 CCV 2023 | SparseBEV:高性能、全稀疏的纯视觉3D目标检测器
CCV 2023 | SparseBEV:高性能、全稀疏的纯视觉3D目标检测器
本文介绍在3D 目标检测领域的新工作:SparseBEV。我们所处的 3D 世界是稀疏的,因此稀疏 3D 目标检测是一个重要的发展方向。然而,现有的稀疏 3D 目标检测模型(如 DETR3D[1],PETR[2] 等)和稠密 3D 检测模型(如 BEVFormer[3],BEVDet[8])在性能上尚有差距。针对这一现象,我们认为应该增强检测器在 BEV 空间和 2D 空间的适应性(adaptability)。
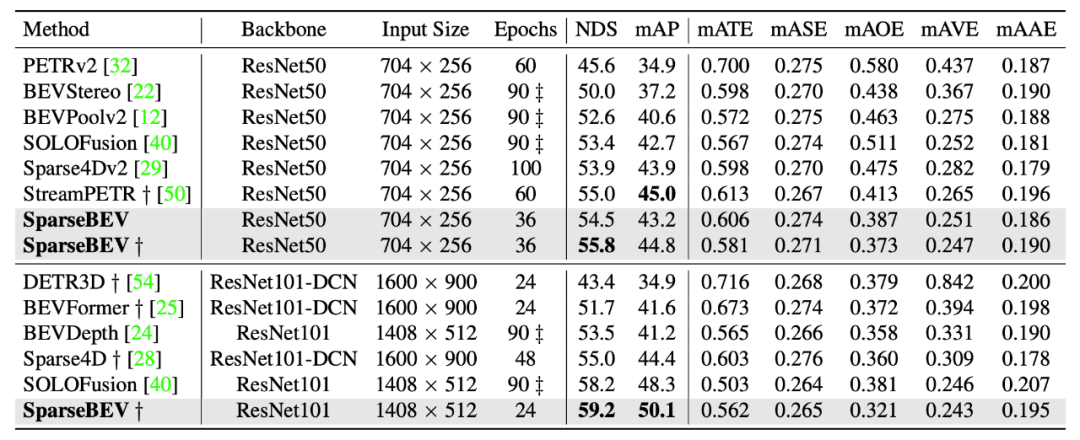
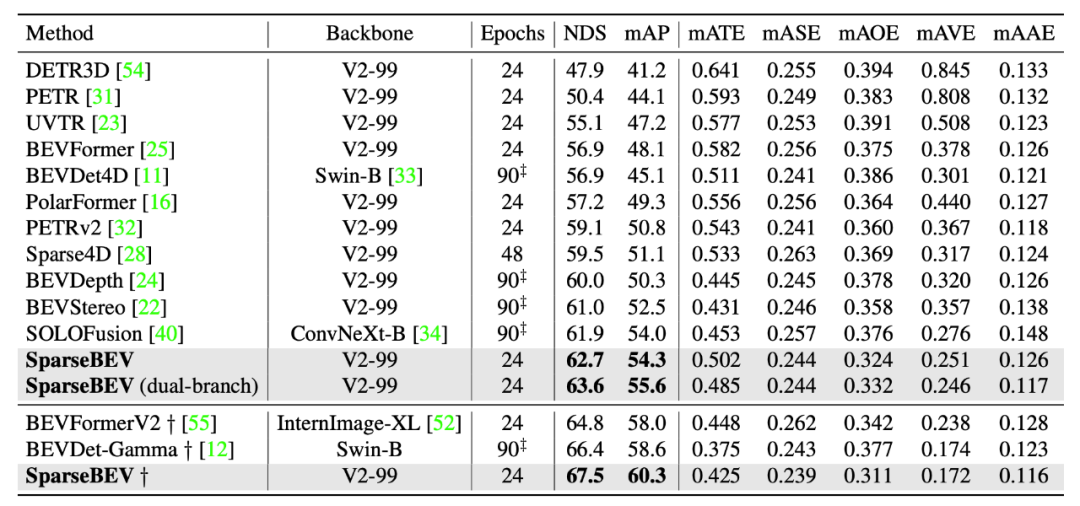
基于此,我们提出了高性能、全稀疏的 SparseBEV 模型。在 nuScenes 验证集上,SparseBEV 在取得 55.8 NDS 性能的情况下仍能维持 23.5 FPS 的实时推理速度。在 nuScenes 测试集上,SparseBEV 在仅使用 V2-99 这种轻量级 backbone 的情况下就取得了 67.5 NDS 的超强性能。如果用上 HoP[5] 和 StreamPETR-large[6] 等方法中的 ViT-large 作为 backbone,冲上 70+ 不在话下。
我们的工作已被 ICCV 2023 接收,论文、代码和权重(包括我们在榜单上 67.5 NDS 的模型)均已公开:

