 大语言模型(LLM)预训练数据集调研分析
大语言模型(LLM)预训练数据集调研分析
大语言模型涉及数据的通常有有多个阶段(Aligning language models to follow instructions [1]):pre-train、sft(supervised finetune)、rlhf(optional). State of GPT:大神 Andrej 揭秘 OpenAI 大模型原理和训练过程。

supervised finetune 一般在 base model 训练完成后,使用 instruction 以及其他高质量的私域数据集来提升 LLM 在特定领域的性能;而 rlhf 是 openAI 用来让model 对齐人类价值观的一种强大技术;pre-training dataset 是大模型在训练时真正喂给 model 的数据,从很多 paper 能看到一些观点比如:1. 提高预训练数据的质量能让大模型的性能表现更好;2. LLM 要想要更加强大,除了继续加大模型参数量之外,给模型准备更多成比例的更大量的高质量数据也很关键。
经过初步调研发现在英文世界的大模型,预训练数据都来自互联网爬取的全网数据,在英文世界有 Common crawl 这样的组织来维护这类全网爬虫数据集;也有 huggingface 这种非常好的社区,组织起 NLP 领域的模型 datasets 分享。
而在中文世界,似乎没有特别公开的大规模语料数据集,huggingface、github 上也没有找到特别多组织的很有体系的中文语料数据集。另一方面,近期中国国内公布的一些大模型,也主要以评估分结果作为输出,很少有针对 pre-training 数据展开详细介绍的信息。
本文旨在总结一些开源的英文大模型的 pre-training dataset,通过分析 gpt3、llama、falcon 等开源 LLM 的 paper 上提到的 dataset 部分逻辑,以及深入调研一些比如 C4、The Pile、RefinedWeb 数据集,希望能总结一些规律,给期望了解 pre-train 数据集对 LLM 最终效果有何影响的人能有更加直观的认知。

先来看看业界大模型的公开dataset资料
先分别简单总结一下 GPT-3、llama、falcon 的 paper 里 dataset 部分的描述。然后我们重点展开 falcon 模型的 dataset refinedWeb,这是因为 falcon-40B 在 2023-07 这个时间点打榜到了 huggingface 的第一名,且 falcon 论文中着重提到了他们的 pre-train dataset:tiiuae/falcon-refinedweb。Datasets at Hugging Face [2],是公开的 paper 中讲 pre-train 讲的比较详细的一篇,且 falcon 声称是数据让他们的 model 效果这么好,那我们就展开了解一下。
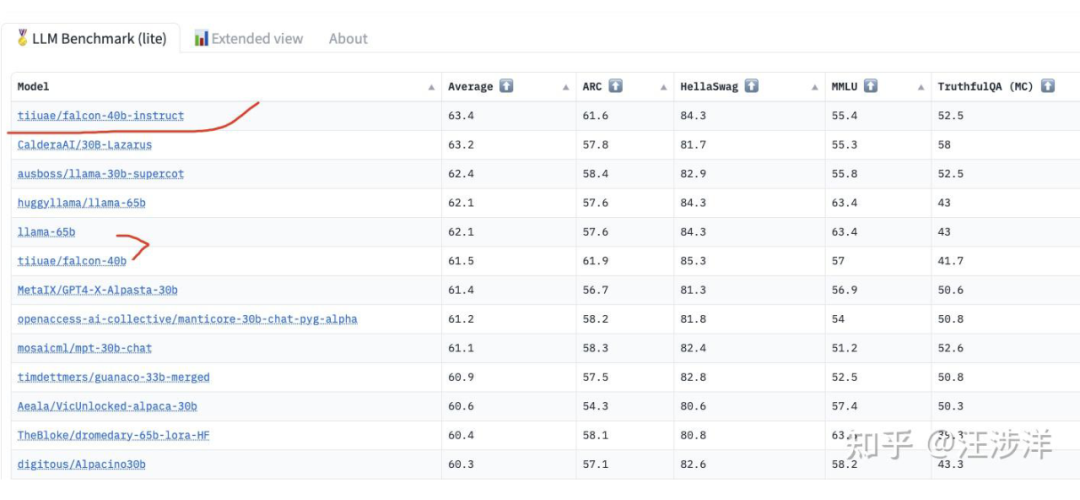
1.1 先看openai的GPT系列
GPT3: Language Models are Few-Shot Learners [3] (GPT3 paper)
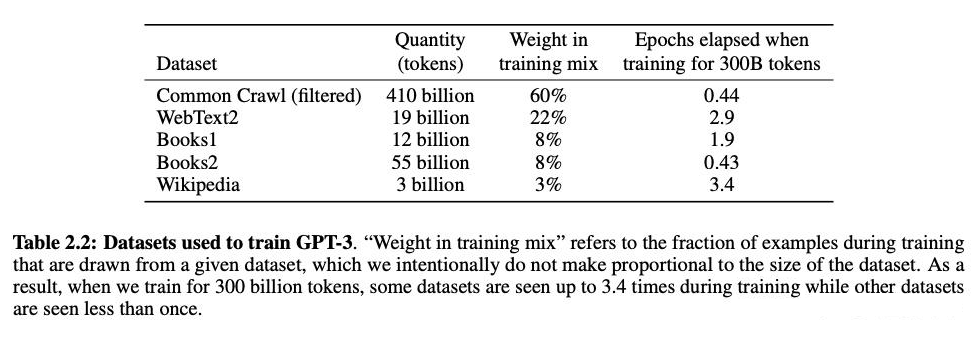
GPT4: (GPT-4 [4]) 就没有再公开 pre-training 的 dataset 了
GPT3 的 paper 是 2020 年 5 月发布的,大概是 3 年前。使用的 pre-training dataset 在目前看来也比较简单,主要来源就是 web 数据、书、维基百科这 3 个,不能算很丰富。尤其没有包含很多垂直 industry 的数据。但在 3 年前用这些数据来验证模型的性能随模型大小变化的趋势,以及做常识性评估逻辑是非常合适了。
很多人都说 openAI 的核心竞争力之一就在数据,但很遗憾 GPT4 的 paper 中确实没有再公开当前的数据细节了。这么看 elon musk 喷 openAI 变成了closeAI 好像也有点道理。哈哈哈 。。
这里引用一堆废纸:GPT 模型成功的背后用到了哪些以数据为中心的人工智能(Data-centric AI)技术?[5] 文章总结的 openAI GPT 系列数据变化图。
GPT3 的数据加工主要有 filter & deduplication:

