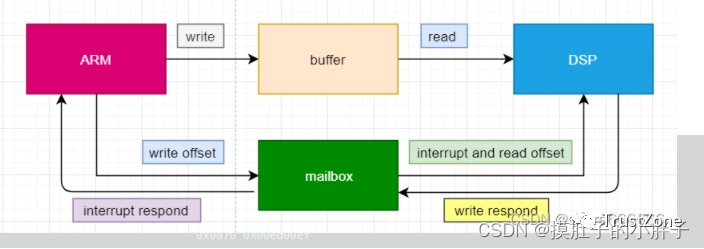
 使用mailbox和MUTEX的处理器间通信解决方案
使用mailbox和MUTEX的处理器间通信解决方案
现在业界的许多解决方案都包含多个处理器,或者是硬核处理器,如Arm A9、A53或R5,软核如MicroBlaze、Arm Cortex-M1/M3,或者是两者的组合。
Arm Cortex-M1被称为软核处理器,这主要是因为它在设计和应用上具有更大的灵活性。首先,软核处理器是可以根据需要进行定制的。在设计上,Arm Cortex-M1可以根据特定应用的需求进行定制。例如,在硬件资源有限的情况下,如FPGA设备,Cortex-M1能通过优化设计来满足面积预算要求。它采用了三阶段32位RISC处理器架构,并且使用了高效的指令集,例如Thumb-2指令集,这样就可以在有限的硬件资源下实现更高的性能。其次,软核处理器在应用上也更加灵活。它们可以集成到各种不同的硬件平台中,比如FPGA、ASIC等。同时,软核处理器可以使用不同的编程语言进行编程和控制,这样就可以适应更多的应用场景和需求。由于其灵活性和适应性,软核处理器在各种应用领域中更加受欢迎。
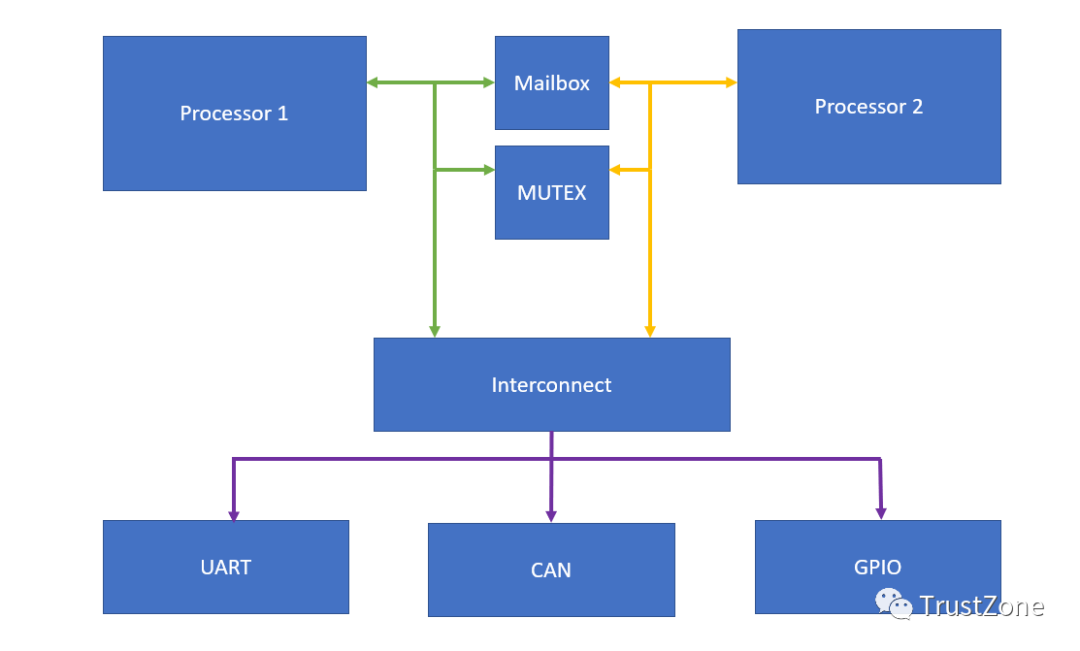
当我们实施多处理器解决方案时,通常我们会在可用的内核之间划分任务,利用每个内核来最大限度地提高其性能属性。例如,在PL中使用MicroBlaze或Cortex内核来执行专用的实时卸载任务,同时使用硬核应用程序处理器来执行更高级别的功能。
如果你做过复杂Soc相关的项目,应该对于这个肯定有所了解,用一个客制化的小核去协助主处理器做很多的事情,或者是多核SMP架构中,都会常看到这种核间通信的机制。
