最有用的数据。事实上,GPT-3.5是在Codex的基础上进行微调的。- 没有编码基准数据。没有代码能力,就不能声称「优于GPT-3.5」或「接近GPT-4」。它本应是预训练配方中不可或缺的一部分,而不是事后的微调。- 对于参数大于30B的语言模型,是时候采用混合专家系统(MoE)了。到目前为止,我们只看到OSS MoE LLM < 10B。
一起来看看,Falcon 180B究竟是什么来头?世界最强开源大模型此前,Falcon已经推出了三种模型大小,分别是1.3B、7.5B、40B。官方介绍,Falcon 180B是40B的升级版本,由阿布扎比的全球领先技术研究中心TII推出,可免费商用。

这次,研究人员在基底模型上技术上进行了创新,比如利用Multi-Query Attention等来提高模型的可扩展性。对于训练过程,Falcon 180B基于亚马逊云机器学习平台Amazon SageMaker,在多达4096个GPU上完成了对3.5万亿token的训练。总GPU计算时,大约7,000,000个。Falcon 180B的参数规模是Llama 2(70B)的2.5倍,而训练所需的计算量是Llama 2的4倍。具体训练数据中,Falcon 180B主要是RefinedWe数据集(大约占85%) 。此外,它还在对话、技术论文,以及一小部分代码等经过整理的混合数据的基础上进行了训练。这个预训练数据集足够大,即使是3.5万亿个token也只占不到一个epoch。官方自称,Falcon 180B是当前「最好」的开源大模型,具体表现如下:在MMLU基准上,Falcon 180B的性能超过了Llama 2 70B和GPT-3.5。在HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC 及ReCoRD上,与谷歌的PaLM 2-Large不相上下。另外,它在Hugging Face开源大模型榜单上,是当前评分最高(68.74分)的开放式大模型,超越了LlaMA 2(67.35)。
2. Meta的Flamera头显对增强现实有了新的愿景
原文:https://mp.weixin.qq.com/s/UepWwW7D03_jISTsSmjwnA
Meta的最新原型头显Flamera像是直接从科幻动作片中来的一样,它在Siggraph 2023上引起了人们的注意 —— Flamera在那里获得了令人垂涎的Best in Show奖。据悉,Flamera原型头显展示了接近人眼分辨率和全新的"透视"真实世界的技术。该原型或许为VR、MR和AR的未来铺平了道路。头显原型展示的技术突破引发了人们的兴趣和关注。Moor Insights&Strategy副总裁兼首席分析师Ansel Sag表示:“这绝对是我见过的质量最好的(增强现实)实现透视真实世界的全新方法。”

Giving Reality the Bug Eye出于显而易见的原因,在物理上不可能将头显的摄像头与用户的眼睛完全放置在同一位置。这种位移导致了我(作者,以下简称我)个人经历的视角的转变:我在使用AR/VR头显时撞到了墙上,或者被被椅子绊倒了。像Meta Quest Pro这样的尖端头显,通过从正确的角度重新投射周围环境的视图,跨越了这一障碍,但解决方案可能会导致视觉失真。Meta的虫眼Flamera提出了一个新颖的解决方案。它摒弃了当前头显青睐的外部摄像头阵列,采用了独特的“光场穿透”设计,将图像传感器与物理控制到达传感器的光的孔径配对。会导致不正确视角的光被阻挡,而提供准确视角的光则被允许到达传感器。当直接通过镜头观看时,结果很奇怪:这有点像透过纸上的洞看世界。头显重新排列原始图像以消除间隙并重新定位传感器数据。一旦这个过程完成,耳机就会为用户提供准确的世界视图。Sag说:“这绝对是一个原型,但它的图像质量和分辨率给我留下了深刻印象。” “帧速率很好,”ModiFace的软件开发总监Edgar Maucourant也演示了这款头显,并对此印象深刻,“我的眼睛所看到的东西和我的手的位置与我的手真正的位置之间没有延迟,也没有差异。”Maucourant认为Flamera的准确性可能会为用户直接与周围世界互动的AR应用程序带来福音。