 思科强化基于以太网的AI网络战略
思科强化基于以太网的AI网络战略
当地时间 9 月 12 日,思科正式宣布已停止生产其 HyperFlex 超融合基础设施(HCI)产品。
思科表示,做出这个决定有两方面的考虑。一方面是不断变化的客户需求和市场形势,让自己重新考虑了针对这款设备的计划;另一方面是超大规模计算公司开始涉足这个市场。例如,甲骨文刚刚将其本地云精简为一款可与大型超融合设备竞争的产品。
思科没有详细解释为何停止 HyperFlex,只是说,这是为客户、合作伙伴和员工提供更有力的支持。思科发言人称,思科“仍然致力于简化混合多云运营”。但实现这一目标背后出力的是 Nutanix 而不是思科。两家公司最近宣布合作,在思科硬件上运行 Nutanix 的软件堆栈,思科出售最终的设备并获得佣金。
思科承诺为 HyperFlex 客户提供五年的支持和服务。不过,对于使用 HyperFlex 运行 VMware ESXi 虚拟机管理程序的客户来说,这项服务很复杂。思科不会在其硬件上认证未来版本的 ESXi ,也就是说 VMware 客户要么在 ESXi 8.0 退出支持后依旧使用,要么运行不受支持的代码。
另一种选择是完全放弃 HyperFlex,思科已经针对这种情况发布了一份白皮书。亦或是清理 HyperFlex 并将其运行的机器用作普通 UCS 服务器使用。为了让该平台的用户有时间做好准备。思科将在 2024 年 3 月 12 日之前继续接受 HyperFlex 硬件和软件的订单,并尝试在同年 6 月 10 日之前全部发货。
厌倦了成为“others”
思科之所以放弃 HyperFlex,可能是因为它的销量始终没能达到让思科满意。
IDC 2022 年底的数据显示,在该市场中,VMware 占据了绝对优势的 41% 份额, Nutanix 占 25%,排名第三的HPE 占 7.3% ,这使得思科只能“屈居”于“其他”类别中。
思科一直在大肆宣传自己在刀片服务器领域的实力——UCS 服务器占据利基市场,但实际上从未撼动过戴尔、 HPE 或联想等其他玩家的地位。HyperFlex 对于改变这种局面似乎帮助不大,在思科将大部分工具转向云和订阅模式的时期,反而给思科带来了维护管理软件堆栈的负担。
鉴于这块业务始终无法做出成绩,而超大规模云又对服务器制造商构成威胁,混合云又减少了对本地设备的需求,这也不难看出为什么思科决定让 HyperFlex 的时代提前结束了。
不过思科没有错过这轮AI网络的风口,此前就制定了一系列基于以太网的AI网络战略。
思科基于以太网的AI网络战略
思科云网络、Nexus和ACI产品线产品管理副总裁Thomas Scheibe表示:“各组织正坐拥海量数据,他们正在研究人工智能技术,试图让这些数据更容易访问,并更快地从中获得价值。客户想知道他们需要在网络方面做什么,以便能运行其庞大的 GPU 集群并处理大量数据。对于大多数客户来说,以太网将是答案。”
为此,思科制定了一份蓝图,定义组织如何使用现有数据中心以太网来支持人工智能工作负载。思科人工智能蓝图的核心组件是其 Nexus 9000 数据中心交换机,这些交换机的每个 ASIC 高达 25.6Tbps 的带宽,并且拥有可用的硬件和软件功能,可提供所需的低延迟、拥塞管理机制和遥测, 可提供 AI/ML 集群所需的极高吞吐量。
此外,最近思科在面向AI的新型高端可编程Silicon One处理器取得了全新进展,芯片产品家族又添新成员。全新处理器包括Silicon One G202和Silicon One G200,能够实现25.6Tbps和51.2Tbps的转发性能。两款处理器建立在 Cisco Silicon One G100统一架构的技术基础之上实现突破创新。针对高带宽、超大规模数据中心以及 AI/ML高性能网络进行了全面优化,构建无损、低延迟和高能效的AI数据中心。
