 Apple提出FastViT:快速卷积和Transformer混合架构
Apple提出FastViT:快速卷积和Transformer混合架构
导读
本文提出了一种通用的 CNN 和 Transformer 混合的视觉基础模型,移动设备和 ImageNet 数据集上的精度相同的前提下,FastViT 比 CMT 快3.5倍,比 EfficientNet 快4.9倍,比 ConvNeXt 快1.9倍
太长不看版
本文是 MobileOne 原班人马打造,可以看做是 MobileOne 的方法在 Transformer 上的一个改进型的应用。作者取名 FastViT,是一种 CNN,Transformer 混合架构的低延时模型。作者引入了一种新的 token mixer,叫做 RepMixer,它使用结构重新参数化技术,通过删除网络中的 Shortcut 来降低内存访问成本。
进一步使用大核卷积使得 FastViT 精度得到提升,而且不怎么影响延时。在移动设备和 ImageNet 数据集上的精度相同的前提下,FastViT 比 CMT 快3.5倍,比 EfficientNet 快4.9倍,比 ConvNeXt 快1.9倍。在类似的延迟下,FastViT 在 ImageNet 上获得的 Top-1 准确率比 MobileOne 高 4.2%,是一种极具竞争力的混合架构模型。
1 FastViT:快速卷积 Transformer 的混合视觉架构
论文名称:FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization

在CVer微信公众号后台回复:FastViT,可以下载本论文pdf、代码
论文:https://arxiv.org/pdf/2303.14189
代码:https://github.com/apple/ml-fastvit
1.1 背景和动机
本文的目标是做一个卷积,Attention 的低延时混合架构,因为这种架构有效地结合了 CNN 和 Transformer 的优势,在多个视觉任务上有竞争力。本文的目标是建立一个模型,实现 SOTA 的精度-延时 Trade-off。
本文的出发点是最近的像 CMT[1],LIT[2]等 CNN 和 Transformer 混合架构的模型都遵循 MetaFormer[3] 的架构,它由带有 skip-connection 的 token mixer 和带有 skip-connection 的前馈网络 (Feed Forward Network) 组成。由于增加了内存访问成本 (memory access cost),这些跳过连接在延迟方面占了很大的开销。为了解决这个延迟开销,本文提出 RepMixer,这是一个完全可以重参数化的令牌混合器,它的特点1是使用结构重参数化来删除 skip-connection。