filter:
用 WebText(Papers with Code - WebText Dataset [6]、openwebtext [7])作为高质量数据集训练了一个分类器。使用分类器去过滤 Common crawl 的 documents。filter 时使用了一个公式,会使用 document_score。会有一个 α 参数,他能把大部分不符合要求的数据过滤掉同时保留一部分质量不高的数据。文章里居然也说到这样做能提高性能。
deduplication:
使用fuzzy deduplicate做去重。提到了使用spark的minHashLSH实现来做hash。
Question1:为什么 LLM 的 pre-training dataset 要这么关注 deduplication 呢?
Answer1:
“Deduplicating Training Data Makes Language Models Better”.Katherine Lee et al. ACL 2022.[8]
minHash:
是一个对比文档相似度的技术。wikipedia 给出的 minhash 中 K 个 hash function 的错误率为:。这里关键注意 GPT3 使用了 10 hashes。错误率还是相对比较高的。后面也关注下其他 LLM 的这个取值。
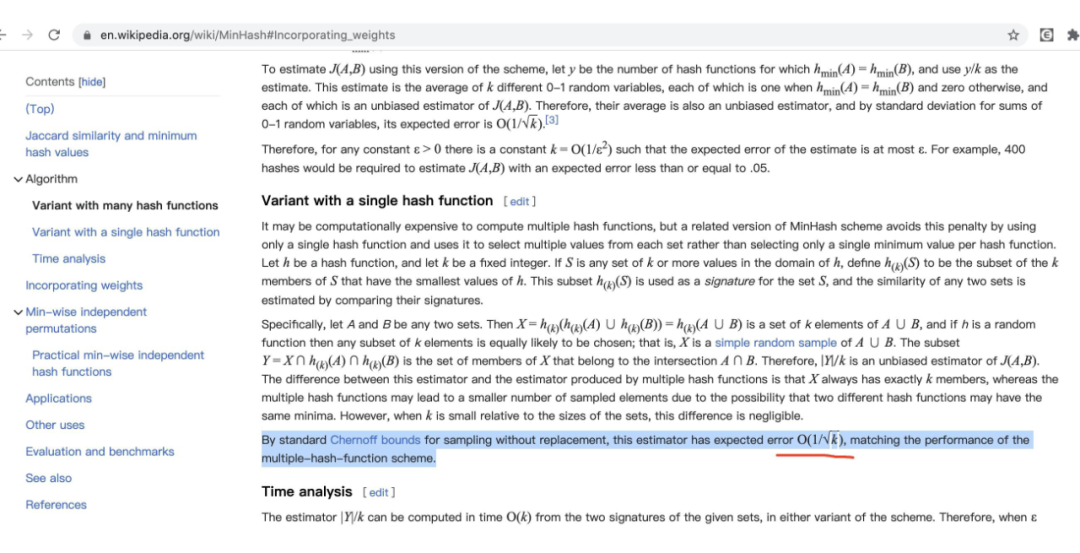
▲ wikipedia 上 minHash 中 k 个 hash 带来的错误率
数据量:
300Billion token.
1.2 facebook llama & llama2
###updated at 20230719###
facebook 发布了 llama2 版本:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/

