 存算一体芯片的技术壁垒
存算一体芯片的技术壁垒
作为后摩尔时代发展的必然趋势之一,存算一体越来越受到行业的关注。在存算十问的前六问中,我们梳理了存算一体的技术路线、挑战和通用性等问题,这一次我们从技术的壁垒入手,邀请后摩智能的几位研发人员来谈谈,从学术到商用,存算一体的技术壁垒体现在哪里,后摩智能又是如何从IP、电路设计、架构设计等层面突破技术难题,形成自己独有的技术壁垒。
Q1存算一体芯片是一个壁垒比较高的技术方向吗?它的壁垒体现在哪些方面?
存算一体芯片是技术壁垒很高的一个方向。从芯片底层到软件划分的话,主要体现在以下几个方面:
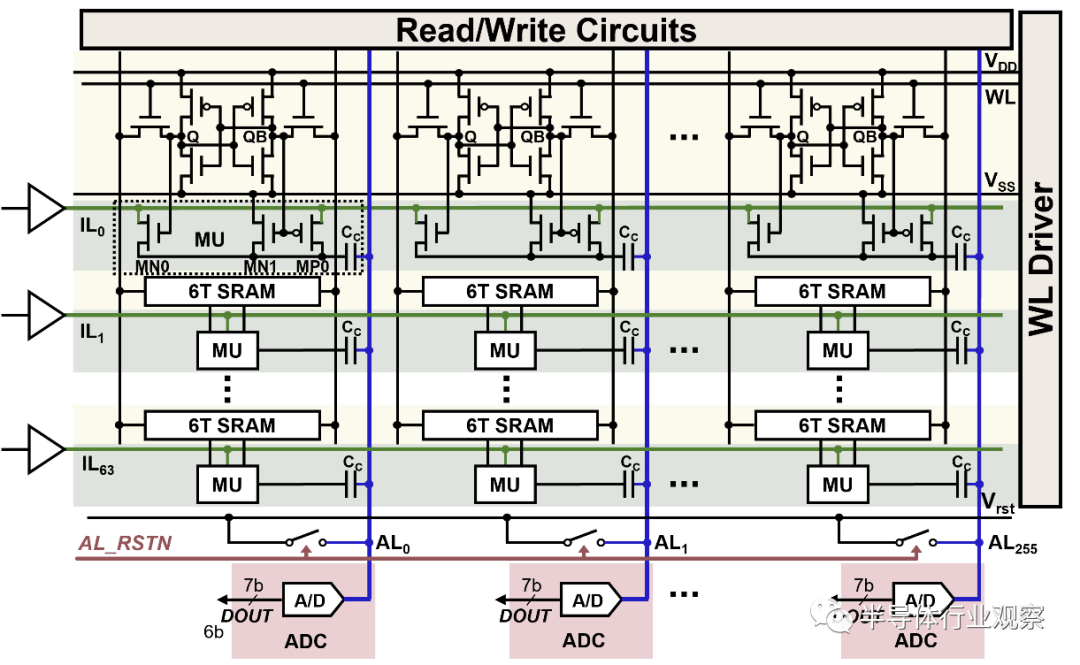
(1)CIM的基本运算单元(即MACRO)的设计是第一个难点。作为存算一体芯片的基石,存内计算IP的功能和性能直接影响存算一体芯片的整体表现。存内计算IP依托的存储介质和所采用的计算范式繁多且呈“百花齐放”。
以SRAM CIM MACRO为例,因为需要修改存储阵列以加入计算的逻辑单元、支持“存储-计算”双工作模 式,并且在满足计算性能的同时还需要保证阵列的规整性来优化面积效率、保证阵列的可靠性、可测试性等。需要SRAM专家针对性的进行设计。值得强调的是,当前的EDA工具不支持设计流程,必须自主设计相应的EDA工具来配合整个过程,包括margin, aging, EMIR, PPA的分析、Sign-off、PI/S等工具。
(2)当完成CIM MACRO设计后,需要将大量的MACRO高效的组织在一起来处理形式多样的Tensor运算,同时配合一定的通用算力来满足各种长尾算子(通常指计算量较小的非Tensor算子)的处理能力。这里涉及到多个MACRO之间的数据流组织方式,即如何将一个Tensor的运算分配到多个MACRO协同处理,完成这个目标需要精心进行架构设计,并且通常需要一个高效的片上网络(NoC)来支持。
另外,通常需要在芯片内配置大容量的SRAM来减少片外DRAM的访存需求,如何组织SRAM,并且配合上述计算流程,也是一个重要的设计内容。
(3)存算一体AI核和SoC的架构设计和实现:存内计算IP提供了高能效的并行计算模式,但同样受限于其支持运算类型的局限性,因而对于存算一体AI核和SoC的架构设计的难度和复杂度要求急剧上升,既要充分利用存内计算IP本身运算的高效性,又要减少存内计算IP之间的数据传输,同时还要兼顾支持网络算子的通用性和物理实现的可行性。
(4)存算一体软件编译器的快速部署和实现:软件工具链对于发挥存算芯片的效率也至关重要。软件需要将模型切分成合适的Tensor算子,然后生成相应的指令调用底层硬件来处理。
在后端算子性能优化时,需要打破算子的边界,要解决层间流水,多模型流水并行,结合存算架构的特点完成优化。业界有很多开源框架的 IR 可以参考,像 MLIR 和 TVM 的 Relay 和 TIR,这些开源的 IR 无法很好地处理上述优化需求,我们根据存算架构 AI Core 的特点,设计了一层 IR ,更好地解决了数据流分析、数据依赖分析,可以更方便地进行层间调度和切分等优化。
同时,对于自动驾驶等场景,通过算子融合来提升计算和访存效率是非常关键的一个优化目标,需要工具链自动化的完成算子的融合、调度及对大容量SRAM的高效管理,以同时提升芯片的利用率和应用的开发效率等。
Q2相较于传统的芯片电路设计,后摩智能的存算电路架构设计和电路设计有何特殊性和优点?