RepMixer 的特点2是在训练期间为主要的层添加一些过参数化的额外的分支,以在训练时提升模型的精度,在推理时全部消除。RepMixer 的特点3是在网络中使用了大核卷积在前几个阶段替换掉 Self-Attention。具体是在前馈网络 (FFN) 层和 Patch Embedding 层中加入了大核卷积。这些更改对模型的总体延迟影响很小,同时提高了性能。
对于性能这块作者在 iPhone 12 Pro 设备和 NVIDIA RTX-2080Ti desktop GPU 上进行了详尽的分析,实验结果如下图1所示。可以看到在两种设备上,FastViT 都实现了最佳的精度-延时的权衡。
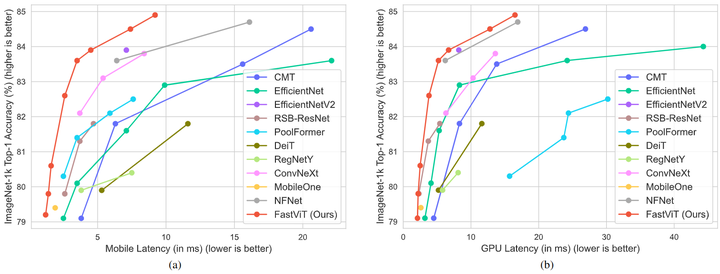
图1:iPhone 12 Pro 设备和 NVIDIA RTX-2080Ti desktop GPU 上的精度-延时比较
1.2 FastViT 模型架构
FastViT 整体架构如下图2所示。
Stage 的内部架构
FastViT 采用了4个 stage 的架构,每个 stage 相对于前一个的分辨率减半,通道数加倍。前3个 stage 的内部架构是一样的,都是训练的时候采用下式:
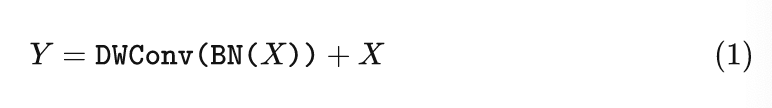
推理的时候采用结构重参数化得到下式:

第4个 stage 的内部架构如图2 (a) 所示,采用 Attention 来作为 token mixer,可能是为了性能考虑,宁愿不采用结构重参数化,牺牲延时成本,以换取更好的性能。
值得注意的是,每个 Stage 中的 FFN 使用的并不是传统的 FFN 架构,而是如图2 (c) 所示的,带有大核 7×7 卷积的 ConvFFN 架构。
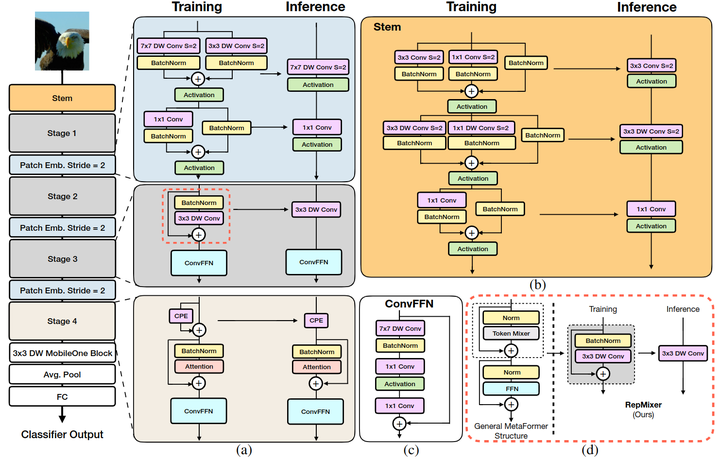
图2:FastViT 模型架构
Stem 的结构
Stem 是整个模型的起点,如图2 (b) 所示,FastViT 的 Stem 在推理时的结构是 3×3 卷积 + 3×3 Depth-wise 卷积 + 1×1 卷积。在训练时分别加上 1×1 分支或者 Identity 分支做结构重参数化。
Patch Embedding 的架构
