 【AI简报20230922期】华人AI芯片挑战英伟达,深入浅出理解Transformer
【AI简报20230922期】华人AI芯片挑战英伟达,深入浅出理解Transformer
1. OpenAI DALL·E 3来了,集成ChatGPT,生图效果太炸了
原文:https://mp.weixin.qq.com/s/P4HwP3VwzSnndD5LSt8pXw
终于,OpenAI 的文生图 AI 工具 DALL-E 系列迎来了最新版本 DALL・E 3,而上个版本 DALL・E 2 还是在去年 4 月推出的。
OpenAI 表示,「DALL・E 3 比以往系统更能理解细微差别和细节,让用户更加轻松地将自己的想法转化为非常准确的图像。」

除了炸裂的生图效果之外,此次 DALL・E 3 的最大特点是与 ChatGPT 的集成,它原生构建在 ChatGPT 之上,用 ChatGPT 来创建、拓展和优化 prompt。这样一来,用户无需在 prompt 上花费太多时间。具体来讲,通过使用 ChatGPT,用户不必绞尽脑汁地想出详细的 prompt 来引导 DALL・E 3 了。当输入一个想法时,ChatGPT 会自动为 DALL・E 3 生成量身定制的、详细的 prompt。同时用户也可以使用自己的 prompt。至于集成 ChatGPT 后的效果怎么样?OpenAI CEO 山姆・奥特曼兴奋地展示了 DALL・E 3 的连续性生成结果,简直称得上完整的「故事片」。
ChatGPT 集成并不是 DALL・E 3 唯一的新特点,它还能生成更高质量的图像,更准确地反映提示内容。DALL・E 将文本 prompt 转换成图像。即使是 DALL・E 2 ,也会经常忽略特定的措辞导致出错。但 OpenAI 的研究人员说,最新版本能更好地理解上下文,并且处理较长的 prompt 效果会更好。此外,它还能更好地处理向来困扰图像生成模型的内容,如文本和人手。
可以看到在上图将 prompt 中的每一个细节都表现出来了。半透明的质感、画面底部的波涛汹涌、阳光与厚厚的云层、心脏中的宇宙景象,以及难倒很多图像生成模型的文字展现,DALL・E 3 都顺利地完成了这些任务。那么,DALL・E 3 能不能成为 Midjourney 「杀手」呢?推特用户 @MattGarciaEth 已经将二者生成的图片进行了很多比较。大家觉得哪个更好呢?
目前,DALL・E 3 处于研究预览版本。OpenAI 计划将 DALL・E 3 的发布时间错开, 将于 10 月份首先向 ChatGPT Plus 和 ChatGPT Enterprise 用户发布,随后在秋季向研究实验室及其 API 服务发布。不过,该公司没有透露何时或者是否计划发布免费的公开版本。
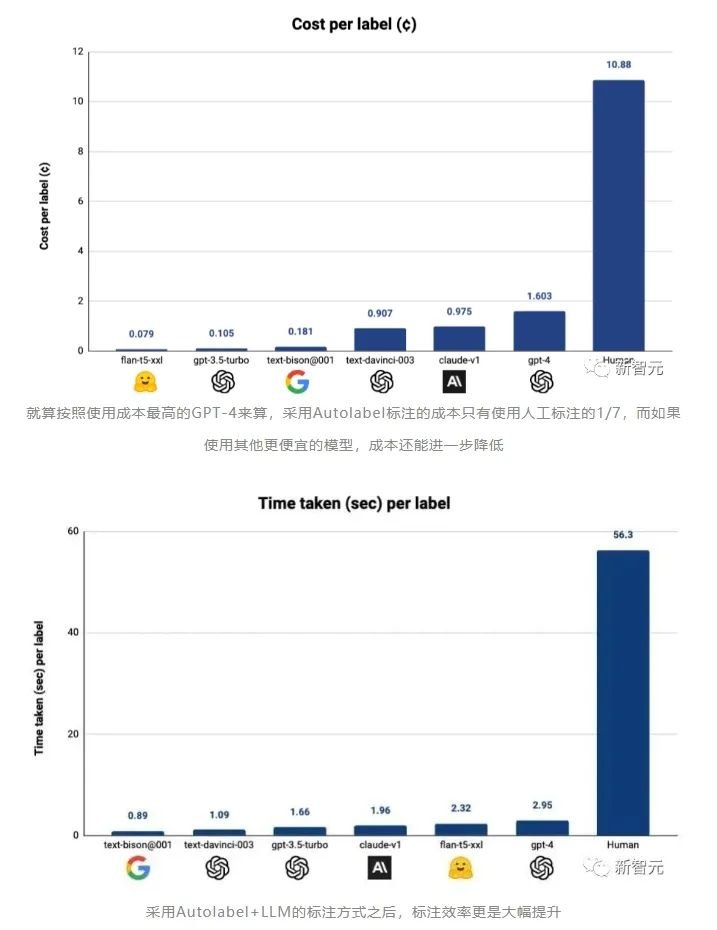