当然,要正确实施多处理器解决方案应用程序,解决方案中的所有处理器都需要能够安全可靠地通信和共享可用的系统资源。
这就是处理器间通信(IPC)的作用所在;如果正确实施,它可以实现处理器之间的安全可靠通信,同时也允许多个处理器共享公共资源,例如UART,而不会导致损坏的冲突。
mailbox和MUTEX在我们的IPC解决方案中扮演不同的角色:
这个字母一大写一小写突然看的我好难受但是又不想改哈哈哈
mailbox-允许使用基于FIFO的消息传递方法在多个处理器之间进行双向通信。
MUTEX-实现互斥锁,这允许处理器锁定共享资源,防止同时进行多次访问。
无论我们使用异构SoC还是FPGA,mailbox和MUTEX都在可编程逻辑(PL)中实现。
异构SoC(System on Chip)处理器是一种集成多个不同架构处理单元核心的SoC处理器。例如,TI的OMAP-L138(DSP C674x + ARM9)和AM5708(DSP C66x + ARM Cortex-A15)SoC处理器,以及Xilinx的ZYNQ(ARM Cortex-A9 + Artix-7/Kintex-7可编程逻辑架构)SoC处理器等。异构多核SoC处理器结合了不同类型处理器的优点。例如,ARM处理器廉价且耗能低,擅长进行控制操作和多媒体显示;DSP天生为数字信号处理而生,擅长进行专用算法运算;FPGA则擅长高速、多通道数据采集和信号传输。同时,核间通过各种通信方式,快速进行数据的传输和共享,使得异构多核SoC处理器能实现1+1>2的效果。
我们可以直接从Xilinx IP库在设计中实现mailbox和MUTEX。由于两者都用于两个处理器之间的通信,因此它们有两个从AXI输入。
使用mailbox或MUTEX,为每个处理器提供一个从AXI接口。
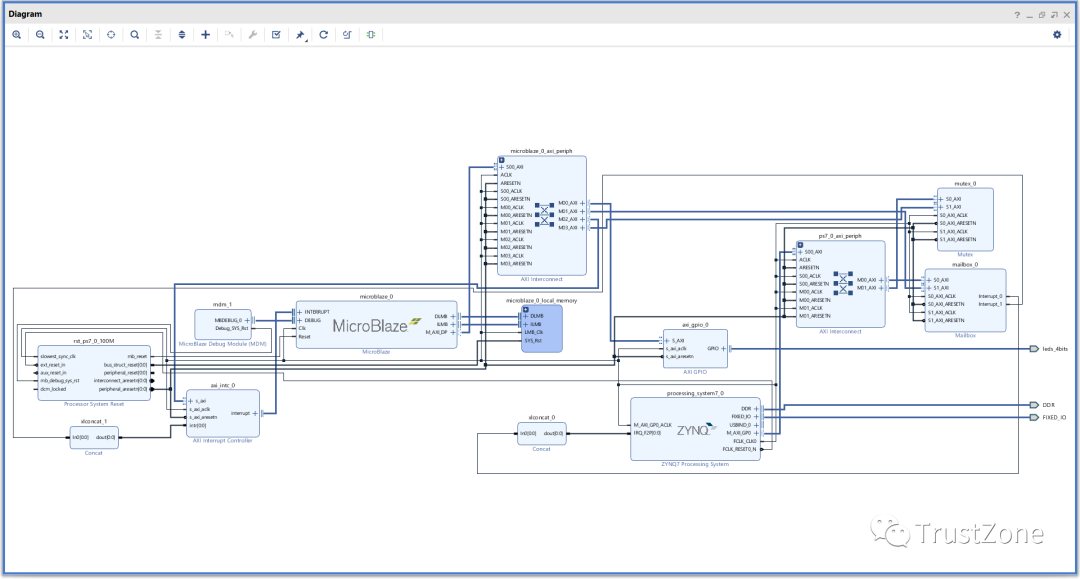