RoCEv2 作为 AI 集群的传输
RDMA是众所周知的用于高性能计算和存储网络环境的技术。RDMA 的优点是在内存到内存级别的计算节点之间实现高吞吐量和低延迟的信息传输,而不会给 CPU 带来负担。该传输功能被卸载到网络适配器硬件以绕过操作系统软件网络堆栈。
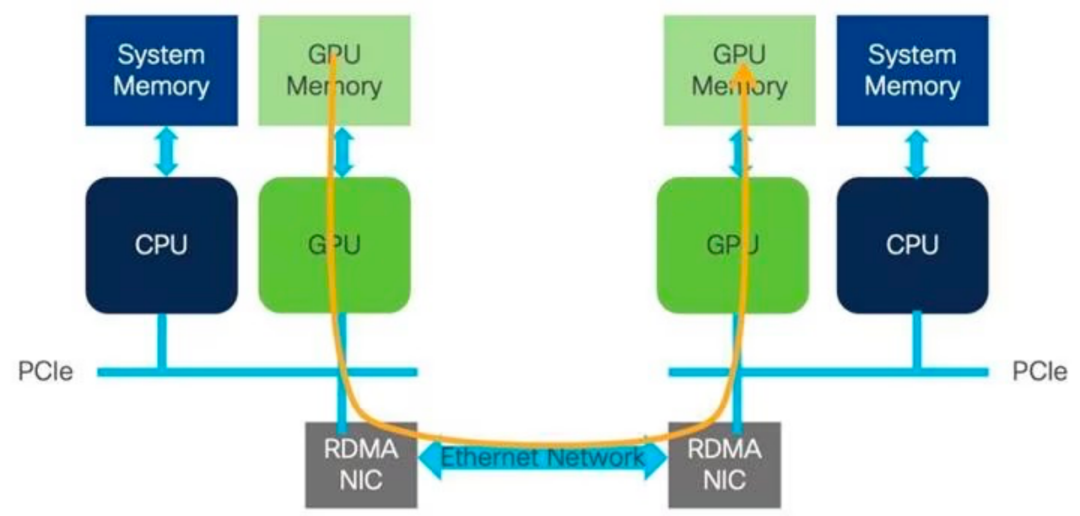
RDMA 提供了多种网络传输实现,包括InfiniBand 和基于以太网的RoCE。
InfiniBand (IB) 提供高吞吐量和 CPU 旁路,从而降低延迟。InfiniBand 还在协议中内置了拥塞管理,这些优势使 InfiniBand 成为高性能计算传输的首选。对于需要 HPC 工作负载的企业网络,InfiniBand 设计了一个单独的网络以利用其所有优势,但这些专门构建的网络给企业带来了额外的成本和复杂性。
RoCE 是 InfiniBand 的以太网转发扩展。RoCEv2 将 IB 传输封装在以太网、IP 和 UDP 报头中,因此可以通过以太网进行路由。ROCEv2是一种高性能网络计算技术,可以让数据直接在两个设备的内存之间传输,而无需涉及服务器CPU。它允许通过单个连接同时传输或路由多个数据包,从而减少延迟和复杂性并提高吞吐量。

RoCE 和 RoCEv2 帧格式,其中 RoCEv2 IP 和 UDP 报头位于以太网之上
以太网在企业数据中心中无处不在,网络管理员对以太网非常熟悉,这是该技术的一大优势。除此之外,经济性和创建承载常规企业流量以及 RDMA 工作负载的“融合”结构对客户非常有吸引力,这也是在数据中心网络中实施 RoCEv2 的原因之一。
RoCEv2 需要无损传输,可以通过使用显式拥塞通知 (ECN) 和优先级流量控制 (PFC) 拥塞避免算法来实现。
AI集群需要无损网络
对于RoCEv2传输,网络必须提供高吞吐量和低延迟,同时避免在发生拥塞的情况下流量下降。Cisco Nexus 9000 通过 ECN 和 PFC 中的软件和硬件遥测在无损网络中提供支持和可见性。
显式拥塞通知 (ECN)
在需要端到端传播拥塞信息的情况下,可以使用ECN进行拥塞管理。ECN 在 IP 报头服务类型 (TOS) 字段内的 2 个最低有效位内经历拥塞的网络节点中进行标记。当接收方收到 ECN 拥塞经历位设置为 0x11 的数据包时,它会生成拥塞通知数据包 (CNP) 并将其发送回发送方。当发送方收到拥塞通知时,它会减慢与该通知匹配的流量。这种端到端流程构建在数据路径中,因此是管理拥塞的有效方法。
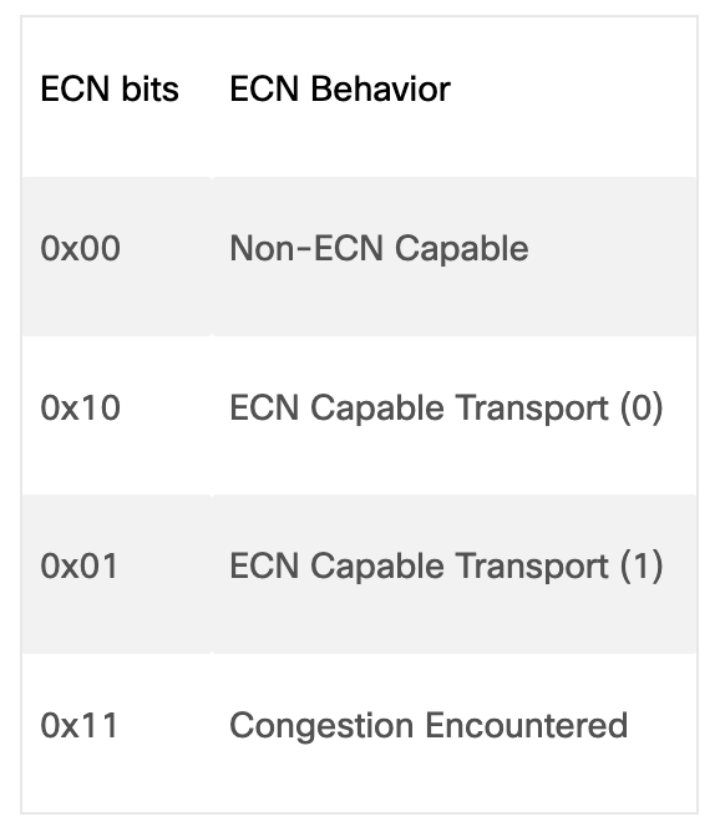
网络设备和终端主机使用的 ECN 位值
ECN 本质上是通过监控网络拥塞或其他可能导致数据包丢失的情况,并限制网络以确保这种情况不会发生,从而实现无损以太网。无损以太网不仅是AI网络的关键要求,也是当今 VOIP 或视频环境的关键要求。
优先流量控制 (PFC)
优先级流量控制在第 2 层网络中引入,作为实现无损以太网的主要机制。流量控制由第 2 层帧中的服务类别 (COS) 值驱动,并使用暂停帧和暂停机制来指示和管理拥塞。然而,构建可扩展的第 2 层网络对于网络管理员来说是一项具有挑战性的任务。因此,网络设计大多演变为第 3 层路由结构。
