 ecology相关的挖掘思路
ecology相关的挖掘思路
前段时间 ecology 密集发布了一系列补丁,修复几个笔者之前储备的 0day,本文就来介绍其中一个列比较有意思的,以及分享一下相关的挖掘思路。
背景
最近几个月笔者都在研究 Java Web 方向,一方面是工作职责的调整,另一方面也想挑战一下新的领域。对于漏洞挖掘而言,选择一个具体目标是非常重要的,经过一段时间供应链和生态的学习以及同事建议,兼顾漏洞挖掘难度和实战效果选择了 ecology OA作为第一个漏洞挖掘的目标。
代码审计
虽然本文介绍的是 Fuzzing,但之前也说过很多次,自动化漏洞挖掘只能作为一种辅助手段,是基于自身对代码结构的理解基础上的提效方式。
在真正开始挖漏洞之前,笔者花了好几周的时间去熟悉目标的代码,并且对一些不清晰的动态调用去进行运行时分析,最终才能在 20G 代码之中梳理出大致的鉴权和路由流程。
通过分析 JavaEE 应用注册的路由,注意到其中一个映射:
ServletMapping[url-pattern=/services/*,name=XFireServlet]^/services(?=/)|^/servicesz]
其对应的类为org.codehaus.xfire.transport.http.XFireConfigurableServlet:
<servlet>
<servlet-name>XFireServletservlet-name>
<display-name>XFireServletdisplay-name>
<servlet-class>org.codehaus.xfire.transport.http.XFireConfigurableServletservlet-class>
servlet>
<servlet-mapping>
<servlet-name>XFireServletservlet-name>
<url-pattern>/services/*url-pattern>
servlet-mapping>
XFire 考古
XFire[1]并不是 ecology 自己的业务代码,而是一个 SOAP Web 服务框架,它是作为 Apache Axis 的有效替代方案而开发的。除了通过使用 StAX 实现良好性能的目标外,XFire 的目标还包括通过各种插件机制实现灵活性,API 的直观操作以及与通用标准的兼容性。此外 XFire 非常适合集成到基于 Spring Framework 的项目中。
值得一提的是,XFire 目前已经不再进行开发,其官方继任者是Apache CXF[2]。
XFire 的用法比较简单,首先在META-INF/xfire/services.xml中定义需要导出的服务,比如:
"1.0"encoding="UTF-8"?>
<beansxmlns="http://xfire.codehaus.org/config/1.0">
<service>
<name>WorkflowServicename>
<namespace>webservices.services.weaver.com.cnnamespace>
<serviceClass>weaver.workflow.webservices.WorkflowServiceserviceClass>
<implementationClass>weaver.workflow.webservices.WorkflowServiceImplimplementationClass>
<serviceFactory>org.codehaus.xfire.annotations.AnnotationServiceFactoryserviceFactory>
service>
beans>
这样weaver.workflow.webservices.WorkflowService就被认为是导出服务。
可以直接被客户端进行调用。调用方式主要是通过 SOAP 请求到 XFireServlet,例如调用上述服务可以发送 POST 请求到/services/WorkflowService:
"1.0"encoding="UTF-8"?>
<Body>
<getUserId>
<p>evilpanp>
<p>2333p>
getUserId>
Body>
表示以指定参数调用服务的getUserId方法。
SQL 注入
接下来回到漏洞本身,WorkflowService 服务的具体实现为WorkflowServiceImpl,例如其中的 getUserId 就是服务导出的一个方法,其具体实现为:
@Override
publicStringgetUserId(Stringvar1,Stringvar2){
if(Util.null2String(var2).equals("")){
return"-1";
}elseif(Util.null2String(var1).equals("")){
return"-2";
}else{
RecordSetvar3=newRecordSet();
var3.executeQuery("selectidfromHrmResourcewhere"+var1+"=?andstatus<4 ",var2);
return!var3.next()?"0":Util.null2s(var3.getString("id"),"0");
}
}
可以看到,一个教科书式的 SQL 注入就已经找到了。
Service 鉴权
现在漏洞点找到了,触发路径也找到了,可实际测试的时候发现这个接口有些特殊的鉴权,其鉴权逻辑为判断请求地址是否是内网地址,如果是的话就放行。
考虑到很多系统是集群部署的,且前面有一层或者多层负载均衡,因此实际请求服务的可能是经过反向代理的请求,此时客户端的真实 IP 只能通过X-Forward-For等头部获取。
这本来无可厚非,但是 HTTP 请求头是可以被攻击者任意设置的,因此 ecology 在此基础上进行了复杂的过滤,精简后的伪代码如下:
privateStringgetRemoteAddrProxy(){
Stringip=null;
StringtmpIp=null;
tmpIp=this.getRealIp(this.request.getHeaders("RemoteIp"),ipList);