“例如,如果我们考虑远程辅助,人们必须操纵物体,那么今天它是用HoloLens和Magic Leap等AR眼镜来实现的……我们可以想象使用AR穿透来实现这一点。”Meta’s Answer to the Apple Vision Pro?与微软的HoloLens和Magic Leap进行比较很重要。它们通过透明显示器绕过了透视问题,让用户的视觉畅通无阻。当HoloLens于2016年发布时,这种方法感觉像是未来的趋势,但其显示质量、视野和亮度仍然存在问题。Meta的Quest Pro和苹果即将推出的Vision Pro强调了这一方向的转变。尽管以AR/VR头显(或者,苹果方以“空间计算机”)的形式进行营销,但它们显然是虚拟现实家族的一个分支。它们通过不透明的显示器完全遮挡了用户的视野。增强现实是通过视频馈送提供的,该视频馈送将外部世界投射到显示器。Vision Pro解决直通问题的方法更注重肌肉而非大脑。它使用了一系列与其他AR/VR头显类似的外部摄像头,但将其与苹果定制的R1芯片配对,该芯片与苹果M2芯片协同工作(就像该公司笔记本电脑中的芯片一样)。R1是一个“视觉处理器”,可以帮助vision Pro的12台相机通过计算校正视角(以及其他任务)。这很像Meta在Quest Pro上尝试的方法,但苹果将功率提高到了11。Meta的Flamera取而代之的是用镜头校正视角。这大大降低了准确直通AR所需的原始计算能力。但这并不是说Meta已经完全打开了AR。Flamera的技术距离可供购买的头显还有很长的路要走,目前与传统的直通AR相比存在一些缺点。Sag表示,该头显“视野相当有限”,并注意到其景深“不连续”,这意味着远处的物体看起来比实际更近。Maucourant警告说“颜色不太好”,并认为头显的分辨率很低。尽管如此,Flamera或展示了Meta、苹果和其他希望进入AR领域的公司之间即将发生的争论方向。科技界的大腕们似乎确信,明天最好的AR/VR头显看起来更像最初的Oculus Rift,而不是微软的HoloLens。然而,目前这些原型更多还是在研究阶段,离成为消费级产品还有一段距离。未来,头显技术的发展还需要在各个方面进行突破和创新,以实现更高的分辨率、更低的延迟、更舒适的使用体验等。只有解决了这些问题,才能让用户真正感受到头显带来的沉浸式体验,进一步推动VR、MR和AR技术的广泛应用。
3. 腾讯混元大模型正式亮相,我们抢先试了试它的生产力
原文:https://mp.weixin.qq.com/s/xuk77KHJHhoh6kWkf-4AKg
上个星期,国内首批大模型备案获批,开始面向全社会开放服务,大模型正式进入了规模应用的新阶段。在前期发布应用的行列中,有些科技巨头似乎还没有出手。很快到了 9 月 7 日,在 2023 腾讯全球数字生态大会上,腾讯正式揭开了混元大模型的面纱,并通过腾讯云对外开放。作为一个超千亿参数的大模型,混元使用的预训练语料超过两万亿 token,凭借多项独有的技术能力获得了强大的中文创作能力、复杂语境下的逻辑推理能力,以及可靠的任务执行能力。

腾讯集团副总裁蒋杰表示:「腾讯混元大模型是从第一个 token 开始从零训练的,我们掌握了从模型算法到机器学习框架,再到 AI 基础设施的全链路自研技术。」打开大模型,全部都是生产力腾讯一直表示在大模型的相关方向上早已有所布局,专项研究一直有序推进。这个不是「新技术」的大模型是什么级别?在大会上蒋杰通过直接询问混元大模型的方式透露了一些基本信息,它的参数量是千亿级,训练用的数据截止到今年 7 月份,此外腾讯也表示大模型的知识将会每月更新。腾讯在现场展示了「腾讯混元大模型小程序」、腾讯文档中的 AI 助手以及腾讯会议 AI 助手的能力。机器之心第一时间获得测试资格尝试了一番,首先是微信小程序。