在本示例中,我们将使用Zynq与PL中的MicroBlaze通信和共享资源。
MicroBlaze将连接到驱动LED的GPIO。
要创建框图,我们首先需要添加Zynq处理系统IP,并运行块自动化以配置选定主板的Zynq。
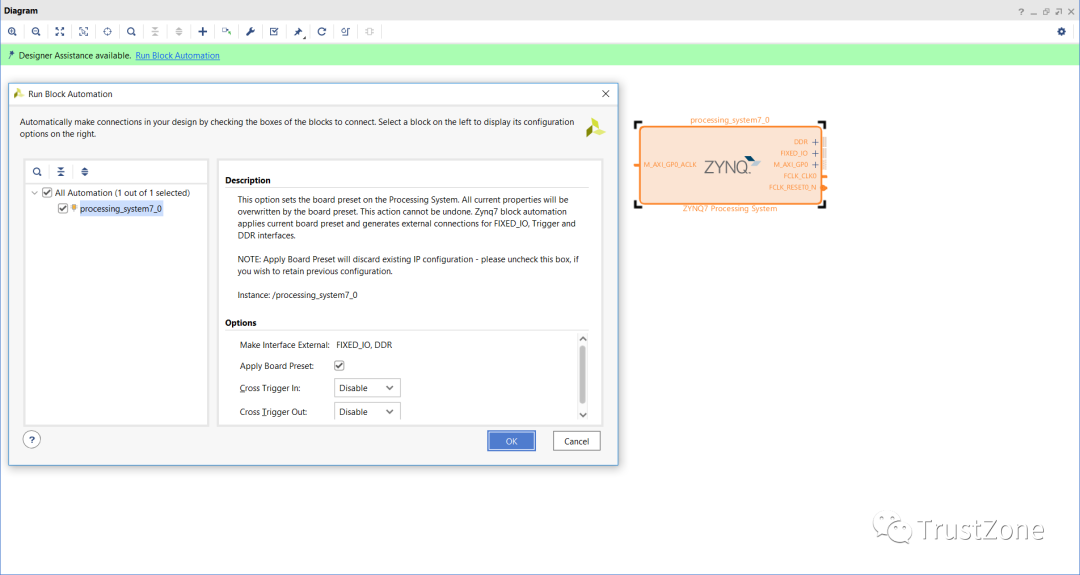
这是添加的一个处理系统。对于第二个,使用IP目录添加MicroBlaze。一旦MicroBlaze IP出现在框图中,双击重新自定义IP,选择微控制器预设,保持所有其他选项不变。
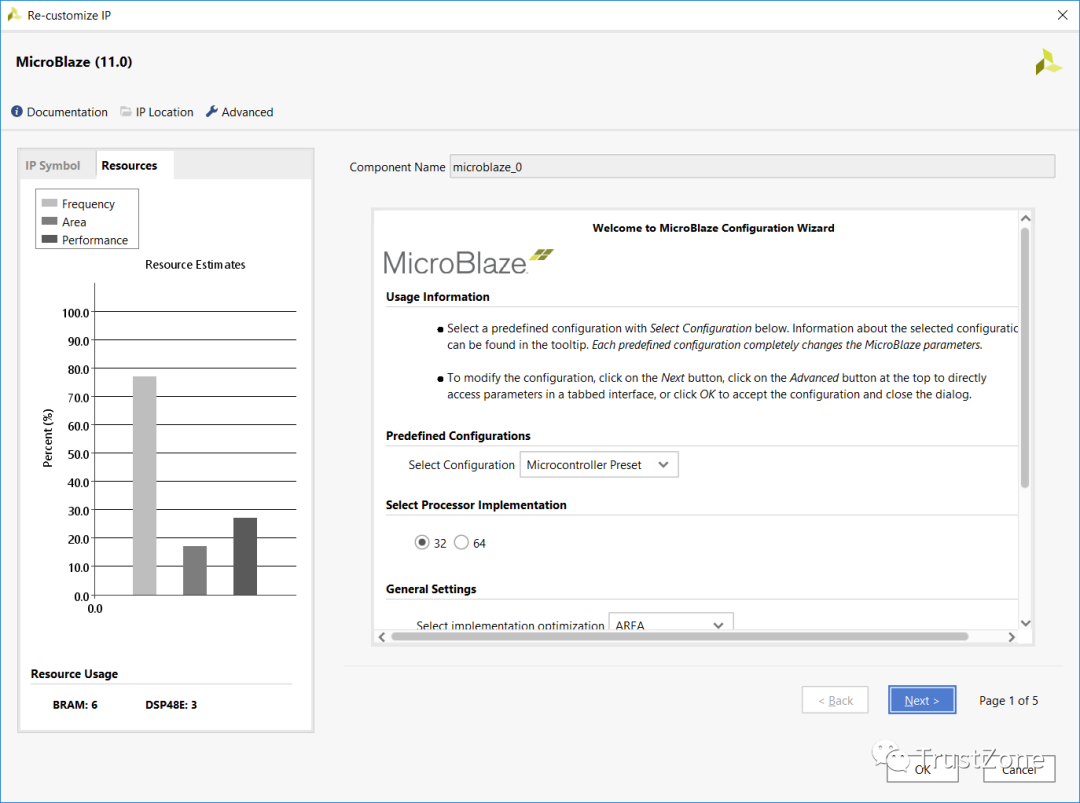
配置MicroBlaze IP后,下一步是运行其块自动化以创建MicroBlaze解决方案。这将添加到块RAM中,MicroBlaze将从中运行和调试设施。
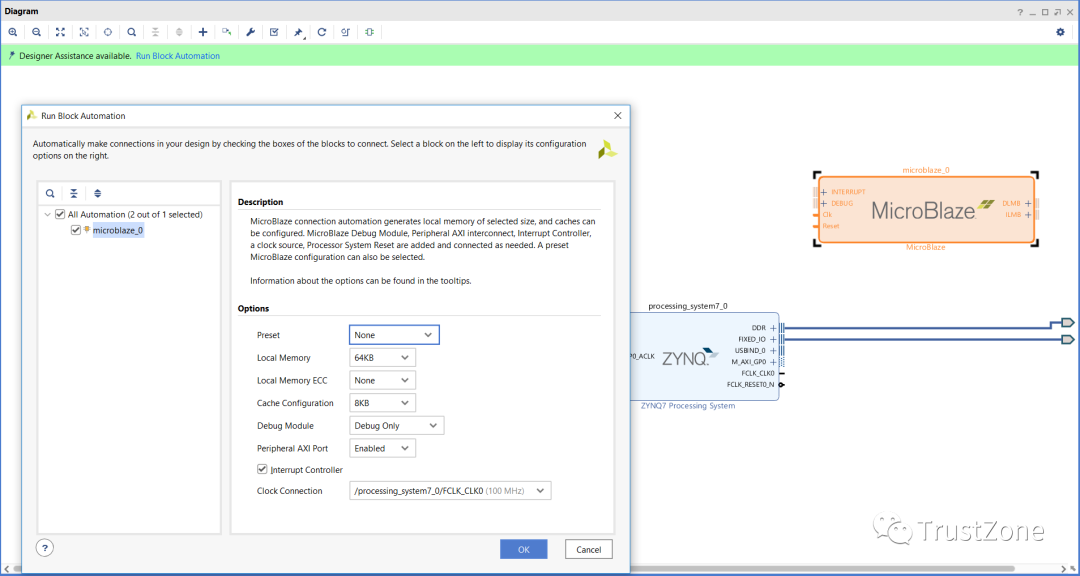
现在有了我们的两个处理系统解决方案,我们已经准备好添加到mailbox和MUTEX中-这两个解决方案都可以从Xilinx IP目录中添加。
完成后,我们可以使用连接自动化向导将它们连接到两个处理器系统AXI连接。
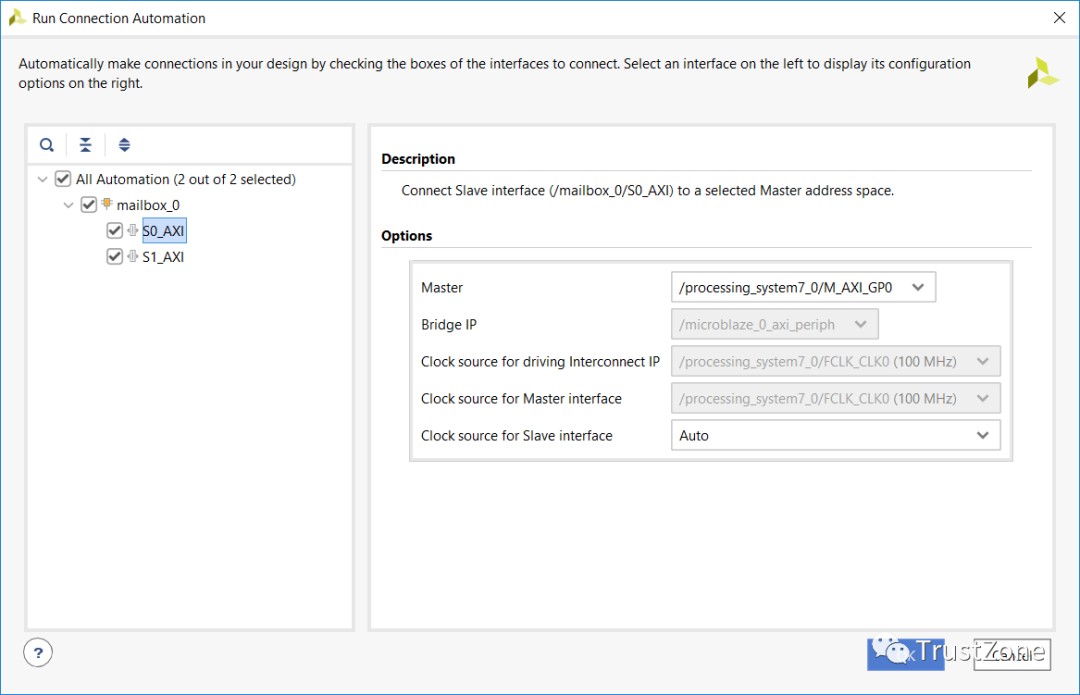
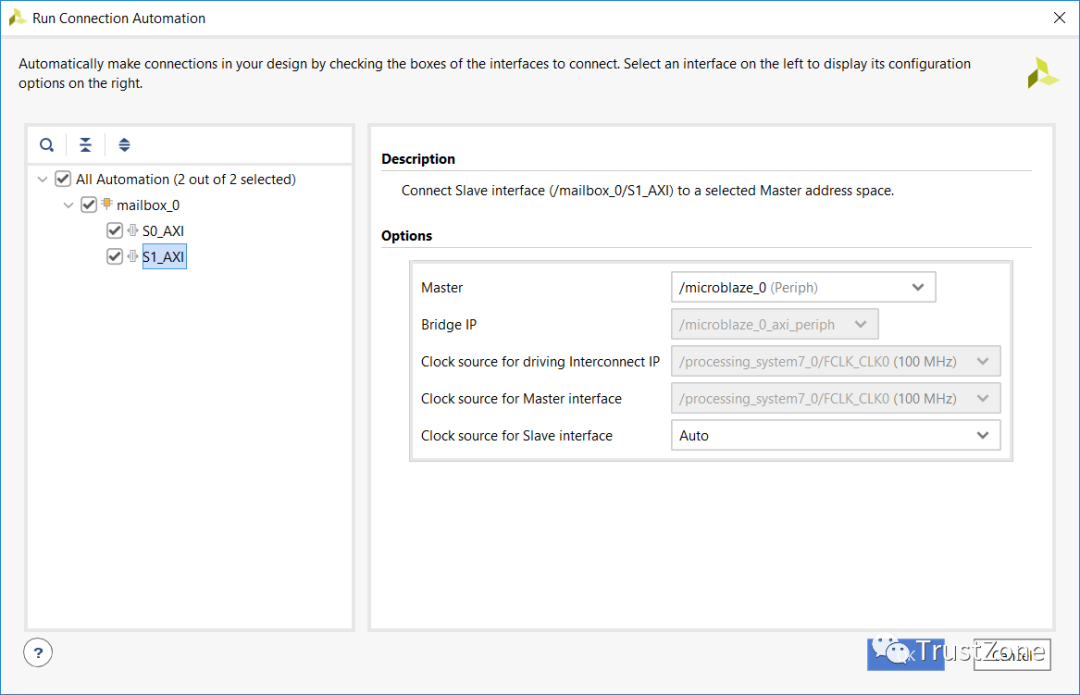
mailbox使用FIFO传输消息,其深度可以通过重复使用mailbox IP来配置。为确保在接收处理器上有效处理消息,mailbox能够在消息排队时向相关处理器生成中断。
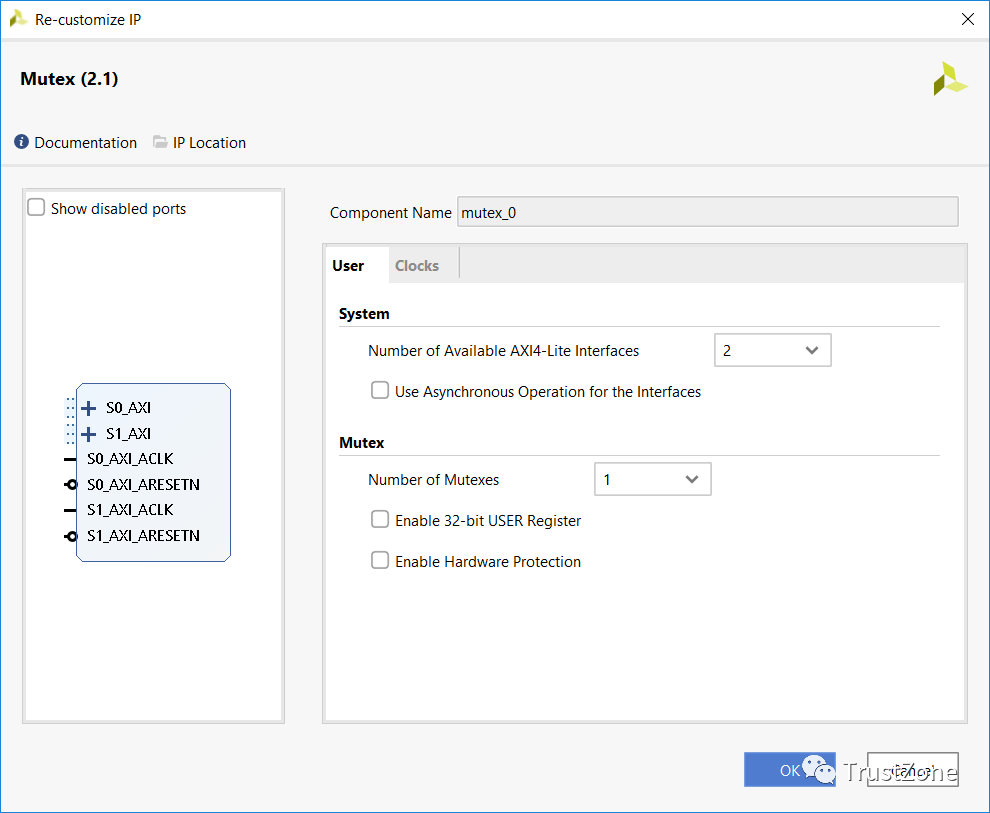
与mailbox一样,MUTEX非常相似,只是它不使用FIFO,而是为每个MUTEX使用寄存器来指示锁定状态。我们可以在多达8个处理器之间共享多达32个MUTEX。