pre-trainning 数据的主亮点:
-
使用了 2trillion tokens,相比 llama1 的 1.4T token 提高了 40%
-
llama2 并没有使用 facebook 的自己产品的数据
- 在做 filter 时干掉了包含 private personal information 多的数据。
其他亮点:
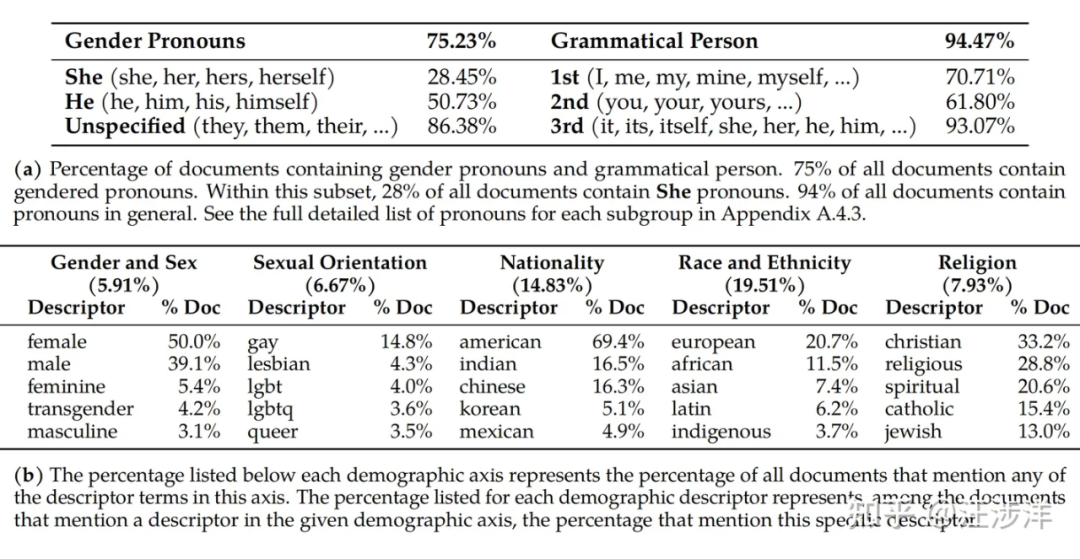
提供了pre-train数据的一些insight分析,比如下图,感兴趣还是自己看paper吧。
###end of updated at 20230719###
LLaMA: Open and Efficient Foundation Language Models
https://arxiv.org/abs/2302.13971
llama 整体的 pre-training dataset与GPT3 相比,多的部分有:
1. 使用了更丰富的数据源。比如 Github,ArXiv ,StackExchange 等。总体占比有 10%。这些高质量的数据源里有核心代码、高质量论文、高质量问答数据。这些高质量数据对 LLM suppose 是有很大的帮助。
Question2:不同数据源的比例对 LLM 的最终 performance 有影响么?
2.还是用了C4这个数据集。类似于WebText。
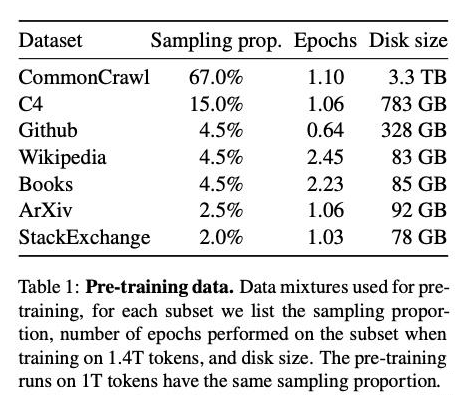
再看看 filter、deduplication 的细节

llama 针对 common crawl 的处理
-
在行级别做了 deduplication,llama paper 没有讲具体细节,但在 ccnet paper 有讲(CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data [9])后续专门展开讲一下。
-
使用了 fastText 做文本语言分类,删掉非英语。
-
使用了 ngram 做低质量 filter。
- 训练了一个 model,把网页分成被 wikipedia 引用和普通网页,这里主要也是区分质量。
数据量:
1.4T token.
1.3 facebook CCNet pipeline分析
原始论文:
https://arxiv.org/abs/1911.00359
CCNet 是 facebook 开发的针对 common crawl 的一系列数据 ETL pipeline。
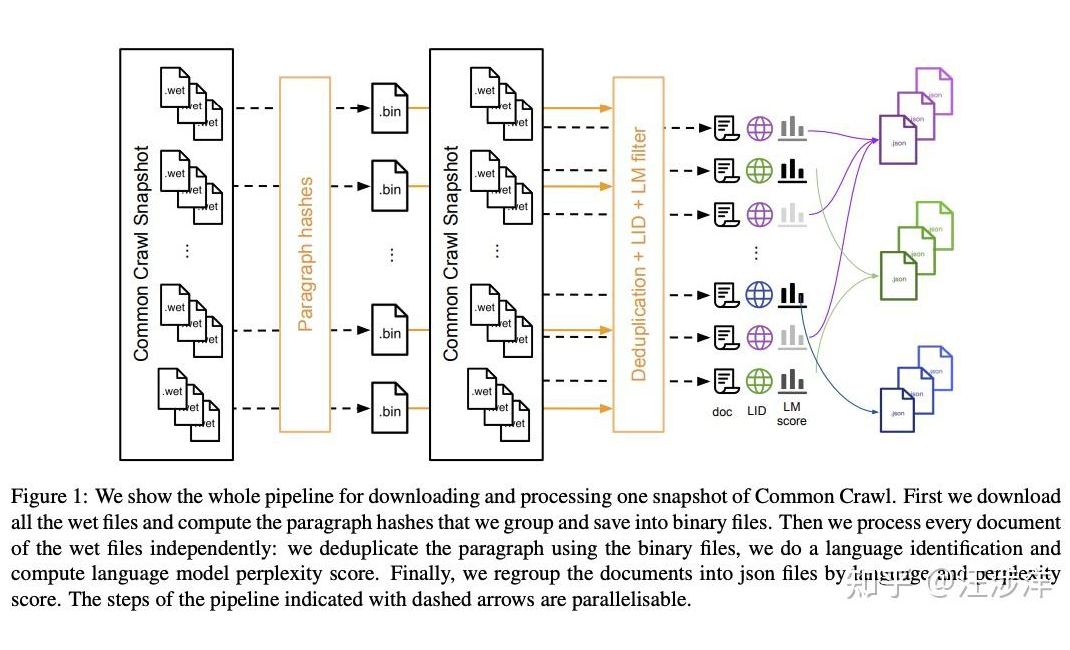
▲ ccNet pipeline
deduplication:
 ▲ dedup-1
▲ dedup-1