从生产力、生活、娱乐到编程开发,它开放的能力可谓非常全面了,符合一个千亿级大模型的身份。那么混元真的能有效地完成这些任务吗?我要写一份 PPT,只想好了主题却不知从何写起,问一下混元大模型。只需几秒,AI 就给了一份分出七个部分的大纲,每一部分里也包含细分的点:输入一篇 arXiv 上 9 月份谷歌提交的论文《RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback》摘要和介绍部分,长长的好几段,很多大模型根本不支持这么多输入内容,混元大模型直接进行了总结顺便翻译成中文。它详细解释了平方根倒数算法里面数字的意义(不过对注释理解得不太透彻)。或许过不了多久,我们做开发的时候就离不开大模型了。然后是腾讯文档。很多人已经把 GPT-4 等大模型工具用在了自己的工作流程中,混元大模型在腾讯文档推出的智能助手功能中已有应用。在 PC 端新建智能文档,输入 “/”,就能根据需求实现内容生成、翻译、润色等操作。已覆盖腾讯超过 50 个业务蒋杰总结了混元大模型的三大特点:具备强大的中文创作能力、复杂语境下的逻辑推理能力以及可靠的任务执行能力。目前不少业内大模型在场景中的应用依然有限,主要问题集中在容错率高,只适用于任务简单的休闲场景。腾讯在算法层面进行了一系列自研创新,提高了模型可靠性和成熟度。

针对大模型容易「胡言乱语」的问题,腾讯优化了预训练算法及策略,通过自研的「探真」技术,让混元大模型的「幻觉」相比主流开源大模型降低了 30-50%。「业界的做法是提供搜索增强,知识图谱等『外挂』来提升大模型开卷考试的能力。这种方式增加了模型的知识,但在实际应用中存在很多局限性,」蒋杰表示。「混元大模型在开发初期就考虑完全不依赖外界数据的方式,进行了大量研究尝试,我们找到的预训练方法,很大程度上解决了幻觉的问题。」腾讯还通过强化学习的方法,让模型学会识别陷阱问题,通过位置编码的优化,提高了模型处理超长文的效果和性能。在逻辑方面,腾讯提出了思维链的新策略,让大模型能够像人一样结合实际的应用场景进行推理和决策。腾讯混元大模型能够理解上下文的含义,具有长文记忆能力,可以流畅地进行专业领域的多轮对话。除此之外,它还能进行文学创作、文本摘要、角色扮演等内容创作,做到充分理解用户意图,并高效、准确的给出有时效性的答复。这样的技术落地之后,才能真正提升生产力。

在中国信通院《大规模预训练模型技术和应用的评估方法》的标准符合性测试中,混元大模型共测评 66 个能力项,在「模型开发」和「模型能力」两个领域的综合评价获得了当前最高分。在主流的评测集 MMLU、CEval 和 AGI-eval 上,混元大模型均有优异的表现,特别是在中文的理科、高考题和数学等子项上表现突出。构建大模型的意义在于行业应用。据了解,腾讯内部已有超过 50 个业务和产品接入并测试了腾讯混元大模型,包括腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ 浏览器等,并取得了初步效果。腾讯的程序员们,已经在用大模型工具提高开发效率了。此外,腾讯还通过自研机器学习框架 Angel,使模型的训练速度相比业界主流框架提升 1 倍,推理速度比业界主流框架提升 1.3 倍。用于构建大模型的基础设施也没有拉下。此前腾讯曾表示已于今年年初构建了大规模算力中心,近期 MiniMax 和百川智能旗下的大模型都使用了腾讯的算力。腾讯也在致力于把行业数据与自身能力相结合,基于外部客户的行业化数据来解决行业特定问题,与实体行业结合,不断推动大模型的社会、经济利益和商业价值。「根据公开数据显示,国内已有 130 个大模型发布。其中既有通用模型也有专业领域模型。混元作为通用模型能够支持腾讯内部的大部分业务,今天我展示的几个深度接入的业务都有很大的用户量。大模型已在我们的核心领域获得了深度应用,」蒋杰说道。「我大模型首先是服务企业本身,其次是通过腾讯云对外开放。」在开放给客户使用时,混元大模型将作为腾讯云模型即服务 MaaS 的底座。客户既可以直接调用混元 API,也能将混元作为基座模型,为不同的产业场景构建专属应用。可见,腾讯在大模型领域的策略讲究的是一个稳字:专注打好基础,不急于拿出半成品展示。而这一出手,就展现出了过硬的实力。

不过大模型的发展还在继续,正如蒋杰所言:「毫不夸张地说,腾讯已经全面拥抱大模型。我们的能力一直在演进,相信 AIGC 的潜力是无限的,我们已在路上。」
4. GitHub热榜登顶:开源版GPT-4代码解释器,可安装任意Python库,本地终端运行