由于 RoCEv2 可以路由,因此 PFC 被调整为与DSCP 优先级配合使用,以发出网络中路由跳之间的拥塞信号。DSCP 是一种用于对 IP 网络上的网络流量进行分类的机制。它使用 IP 报头中的 6 位差分服务字段来进行数据包分类。使用第 3 层标记使流量能够跨路由器维护分类语义。由于 PFC 帧使用链路本地寻址,因此网络设备可以接收并执行路由和交换流量的暂停信令。PFC 从拥塞位置到流量源逐跳传输。此逐步行为可能需要一些时间才能传播到源。PFC 用作管理 RoCEv2 传输拥塞的主要工具。
Cisco Nexus 9000 交换机支持 PFC 拥塞管理和 ECN 标记,通过加权随机早期检测 (WRED) 或近似公平丢弃 (AFD) 来指示网络节点中的拥塞情况。
PFC 和 ECN 相辅相成,提供最高效的拥塞管理。它们共同在拥塞期间提供最高的吞吐量和最低的延迟损失,在构建无损以太网中发挥着重要作用。总而言之,这些技术可以使以太网能够对某些工作负载进行优先级排序,例如人工智能工作负载,它们不能容忍任何丢包,并且即使出现拥塞也始终获得网络优先级。
Silicon One
思科AI网络基础设施的另一个要素是其新型高端可编程Silicon One处理器,该处理器旨在为企业提供大规模 AI/ML基础设施。
思科将 5 纳米 51.2Tbps Silicon One G200 和 25.6Tbps G202 添加到其Silicon One 系列中。这些处理器可以针对单个芯片组的路由或交换进行定制,从而无需为每个网络功能使用不同的芯片架构。这是通过通用操作系统、P4 可编程转发代码和 SDK 来完成的。
思科表示,这些新设备位于 Silicon One 系列的顶端,将带来网络增强功能,使其成为要求苛刻的 AI/ML 部署或其他高度分布式应用的理想选择。Silicon One 系统的核心是支持增强的以太网功能,例如改进的流量控制、拥塞感知和避免。该系统还包括先进的负载平衡功能和“packet-spraying”功能,可将流量分散到多个 GPU 或交换机上,以避免拥塞并改善延迟。思科表示,基于硬件的链路故障恢复还有助于确保网络以最高效率运行。
结合这些增强型以太网技术并进一步推进,最终使客户能够建立思科所谓的Scheduled Fabric。思科表示,在Scheduled Fabric中,芯片物理组件、光学器件、交换机像一个大型模块化机箱一样连接在一起,并相互通信,以提供最佳的调度行为和更高的带宽吞吐量。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19156浏览量
229062 -
以太网
+关注
关注
40文章
5373浏览量
171046 -
交换机
+关注
关注
21文章
2622浏览量
99221 -
人工智能
+关注
关注
1791文章
46833浏览量
237483 -
GPU芯片
+关注
关注
1文章
303浏览量
5775
原文标题:思科新动作:放弃 HyperFlex超融合,强化基于以太网的AI网络战略!
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
以太网与光纤网络的优劣比较
以太网速率对网络性能的影响
以太网端口的类型和特性
以太网要怎么连接
工业以太网和普通以太网区别在哪
工业以太网的基本原理及优势
新思科技推出业界首个1.6T以太网IP整体解决方案
新思科技正式推出业界首个1.6T以太网IP整体解决方案
新思科技发布1.6T以太网IP集成方案,助推AI与HPC网络芯片市场发展
以太网怎么连接 以太网组网结构分析





 工商网监
工商网监
评论