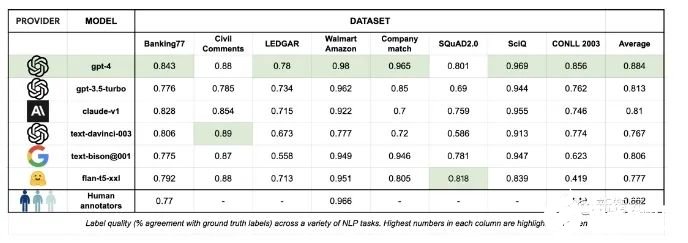
2. GPT-4终结人工标注!AI标注比人类标注效率高100倍,成本仅1/7
原文:https://mp.weixin.qq.com/s/AwXljsdH1SG0qzNeYTaprA除了GPU,还有什么是训练一个高效的大模型必不可少且同样难以获取的资源?高质量的数据。OpenAI正是借助基于人类标注的数据,才一举从众多大模型企业中脱颖而出,让ChatGPT成为了大模型竞争中阶段性的胜利者。但同时,OpenAI也因为使用非洲廉价的人工进行数据标注,被各种媒体口诛笔伐。
而那些参与数据标注的工人们,也因为长期暴露在有毒内容中,受到了不可逆的心理创伤。
总之,对于数据标注,一定需要找到一个新的方法,才能避免大量使用人工标注带来的包括道德风险在内的其他潜在麻烦。所以,包括谷歌,Anthropic在内的AI巨头和大型独角兽,都在进行数据标注自动化的探索。


3. Transformer+强化学习,谷歌DeepMind让大模型成为机器人感知世界的大脑
原文:https://mp.weixin.qq.com/s/pp9viv9IfdiLMFXgy4h56A在开发机器人学习方法时,如果能整合大型多样化数据集,再组合使用强大的富有表现力的模型(如 Transformer),那么就有望开发出具备泛化能力且广泛适用的策略,从而让机器人能学会很好地处理各种不同的任务。比如说,这些策略可让机器人遵从自然语言指令,执行多阶段行为,适应各种不同环境和目标,甚至适用于不同的机器人形态。但是,近期在机器人学习领域出现的强大模型都是使用监督学习方法训练得到的。因此,所得策略的性能表现受限于人类演示者提供高质量演示数据的程度。这种限制的原因有二。
- 第一,我们希望机器人系统能比人类远程操作者更加熟练,利用硬件的全部潜力来快速、流畅和可靠地完成任务。
- 第二,我们希望机器人系统能更擅长自动积累经验,而不是完全依赖高质量的演示。

- 论文:https://q-transformer.github.io/assets/q-transformer.pdf
- 项目:https://q-transformer.github.io/
DeepMind 也进行了实验评估 —— 既有用于严格比较的仿真实验,也有用于实际验证的大规模真实世界实验;其中学习了大规模的基于文本的多任务策略,结果验证了 Q-Transformer 的有效性。在真实世界实验中,他们使用的数据集包含 3.8 万个成功演示和 2 万个失败的自动收集的场景,这些数据是通过 13 台机器人在 700 多个任务上收集的。Q-Transformer 的表现优于之前提出的用于大规模机器人强化学习的架构,以及之前提出的 Decision Transformer 等基于 Transformer 的模型。