论文标题:
SparseBEV: High-Performance Sparse 3D Object Detection from Multi-Camera Videos
论文链接:https://arxiv.org/abs/2308.09244
代码链接:https://github.com/MCG-NJU/SparseBEV

引言
现有的 3D 目标检测方法可以被分类为两种:基于稠密 BEV 特征的方法和基于稀疏 query 的方法。前者需要构建稠密的 BEV 空间特征,虽然性能优越,但是计算复杂度较大;基于稀疏 query 的方法避免了这一过程,结构更简单,速度也更快,但是性能还落后于基于 BEV 的方法。因而我们自然而然地提出疑问:基于稀疏 query 的方法是否可以实现和基于稠密 BEV 的方法接近甚至更好的性能?
根据我们的实验分析,我们认为实现这一目标的关键在于提升检测器在 BEV 空间和 2D 空间的适应性。这种适应性是针对 query 而言的,即对于不同的 query,检测器要能以不同的方式来编码和解码特征。这种能力正是之前的全稀疏 3D 检测器 DETR3D 所欠缺的。
因此,我们提出了 SparseBEV,主要做了三个改进。首先,设计了尺度自适应的自注意力模块(scale-adaptive self attention, SASA)以实现在 BEV 空间的自适应感受野。其次,我们设计了自适应性的时空采样模块以实现稀疏采样的自适应性,并充分利用长时序的优势。最后,我们使用动态 Mixing 来自适应地 decode 采到的特征。