if(ip==null||ip.length()==0||"unknown".equalsIgnoreCase(ip)){
ip=tmpIp;
}
booleanisInternalIp=IpUtils.internalIp(ip);
if(isInternalIp){
ipList.add(this.request.getRemoteAddr());
tmpIp=IpUtils.getRealIp(ipList);
if(!IpUtils.internalIp(tmpIp)){
ip=tmpIp;
}
}
returnip!=null&&ip.length()!=0&&!"unknown".equalsIgnoreCase(ip)?ip:null;
}
IpUtils#internalIp的判断更为复杂,连byte[]都出来了:
publicstaticbooleaninternalIp(Stringip){
if(ip!=null&&!ip.equals("127.0.0.1")&&!ip.equals("::1")&&!ip.equals("0000:1")){
if(ip.indexOf(":")!=-1&&ip.indexOf(":")==ip.lastIndexOf(":")){
ip=ip.substring(0,ip.indexOf(":"));
}
byte[]addr=(byte[])null;
if(isIpV4(ip)){
addr=textToNumericFormatV4(ip.trim());
}else{
addr=textToNumericFormatV6(ip.trim());
}
returnaddr==null?false:internalIp(addr);
}else{
returntrue;
}
}
publicstaticbooleaninternalIp(byte[]addr){
byteb0=addr[0];
byteb1=addr[1];
byteSECTION_1=true;
byteSECTION_2=true;
byteSECTION_3=true;
byteSECTION_4=true;
byteSECTION_5=true;
byteSECTION_6=true;
switch(b0){
case-84:
if(b1>=16&&b1<= 31){
returntrue;
}
case-64:
switch(b1){
case-88:
returntrue;
}
default:
returnfalse;
case10:
returntrue;
}
}
其逻辑是对 getRemoteAddrProxy 取出来的 IP,如果路径匹配webserviceList且 IP 匹配webserviceIpList前缀,就认为是内网地址的请求从而进行放过:
webserviceList=[
"/online/syncOnlineData.jsp",
"/services/",
"/system/MobileLicenseOperation.jsp",
"/system/PluginLicenseOperation.jsp",
"/system/InPluginLicense.jsp",
"/system/InMobileLicense.jsp"
];
webserviceIpList=[
"localhost",
"127.0.0.1",
"192.168.",
"10.",
"172.16.",
"172.17.",
"172.18.",
"172.19.",
"172.20.",
"172.21.",
"172.22.",
"172.23.",
"172.24.",
"172.25.",
"172.26.",
"172.27.",
"172.28.",
"172.29.",
"172.30.",
"172.31."
]
根据上面的代码,你能发现鉴权绕过的漏洞吗?
Fuzzing
也许对代码比较敏感的审计人员可以通过上述鉴权代码很快发现问题,但说实话我一开始并没有找到漏洞。于是我想到这个鉴权逻辑是否能单独抽离出来使用 Fuzzing 的思路去进行自动化测试。
之前发现 Java 也有一个基于 libFuzzer 的模糊测试框架Jazzer[3],但是试用之后发现比较鸡肋,因为和二进制程序会自动 Crash 不同,Java 的 fuzz 需要自己指定 Sink,令其在触达的时候抛出异常来构造崩溃。
虽然说没法发现通用的漏洞,但是对于现在这个场景来说正好是绝配,我们可以将目标原始的鉴权代码抠出来,然后在未授权通过的时候抛出一个异常即可。构建的 Test Harness 代码如下:
publicstaticvoidfuzzerTestOneInput(FuzzedDataProviderdata){
Stringpoc=data.consumeRemainingAsString();
fuzzIP(poc);
}
publicstaticvoidfuzzIP(Stringpoc){
if(containsNonPrintable(poc))return;
XssRequestWeblogicx=newXssRequestWeblogic();
Stringout=x.getRemoteAddr(poc);
booleancheck2=check2(out);
if(check2){
thrownewFuzzerSecurityIssueHigh("FoundIP["+poc+"]");
}
}
publicstaticbooleancheck2(Stringipstr){
for(Stringip:webserviceIpList){
if(ipstr.startsWith(ip)){
returntrue;
}
}
returnfalse;
}
其中精简了一些 ecology 代码中读取配置相关的依赖,将无关的逻辑进行手动剔除。
编译好代码后,使用以下命令开始进行 fuzz:
$./jazzer--cp=target/Test-1.0-SNAPSHOT.jar--target_class=org.example.App
不多一会儿,就已经有了一个成功的结果!
