 PCIe相关问题解答
PCIe相关问题解答

PCIe设备的数据流有哪些,分别是什么场景?
PCIe设备的数据流主要为4大类:
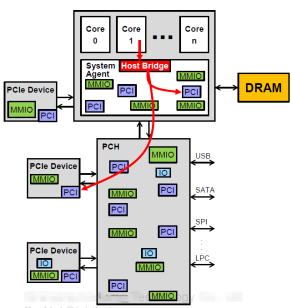
1.CPU发起的,访问PCIe设备配置空间的数据流。这种数据流主要是BIOS/Linux PCIedriver 对设备进行初始化、资源分配时,读写配置空间的。包括PCIe 枚举,BAR空间分配, MSI 分配等。 设备驱动通过 pci_wirte_config() / pci_read_config() 发起配置空间访问。 lspci /setpci 也是对应到配置空间访问。
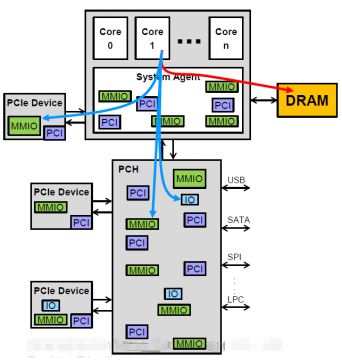
2.CPU发起的,访问PCIe设备MMIO/IO的数据流。将Bar空间mmap 到系统地址空间后,设备驱动可通过地址访问PCIe设备的 Bar/ MMIO 空间。 一般的,设备会将特定的寄存器和存储实现在MMIO空间内。CPU可使用 iowrite32() / ioread32() 等方式访问 MMIO空间。这是一种效率较低的PCIe使用方式.
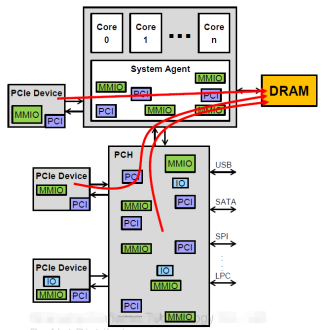
3.PCIe设备发起的,访问 HostMemory 的 DMA数据流。这种数据流由PCIe设备的DMAEngine 发起,是一种常见的、高性能的PCIe数据流。CPU通过配置 PCIe设备内的DMAEngine (通过MMIO寄存器),启动设备PCIeDMA。网卡,GPU等PCIe设备,数据通路均有PCIeDMA完成。
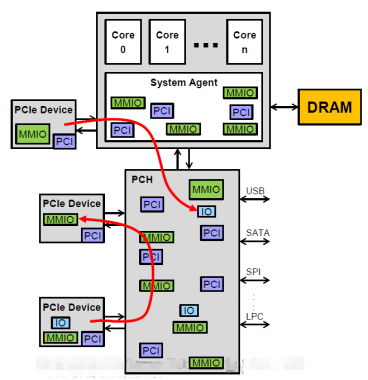
4.PCIe设备发起的,访问PCIe设备MMIO/IO的数据流, 亦称P2P (Peer to Peer)。同(3)类似,也是利用PCIe设备的DMAengine, 但是数据访问的是其他PCIe设备的MMIO地址空间而非HostMemory. CPU须配置桥片端口路由地址。 GDR (GPU directRDMA) 就是利用这种数据流,避免主机内存的数据拷贝。
CPU访问设备内存(Bar空间)和访问主机内存,有什么不同?