Patch Embedding 是模型在 Stage 之间过渡的部分,FastViT 的 Patch Embedding 如图2 (a) 所示,在推理时的结构是 7×7 大 Kernel 的 Depth-wise 卷积 + 1×1 卷积。在训练时分别加上 3×3 分支做结构重参数化。
位置编码
位置编码使用条件位置编码,它是动态生成的,并以输入 token 的局部邻域为条件。这些编码是由 depth-wise 运算符生成的,并添加到 Patch Embedding 中。
1.3 RepMixer 的延时优势
如下图3所示,作者对比了 RepMixer 和高效的 Pooling 操作的延时情况。架构使用的是 MetaFormer S12,大概有 1.8 GFLOPs。作者在 iPhone 12 Pro 移动设备上为从 224×224 到 1024×1024 的各种输入分辨率的模型计时。可以看到 RepMixer 明显优于 Pooling,尤其是在较高分辨率的时候。在分辨率为 384×384 时,使用 RepMixer 可以降低 25.1% 的延迟,而在分辨率为 1024×1024 时,使用 RepMixer 可以降低 43.9% 的延迟。
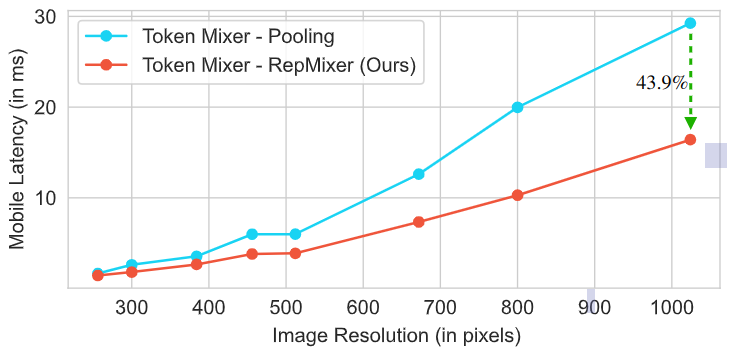
图3:RepMixer 的延时优势
1.4 FastViT 的大核卷积
RepMixer 的感受野是局部的。我们知道 Self-Attention 操作的感受野是全局的,但是 Self-Attention 操作计算量昂贵,因此之前有工作说使用大核卷积可以在计算量得到控制的情况下有效增加感受野的大小。FastViT 在两个位置引入了大核卷积,分别是 Patch Embedding 层和 FFN。对比实验的结果如下图4所示。将 V5 与 V3 进行比较,模型大小增加了 11.2%,延迟增加了 2.3 倍,而 Top-1 精度的增益相对较小,只有 0.4%,说明使用大核卷积来替换 Self-Attention 是一种高效,节约延时的方式。V2 比 V4 大 20%,延时比 V4 高 7.1%,同时在 ImageNet 上获得相似的 Top-1 精度。
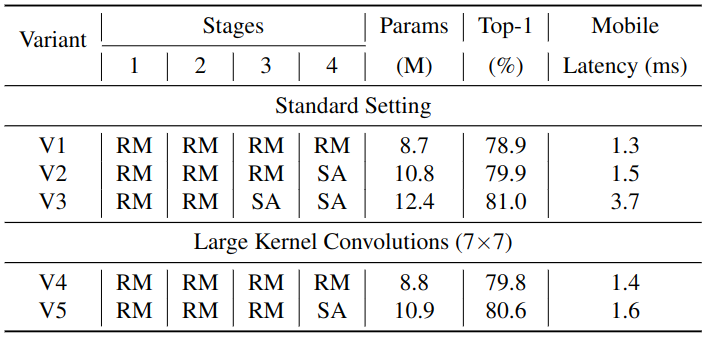
图4:大核卷积的消融实验
随着感受野的增加,大核卷积也有助于提高模型的鲁棒性。FastViT 各种模型的超参数配置如下图5所示。
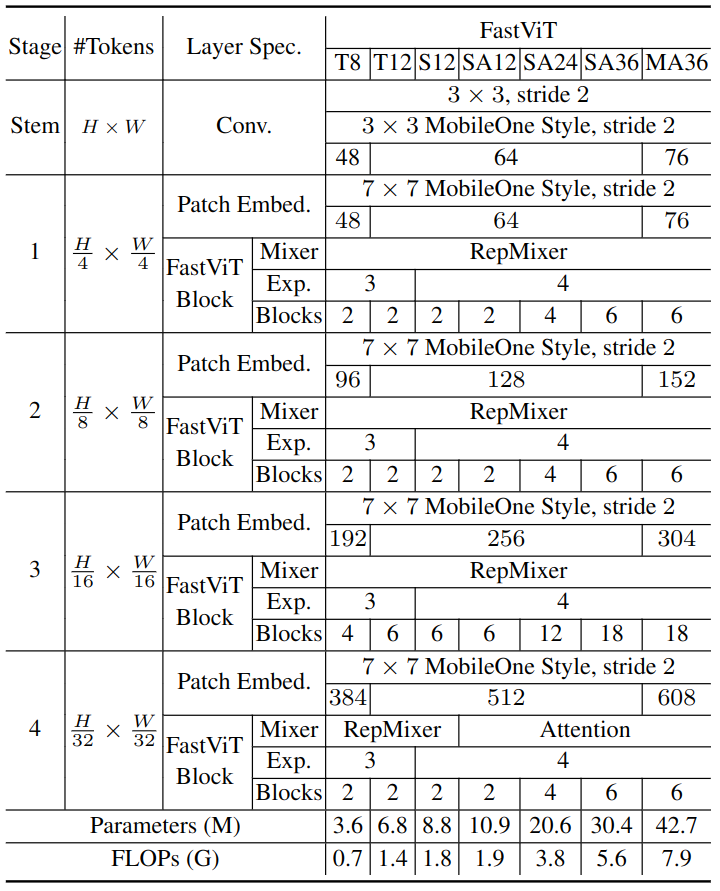
图5:FastViT 的超参数配置
1.5 实验结果
ImageNet-1K 图像分类实验结果