早在今年的2月9日,ICCV 投稿前夕,我们的 SparseBEV(V2-99 backbone)就已经在 nuScenes 测试集上取得了65.6 NDS 的成绩,超过了 BEVFormer V2[7] 等方法。如下图所示,该方案命名为 SparseBEV-Beta,具体可见 eval.ai 榜单:https://eval.ai/web/challenges/challenge-page/356/leaderboard/1012
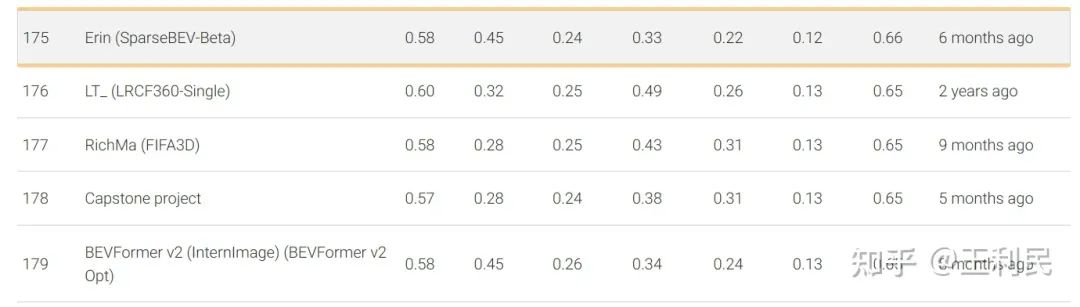
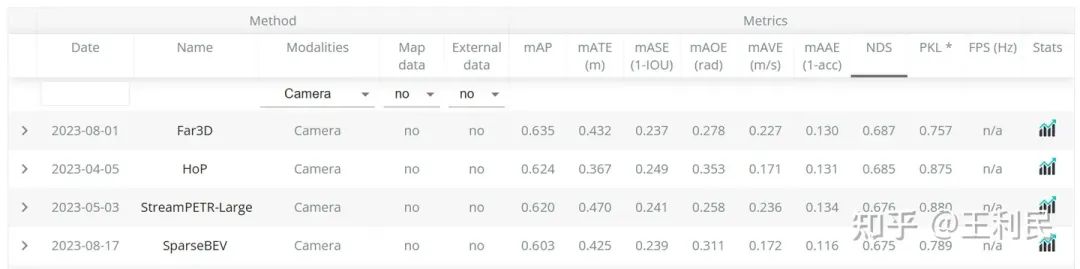
最近,我们采用了一些来自 StreamPETR 的最新 setting,包括将 bbox loss 的 X 和 Y 的权重调为 2.0,并使用 query denoising 来稳定训练等等。现在,仅采用轻量级 V2-99 作为 backbone 的 SparseBEV 在测试集上就能够实现 67.5 NDS 的超强性能,在纯视觉 3D 检测排行榜中排名第四(前三名均使用重量级的 ViT-large 作为 backbone):
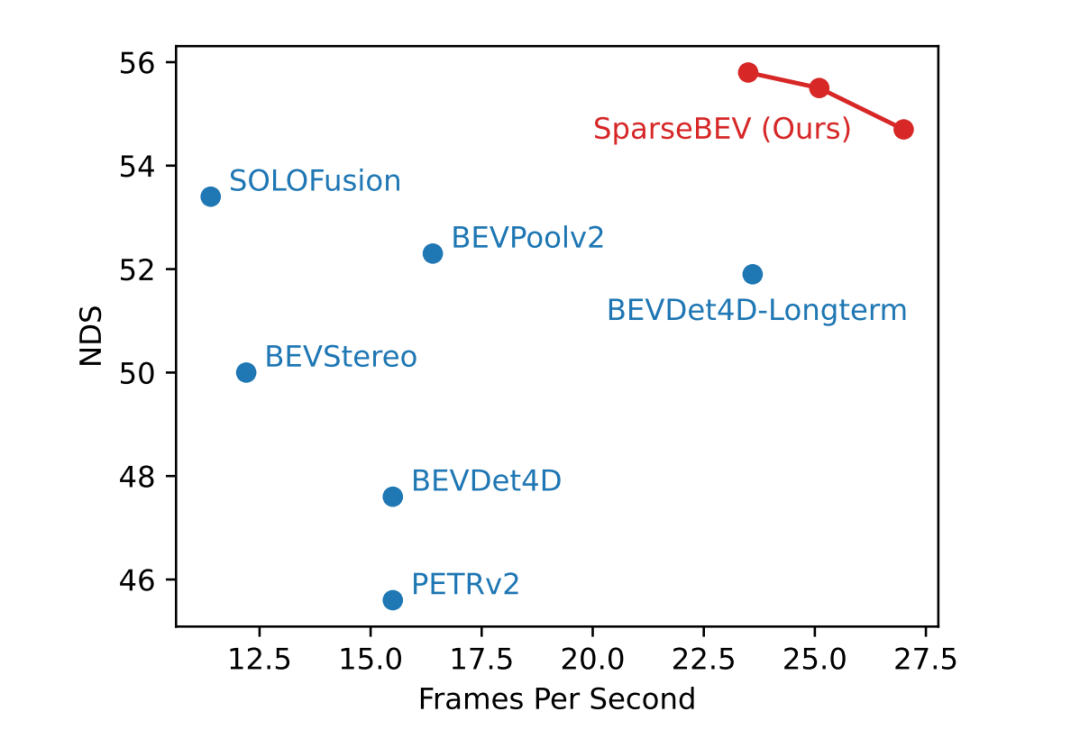
在验证集的小规模的 Setting(ResNet50,704x256)下,SparseBEV 能取得 55.8 NDS 的性能,同时保持 23.5 FPS 的实时推理速度,充分发挥了 Sparse 设计带来的优势。