原文:https://mp.weixin.qq.com/s/TiSVeZOeWourVJ60yyyygw
ChatGPT的代码解释器,用自己的电脑也能运行了。刚刚有位大神在GitHub上发布了本地版的代码解释器,很快就凭借3k+星标并登顶GitHub热榜。不仅GPT-4本来有的功能它都有,关键是还可以联网。
ChatGPT“断网”的消息传出后引起了一片哗然,而且一关就是几个月。这几个月间联网功能一直杳无音讯,现在可算是有解决的办法了。由于代码是在本地运行,所以除了联网之外,它还解决了网页版的很多其他问题:-
3小时只能发50条消息
-
支持的Python模块数量有限
-
处理文件大小有限制,不能超过100MB
-
关闭会话窗口之后,此前生成的文件会被删除
如果没有API,还可以把模型换成开源的Code LLaMa。这个代码解释器推出之后,很快有网友表示期待一波网页版:

那么我们就来看看这个本地代码解释器到底怎么样吧!让GPT“重新联网”既然调用了GPT-4的API,那GPT-4支持的功能自然都能用,当然也支持中文。关于GPT本身的功能这里就不再一一详细展示了。不过值得一提的是,有了代码解释器之后,GPT的数学水平提升了好几个档次。所以这里我们用一个高难度的求导问题来考验一下它,题目是f(x)=√(x+√(x+√x))。
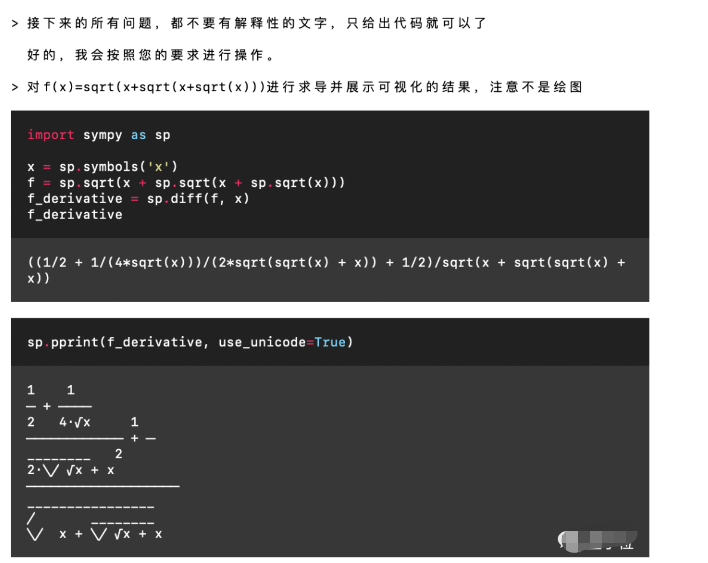
Emmm……这个结果有些抽象,不过应该是提示词的问题,我们修改一下:
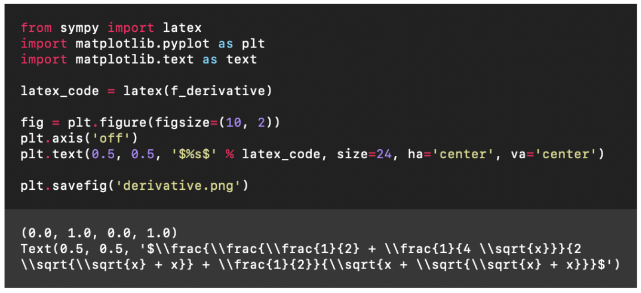
然后我们就看到了这样的结果:
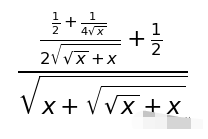
这个式子和标准答案长得不太一样,不过是不是格式的问题呢?我们验证了一下:
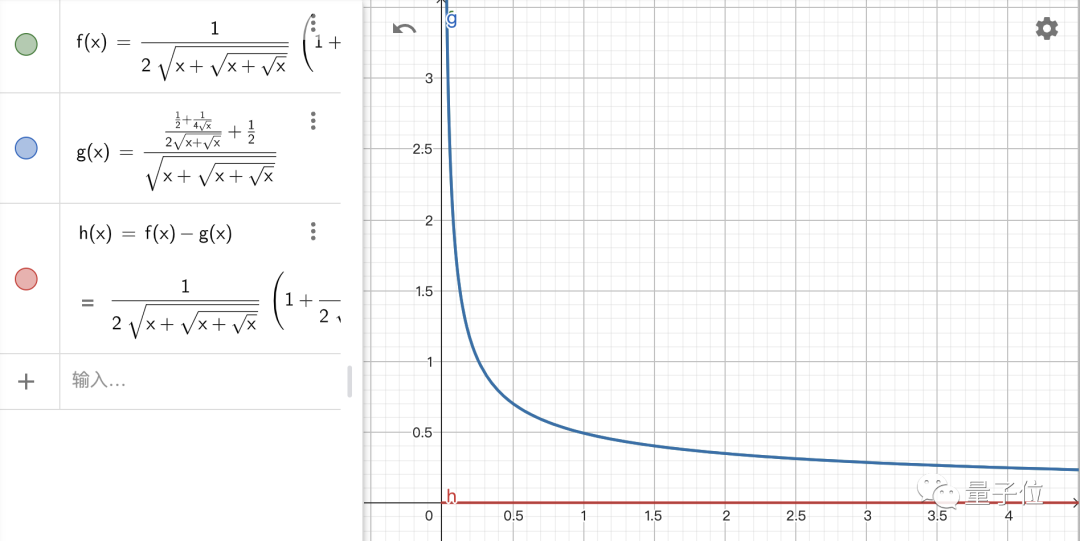
结果是正确的!接下来就要进入重头戏了,来看看这个代码解释器的联网功能到底是不是噱头:比如我们想看一下最近有什么新闻。更多的内容请点击原文,谢谢。
5. ReVersion|图像生成中的Relation定制化
原文:https://mp.weixin.qq.com/s/7W80wWf2Bj68MnC8NEV9cQ
新任务:Relation Inversion今年,diffusion model和相关的定制化(personalization)的工作越来越受人们欢迎,例如DreamBooth,Textual Inversion,Custom Diffusion等,该类方法可以将一个具体物体的概念从图片中提取出来,并加入到预训练的text-to-image diffusion model中,这样一来,人们就可以定制化地生成自己感兴趣的物体,比如说具体的动漫人物,或者是家里的雕塑,水杯等等。现有的定制化方法主要集中在捕捉物体外观(appearance)方面。然而,除了物体的外观,视觉世界还有另一个重要的支柱,就是物体与物体之间千丝万缕的关系(relation)。目前还没有工作探索过如何从图片中提取一个具体关系(relation),并将该relation作用在生成任务上。为此,我们提出了一个新任务:Relation Inversion。
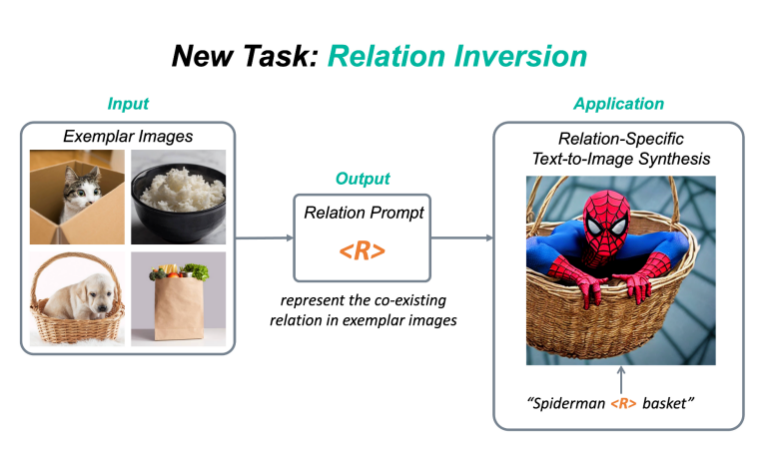
如上图,给定几张参考图片,这些参考图片中有一个共存的relation,例如“物体A被装在物体B中”,Relation Inversion的目标是找到一个relation prompt来描述这种交互关系,并将其应用于生成新的场景,让其中的物体也按照这个relation互动,例如将蜘蛛侠装进篮子里。

论文:https://arxiv.org/abs/2303.13495代码:https://github.com/ziqihuangg/ReVersion主页:https://ziqihuangg.github.io/projects/reversion.html视频:https://www.youtube.com/watch?v=pkal3yjyyKQDemo:https://huggingface.co/spaces/Ziqi/ReVersion