ccnet 的亮点:
-
提出了针对 raw common crawl data,要先做 dedup 在做语言分类鉴别,最终效果更好,尤其对小语种。
-
在对 common crawl 做 filter 时,使用了数据分级,并没有把 tail 数据全删掉。他分了 head middle tail,分级是使用另外训练的 model 来做的,比如head:先使用了 wikipedia 的数据来训练出model,然后看每一个 paragraph 的数据过这个 model 算出来 perplexity score 高的就算 head。
- 有按照不同语种分类,包含了小语种数据。
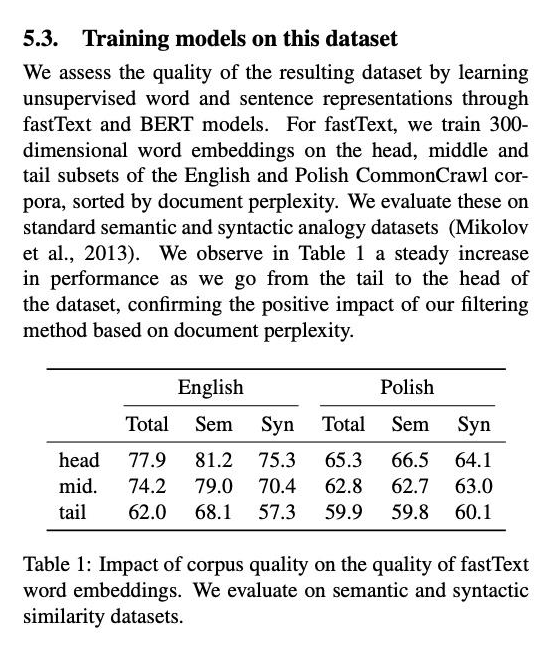
ccnet 的待提升:
-
facebook 的 deduplication 并没有使用 minhash,而是直接采用的 SHA-1 做传统的 hash 去重。
- 没有更多 line 级别的严格 filter。

来自迪拜的falcon以及其refinedweb数据集
本文下面重点调研下 falcon,falcon 是 dubai 的一家研究机构训练的 LLM,他不但开源了自己的 7B,40B 版本的模型,还着重开源了他的 pre-training dataset [10]。本文详细展开看一看。
论文原文:
https://arxiv.org/pdf/2306.01116.pdf
2.1 重要论点:只用web数据做预训练,LLM效果也能很好
仅使用互联网的 web 数据,把filter 和 deduplicate做好,也能训练处性能比使用精加工的数据集训练出来的 state-of-the-art 模型。我觉得这个论点挺猛的,这给了很多 LLM 创业团队打了很大的鸡血,即使起步晚一点,没有特别多的数据积累,似乎在大模型质量上也不一定会落后。

美中不足的是,完整版本的 refinedWeb 数据集有 5Trillion tokens,但 falcon 在 huggingface 开源的版本只有 600billion tokens,是用在训练 1.3B/7B 参数的模型上的,而不是 40B 最大的模型。在开源的时候,也保留自己的一部分核心竞争力。重点看看他们的数据清洗逻辑,可能对从业者处理中文互联网有帮助。