4. Transformer的上下文学习能力是哪来的?
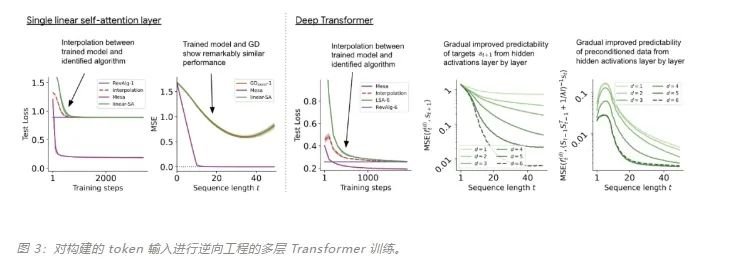
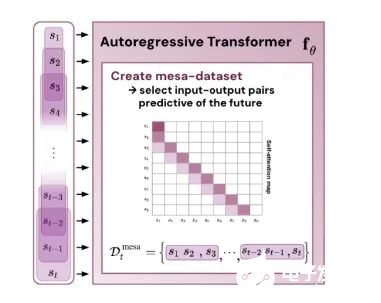
原文:https://mp.weixin.qq.com/s/7eRwSwIE-X-qfjAsOCW1WQ为什么 transformer 性能这么好?它给众多大语言模型带来的上下文学习 (In-Context Learning) 能力是从何而来?在人工智能领域里,transformer 已成为深度学习中的主导模型,但人们对于它卓越性能的理论基础却一直研究不足。最近,来自 Google AI、苏黎世联邦理工学院、Google DeepMind 研究人员的新研究尝试为我们揭开谜底。在新研究中,他们对 transformer 进行了逆向工程,寻找到了一些优化方法。论文《Uncovering mesa-optimization algorithms in Transformers》:

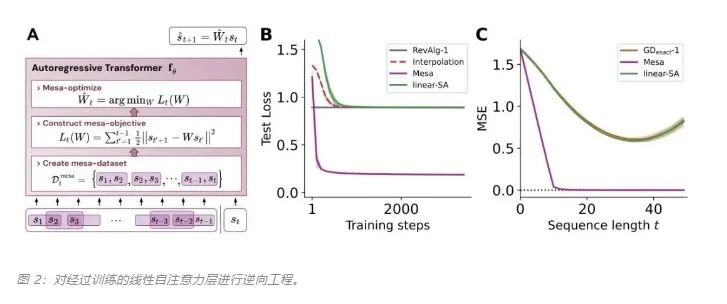
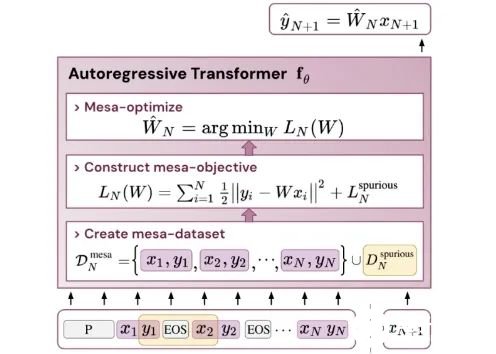
论文链接:https://arxiv.org/abs/2309.05858作者证明,最小化通用自回归损失会产生在 Transformer 的前向传递中运行的基于辅助梯度的优化算法。这种现象最近被称为「mesa 优化(mesa-optimization)」。此外,研究人员发现所得的 mesa 优化算法表现出上下文中的小样本学习能力,与模型规模无关。因此,新的结果对此前大语言模型中出现的小样本学习的原理进行了补充。研究人员认为:Transformers 的成功基于其在前向传递中实现 mesa 优化算法的架构偏差:(i) 定义内部学习目标,以及 (ii) 对其进行优化。