ReVersion框架作为针对Relation Inversion问题的首次尝试,我们提出了ReVersion框架:
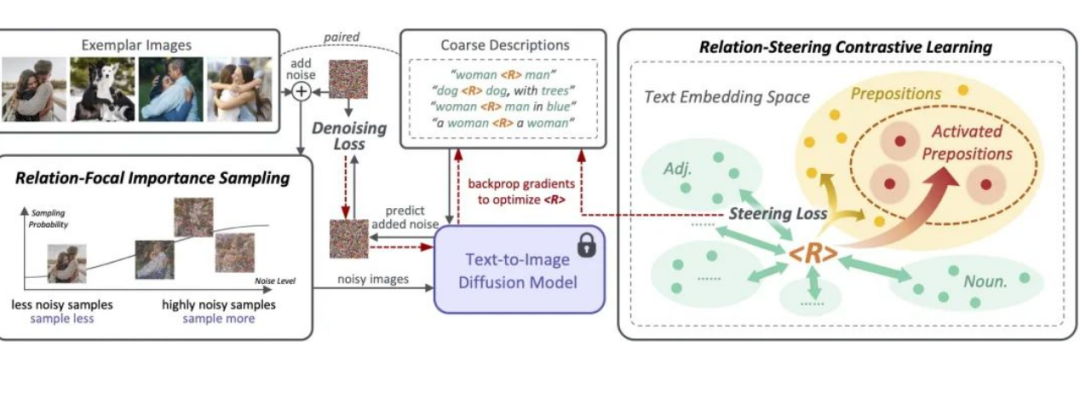
相较于已有的Appearance Invesion任务,Relation Inversion任务的难点在于怎样告诉模型我们需要提取的是relation这个相对抽象的概念,而不是物体的外观这类有显著视觉特征的方面。我们提出了relation-focal importance sampling策略来鼓励更多地关注high-level的relation;同时设计了relation-steering contrastive learning来引导更多地关注relation,而非物体的外观。更多细节详见论文。ReVersion Benchmark我们收集并提供了ReVersion Benchmark:https://github.com/ziqihuangg/ReVersion#the-reversion-benchmark它包含丰富多样的relation,每个relation有多张exemplar images以及人工标注的文字描述。我们同时对常见的relation提供了大量的inference templates,大家可以用这些inference templates来测试学到的relation prompt是否精准,也可以用来组合生成一些有意思的交互场景。结果展示丰富多样的relation,我们可以invert丰富多样的relation,并将它们作用在新的物体上
6. 神经网络大还是小?Transformer模型规模对训练目标的影响
原文:https://mp.weixin.qq.com/s/el_vtxw-54LVnuWzS1JYDw
论文链接:https://arxiv.org/abs/2205.10505
01 TL;DR本文研究了 Transformer 类模型结构(configration)设计(即模型深度和宽度)与训练目标之间的关系。结论是:token 级的训练目标(如 masked token prediction)相对更适合扩展更深层的模型,而 sequence 级的训练目标(如语句分类)则相对不适合训练深层神经网络,在训练时会遇到 over-smoothing problem。在配置模型的结构时,我们应该注意模型的训练目标。一般而言,在我们讨论不同的模型时,为了比较的公平,我们会采用相同的配置。然而,如果某个模型只是因为在结构上更适应训练目标,它可能会在比较中胜出。对于不同的训练任务,如果没有进行相应的模型配置搜索,它的潜力可能会被低估。因此,为了充分理解每个新颖训练目标的应用潜力,我们建议研究者进行合理的研究并自定义结构配置。02 概念解释下面将集中解释一些概念,以便于快速理解:2.1 Training Objective(训练目标)
 训练目标是模型在训练过程中完成的任务,也可以理解为其需要优化的损失函数。在模型训练的过程中,有多种不同的训练目标可以使用,在此我们列出了 3 种不同的训练目标并将其归类为 token level 和 sequence level:
训练目标是模型在训练过程中完成的任务,也可以理解为其需要优化的损失函数。在模型训练的过程中,有多种不同的训练目标可以使用,在此我们列出了 3 种不同的训练目标并将其归类为 token level 和 sequence level:-
sequence level:
-
-
classification 分类任务,作为监督训练任务。简单分类(Vanilla Classification)要求模型对输入直接进行分类,如对句子进行情感分类,对图片进行分类;而 CLIP 的分类任务要求模型将图片与句子进行匹配。
-
token level:(无监督)
-
-
masked autoencoder:masked token 预测任务,模型对部分遮盖的输入进行重建
-
next token prediction:对序列的下一个 token 进行预测
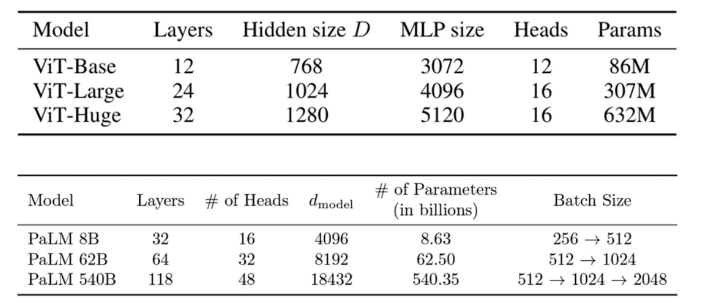