方法
模型架构
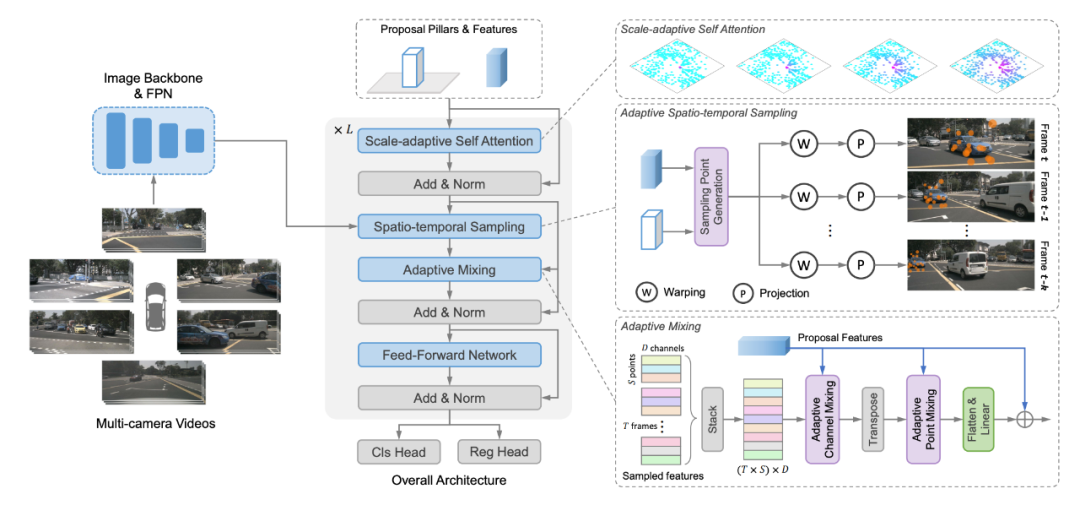
SparseBEV 的模型架构如上所示,其核心模块包括尺度自适应自注意力、自适应时空采样、自适应融合。
Query Initialization
现有 query-based 方法都用 reference point 作为 query。在 SparseBEV 中,Query 包含的信息更丰富, 包括3D坐标 、尺寸 、旋转角 、速度 ,以及对应的 维特征。每个 query 都被初始化为 pillar 的形状, 为 0 且 约为 4,这是因为自驾场景中一般不会在 轴上出现多个物体。Scale-adaptive Self AttentionBEV 空间的多尺度特征提取很重要。基于 Dense BEV 的方法往往通过 BEV Encoder 来显式聚合多尺度特征(比如 BEVDet[8] 用 ResNet+FPN 组成 BEV Encoder 来提取多尺度的 BEV 特征,BEVFormer 则使用 Multi-scale Deformable Attention 来实现 BEV 空间的多尺度),而基于稀疏 query 方法则做不到这一点。