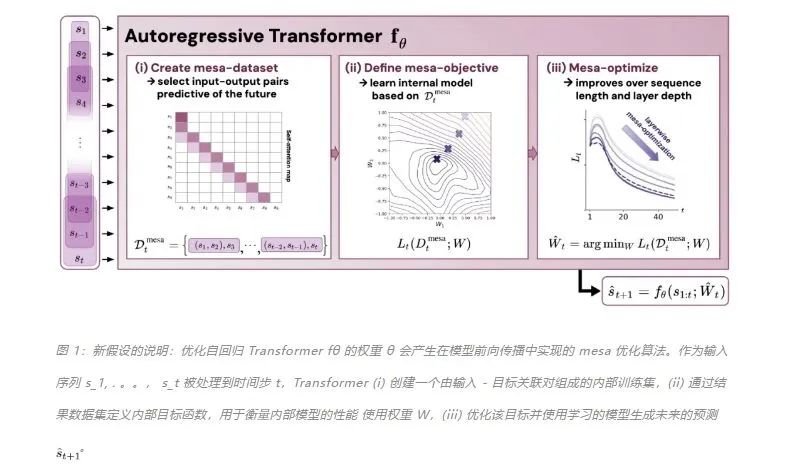
- 概括了 von Oswald 等人的理论,并展示了从理论上,Transformers 是如何通过使用基于梯度的方法优化内部构建的目标来自回归预测序列下一个元素的。
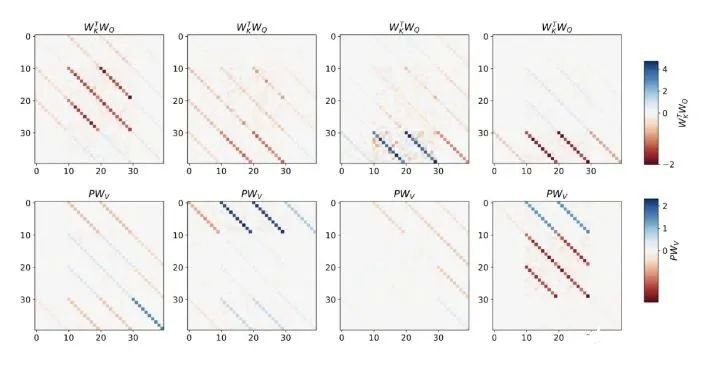
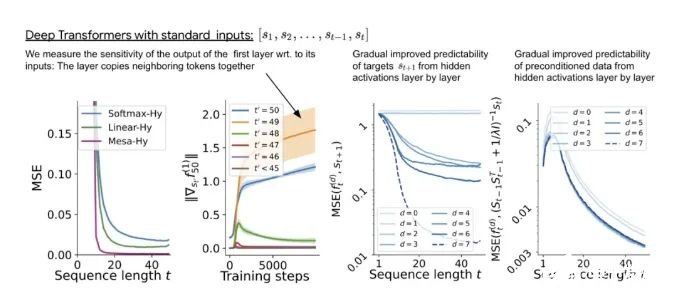
- 通过实验对在简单序列建模任务上训练的 Transformer 进行了逆向工程,并发现强有力的证据表明它们的前向传递实现了两步算法:(i) 早期自注意力层通过分组和复制标记构建内部训练数据集,因此隐式地构建内部训练数据集。定义内部目标函数,(ii) 更深层次优化这些目标以生成预测。
- 与 LLM 类似,实验表明简单的自回归训练模型也可以成为上下文学习者,而即时调整对于改善 LLM 的上下文学习至关重要,也可以提高特定环境中的表现。
- 受发现注意力层试图隐式优化内部目标函数的启发,作者引入了 mesa 层,这是一种新型注意力层,可以有效地解决最小二乘优化问题,而不是仅采取单个梯度步骤来实现最优。实验证明单个 mesa 层在简单的顺序任务上优于深度线性和 softmax 自注意力 Transformer,同时提供更多的可解释性。

- 在初步的语言建模实验后发现,用 mesa 层替换标准的自注意力层获得了有希望的结果,证明了该层具有强大的上下文学习能力。
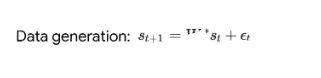
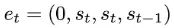