为了防止处理器无意中或恶意地解锁互斥体,使用CPU ID。
完成的框图应与下面的框图相似。
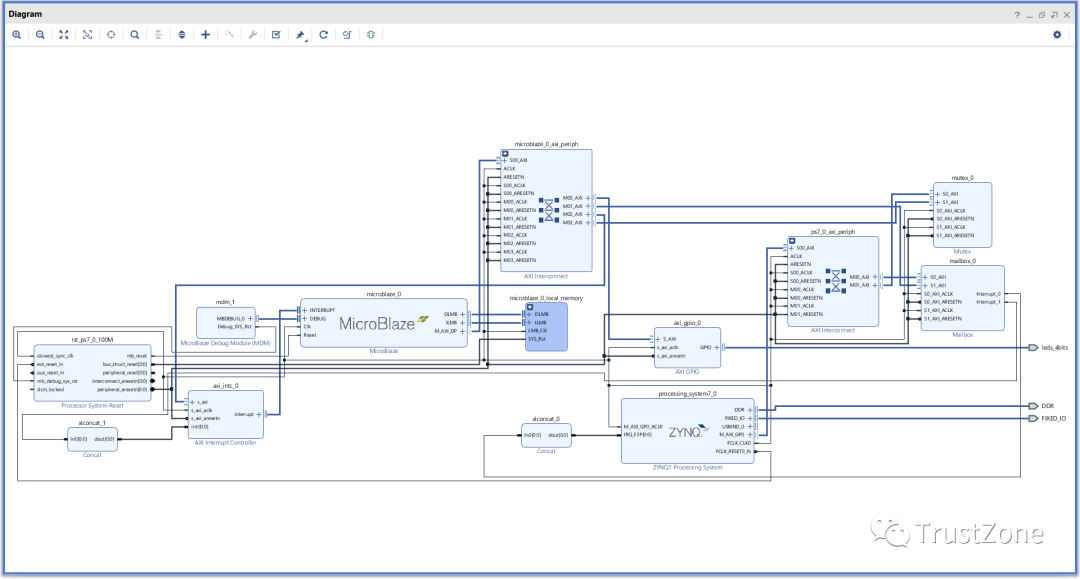
我们现在可以构建硬件并将设计导出到SDK,准备编写软件应用程序。
MailBox
我们检查了Vivado中实现处理器间通信(IPC)邮箱和互斥体所需的硬件构建。
现在,我们将研究如何使用mailbox将数据从一个处理器传输到另一个处理器。
请记住,在这个系统中,我们使用的是Zynq处理系统(PS) A9内核之一和可编程逻辑(PL)中的MicroBlaze。
两个处理器都使用AXI连接到mailbox,因此我们可以使用主板支持包(BSP)中提供的API很容易就实现了发送和接收消息。
将设计从Vivado导出到Xilinx SDK将将中的硬件规范导入到SDK。在硬件项目中检查HDF文件将显示MicroBlaze和Cortex-A9内存映射。
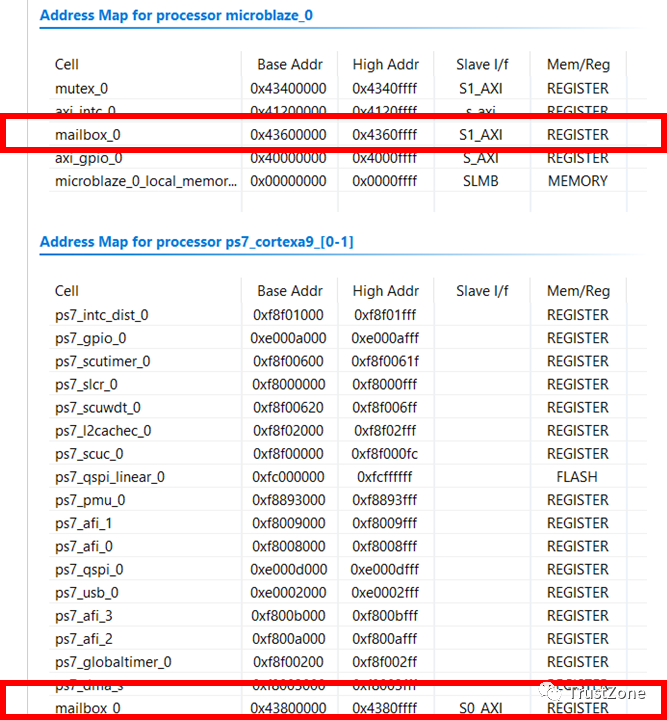
导入硬件定义后,下一步是创建两个应用程序-一个用于Arm Cortex-A9,另一个用于MicroBlaze。当我们创建这些应用程序时,请确保选择适当的处理器,并启用应用程序也创建BSP。
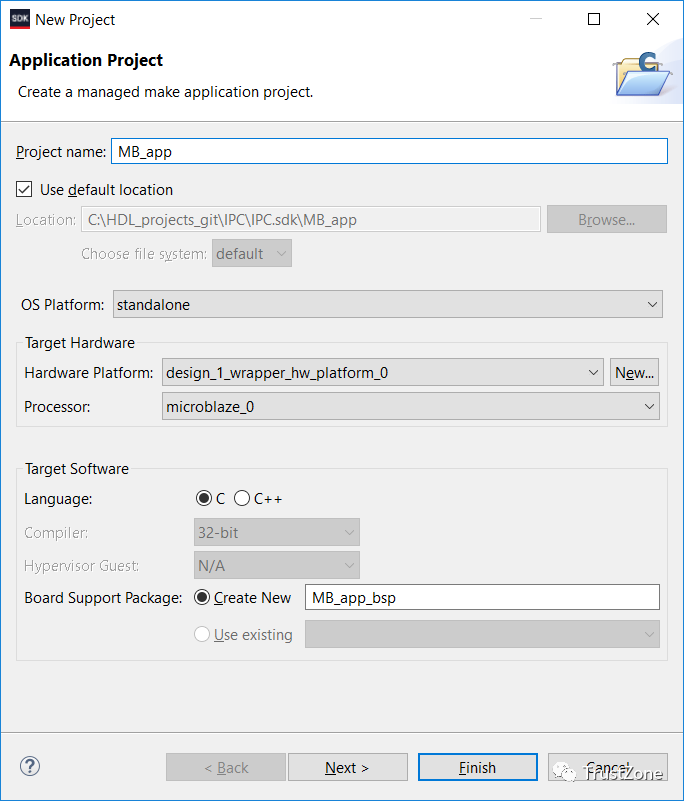
完成此操作后,我们应在SDK项目资源管理器中包含以下内容:
描述Vivado设计的硬件平台-这应用作所有应用程序和BSP的参考硬件平台。
两个主板支持包-PS Arm A9和MicroBlaze应用程序各一个。
两个应用程序-PS Arm A9和MicroBlaze各一个。