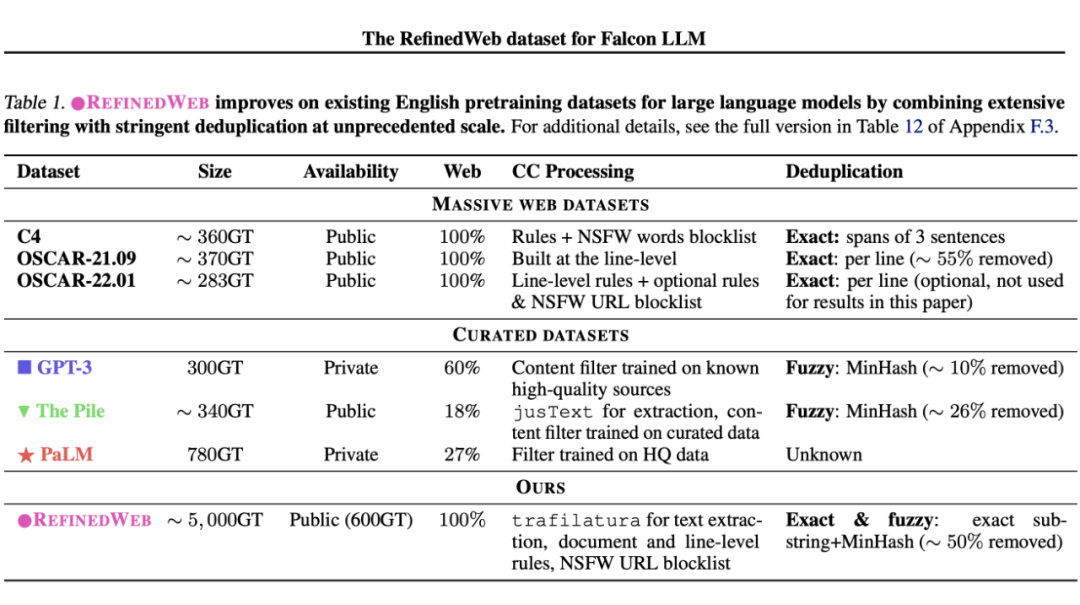 ▲ RefinedWeb 在 Web 数据的 filter、deduplication 上做了很重的工作。
▲ RefinedWeb 在 Web 数据的 filter、deduplication 上做了很重的工作。
NSFW :Not Safe/Suitable For Work
2.2 RefinedWeb详细加工过程
加工总原则
1. Scale first|规模第一
这个数据集是为了加工 40B~200B 参数的 LLM 设计的,因此需要 trillion 级别的 tokens。因此重点放在从 commoncrawl 的原始数据加工上准备数据,而不是耗费大量人力去处理垂直领域的数据集。
2. Strict deduplication|严格去重。
同时使用了 exact 和 fuzzy 去重,比其他论文报告的删除率更高。
3. Neutral filtering|中性过滤
也使用了基于模型的语言鉴定,使用了很多启发式的规则,后面会详细介绍。这一切都是为了避免 pre-training 数据当中包含 biased 数据。
总体流程
下图为总体数据清晰 pipeline,包含了每一步删除的文本数量,下面分步骤详细展开讲
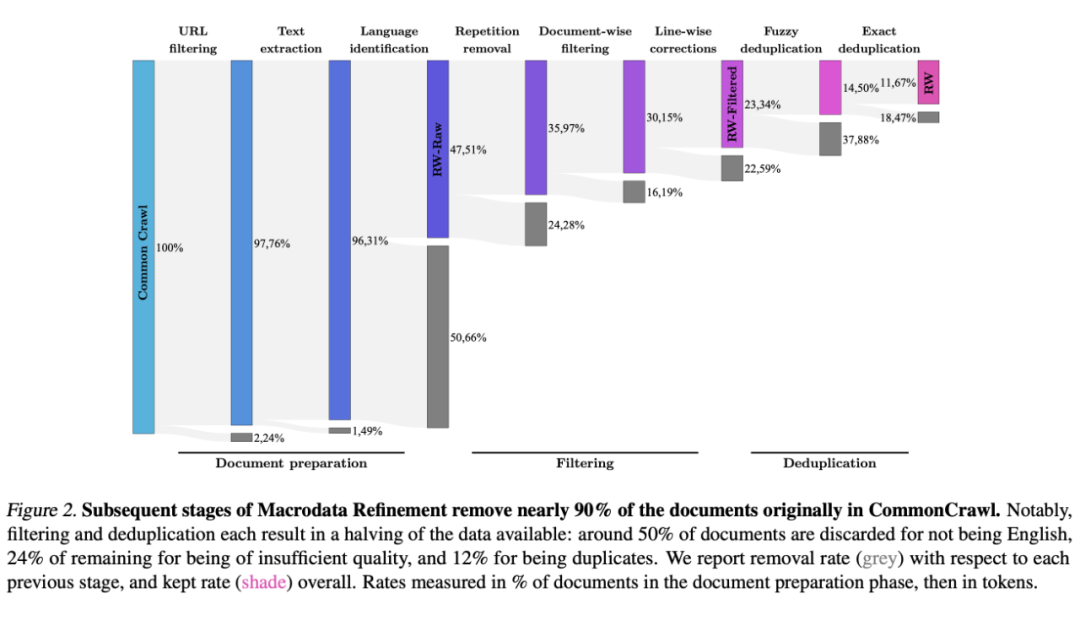

2.3 URL filtering
在重度去重、过滤等任务之前,先对整体做了基于 URL 的过滤。主要目标是过滤掉一些欺诈、成人网站。这里有两个基本规则:1)一个 4.6M 个域名的黑名单 2)URL 分,基于内容中单词的严格打分。falcon 发现单单基于一些 common 的黑名单还是会犯假阳性错误,比如过滤掉很多 popular 的博客平台和好的的文化网站。然后很多基于单词规则的规则数据集加工逻辑(比如 C4)会很容易把一些医学、法律类的网页给 block 了。
falcon 的 URL filtering 专注于找到可能对用户有害的成人内容相关的域名,或者包含了很多非结构化内容的域名,比如类似百度网盘这种存文件的。首先,在 4.6M 个黑名单中的域名,直接显示的 ban 了;然后,构建了一个 URL 打分体系,基于使用匹配一系列精选单词。这些精选单词列表是手工维护的,也是使用 ToxicBERT 标注出来的 toxicity 单词。
url 打分部分提到的分级操作很精细:
Strict 级别:子单词匹配
URL 包含的内容中,单词里哪怕 substring 里匹配上了也会被直接过滤。比如很多欺诈网站会用很多特殊表情放在很多命中黑名单的单词中间来 hack 整个单词级别的过滤。
Hard级别:整个单词匹配
整个单词命中才会被过滤
Soft级别:单词匹配
至少 2 个单词 match 才会过滤,这里的规则我觉得是可以调整的。soft 级别包含了一些单词是受怀疑的单词,单个单词并不一定有足够的理由是有害的,但是多个怀疑的词同时出现才会有害。这让我们能保留一些医学、法律方面的内容不会被过滤掉。比如(e.g., 但一个单词 dick)。

2.4 Text extraction
只想抽取网页的主要内容,把 menu,header,footer,以及广告都给去掉。其他论文发现 trafilatura 是最好的非商用 library 去从做这件事。然后把 doc 内容中的 url 都删掉。
2.5 Language identification
使用了 CCNet 中使用到的 fastText 来做文本的语言分类,这个是 document 粒度的。他使用了字符 n-gram 模型,这个模型使用 Wikipedia 数据训练出来,支持 176 中语言。我们把主语言低于 0.65 分的文档直接删掉了。
falcon 只 focus 在英语上,经过这一步处理后的数据叫 RW-RAW。
整个 refinedweb 数据处理 pipeline 是可以应用在其他语言上的,但从 common crawl 的数据分布看,中文数据是明显不符合中文的人口分布的。中国应该是世界第二大语言,但 common crawl 里中文的数据只排第 6.. 我觉得这就是说做中文的 LLM 以及相关的语料数据整理,做得好肯定还得靠我们中国人自己(吾辈加油)