如下图6所示是 ImageNet-1K 图像分类实验结果。对于 iPhone 设备延时的测量,作者使用 Core ML Tools (v6.0) 导出模型,并在带有 iOS 16 的 iPhone12 Pro Max 上运行,并将所有模型的 Batch Size 大小设置为1。对于 GPU延时的测量,作者把模型导出为 TensorRT (v8.0.1.6) 格式,并在 NVIDIA RTX-2080Ti 上运行,Batch Size 大小为8,报告100次运行的中位数。
与 SOTA 模型的性能比较如下图6所示。本文的 FastViT 实现了最佳的精度-延时均衡,比如 FastViT-S12 在 iPhone 12 Pro 上比 MobileOne-S4 快 26.3%,GPU 上快 26.9%。在 83.9% 的 Top-1 精度下,FastViT-MA36 比 iPhone 12 Pro 上优化的 ConvNeXt-B 模型快 1.9倍, GPU上快2.0倍。
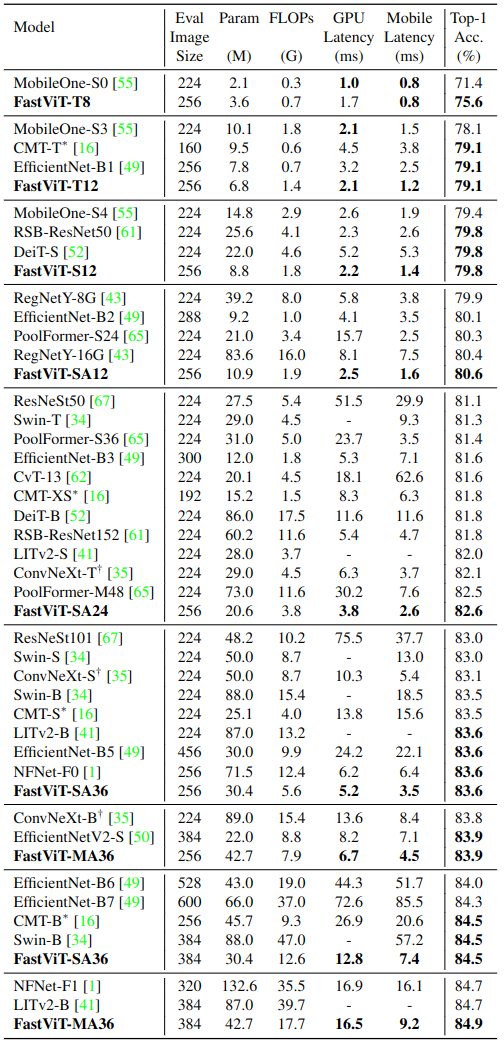
图6:ImageNet-1K 图像分类实验结果
知识蒸馏实验结果
如下图7所示是 FastViT 作为学生模型的知识蒸馏实验结果。作者遵循 DeiT 中的实验设置,RegNet16GF 作为教师模型,使用 Hard Distillation,其中教师的输出设置为 true label,一共训练300个 Epochs。FastViT 优于最近最先进的模型 EfficientFormer。FastViT-SA24 的性能与 EfficientFormer-L7 相似,但参数少3.8倍,FLOPs 少2.7倍,延迟低2.7倍。
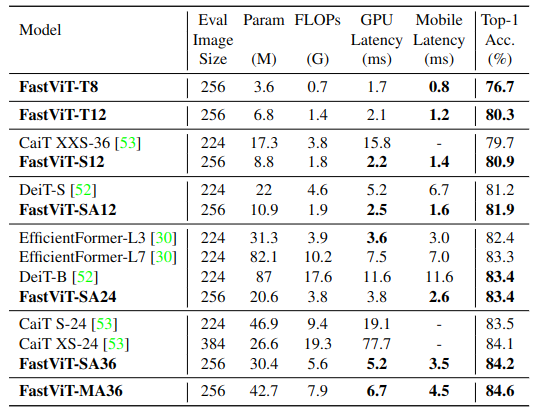
图7:知识蒸馏实验结果
目标检测和语义分割实验结果
对于语义分割,作者在 ADE20k 上验证了模型的性能语义分割模型头使用的是 Semantic FPN,所有的模型都是用预先训练好的对应图像分类模型的权重进行初始化。在 512×512 的设置上估计 FLOPs 和延迟。由于输入图像的分辨率较高,在表9和表10中,GPU 延迟在测量时使用了大小为2的 Batch Size。在图8中,作者将 FastViT 与最近的工作进行了比较。FastViT-MA36 的 mIoU 比 PoolFormer-M36 高 5.2%,但是 PoolFormer 具有更高的 FLOPs、参数量和延迟。
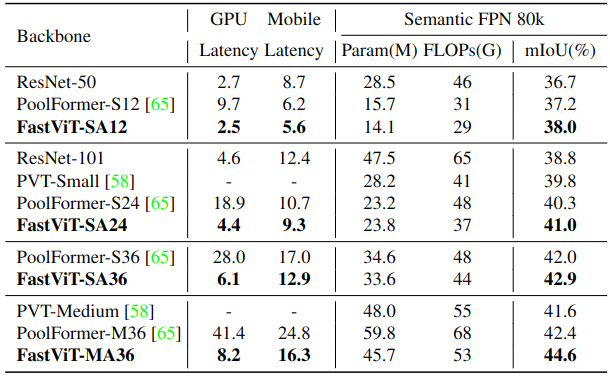
图8:语义分割实验结果