在此应用程序中,MicroBlaze将报告何时启动并运行,以及LED的打开或关闭状态。
为此,我们将使用BSP提供的mailbox API,两者都提供相同的API供使用。
这些文件包含在xmbox.h文件中,使我们能够初始化和配置mailbox 以使用。
要从mailbox 读取和写入,有几个功能:
XMbox_Read ( XMbox * InstancePtr, u32 * BufferPtr, u32 RequestedBytes, u32 * BytesRecvdPtr) XMbox_ReadBlocking ( XMbox * InstancePtr, u32 * BufferPtr, u32 RequestedBytes ) XMbox_Write(XMbox* InstancePtr,u32 * BufferPtr,u32 RequestedBytes, u32 * BytesSentPtr ) XMbox_WriteBlocking ( XMbox * InstancePtr, u32 * BufferPtr, u32 RequestedBytes )
在上述函数中,实例指针引用mailbox 声明,缓冲区指针指向我们存储TX或RX数据的位置。虽然请求的字节是传输的大小,但读和写函数也报告实际发送或接收的字节数,因为这可能与请求的字节数不同。
这里特别指出,对于所有函数,发送或接收的字节数应该是4的倍数;如果不是,则需要一些填充。如果没有请求4字节的倍数,将生成断言。
当然,阻塞读写不会报告实际发送或接收的字节数,因为函数实际上会阻塞,直到发送或接收请求的字节数。
除了发送和接收功能,还有许多内部管理功能:
中断使能、状态和禁用
发送和接收中断FIFO阈值定义
FFIO管理和控制,包括检查空和满、刷新和复位 通过使用这些功能,我们能够为Arm A9内核和MicroBlaze创建简单的应用程序。