2.2 Transformer Configration(模型结构:配置)
Transoformer 的配置指的是定义 Transformer 模型结构和大小的超参数,包括层数(深度),隐藏层大小(宽度),注意力头的个数等。2.3 Over-smoothing (过度平滑)
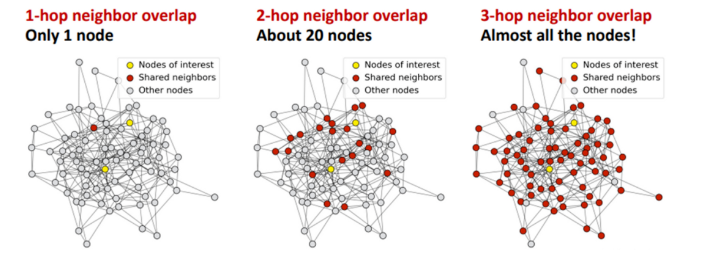
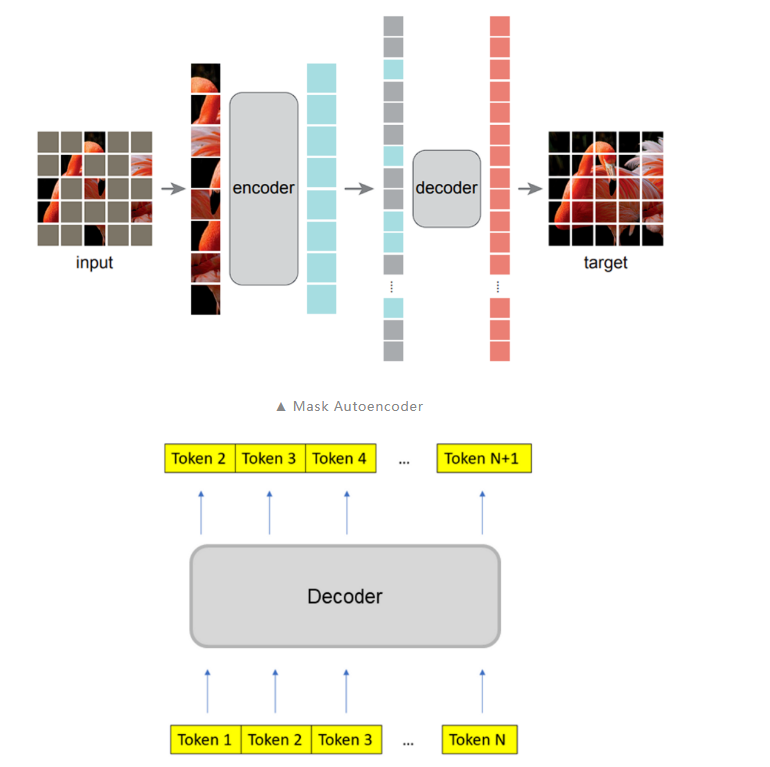
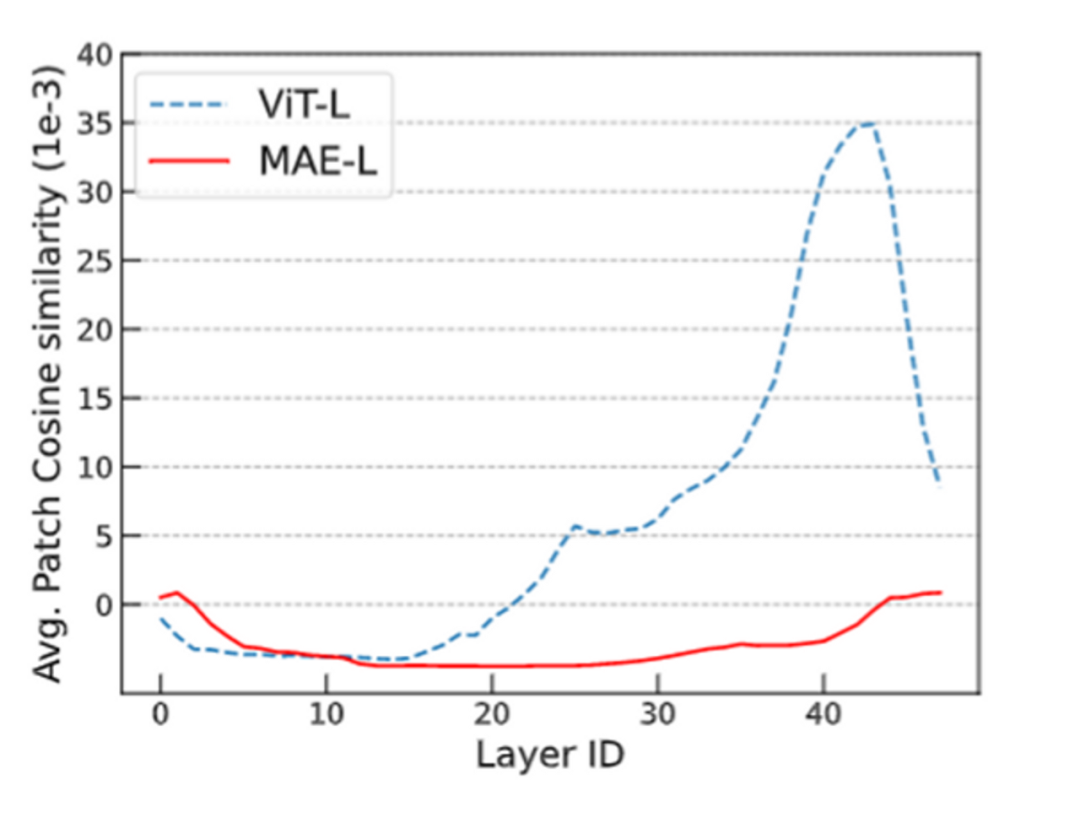
过度平滑是一个在图神经网络中的概念,具体表示模型输出趋向平滑一致,各个点的输出缺少细节和变化的现象。这一现象在图神经网络中被广泛研究,但它也在 Transformer 模型中存在。(已有研究)发现 Transoformer 模型遇到的 over-smoothing 问题阻碍模型加深。具体而言,当堆叠多层的 Transformer layers 时,transformer layer 输出的 token 表征(向量)会趋于一致,丢失独特性。这阻碍了 Transformer 模型的扩展性,特别是在深度这一维度上。增加 Transformer 模型的深度只带来微小的性能提升,有时甚至会损害原有模型的性能。1. ViT 和 MAE 中的 over-smoothing直观上,掩码自编码器框架(例如 BERT、BEiT、MAE)的训练目标是基于未掩码的 unmasked token 恢复被掩码的 masked token。与使用简单分类目标训练 Transformer 相比,掩码自编码器框架采用了序列标注目标。我们先假设掩码自编码器训练能缓解 over-smoothing,这可能是掩码自编码器 MAE 有助于提升 Transformer 性能的原因之一。由于不同的 masked token 相邻的 unmaksed token 也不同,unmasked token 必须具有充分的语义信息,以准确预测其临近的 masked token。也即,unmasked token 的表征的语义信息是重要的,这抑制了它们趋向一致。总之,我们可以推断掩码自编码器的训练目标通过对 token 间的差异进行正则化,有助于缓解过度平滑问题。我们通过可视化的实验来验证了这一观点。我们发现 ViT 的 token 表征在更深的层中更加接近,而 MAE 模型则避免了这个问题,这说明在掩码自编码器中,over-smoothing 问题得到了缓解。通过简单的分类任务训练 Transformer 模型则不具备这一特点。
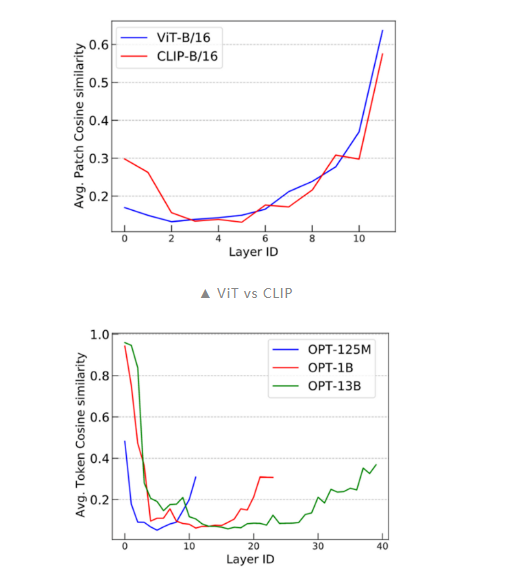
进一步的,我们还通过傅里叶方法对这一问题进行了研究,具体可以参考我们的论文。2. CLIP 和 LLM 中的 over-smoothing根据上述分析,我们可以得出结论:token 级的训练目标(例如语言建模中的:next token prediction)表现出较轻的 over-smoothing。另一方面,基于 sequence 级别的目标(如对比图像预训练)更容易出现 over-smoothing。为了验证这个结论,我们使用 CLIP 和 OPT 进行了类似的 cosine 相似度实验。我们可以看到 CLIP 模型展现了与 Vanilla ViT 类似的 over-smoothing 现象。这一观察结果符合我们的预期。此外,为了探究 next-token prediction 这一广泛采用的语言建模预训练目标是否可以缓解 over-smoothing,我们对 OPT 进行了评估,并发现它能够有效应对 over-smoothing。这一发现具有重要意义,因为它有助于解释为什么语言建模模型在可扩展性方面(如超大规模预训练语言模型)优于许多视觉模型。
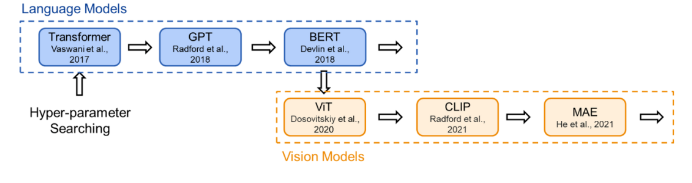
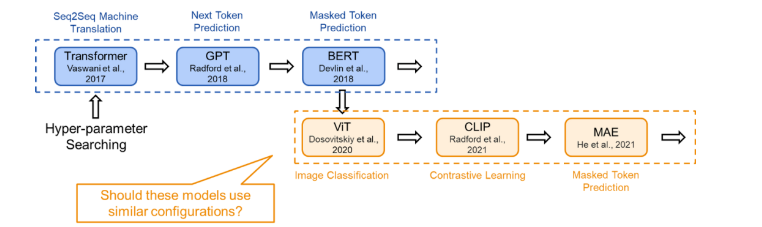