2.6 Filtering: document-wise and line-wise
Repetition removal.
因为爬虫的错误或者低质量的数据源存在,网页包含重复内容也很常见,这肯定对 LLM 不好。我们肯定可以在 deduplication 阶段处理,但在更早的文档级别去做些处理是更轻量级的。我们删掉了大量的存在 line、paragraph、ngram能识别出来的重复的文档。
Document-wise filtering.
及其生成的垃圾文档占比也不低。他们往往使用了不少特殊关键字、无聊文档等,这些都不适合用来训练 LLM。
这里有个好玩的问题:几年后当 LLM 产生的内容充斥整个互联网时,又该怎么去过滤取舍 LLM 的 pre-trainning 数据呢?可以关注下这个话题:如果以后全网都是 AI 生成的质量不高的内容这些 AI 大模型再用这些数据训练那么这些大模型会不会越来越差?[11]
主要参考了 Rae et al.(2021)paper 里的一些质量过滤启发逻辑。他们主要 focus 在删掉一些异常值比如:总体文本长度,符号和单词比例,以及一些用于鉴定文档是真正自然语言的一些标准。我们注意到这些过滤器应该是在语言级别去使用的,这些过滤器从英语直接迁移到其他语言,会有过拟合的现象。
这里值得详细展开去看看 Rae et al.(2021)paper
Line-wise filter.
尽管在使用 trafilatura 库后已经有了不错的效果提升,很多网页文档还是遗留下来了一些不太符合预期的 line,比如社交网络的 likes 啊,点赞,反对按钮之类的。鉴于此,我们开发了一个 line 级别的矫正 filter,目标就是去纠正这些不符合预期的 line。如果这些矫正器删除了一个 doc 里大于 5% 的内容,我们就把整个 doc 删掉。
falcon 开发了一个 line 级别的 filter 策略,手工检查行级别数据:
-
如果主要由大写字母组成(删掉)
-
如果只有数字组成(删掉)
-
如果是点赞、反对等这些东西(删掉);
-
如果一行只有一个单词(删掉);
-
如果内容很短(≤ 10 words),且匹配到一些 pattern(持续更新):
-
– 在这行的开始;
-
– 在这行的结束(e.g. 阅读更多.....);
-
最终,如果被标记 line 的单词量超过了整个文档的 5%,整个 doc 都删掉。我们是通过人工检查数据发现的这些逻辑,在处理不同语言的预料时,也需要有个性化的做更多特殊处理。
在经历了 URL filter、text extraction、language identification、以及 doc/line级别的 filter 之后,common crawl 整体上只剩下了 23% 的数据。
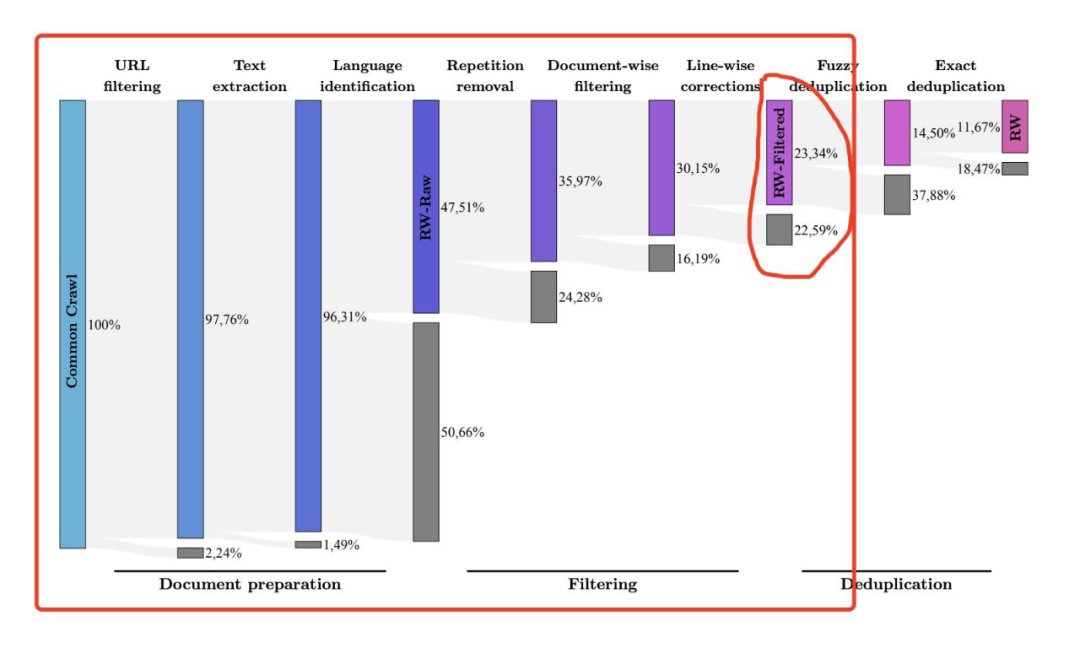
整个 filter 过程后,common crawl 剩下 23% 的数据
2.7 Deduplication: fuzzy, exact, and across dumps
Fuzzy deduplication|模糊去重
falcon 做模糊去重也使用了 minhash,但 falcon 使用了 9000 个 hash function。这相比与 GPT3 的 10 个 hash function 会带来巨大的精度提升,但也带来了计算量的巨大消耗。文中说到如果使用不够激进的设置,比如类似 The Pile 数据集使用的 10 个 hash function,会带来很低的去重比率和更差的模型性能。falcon 使用 minhash 去在 web 语料中大范围的找到近似的重复文档。这项技术让我们能鉴别出通过精确去重方法鉴别不出来的长度比较小的重复内容(比如比 50 个 token 还要小的内容)。
开始先从对内容进行规范化处理做起:删掉标点符号,把文本全部做小写处理,NFD 正则化,口音都会被删掉,空格都会被标准化处理。然后使用 GPT2 的 tokenizer 做了分词,以及为每个 doc 获取了单独的 n-grams。然后就用标准的 minhash 做重复度检查。最终在所有的 bucket 当中,如果 doc A and B 在一个 bucket 相似,B and C 在另一个 bucket 相似,则 A-B-C 就变成了一个 cluster。最后在 cluster 当中随机挑一个保留下来。
Exact deduplication|精确去重
使用 substring 在句子级别,而不是文档级别去,找到 token-by-token 的字符串匹配。如果连续超过 50 个 token 是相同的,就做删除处理。这样抽取子字符串去做 match 后的删除内容做会改变文档内容,因此还实验了删掉整个 doc 或者针对这些内容做 loss-masking 处理,而不是直接删掉他们,但这些尝试似乎没有给 LLM 的训练带来明显的性能增长。
falcon 使用了 Lee et al.(2022)论文中的 EXACTSUBSTR 实现去做精确文本匹配。精确去重作用在 minhash 的模糊去重后的数据上,进一步减少了近 40% 的数据量。EXACTSUBSTR 会找到跨 doc 的长子字符串,是通过字符粒度逐个检查实现的。这些子字符串可能比较小没有占到 doc 的足够大的部分,以至于没有在 minhash 的模糊去重阶段被去掉,或者因为 minhash 的相似度检查就是没有找出来。
在精确去重中,文中还提到了发现 duplication span 后的几种策略:
• EXACTSUBSTR-CUT|把 span 直接删了:比如不到 20 个 token 的
• EXACTSUBSTR-MASK|给 span 加上 musk
• EXACTSUBSTR-DROPPARTIAL:如果重复部分超过 doc 的 20%,直接把 doc 删了
• EXACTSUBSTR-DROPANY:只要发现有 duplicate 的 span,整个 doc 都删了
EXACTSUBSTR-CUT 把中间的 span 删了可能会导致 doc 内语义的不连贯;EXACTSUBSTRMASK 不会有前者的问题;EXACTSUBSTR-DROP 在文档很大时,可能还会保留 duplicate 的内容,而 EXACTSUBSTR-DROPANY 就是更加激进的做法了。
URL deduplication|URL去重
因为计算量的限制,在整个 RW-Filtered 数据集粒度直接做全局去重是不可能的。因此,把 CommonCrawl 分成 100 份,在每一份数据中做去重。大部分的重复都其实是能在这些分片内的去重完成的,但是我们也发现了在分片之间会有显著的一些 overlap,这是因为爬虫对部分 URL 访问爬取了多次。因此,又保留了在分片内发现过的做过去重操作的 URL 清单,在后续的每个分片上看到都直接做删除处理。