A9程序很简单。一旦mailbox 初始化,它就会永远循环等待来自MicroBlaze的消息,然后再通过终端打印出来。
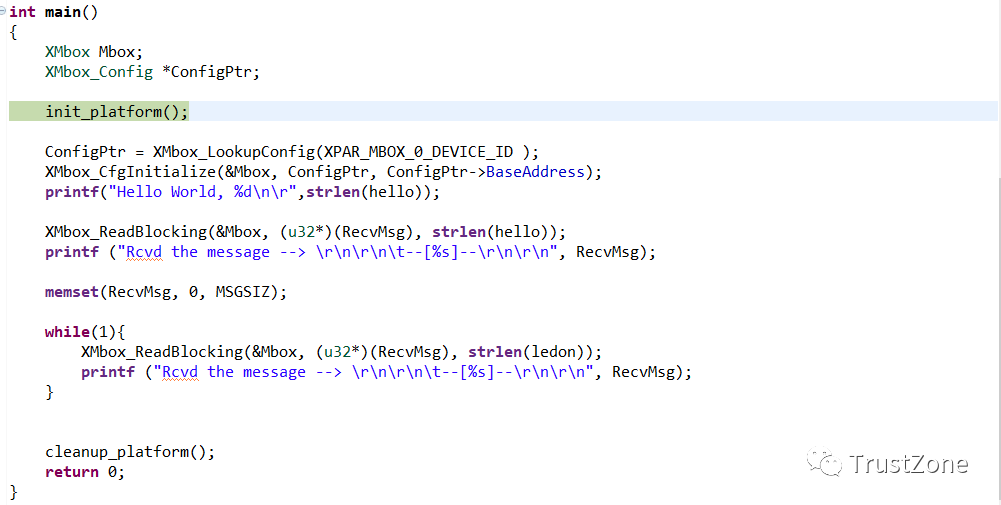
MicroBlaze应用程序要复杂一些。它在启动时向A9内核发送消息,然后每次切换LED时,它还发送有关LED状态的消息。
要在Zynq上运行此操作,我们需要创建一个新的调试配置,该配置下载两个处理器。为了确保在多处理器环境中取得成功,我们需要考虑两个处理器的启动。在此调试配置中,选择:
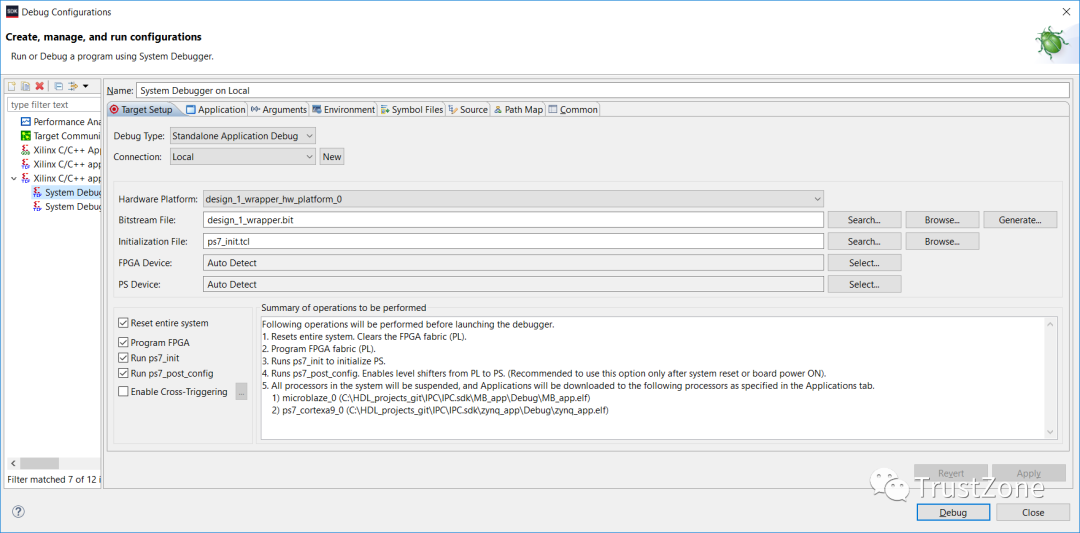
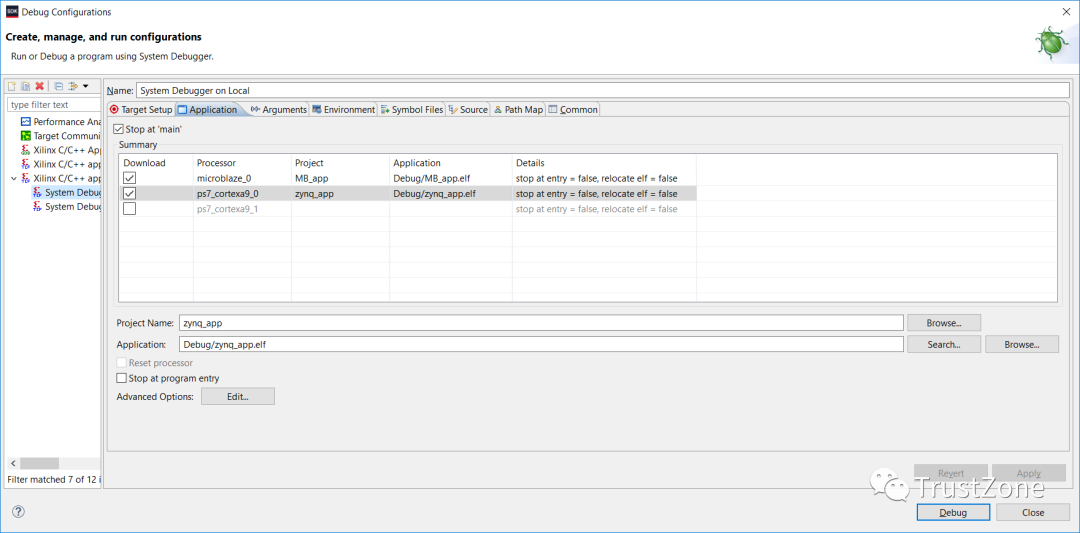
调试配置运行时,将配置设备,并下载两个处理器的应用程序。然后,两个处理器将在main()的入口点暂停。
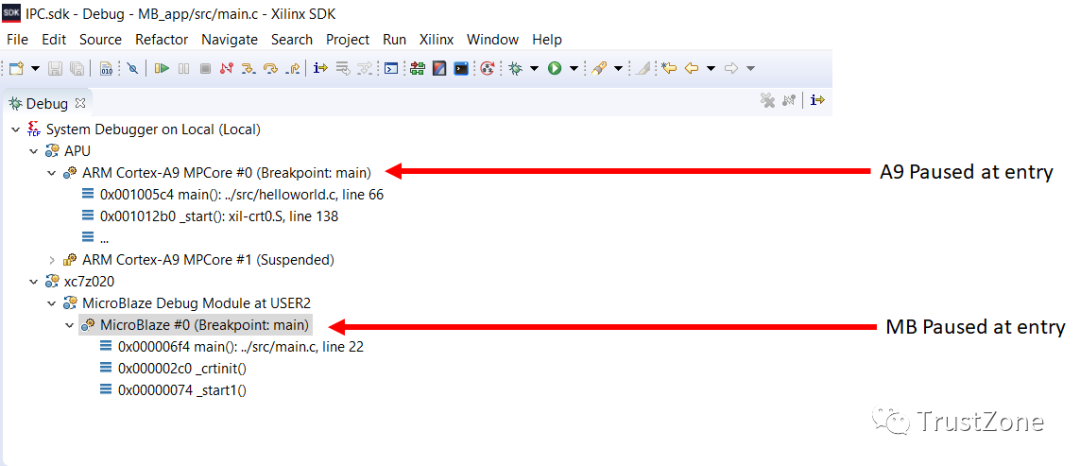
对于此示例应用程序,请首先启动A9处理器,然后启动MicroBlaze处理器。
当使用上面的示例代码执行此操作时,就可以在终端窗口中看到了以下内容:
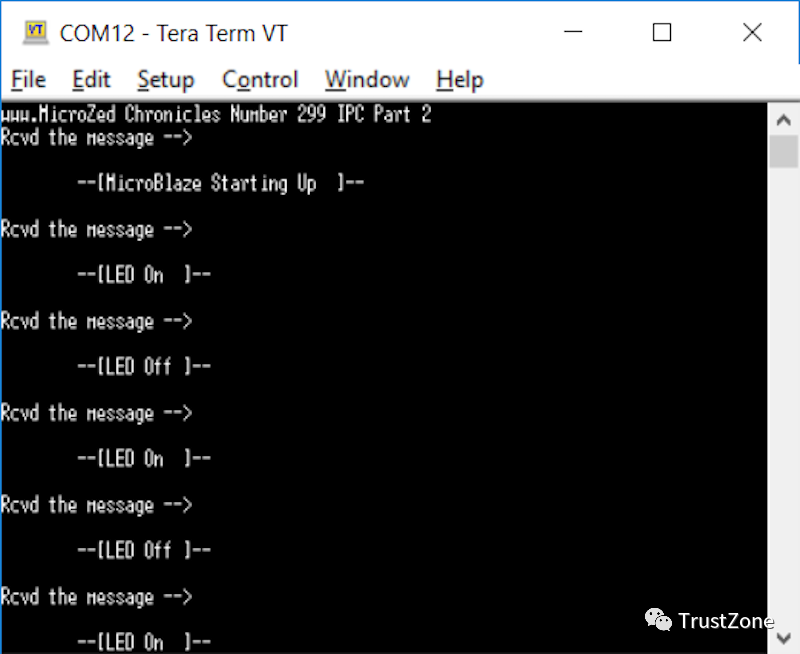
两个处理器都在通信!
接下来,我们关注点放到互斥体。
MUTEX
当我们的设备中有多个处理器时,多个处理器可能希望同时共享公共资源(例如内存或UART)。如果对这些资源的访问不受控制,它可能会迅速而容易地导致腐败。比如说串口打印,混淆在一起。
互斥似乎是最简单的问题之一,当然可以使用一个标志,双方都可以测试,如果是自由设置,则声称对资源的访问。
然而,出现了一个问题,即在一个处理器测试和设置标志之间的时间内,对方处理器也可以将标志视为空闲,并开始其锁定过程。