03 溯源:现有的Transformer架构是怎么来的为了在研究时保证公平的比较,现有的 Transformer 类模型通常会遵循固定的结构(small, base, large…),即相同的宽度和深度。比如前面提到的 transformer-base 就是宽度为 768(隐藏层),深度为 12(层数)。然而,对于不同的研究领域,不同的模型功能,为什么仍要采用相同的超参数?为此,我们首先对 Transformer 架构进行了溯源,回顾了代表性的工作中 Transformer 结构的来源:Vision Transformer 的作者根据 BERT 中 Transformer-base 的结构作为其 ViT 模型配置;而 BERT 在选择配置时遵循了 OpenAI GPT 的方法;OpenAI 则参考了最初的 Transformer 论文。在最初的 Transformer 论文中,最佳配置来源于机器翻译任务的笑容实验。也就是说,对于不同任务,我们均采用了基于对机器翻译任务的 Transformer 配置。(参考上文,这是一种序列级别的任务)
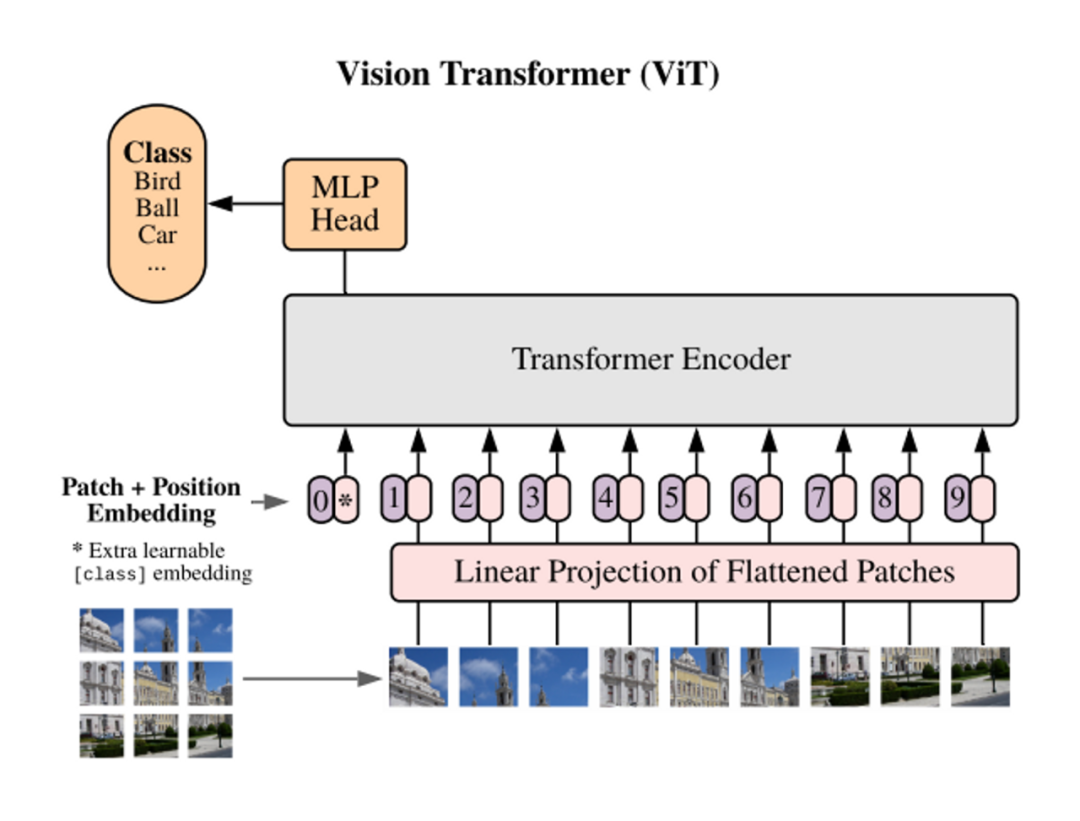
04 现状:不同的模型采用不同的训练目标现在,Transformer 模型通过各种训练目标进行训练。以 ViT 为例,我们可以在图像分类的监督学习环境下从头开始训练 Transformer 模型。在这种直接的图像分类任务中,每个图像被建模为一个 token 序列,其中每个 token 对应图像中的一个图块。我们使用来自图像的所有 token(即图块)的全局信息来预测单个标签,即图像类别。在这里,由于训练目标是捕捉图像的全局信息,token 表示之间的差异不会直接被考虑。这一训练目标与机器翻译任务完全不同,机器翻译要求模型理解 token 序列,并以此生成另一个序列。据此,我们可以合理假设对于这两个不同任务,应该存在不同的最佳 Transformer 配置。
05 对于MAE训练目标调整模型结构基于上述的讨论,我们得到了如下认识:-
现有的 Transformer 模型在加深模型深度时会发生 over-smoothing 问题,这阻碍了模型在深度上的拓展。
-
相较于简单分类训练目标,MAE 的掩码预测任务能够缓解 over-smoothing。(进一步地,token 级别的训练目标都能够一定程度地缓解 over-smoothing)
-
MAE 的现有模型结构继承于机器翻译任务上的最佳结构设置,不一定合理。
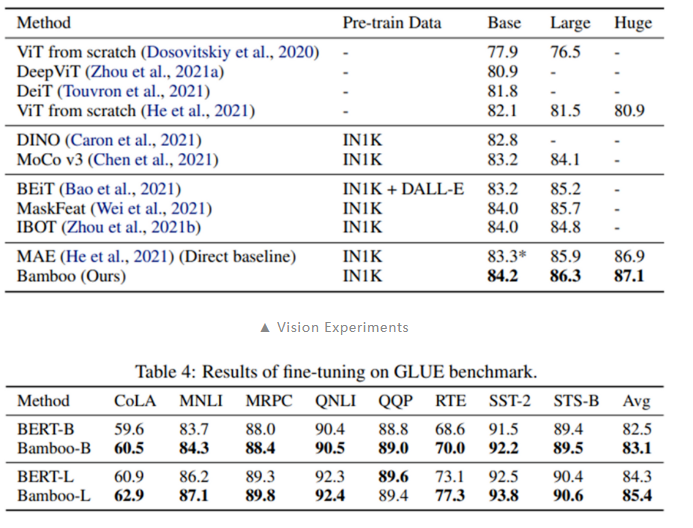
综合以上三点,可以推知 MAE 应该能够在深度上更好的拓展,也即使用更深的模型架构。本文探索了 MAE 在更深,更窄的模型设置下的表现:采用本文提出的 Bamboo(更深,更窄)模型配置,我们可以在视觉和语言任务上得到明显的性能提升。
另外,我们在深度拓展性上也做了实验,可以看到,当采用 Bamboo 的配置时,MAE 能够获得明显的性能提升,而对于 ViT 而言,更深的模型则是有害的。MAE 在深度增加到 48 层时仍能获得性能提升,而 ViT 则总是处于性能下降的趋势。
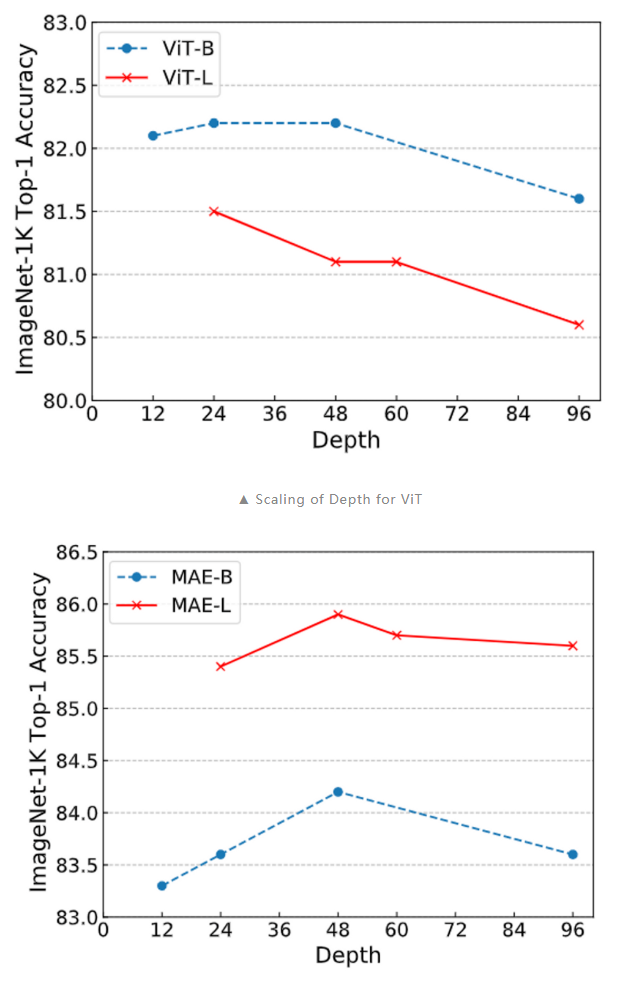
以上的结果佐证了本文提出的观点:训练目标能够影响模型拓展的行为。Training objectives can greatly change the scaling behavior.06 结论本文发现,Transformer 的配置与其训练目标之间存在着密切关系。sequence 级别的训练目标,如直接分类和 CLIP,通常遇到 over-smoothing。而 token 级的训练目标,如 MAE 和 LLMs 的 next token prediction,可以较好地缓解 over-smoothing。这一结论解释了许多模型扩展性研究结果,例如 GPT-based LLMs 的可扩展性以及 MAE 比 ViT 更具扩展性的现象。我们认为这一观点对我们的学术界有助于理解许多 Transformer 模型的扩展行为。
———————End———————
点击阅读原文进入官网
原文标题:【AI简报20230908期】正式亮相!打开腾讯混元大模型,全部都是生产力