我们认为,稀疏 query 之间的 self attention 可以起到 BEV Encoder 的作用,而 DETR3D 中使用的标准的 Multi-head self attention (MHSA) 并不具备多尺度能力。因此,我们提出了尺度自适应自注意力模块(scale-adaptive self attention, SASA),让模型自己去决定合适的感受野:
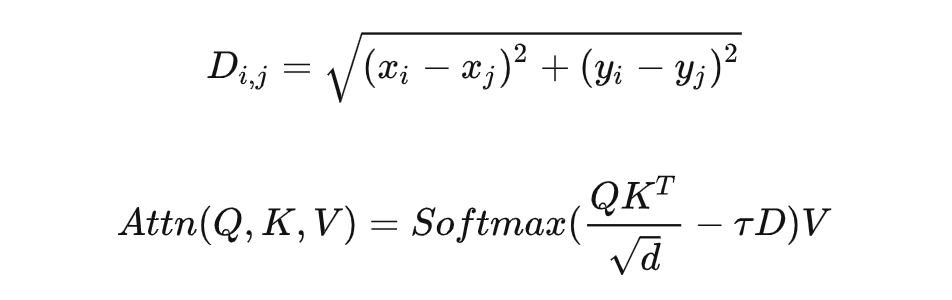
其中 表示两个 query 中心点之间的欧式距离, 表示感受野的控制系数,随着 增大,远距离的 query 的注意力权重减小,感受野相应缩小。当 时,SASA 退化为标准的拥有全局感受野的自注意力模块。这里的 是通过对每个 query feature 使用一层 Linear 自适应生成的,并且每 个 head 生成的 都不同:
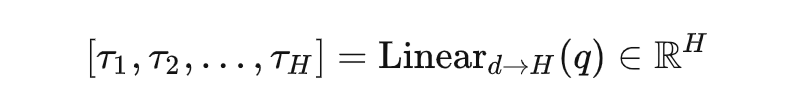
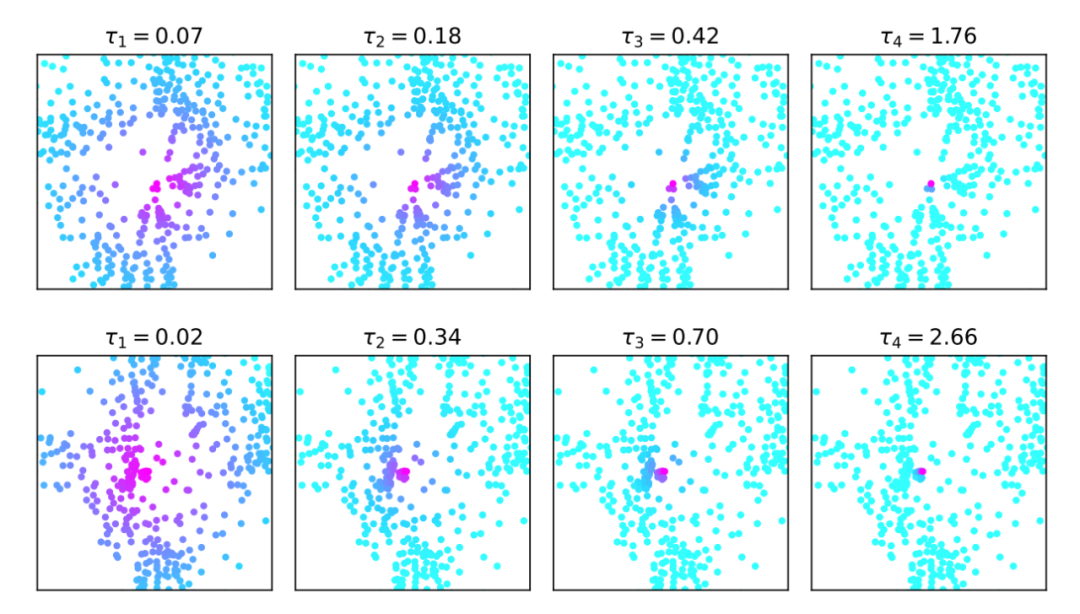
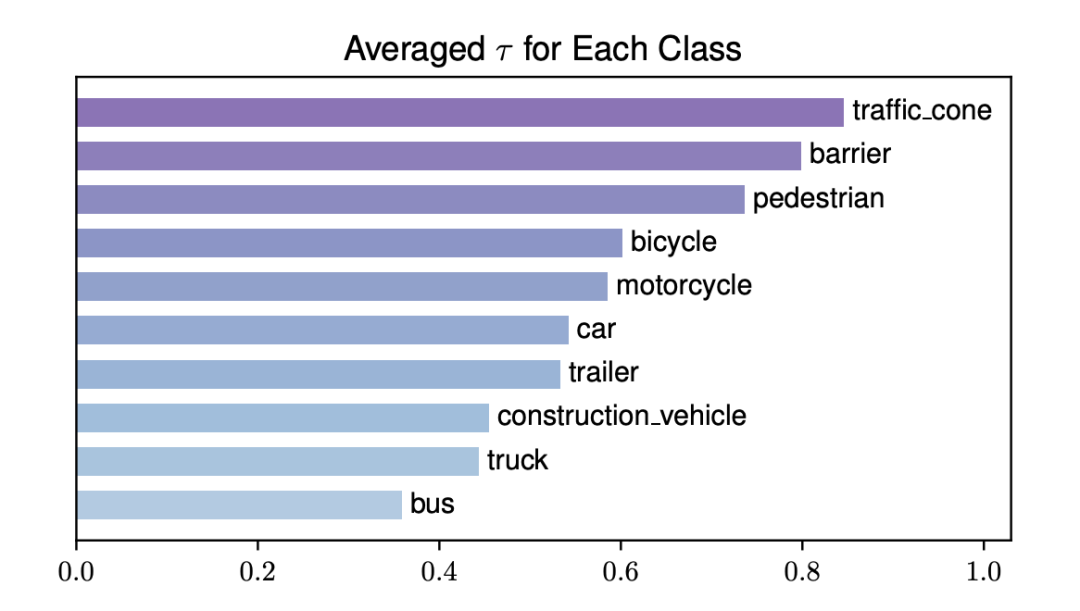