这通常被称为竞争条件,围绕相互排斥的其他潜在陷阱包括僵局和饥饿。处理器无法访问资源(饥饿)或系统锁定,因为每个处理器都在等待不同的锁定进程进行(死锁)。
一般提到互斥,就会涉及到死锁问题。
有许多解决方案可以解决这些问题,包括使用多个标志。虽然,当考虑到除了最简单的情况之外的任何事情时,它们开始变得非常复杂,简言之,它们并不容易扩展。
解决竞争条件的方法是确保测试和设置操作合并到一个操作中,也就是说,如果我们测试互斥标记,并且它是自由的,那么它就会被设置。
这正是Xilinx互斥体的工作方式,当我们写入互斥体时,如果它是空闲的,处理器将被分配资源。
在我们的硬件设计中设计互斥体非常简单,每个处理器都有自己的AXI接口。由于互斥体能够支持1到8个处理器,因此在使用操作系统和在同一处理器上运行的任务之间共享资源时,我们可以只使用一个接口。
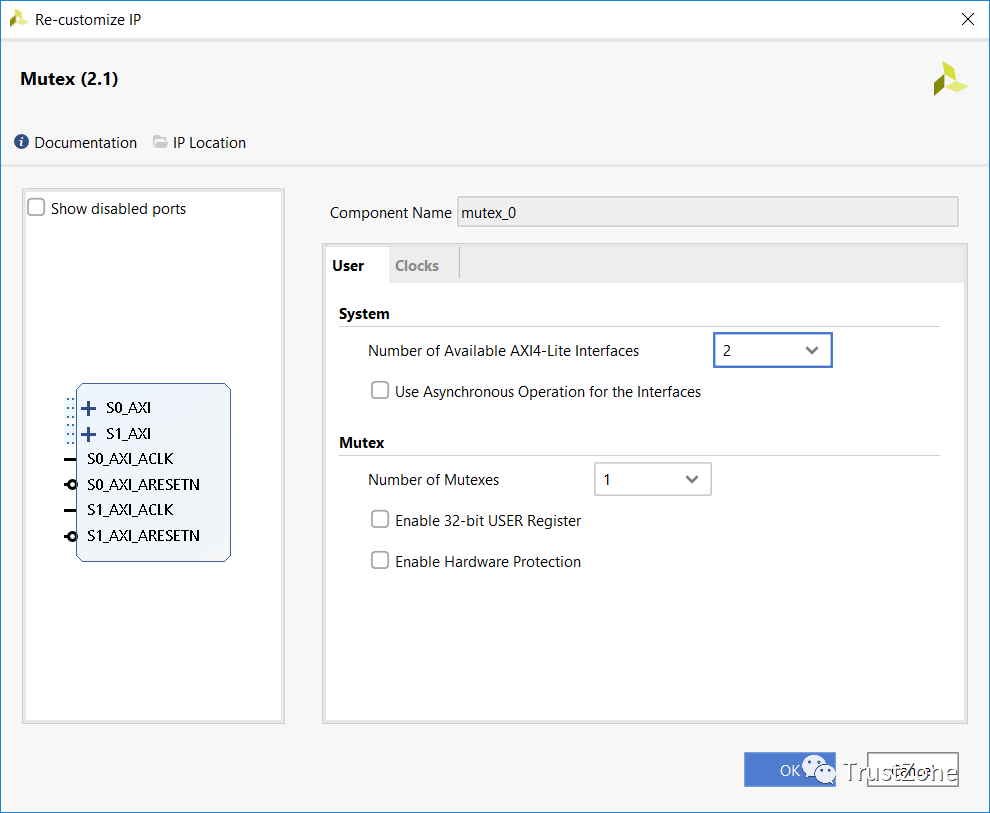
在一个互斥体实例化中,我们最多能够实现32个互斥体。不过,对于这个例子,我们只有一个。当我们实施互斥体时,如果我们愿意,我们还可以在AXI级别启用硬件保护。
如果我们选择启用此功能,则可选AXI HWID字段用于锁定和解锁互斥体,防止CPU伪造CPU ID并错误地解锁。
每个互斥体还有一个可选的32位寄存器,如有必要,可用于在处理器之间共享配置数据。
当谈到在我们的软件中使用互斥体时,我们可以使用主板支持包(BSP)为两个处理器提供的Xmutex API (xmutex.h)。在此API中,我们将找到函数类:
生命周期管理-初始化和状态报告
用户寄存器-设置和取消设置用户寄存器
互斥锁操作-锁定和解锁互斥锁的功能
与我们上面看到的mailbox示例类似,互斥操作提供阻止和非阻止调用。阻塞调用由函数XMutex_Lock()提供,而无阻塞函数调用是XMutex_Trylock()。