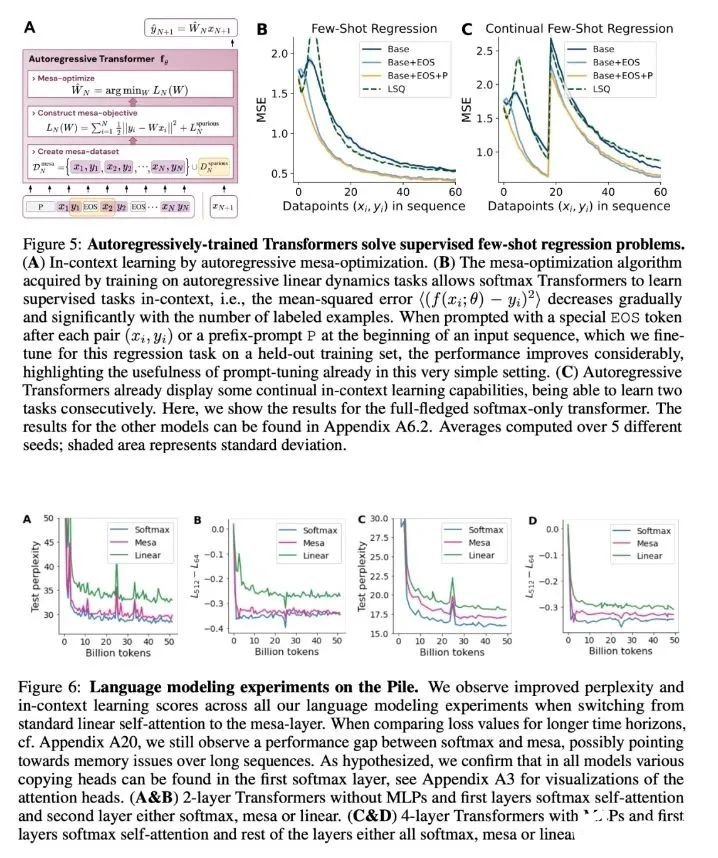
5. 1.5T内存挑战英伟达!8枚芯片撑起3个GPT-4,华人AI芯片独角兽估值365亿
原文:https://mp.weixin.qq.com/s/GjG_OpzlAO7vGwOW7fmE-w高端GPU持续缺货之下,一家要挑战英伟达的芯片初创公司成为行业热议焦点。8枚芯片跑大模型,就能支持5万亿参数(GPT-4的三倍) 。这是独角兽企业SambaNova刚刚发布的新型AI芯片SN40L——型号中40代表是他们第四代产品,L代表专为大模型(LLM)优化:高达1.5T的内存,支持25.6万个token的序列长度。
CEO Rodrigo Liang表示,当前行业标准做法下运行万亿参数大模型需要数百枚芯片,我们的方法使总拥有成本只有标准方法的1/25。SambaNova目前估值50亿美元(约365亿人民币),累计完成了6轮总计11亿美元的融资,投资方包括英特尔、软银、三星、GV等。他们不仅在芯片上要挑战英伟达,业务模式上也说要比英伟达走的更远:直接参与帮助企业训练私有大模型。目标客户上野心更是很大:瞄准世界上最大的2000家企业。
 1.5TB内存的AI芯片最新产品SN40L,由台积电5纳米工艺制造,包含1020亿晶体管,峰值速度638TeraFLOPS。与英伟达等其他AI芯片更大的不同在于新的三层Dataflow内存系统。与主要竞品相比,英伟达H100最高拥有80GB HBM3内存,AMD MI300拥有192GB HBM3内存。SN40L的高带宽HBM3内存实际比前两者小,更多依靠大容量DRAM。Rodrigo Liang表示,虽然DRAM速度更慢,但专用的软件编译器可以智能地分配三个内存层之间的负载,还允许编译器将8个芯片视为单个系统。