Adaptive Spatio-temporal Sampling
对于每个 query,我们对 query feature 使用一层 Linear 生成一系列 3D Offset:。接着,我们将这些 offset 相对于 query pillar 进行坐标变换以得到 3D 采样点。采样点生成过程如下: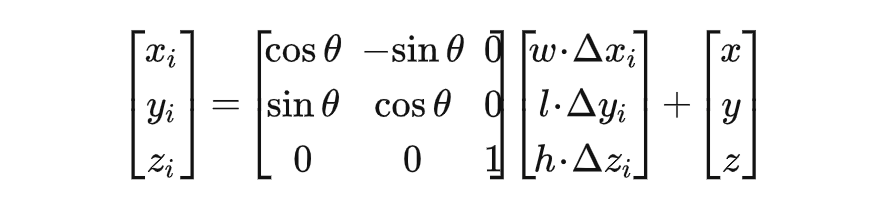
这样,我们生成的采样点可以适应于给定的 query,从而能够更好地处理不同尺寸、远近的物体。同时,这些采样点并不局限于给定的 query bbox 内部,它们甚至可以撒到框外面去,这由模型自己决定。
接着,为了进一步捕捉长时序的信息,我们将采样点 warp 到不同时刻的坐标系中,以此实现帧间对齐。在自动驾驶场景中,有两种类型的运动:一是车自身的运动(ego motion),二是其他物体的运动(object motion)。对于 ego motion,我们使用数据集提供的 ego pose 来实现对齐;对于 object motion,我们利用 query 中定义的瞬时速度向量,并配合一个简单的匀速运动模型来对运动物体进行自适应的对齐。这两种对齐操作都能涨点:

