 STM32L4R9的QuadSPI Flash通讯速率不理想
STM32L4R9的QuadSPI Flash通讯速率不理想
1. 引言
客户反应STM32L4R9 同QSPI Flash 通讯,测出来的读取速率为10MB/s, 和理论值相差较大。
2.问题分析
按照客户的时钟配置和STM32L4R9 的数据手册中的数据,OSPI 读数速率为10MB/s肯定存在问题。同时我们也可以在AN4760 应用手册中看到如下说明:

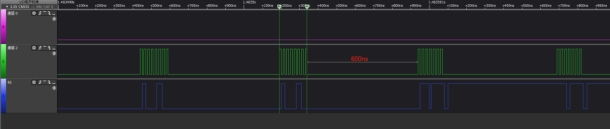
在客户系统中,IO0~IO3的4线通讯模式下信号波形如下图,可以看出每经过8 个CLK周期就有很长一段时间的延时。如果提高CPU的主频,这个延时会缩短,但客户测到最短的延时也有200ns,并且一直存在:
3.问题解决
从客户测试波形上看,由于是4条数据线,因此8个clock正好是4bytes,也就是32bits数据。怀疑STM32L4R9 QSPI在DMA通讯中,读到一个word(32bits)数据后需要在内部做一定的数据处理,造成时间延迟。
分析代码发现,DMA设置的是byte传输模式,如下面代码:
#define BUFFERSIZE (COUNTOF(aTxBuffer) - 1)
hdma.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
STM32L4R9是Cortex-M4 内核,系统总线是32bits的,怀疑是在32bit总线上传输byte数据会降低效率,造成延迟,于是修改代码如下:
示例代码在下面路径,需要使用附件中的main.c文件替换掉下面文件中的main.c:
…STM32Cube_FW_L4_VxxProjects32L4R9IDISCOVERYExamplesOSPIOSPI_NOR_ReadWrite_DMAEWARM
另外程序中做如下改动:
#define BUFFERSIZE 1024 // (COUNTOF(aTxBuffer) - 1)
hdma.Init.PeriphDataAlignment = DMA_PDATAALIGN_WORD;
hdma.Init.MemDataAlignment = DMA_PDATAALIGN_WORD;
配置时请留意OSPIHandle.Init.FifoThreshold = 4; //也需要4的倍数。
修改代码后进行测试,代码读 4096bytes的图像(1026 words),发现每个word数据中间的延迟已经没有了。之前速度提不上去的问题是DMA byte设置引起,因为STM32L4R9是32bits系统,使用8bits传输会降低效率,需要改为DMA 32bits配置就OK了。图形数据传输的总字节数也要设置为4的倍数,不足的需要补齐。
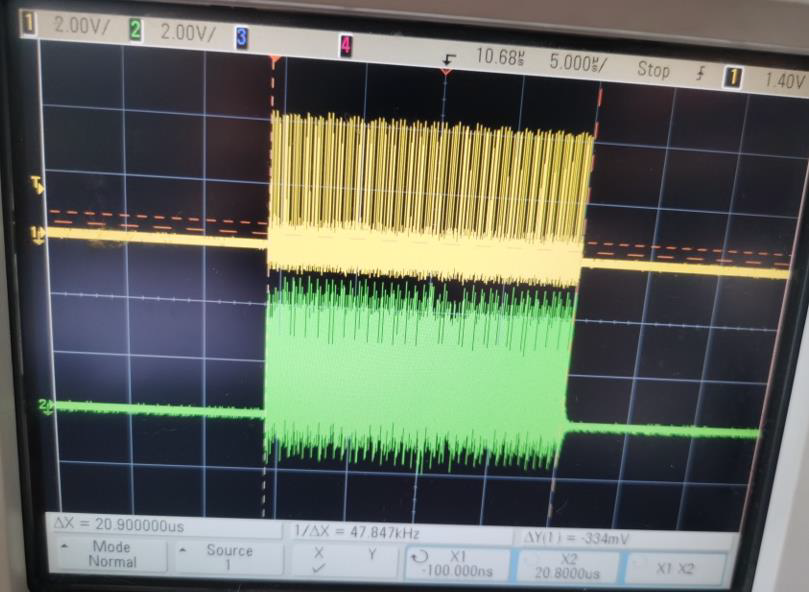
DMA改为word设置后数据传输时没有延迟
4. 小结
对32位系统来说,使用byte的数据传输在一些情况下会降低效率,建议对32bits系统使用32bits的数据传输方式。
来源:STM32单片机
-
FlaSh
+关注
关注
10文章
1633浏览量
147934 -
cpu
+关注
关注
68文章
10853浏览量
211561 -
通讯
+关注
关注
9文章
902浏览量
34887 -
总线
+关注
关注
10文章
2877浏览量
88050
发布评论请先 登录
相关推荐
用STM32L4R9驱动480*800的LCD屏幕,结果屏幕刷新看起来是逐行进行,刷新速度较慢,是否正常?
使用STM32L4R9单片机开发板,DfuSeDemo无法检测到设备的原因?
STM32L4R9复位标志始终为0为什么会这样
探索板上停止模式下的STM32L4R9功耗数据与电气特性不匹配怎么处理?
请问如何在STM32L4R9上实现CANOpen协议?
STM32L4R9 LQFP100可以支持多路复用hyperbus ram/flash设备吗?
如何将SPI与STM32L4R9探索板一起使用?
STM32L4R9芯片的图形加速器DMA2D实例使用
基于STM32L4R9I-DISCO的低功耗系统设计
利用QuadSPI外扩串行NOR Flash的实现

应用笔记 | STM32L4R9 的QuadSPI Flash 通讯速率不理想






 工商网监
工商网监
评论