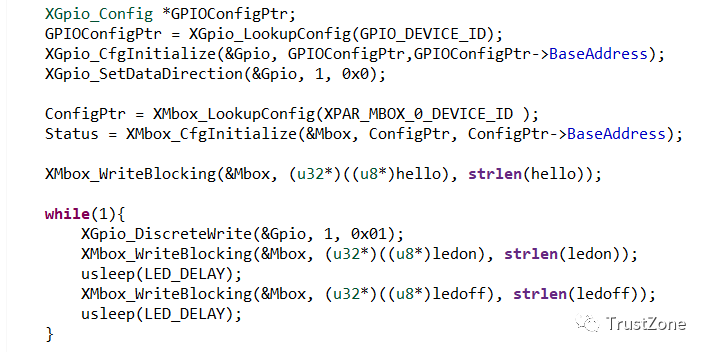
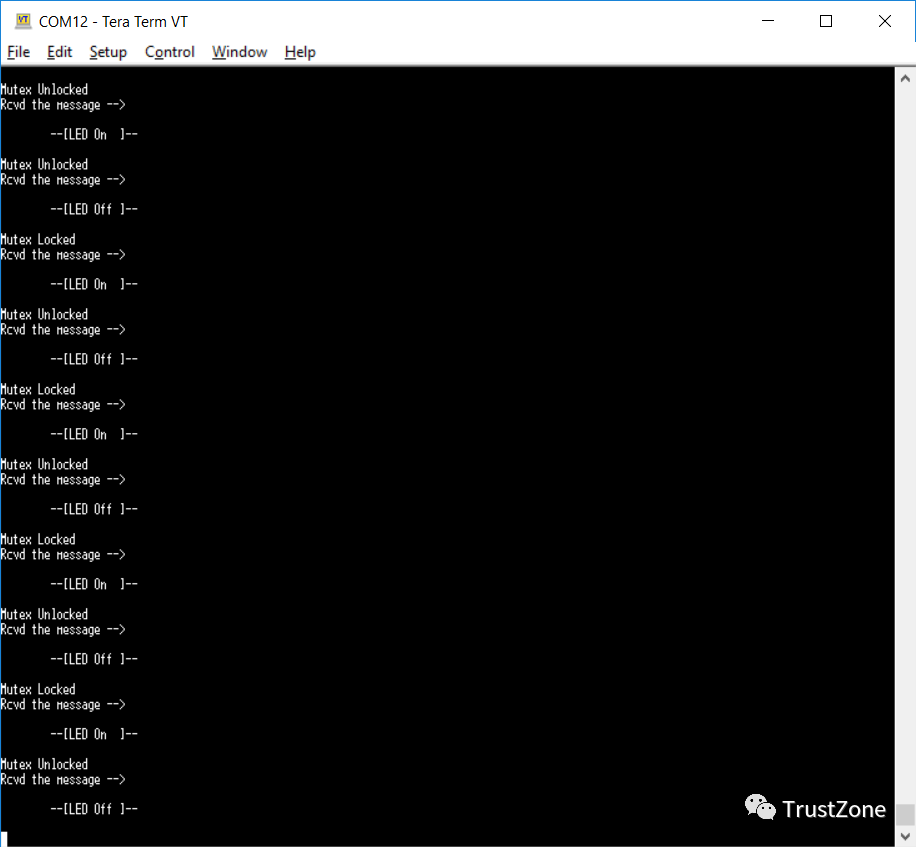
为了演示互斥体的应用,我们将更新我们的SW应用程序,以便MircoBlaze应用程序在设置LED时锁定互斥体,并在清除LED时解锁互斥体。
然后,Zynq应用程序将测试互斥体,并报告它是否与LED状态一起设置。一个简单但有效的示例,说明互斥函数是如何工作的。
两个处理器的代码如下。


当使用上面的代码运行应用程序时,在终端窗口中观察到以下情况。这表示在访问LED资源时,MicroBlaze正在按预期锁定和解锁互斥体。
-
处理器
+关注
关注
68文章
19273浏览量
229724 -
FPGA
+关注
关注
1629文章
21734浏览量
603111 -
ARM
+关注
关注
134文章
9091浏览量
367441 -
asic
+关注
关注
34文章
1200浏览量
120476 -
硬核处理器
+关注
关注
0文章
3浏览量
6792
原文标题:MUTEX
文章出处:【微信号:谈思实验室,微信公众号:谈思实验室】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于Sitara处理器工业以太网应用的快速启动系统解决方案
核间通信(IPC)解决方案
优化双带双模手机的处理器间通信

基于双MicroBlaze软核处理器的SOPC系统
一种基于Mailbox核间机制的多核处理系统

Jacinto7 TDA4VM处理器的核间通信解决方案
Jacinto 7核间通信解决方案
核间通信可能的实现机制





 工商网监
工商网监
评论