对于稀疏采样这块,我们后来也基于 Deformable DETR 写了一个 CUDA 优化。不过,纯 PyTorch 实现其实也挺快的,CUDA 优化进一步提速了 15% 左右。
我们还提供了采样点的可视化(第一行是当前帧,二三两行是历史前两帧),可以看到,SparseBEV 的采样点精准捕捉到了场景中不同尺度的物体(即在空间上具备适应性),且对于不同运动速度的物体也能很好的对齐(即在时间上具备适应性)。

Adaptive Mixing
接着,我们对采到的特征的 channel 和 point 两个维度分别进行 adaptive mixing[9]。假设共计 帧,每帧 个采样点,我们首先将其堆叠为 个采样点。因此 SparseBEV 属于堆叠时序方案,可以很容易地融合未来帧的信息。接着,我们对这些采样点得到的特征进行 channel mixing,其中 mixing 的权重是根据 query feature 动态生成的:

随后对 point 维度进行同样的 mixing 操作:

Dual-branch SparseBEV
在实验中,我们发现将输入的多帧图像分为 Fast、Slow 两个分支处理可以进一步提升性能。具体地,我们将输入分为高分辨率、低帧率的 Slow 分支和低分辨率、高帧率的 Fast 分支。于是,Slow 分支专注于提取高分辨率的静态细节,而 Fast 分支则专注于捕获运动信息。加入 Dual-branch 的 SparseBEV 结构图如下所示: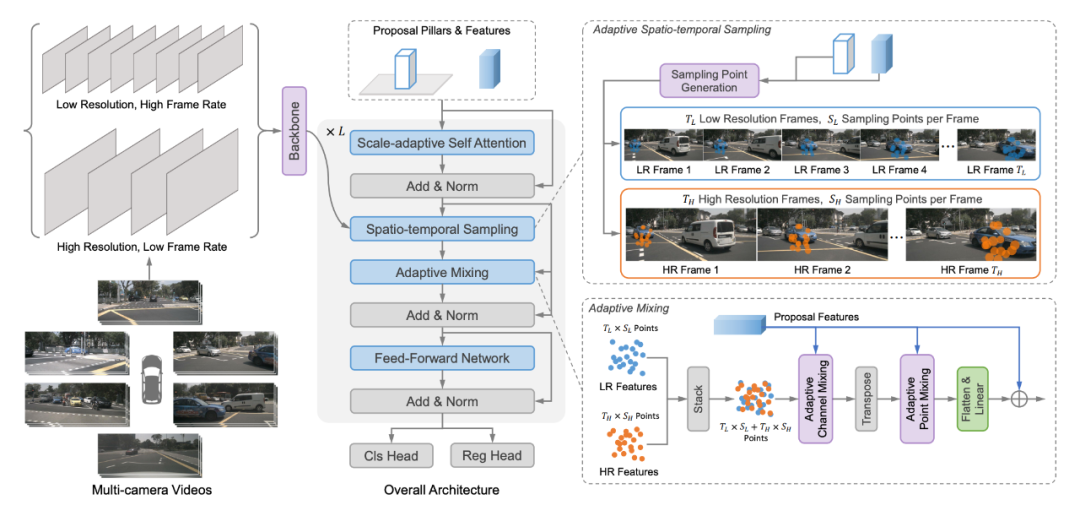 Dual-branch 设计不光减小了训练开支,还显著提升了性能,具体可见补充材料。它的涨点说明了自驾长时序中的静态细节和运动信息应该解耦处理。但是,它把整个模型搞得太复杂,因此我们默认情况下并没有使用它(本文中只有测试集 NDS=63.6 的那行结果用了它)。
Dual-branch 设计不光减小了训练开支,还显著提升了性能,具体可见补充材料。它的涨点说明了自驾长时序中的静态细节和运动信息应该解耦处理。但是,它把整个模型搞得太复杂,因此我们默认情况下并没有使用它(本文中只有测试集 NDS=63.6 的那行结果用了它)。

