 开源大模型Falcon(猎鹰) 180B发布 1800亿参数
开源大模型Falcon(猎鹰) 180B发布 1800亿参数
世界最强开源大模型 Falcon 180B 忽然火爆全网,1800亿参数,Falcon 在 3.5 万亿 token 完成训练,性能碾压 Llama 2,登顶 Hugging Face 排行榜。
今年5月,TII(阿联酋阿布扎比技术创新研究所)推出了号称是 “史上最强的开源大语言模型”——Falcon(猎鹰)。虽然 Falcon 的参数比 LLaMA 小,但性能却更加强大。
此前,Falcon 已经推出了三种模型大小,分别是1.3B、7.5B、40B。据介绍,Falcon 180B 是 40B 的升级版本,Falcon 180B 的规模是 Llama 2 的 2.5 倍,且可免费商用。 Falcon 180B在 Hugging Face 开源大模型榜单上被认为是当前评分最高的开放式大模型,其评分68.74,Meta 的 LlaMA 2以 1.39 的分数差距排名第二。
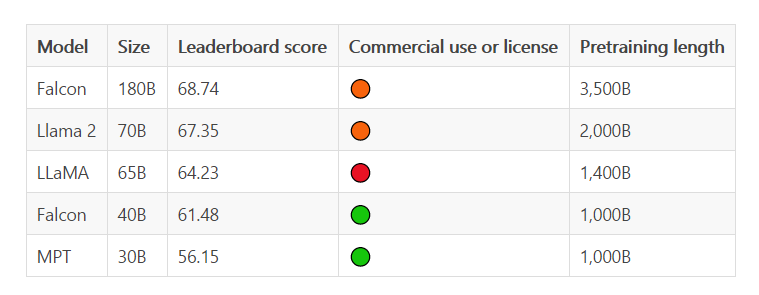
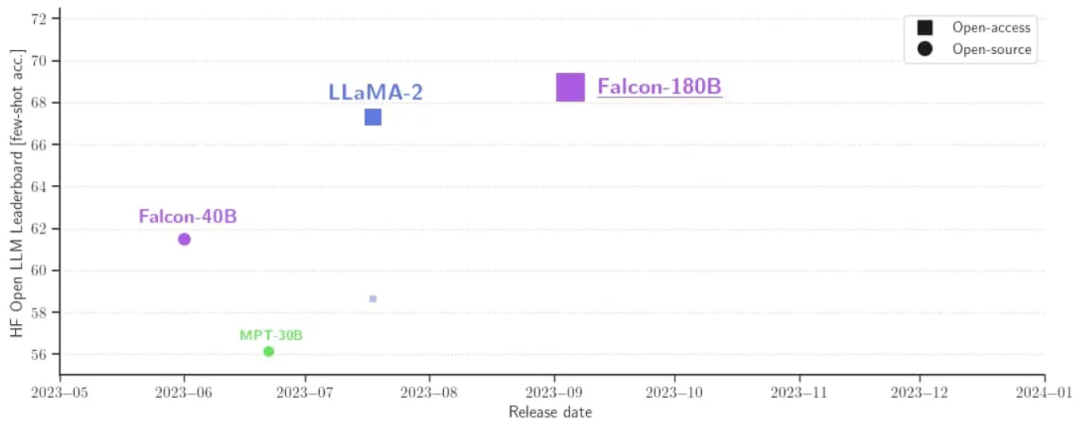
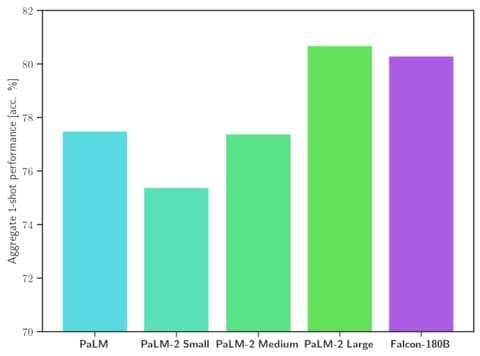
据官方介绍,Falcon 180B 是当前最好的开源大模型。 其在 MMLU 上 的表现超过了 Llama 2 70B 和 OpenAI 的 GPT-3.5。在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC 及 ReCoRD 上与谷歌的 PaLM 2-Large 不相上下。
目前大家可以通过以下地址进行Demo 体验:https://hf.co/spaces/HuggingFaceH4/falcon-chat
硬件要求
| 类型 | 种类 | 最低要求 | 配置示例 | |
|---|---|---|---|---|
| Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB |
Prompt 格式
其基础模型没有 Prompt 格式,因为它并不是一个对话型大模型也不是通过指令进行的训练,所以它并不会以对话形式回应。预训练模型是微调的绝佳平台,但或许你不该直接使用。其对话模型则设有一个简单的对话模式。
System: Add an optional system prompt here User: This is the user input Falcon: This is what the model generates User: This might be a second turn input Falcon: and so on
从 Transfomers 4.33 开始,可以在 Hugging Face 上使用 Falcon 180B 并且使用 HF 生态里的所有工具。但是前提是请确保你已经登录了自己的 Hugging Face 账号,并安装了最新版本的 transformers:
pip install --upgrade transformers huggingface-cli loginbfloat16 以下是如何在bfloat16中使用基础模型的方法。Falcon 180B 是一个大型模型,所以请注意它的硬件要求(硬件要求如上所示)。
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "My name is Pedro, I live in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)
这可能会产生如下输出结果:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video. I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.使用 8 位和 4 位的 bitsandbytes Falcon 180B 的 8 位和 4 位量化版本在评估方面与bfloat16几乎没有差别!这对推理来说是个好消息,因为你可以放心地使用量化版本来降低硬件要求。请记住,在 8 位版本进行推理要比 4 位版本快得多。要使用量化,你需要安装 “bitsandbytes” 库,并在加载模型时启用相应的标志:
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
**load_in_8bit=True,**
device_map="auto",
)
对话模型 如上所述,为跟踪对话而微调的模型版本使用了非常直接的训练模板。我们必须遵循同样的模式才能运行聊天式推理。作为参考,你可以看看聊天演示中的format_prompt函数:
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"System: {system_prompt}
"
for user_prompt, bot_response in history:
prompt += f"User: {user_prompt}
"
prompt += f"Falcon: {bot_response}
"
prompt += f"User: {message}
Falcon:"
return prompt
如你所见,用户的交互和模型的回应前面都有User:和Falcon:分隔符。我们将它们连接在一起,形成一个包含整个对话历史的提示。这样就可以提供一个系统提示来调整生成风格。 -
开源
+关注
关注
3文章
3342浏览量
42490 -
大模型
+关注
关注
2文章
2442浏览量
2690
原文标题:1800亿参数,性能碾压Llama 2,世界最强开源大模型Falcon 180B发布
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Meta重磅发布Llama 3.3 70B:开源AI模型的新里程碑
中国移动与中国石油发布700亿参数昆仑大模型
AMD发布10亿参数开源AI模型OLMo
腾讯发布开源MoE大语言模型Hunyuan-Large
Meta即将发布超强开源AI模型Llama 3-405B
英伟达开源Nemotron-4 340B系列模型,助力大型语言模型训练
智谱AI发布全新多模态开源模型GLM-4-9B
通义千问开源千亿级参数模型
谷歌发布用于辅助编程的代码大模型CodeGemma





 工商网监
工商网监
评论