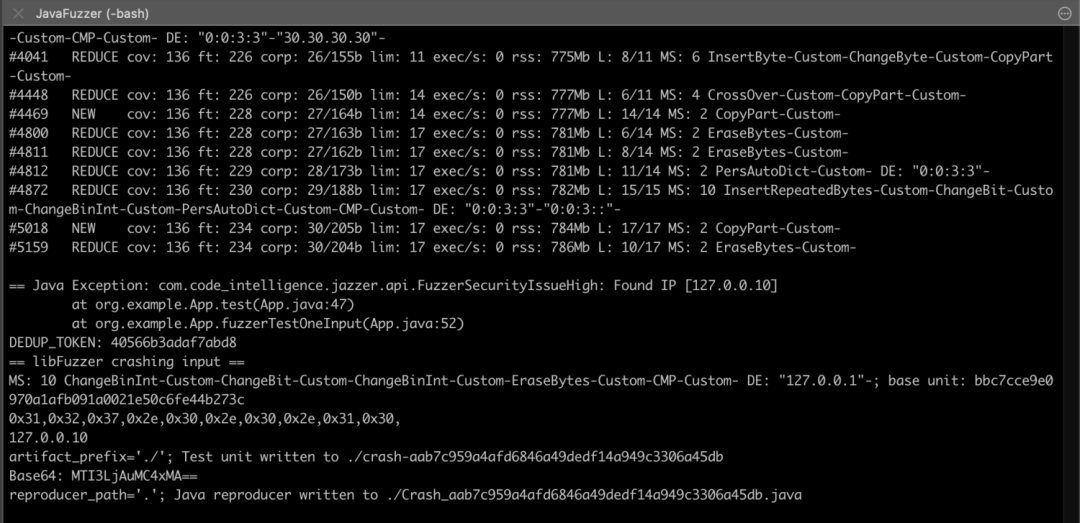 fuzz.png
fuzz.png
可以看到图中给出了127.0.0.10这个 payload,可以触发 IP 鉴权的绕过!反过来分析这个 PoC,可以发现之所以能绕过是因为webserviceIpList只检查了前缀,而127.0.0.10可以在internalIp返回False,即认为不是内部 IP,但实际上 webserviceIpList 却认为是内部 IP,从而导致了绕过。
如果只是从代码上去分析的话,可能一时半会并不一定能发现这个问题,可是通过 Fuzzing 在覆盖率反馈的加持下,却可以在几秒钟之内找到正解,这也是人工审计无法比拟的。
漏洞补丁
通过 IP 的鉴权绕过和 XFire 组件的 SQL 注入,笔者实现了多套前台的攻击路径,并且在 HW 中成功打入多个目标。因为当时提交的报告中带了漏洞细节,因此这个漏洞自然也就被官方修补了。如果没有公开的话这个洞短期也不太会被撞到。
漏洞修复的关键补丁如下:
diff--gita/src/weaver/security/webcontainer/IpUtils.javab/src/weaver/security/webcontainer/IpUtils.java
index6b3d8efc..e7482511100644
---a/src/weaver/security/webcontainer/IpUtils.java
+++b/src/weaver/security/webcontainer/IpUtils.java
@@-48,12+48,16@@publicclassIpUtils{
}
publicstaticbooleaninternalIp(Stringip){
-if(ip!=null&&!ip.equals("127.0.0.1")&&!ip.equals("::1")&&!ip.equals("0000:1")){
+if(ip==null||ip.equals("127.0.0.1")||ip.equals("::1")||ip.equals("0000:1")){
+returntrue;
+}elseif(ip.startsWith("127.0.0.")){
+returntrue;
+}else{
if(ip.indexOf(":")!=-1&&ip.indexOf(":")==ip.lastIndexOf(":")){
ip=ip.substring(0,ip.indexOf(":"));
}
其中把 equals 换成了 startsWith,并且还过滤了我们之前使用的 WorkflowService 组件。当然还是沿袭 ecology 一贯的漏洞修复原则,不改业务代码,只增加安全校验,这也是对历史遗留问题的一种妥协吧。
总结
-
•对于 Java 这样的内存安全编程语言也是可以 fuzz 的,只不过目的是找出逻辑漏洞而不是内存破坏;
-
•漏洞挖掘初期花时间投入到代码审计中是有必要的,有助于理解项目整体结构并在后期进行针对性覆盖;
-
•漏洞挖掘的时候重点关注边界的系统和服务,处于信任边界之外的组件更有可能过于信任外部输入导致安全问题;
-
•对于看起来很复杂的数据处理模块,可以充分利用 Fuzzing 的优势,帮助我们快速找出畸形的 payload;
-
•模块化 Fuzzing 的难点在于抽离代码并构建可编译或者可以独立运行的程序,即构建 Test Harness,跑起来测试用例你就已经成功了 90%;
-
•软件开发和漏洞挖掘正好相反。开发者会出于厌恶情绪刻意避开复杂的历史遗留代码,而这些代码却是更可能出现问题的地方。因此安全研究员要学会克服自己的厌恶情绪,做到 —— “明知山有屎,偏向屎山行”。
-
自动化
+关注
关注
29文章
5598浏览量
79431 -
编程语言
+关注
关注
10文章
1947浏览量
34826 -
代码
+关注
关注
30文章
4803浏览量
68759
原文标题:总结
文章出处:【微信号:哆啦安全,微信公众号:哆啦安全】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
灵玖软件:NLPIR智能挖掘系统专注中文处理
AlphaFuzzer漏洞挖掘工具的使用
数据挖掘算法有哪几种?
数据挖掘浅析
关联规则挖掘在数据录入、校对系统中的应用
怎么学习数据挖掘_如何系统地学习数据挖掘
代码实例及详细资料带你入门Python数据挖掘与机器学习
浅析嵌入式数据挖掘模型应用到银行卡业务中的相关知识
某CMS的命令执行漏洞通用挖掘思路分享






 工商网监
工商网监
评论