实验结果
nuScenes test split

局限性
SparseBEV 的弱点还不少:1. SparseBEV 非常依赖 ego pose 来实现帧间对齐。在论文的 Table 5 中,如果不使用 ego-based warping,NDS 能掉 10 个点左右,几乎和没加时序一样。2. SparseBEV 中使用的时序建模属于堆叠时序,它的耗时和输入帧数成正比。当输入帧数太多的时候(比如 16 帧),会拖慢推理速度。3. 目前 SparseBEV 采用的训练方式还是传统方案。对于一次训练迭代,DataLoader 会将所有帧全部 load 进来。这对于机器的 CPU 能力有较高的要求,因此我们使用了诸如 TurboJPEG 和 Pillow-SIMD 库来加速 loading 过程。接着,所有的帧全部会经过 backbone,对 GPU 显存也有一定要求。对于 ResNet50 和 8 帧 704x256 的输入来说,2080Ti-11G 还可以塞下;但如果把分辨率、未来帧等等都拉满,就只有 A100-80G 可以跑了。我们开源的代码中使用的 Training 配置均为能跑的最低配置。目前有两种解决方案:A. 将部分视频帧的梯度截断。我们开源的 config 中有个 stop_prev_grad 选项,它会将所有之前帧都以 no_grad 模式推理,只有当前帧会有梯度回传。B. 另一种解决方案是采用 SOLOFusion、StreamPETR 等方法中使用的 sequence 训练方案,省显存省时间,我们未来可能会尝试。

结论
本文中,我们提出了一种全稀疏的单阶段 3D 目标检测器 SparseBEV。SparseBEV 通过尺度自适应自注意力、自适应时空采样、自适应融合三个核心模块提升了基于稀疏 query 模型的自适应性,取得了和基于稠密 BEV 的方法接近甚至更优的性能。此外我们还提出了一种 Dual-branch 的结构进行更加高效的长时序处理。SparseBEV 在 nuScenes 同时实现了高精度和高速度。我们希望该工作可以对稀疏 3D 检测范式有所启发。
参考文献
[1] Wang Y, Guizilini V C, Zhang T, et al. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries[C]//Conference on Robot Learning. PMLR, 2022: 180-191.[2] Liu Y, Wang T, Zhang X, et al. Petr: Position embedding transformation for multi-view 3d object detection[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 531-548.[3] Li Z, Wang W, Li H, et al. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers[C]//European conference on computer vision. Cham: Springer Nature Switzerland, 2022: 1-18.[4] Park J, Xu C, Yang S, et al. Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection[J]. arXiv preprint arXiv:2210.02443, 2022.[5] Zong Z, Jiang D, Song G, et al. Temporal Enhanced Training of Multi-view 3D Object Detector via Historical Object Prediction[J]. arXiv preprint arXiv:2304.00967, 2023.[6] Wang S, Liu Y, Wang T, et al. Exploring Object-Centric Temporal Modeling for Efficient Multi-View 3D Object Detection[J]. arXiv preprint arXiv:2303.11926, 2023.[7] Yang C, Chen Y, Tian H, et al. BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 17830-17839.[8] Huang J, Huang G, Zhu Z, et al. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view[J]. arXiv preprint arXiv:2112.11790, 2021.[9] Gao Z, Wang L, Han B, et al. Adamixer: A fast-converging query-based object detector[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 5364-5373.
·
-
物联网
+关注
关注
2916文章
45231浏览量
380143
原文标题:CCV 2023 | SparseBEV:高性能、全稀疏的纯视觉3D目标检测器
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SciChart 3D for WPF图表库
多维精密测量:半导体微型器件的2D&3D视觉方案
技术资讯 | 2.5D 与 3D 封装

全新升级,洛微发布高性能3D工业相机,为机器视觉注入新动能


微视传感高性能3D视觉产品亮相2024上海机器视觉展
手机检测器电路图 手机检测器的功能和应用

英伦科技10.1寸裸眼3D平板电脑——革新您的视觉体验

微波检测器的原理是什么 微波检测器的工作原理和用途
微波检测器的工作原理 微波检测器的性能参数
微波检测器优缺点 微波检测器的功能和作用
3D视觉技术在惯性环上料领域的未来发展






 工商网监
工商网监
评论