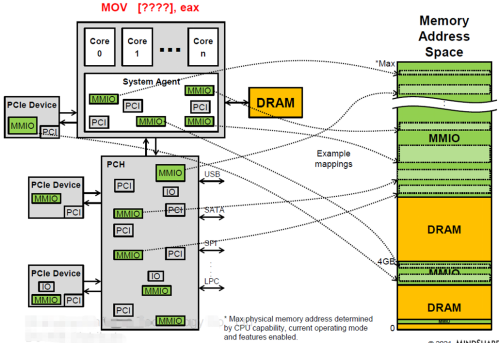
Prefetchable MMIO 映射到系统地址空间后,软件可以通过地址对PCIeMMIO空间进行直接访问(CPU使用MOV指令),这一点与系统内存访问在操作上是一致的。
RootComplex 会根据CPU访问的地址决定数据访问路由,对于系统内存地址空间,数据会被路由到iMC(integrated Memory Controller) 访问DDR;对于MMIO地址空间,数据会被路由到HostBridge 转换为 TLP发起对设备的PCIe通信。
一般的,HostMemory 分配都是Cacheable(writeback) 的,而 MMIO通常是Uncacheable的,加之两者带宽和通信机理的不同,导致了CPU使用地址直接访问PCIeMMIO空间无法达到访问系统内存的性能,也无法用满PCIe带宽。使用memcpy() 在HostMemory 和MMIO 地址拷贝数据也是一种低效方式。
对于连续的MMIO空间访问,可以通过支持writecombine的方式( mmap_wc() )来提升性能。
为什么需要使用PCIe DMA,在设备与主机间搬运数据?
PCIe DMA 能够实现高性能的数据搬运。
1.CPU仅需要配置DMAEngine, 大块的数据搬运过程无需CPU参与,CPU占用率低;
2.DMAEngine 是全硬件化的通信方式,TLPpayload 大overhead小,PCIe链路使用率高;
3.支持descriptor的DMA能够实现用户态数据的零拷贝,减小内存带宽消耗;
4.支持多队列的DMA,能够提高系统并行度,支持多核,多进程应用,硬件解决IO抢占和调度问题,软件编程简单;
如何使用PCIe设备的中断?
PCIe协议定义了三种中断:INTx (legacy), MSI, MSIX
1.INTx中断是相对古老的PCIe设备中断方式,整个系统仅支持8个INTx 中断,所有设备共用。PCIe中的INTx 中断是通过PCIemessage发送到 switch和 IOAPIC的。CPU收到 IOAPIC转发到 localAPIC 的 INTx 中断后,需要查询ISR确定中断源设备,并进一步查询中断含义,才能执行中断处理函数。中断数量少,中断查询复杂,响应延迟大,与数据流不保序等问题的存在,是INTx的主要缺陷。
2.MSI是实现在配置空间的消息中断,每个PCIefunction可支持最多32个MSI中断。MSI中断是一笔PCIe写报文,向APIC地址域写入特定的数据,触发CPU中断。因为其通过PCIewriteTLP 实现,中断与业务数据的保序性容易实现,硬件处理RacingCondition的代价更小。MSI中断可以具备特定的含义,设备之间不耦合,中断响应快。
3.MSIx是实现在Bar空间的消息中断,优点与MSI类似,但其数量支持更多,每个function最多可以支持2K条中断向量。
MSI和MSIx 是目前主流的中断实现方式,在虚拟化的场景下,中断可以通过IOMMU 实现remap和 posting, 进一步提升系统性能。
网卡接收方向性能低,进行调优有哪些思路?
网卡收包性能性能调优,需先识别出性能瓶颈,可通过performance监控工具(如IntelPCM),查看 CPU利用率,内存带宽使用,PCIe流量等。
一般的,优化方向包括:
1.确定NUMA的亲和性,保证CPU/Memory/PCIe 三者的亲和性
2.确定PCIe全链路的带宽匹配,确保内存带宽(读+写双向)有余量
4.查看并打开IDO/RO (需注意应用场景无保序风险)
5.DMAEngine 参数的调优,Batch操作的阈值配置(队列doorbell, completion notify等)
6.中断频率的调优和控制(一般在20K/100k 每秒,需结合应用和CPU)
7.DDIO和 cacheable /uncacheable 内存空间的分配
具体原理和操作可参考课程中的有关介绍。
审核编辑:汤梓红
-
cpu
+关注
关注
68文章
11364浏览量
226319 -
Linux
+关注
关注
88文章
11850浏览量
219774 -
PCIe
+关注
关注
16文章
1496浏览量
89111 -
dma
+关注
关注
3文章
584浏览量
106365 -
数据流
+关注
关注
0文章
131浏览量
16590
原文标题:PCIe 课程典型问题解答
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录





评论