文章出处:【微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
原文标题:【AI简报20230908期】正式亮相!打开腾讯混元大模型,全部都是生产力
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
相关推荐
近日,在2024年12月24日举办的开放原子开发者大会暨首届开源技术学术大会上,腾讯云副总裁、腾讯混元大模型负责人刘煜宏发表了重要演讲。他强
![的头像]() 发表于
发表于 12-26 10:30
•220次阅读
近日,北京智源人工智能研究院(BAAI)发布了最新的FlagEval大模型评测排行榜,其中多模态模型评测榜单的文生图模型引起了广泛关注。结果显示,腾讯
![的头像]() 发表于
发表于 12-25 10:06
•189次阅读
近日,腾讯宣布其混元大模型正式上线,并开源了一项令人瞩目的能力——文生视频。该大模型参数量高达130亿,支持中英文双语输入,为用户提供了更为
![的头像]() 发表于
发表于 12-04 14:06
•164次阅读
近日,腾讯混元团队最新推出的MoE模型“混元Large”已正式开源上线。这一里程碑式的进展标志着
![的头像]() 发表于
发表于 11-08 11:03
•434次阅读
骁龙峰会期间,高通技术公司宣布与腾讯混元合作,基于骁龙8至尊版移动平台,共同推动了腾讯混元大
![的头像]() 发表于
发表于 11-08 09:52
•414次阅读
,分享了智能化应用的行业实践,并发布了华为云在应用开发、运行、运维、集成领域的智能化新产品能力。 在主题为“ AI 赋能应用现代化,加速软件生产力跃升论坛 ”的论坛上,徐峰首先介绍了 AI 软件+应用领域将会成为
![的头像]() 发表于
发表于 10-14 09:45
•535次阅读

大模型应用百花齐放,AI编程助手作为新质生产力工具为企业和开发者带来哪些价值?
![的头像]() 发表于
发表于 09-02 09:25
•646次阅读
5月21日-22日,北京机器视觉助力智能制造创新发展大会在北京国际会议中心圆满举行。本次大会以“Vision+AI引领新质生产力”为核心主题,聚焦“3D视觉与精准成像、AI大模型、工业
![的头像]() 发表于
发表于 05-30 17:14
•555次阅读

从腾讯方面获悉,一站式智能体创作与分发平台腾讯元器即日起全面升级了模型资源扶持方案。
![的头像]() 发表于
发表于 05-27 14:22
•850次阅读
据了解,腾讯混元大模型是腾讯全链路自研的万亿参数大模型,采用混合专家
![的头像]() 发表于
发表于 05-23 17:05
•898次阅读
当嫘祖也开始用大模型掌握新质生产力……
![的头像]() 发表于
发表于 04-16 17:52
•559次阅读

新质生产力,是2023年9月首次提到的新的词汇,新质生产力是生产力现代化的具体体现,即新的高水平现代化生产力(新类型、新结构、高技术水平、高质量、高效率、可持续的
![的头像]() 发表于
发表于 02-28 16:01
•2370次阅读
新质生产力作为先进生产力的具体体现形式,是马克思主义生产力理论的中国创新和实践,是科技创新交叉融合突破所产生的根本性成果。
![的头像]() 发表于
发表于 02-28 15:39
•1.1w次阅读
自从ChatGPT爆火以来,各种AI大模型纷纷亮相,如百度科技的文心一言,科大讯飞的讯飞星火,华为的盘古AI大模型,
![的头像]() 发表于
发表于 02-28 09:35
•2370次阅读
新质生产力的发展主要集中在新能源、新材料、先进制造、电子信息等战略性新兴产业。 新质生产力作为先进生产力的具体体现形式,是马克思主义生产力理论的中国创新和实践,是科技创新交叉融合突破所
![的头像]() 发表于
发表于 02-22 17:57
•4921次阅读
 【AI简报20230908期】正式亮相!打开腾讯混元大模型,全部都是生产力
【AI简报20230908期】正式亮相!打开腾讯混元大模型,全部都是生产力





 工商网监
工商网监
评论