精加工数据集调研:WebText、The Pile 、C4 的调研分析
3.1 WebText
WebTextDataset Replication:https://openwebtext2.readthedocs.io/en/latest/replication/
▲ WebText数据集的
数据集特殊点:
-
做 filter 时使用了 Reddit score
-
数据集和加工数据的代码完全开源,目前 eleutherAI 也在实现openwebtext2
评价:
感觉 webText 比较局限,reddit 相关并不能 cover 很多内容。目前(202307)&未来并不适合作为大模型的 common crawl 数据基础。
3.2 The Pile
原论文:
https://arxiv.org/abs/2101.00027
The Pile 是 EleutherAI(EleutherAI)这个组织精加工的专门为 NLP 大模型训练用的数据集。
EleutherAI is a non-profit AI research lab that focuses on interpretability and alignment of large models.
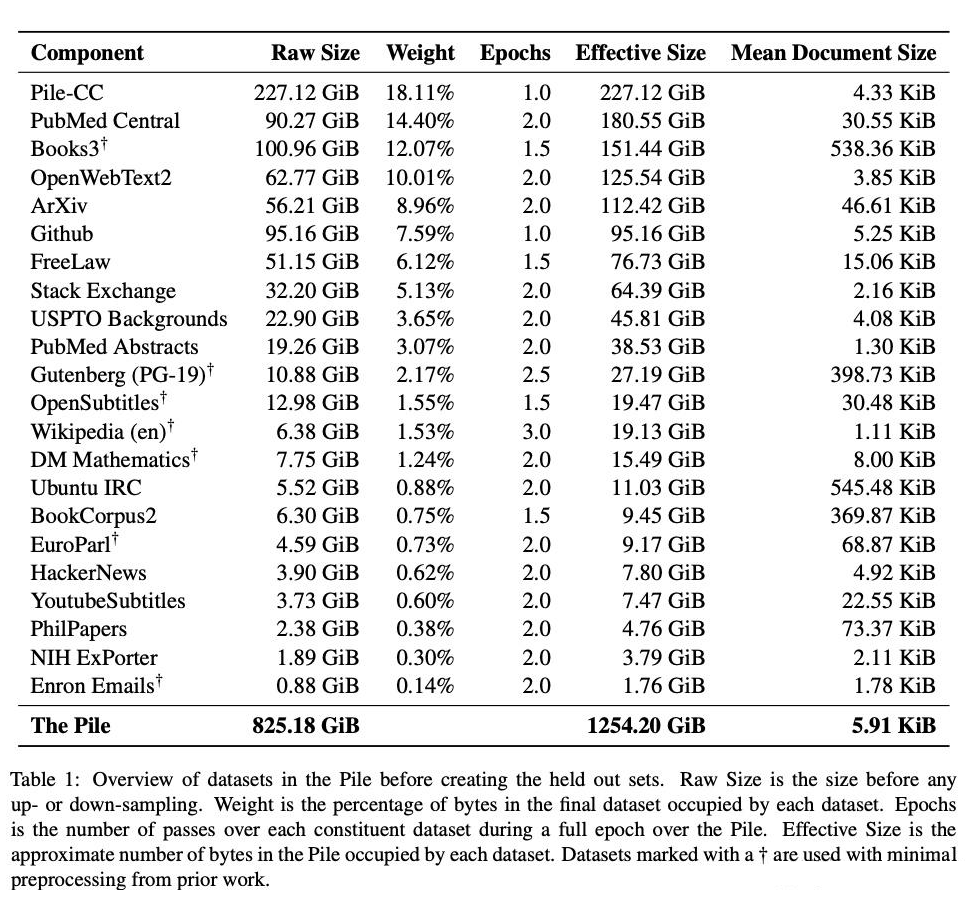
在处理 common crawl 的互联网数据时,有提到使用 well-designed extraciton 和 filter。
More Effective Boilerplate Removal-the GoldMiner Algorithm [13] 用到了这篇论文的方法。