目标检测和实例分割实验实验 MS-COCO 数据集,实验结果如下图9所示。所有模型都使用 Mask-RCNN 目标检测和实例分割头按照 1x schedule 进行训练。所有的模型都是用预先训练好的对应图像分类模型的权重进行初始化。结果显示出 FastViT 在多种延迟机制下实现了最先进的性能。FastViT-MA36 模型的性能与 CMT-S 相似,但在桌面GPU 和移动设备上分别快2.4倍和4.3倍。
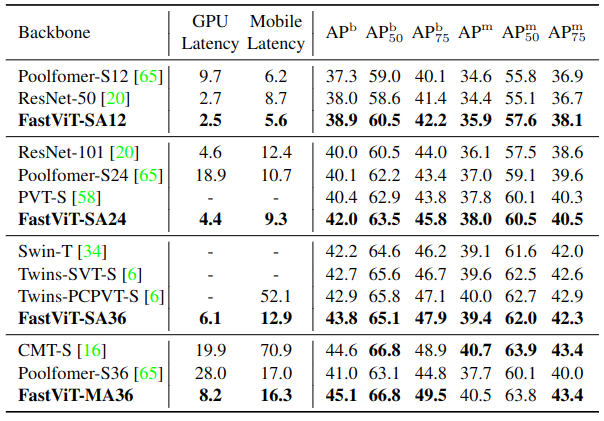
图9:目标检测和实例分割实验结果
总结
本文提出了一种通用的 CNN 和 Transformer 混合的视觉基础模型,是由 MobileOne 原班人马打造,可以看做是 MobileOne 的方法在 Transformer 上的一个改进型的应用。作者引入了一种新的 token mixer,叫做 RepMixer,它使用结构重新参数化技术,通过删除网络中的 Shortcut 来降低内存访问成本,尤其是在较高分辨率时。作者还提出了进一步的架构更改,以提高 ImageNet 分类任务和其他下游任务的性能。在移动设备和 ImageNet 数据集上的精度相同的前提下,FastViT 比 CMT 快3.5倍,比 EfficientNet 快4.9倍,比 ConvNeXt 快1.9倍。在类似的延迟下,FastViT 在 ImageNet 上获得的 Top-1 准确率比 MobileOne 高 4.2%,是一种极具竞争力的混合架构模型。
-
架构
+关注
关注
1文章
516浏览量
25499 -
数据集
+关注
关注
4文章
1208浏览量
24744 -
cnn
+关注
关注
3文章
353浏览量
22260
原文标题:ICCV 2023 | Apple提出FastViT:快速卷积和Transformer混合架构
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于卷积的基础模型InternImage网络技术分析
基于MLP的快速医学图像分割网络UNeXt相关资料分享
利用卷积调制构建一种新的ConvNet架构Conv2Former
一层卷积能做啥?一层卷积可以做超分吗?
简谈卷积—幽默笑话谈卷积
基于多步分解算法的解卷积混合盲源分离新方法
一种混合卷积窗及其在谐波分析中的应用
谷歌将AutoML应用于Transformer架构,翻译结果飙升!
基于卷积的框架有效实现及视觉Transformer背后的关键成分
利用Transformer和CNN 各自的优势以获得更好的分割性能

基于鲁棒神经架构的设计
RetNet架构和Transformer架构对比分析
介绍一种基于卷积和VIT的混合网络





 工商网监
工商网监
评论