(1)电路方面:自主设计的定制CIM MACRO,包括定制的乘法单元、加法树、读写电路、累加器等,进一步拉近计算和存储的距离显著提升性能和能效,通过SRAM单元替代寄存器实现更高的计算密度、更低的读写功耗。相比传统电路设计面效提升2倍左右、能效提升一个量级左右;
(2)架构:层次化的架构设计,将大量MACRO有效组织在一起;CIM MACRO负责Tensor计算,自主设计的RISC-V Vector扩展架构配合定制的SFU负责长尾算子处理,同时满足处理效率和通用性的需求;定制化的NoC,满足多个MACRO和SRAM之间的数据通信需求等
后摩智能的存算电路主要采用了基于全数字域的存算路径,通过对存储单元和计算单元的深度定制来实现高能效的计算目的,从而减少访存开销,打破存储墙瓶颈,这种从SPEC到signoff的全定制化流程研发周期长,且对于研发迭代效率要求极高。
同时,还需要兼顾大规模量产和车规需求,开发特有的CIM BIST和硬件修复电路,保障芯片良率和车规认证。
Q3后摩智能自研的芯片IPU架构,从一代到二代的天枢、天玑,相对于传统架构的优点和创新之处是什么?

这张图就是我们已经推出的H30芯片天枢架构IPU图。
我们的芯片里有4个IPU核,都挂在系统总线NoC上。这4个核是完全一样的设计。对于每一个Core,又由4个Tile组成,每个Tile就对应了一个硬件线程,它们可以独立进行不同的计算,也可以联合起来做同一个计算。
每个Tile内部有CPU、Tensor Engine,Special Function Unit,Vector Processor和多通道DMA,这些计算单元可以直接共享一个多Bank的共享存储资源。这样的架构使得AI计算不但不用在多个处理器,例如CPU,GPU,DSP之间分配任务,甚至数据不用出AI核,就可以高效的完成全部端到端的AI计算。
这个架构里还有一个重要的部分就是数据的传输。就像我们人和人之间需要更好的沟通一样,我们的计算单元之间,也需要很好的共享数据和消息。
我们设计了专用的数据传输总线,可以灵活的在各个Tile,以及各个Core之间建立高速的直接的数据传输通道,而不需要通过系统总线和缓存。
CIM macro有计算形式单一、需求输入数据整齐、没有累加器等缺点。第一代天枢架构为这些功能上的缺点做了相应的补充,使得CIM macro能够真正的应用在大规模AI计算中,而不只停留在paper上;另一方面,将CIM macro用于工程上,有BIST,yield,PI/SI等问题需要摸索解决,第一代架构也在这方面做了规划和适配。
我们下一代的天璇架构IPU设计理念将会是:基于Mesh互联的AI cluster。采用Mesh的互联结构,可以将计算单元的数量灵活的配置成M行N列,根据场景需求,AI算力规模可大可小。
审核编辑:汤梓红
-
芯片
+关注
关注
453文章
50360浏览量
421623 -
sram
+关注
关注
6文章
763浏览量
114629 -
AI
+关注
关注
87文章
30072浏览量
268332 -
存算一体
+关注
关注
0文章
100浏览量
4287
发布评论请先 登录
相关推荐
存算一体大算力AI芯片将逐渐走向落地应用







 工商网监
工商网监
评论