 Dojo对标A100性能强劲,AI应用场景拓展
Dojo对标A100性能强劲,AI应用场景拓展
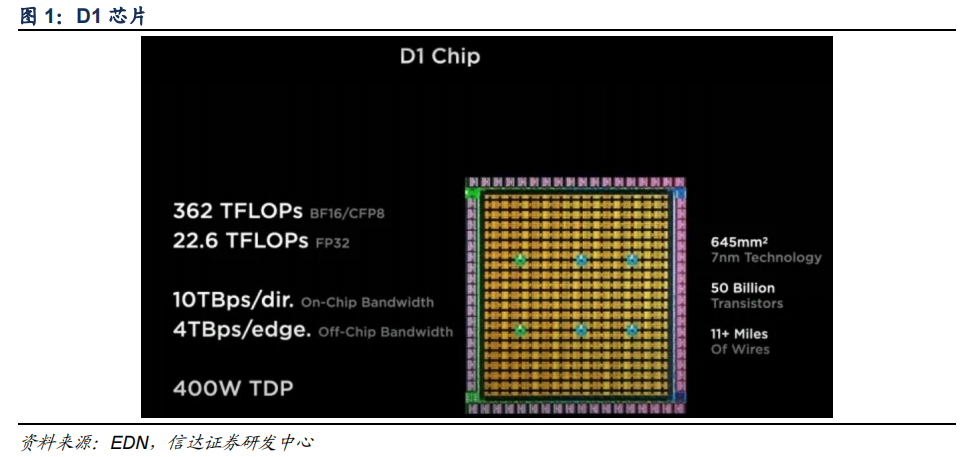
D1 芯片对标英伟达 A100。D1采用台积电 7nm 制程,面积约为 645mm²,包含 500 亿颗晶体管,BF16、CFP8 算力可达 362TFLOPS,FP32 算力可达 22.6TFLOPS。特斯拉D1芯片对标英伟达 A100,英伟达 A100 同样采用台积电 7nm 制程,面积为 826mm²,晶体管数量达 542 亿颗,FP32 峰值算力为 19.5TFLOPS。
D1 芯片依次组成 Tranining tile、Tray、机柜、ExaPOD。特斯拉并未将 SoC 从晶圆上切下来,而是将所有 SoC 连接。25 个 D1 芯片组成了一个 Training Tile 多晶片模组(MCM),每个 D1 芯片功耗 400W,一个 Training Tile 功耗为 15kW。此外,6 个 Training Tile 组成一个 tray,再由两个 Tray 组成一个机柜,10 个机柜组成 ExaPOD,BF16/CFP8 峰值算力达到 1.1EFLOPS(百亿亿次浮点运算),并拥有 1.3TB 高速 SRAM 和 13TB 高带宽 DRAM。
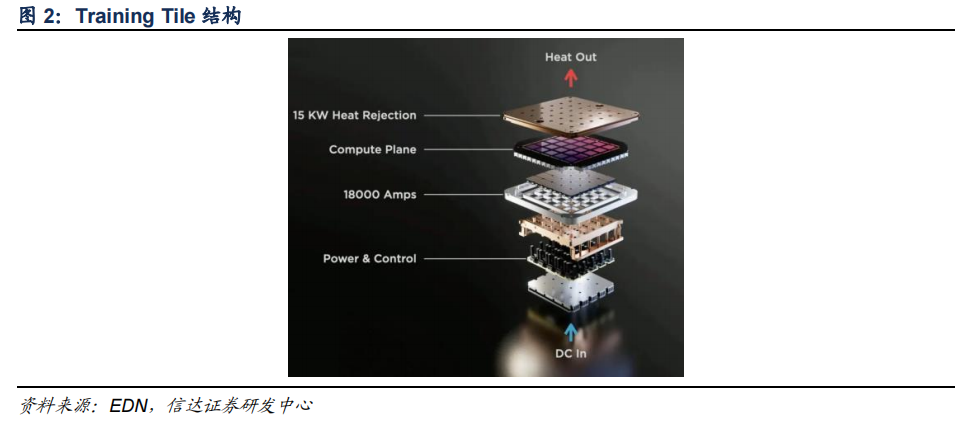