评价:
-
数据种类很丰富,涵盖了非常多垂类的高质量数据。
-
但总体数据 token 量比较小,尤其处理 common crawl 部分。
3.3 C4
C4 是 google 针对 common crawl 数据进行精加工数据集:
https://www.tensorflow.org/datasets/catalog/c4
数据集特殊点:
1. 最初只能使用 google cloud 的 beam 代码做加工。
2. 而后有一些开源实现。比如:c4 · Datasets at Hugging Face [14],C4 Dataset Script[15]
评价:
个人没有详细看开源版本的 C4 加工逻辑,github repo 的文档里加工逻辑写的也不够清晰。使用时相对比较黑盒子。

个人思考
falcon 的 refinedWeb paper [16] 是一篇把基于爬虫爬取数据的处理讲的这么详细的 paper 之一,后续我会再精读 The Pile,C4 等其他数据集,总结出更多的爬虫爬取的网页数据的 pre-training data 处理方法。
在对 LLM dataset 调研的过程中,我发现中文的 NLP 大型语料真的很少,除开没有 common crawl 这样大型公立的互联网数据之外,也缺乏人工整理的高精 curated dataset,在 github 和 huggingface 都很少看到。
github 里搜索 chinese corpus 最高的两个 repo,也都很久没有更新了。https://github.com/brightmart/nlp_chinese_corpushttps://github.com/SophonPlus/ChineseNlpCorpus
不过随着中国搞 LLM 的玩家越来越多,以及整个基于 LLM 的垂类应用越来越多,更多的人也在基于 base model 做 finetune,各个公司其实都会越来越重视整理自己的垂直语料库,希望大家未来长期都能慢慢把一些没有那么高壁垒的数据贡献在 github、huggingface,或者参考 falcon 的方式,贡献自己语料库当中的一部分。
我也建议搞中文的 LLM 厂家不要只分享打榜结果,如果打榜效果好的话可以适当放出一些 insight,比如用了什么数据,怎么处理数据的,尤其是高校科研背景的研究机构可以更多的做公立性质的贡献。

参考文献
[1] https://openai.com/research/instruction-following
[2] https://huggingface.co/datasets/tiiuae/falcon-refinedweb
[3] https://arxiv.org/abs/2005.14165
[4] https://openai.com/research/gpt-4
[5] https://zhuanlan.zhihu.com/p/617057227
[6] https://paperswithcode.com/dataset/webtext
[7] https://huggingface.co/datasets/openwebtext
[8] https://arxiv.org/abs/2107.06499
[9] https://arxiv.org/abs/1911.00359
[10] https://huggingface.co/datasets/tiiuae/falcon-refinedweb
[11] https://www.zhihu.com/question/608053796
[12] https://github.com/EleutherAI/openwebtext2
[13] https://www.scielo.org.mx/scielo.php?script=sci_arttext&pid=S1870-90442013000200011
[14] https://huggingface.co/datasets/c4
[15] https://github.com/shjwudp/c4-dataset-script
[16] https://arxiv.org/pdf/2306.01116.pdf
-
物联网
+关注
关注
2909文章
44608浏览量
373067
原文标题:大语言模型(LLM)预训练数据集调研分析
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

LLM预训练的基本概念、基本原理和主要优势
llm模型训练一般用什么系统
llm模型和chatGPT的区别
预训练模型的基本原理和应用
大语言模型(LLM)快速理解

【大语言模型:原理与工程实践】大语言模型的预训练
【大语言模型:原理与工程实践】大语言模型的基础技术
2023年大语言模型(LLM)全面调研:原理、进展、领跑者、挑战、趋势





 工商网监
工商网监
评论