Dojo 的设计思想是通过较高的对称性来实现 scale out 能力。在单个 Training tile 上,由于并未将芯片切下,为了提高效率和降低成本,特斯拉并未在片上集成 DRAM 等器件,这与许多通用 GPU 有所不同。集群节点之间以 2D mesh 连接,边缘则通过 Interface-processors负责内存池数据搬运。

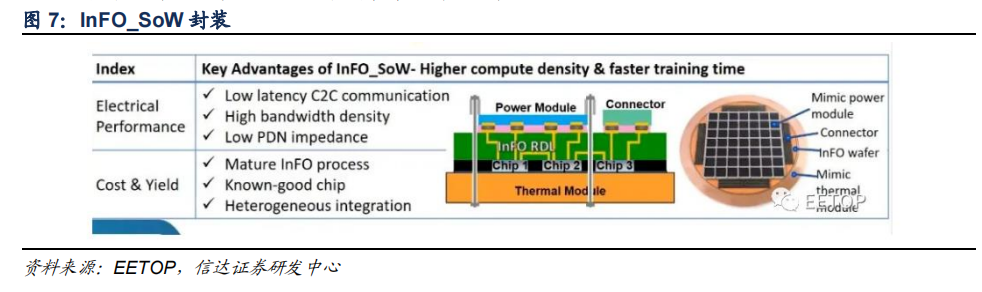
显而易见,D1 芯片需要高速的互联来实现,台积电 SoW 封装技术提供了这一条件。InFO_SoW 取消了衬底和 PCB 的使用,使得多个芯片阵列使解决方案获得晶圆级优势,以获得低延时、高带宽等优势。此外除了异构芯片集成外,其 wafer-field 处理能力还支持基于小芯片的设计,以实现更大的成本节约和设计灵活性。
在部分模型上,Dojo 能实现相对 A100 更高的性能。例如在图像分类模型 ResNet-50 上,Dojo 可以实现比英伟达 A100 更高的帧率。而在用于预测汽车周围物体所占空间的神经网络模型 Occupancy Networks 上,相比英伟达 A100,Dojo 能实现性能的倍增。

特斯拉将大力投资基础设施,2024 年有望达 100Exa-Flops 算力。特斯拉目前 AI 基础设施较少,仅约 4000 个 V100 和约 16000 个 A100。而 Microsoft 和 Meta 等公司拥有超过 10万个 GPU。据特斯拉规划,2024 年有望达 100Exa-Flops 算力。
特斯拉拥有海量数据库,数据价值亟待挖掘。Model3 传包含 8 个摄像头,1 个毫米波雷达,12 个超声波雷达,位置分别为:1-车牌的上方装有一个摄像头;2-超声波传感器(如果配备)位于前后保险杠中;3-各门柱均装有一个摄像头;4-后视镜上方的挡风玻璃上装有三个摄像头;5-每块前翼子板上装有一个摄像头;6-雷达(如果配备)安装在前保险杠后面。特斯拉车型销量形势良好,通过传感器件建立了庞大的数据库,但受限于硬件限制,无法充分挖掘数据价值,Dojo 量产有望突破瓶颈。
自建 AI 基础设施,AI 或赋能特斯拉快速成长。特斯拉 Dojo 性能强大,我们认为,除加速自身智驾进程外,或可拓展至其他应用领域,如机器人等。此外,特斯拉也可能成为一家云服务提供商,向相关厂商提供自身算力或模型服务。
-
传感器
+关注
关注
2550文章
51035浏览量
753044 -
AI
+关注
关注
87文章
30728浏览量
268871 -
毫米波雷达
+关注
关注
107文章
1043浏览量
64342
原文标题:Dojo对标A100性能强劲,AI应用场景拓展
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英伟达a100和h100哪个强?英伟达A100和H100的区别
NanoEdge AI的技术原理、应用场景及优势
新一代AI ISP视频处理模组,对标Hi3559A、Hi3519A平台性能
NVIDIA推出了基于A100的DGX A100
英伟达a100和a800的区别
英伟达a100和a800参数对比





 工商网监
工商网监
评论