1.5TB内存的AI芯片最新产品SN40L,由台积电5纳米工艺制造,包含1020亿晶体管,峰值速度638TeraFLOPS。与英伟达等其他AI芯片更大的不同在于新的三层Dataflow内存系统。与主要竞品相比,英伟达H100最高拥有80GB HBM3内存,AMD MI300拥有192GB HBM3内存。SN40L的高带宽HBM3内存实际比前两者小,更多依靠大容量DRAM。Rodrigo Liang表示,虽然DRAM速度更慢,但专用的软件编译器可以智能地分配三个内存层之间的负载,还允许编译器将8个芯片视为单个系统。
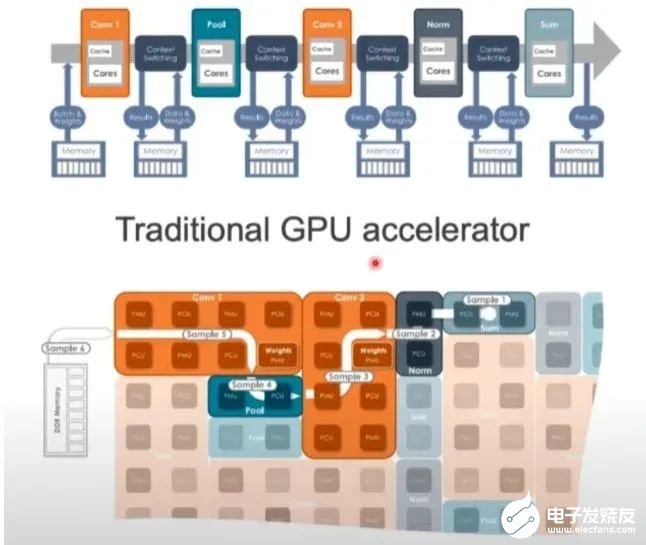
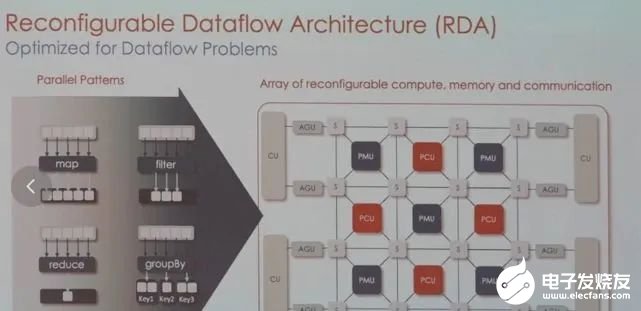
GPU的架构非常严格,面对图像、视频、文本等多样数据时可能不够灵活,而SambaNova可以调整硬件来满足工作负载的要求。目前,SambaNova的芯片和系统已获得不少大型客户,包括世界排名前列的超算实验室,日本富岳、美国阿贡国家实验室、劳伦斯国家实验室,以及咨询公司埃森哲等。业务模式也比较特别,芯片不单卖,而是出售其定制技术堆栈,从芯片到服务器系统,甚至包括部署大模型。为此,他们与TogetherML联合开发了BloomChat,一个1760亿参数的多语言聊天大模型。BloomChat建立在BigScience组织的开源大模型Bloom之上,并在来自OpenChatKit、Dolly 2.0和OASST1的OIG上进行了微调。训练过程中,它使用了SambaNova独特的可重配置数据流架构,然后在SambaNova DataScale系统进行训练。
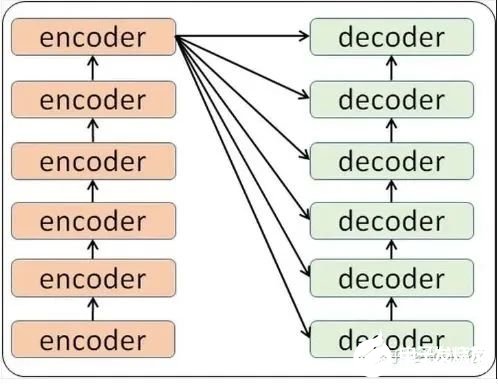
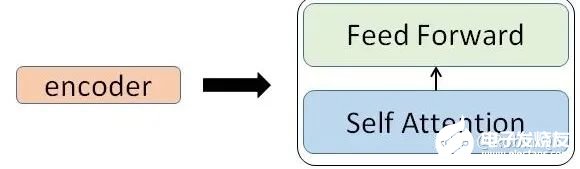
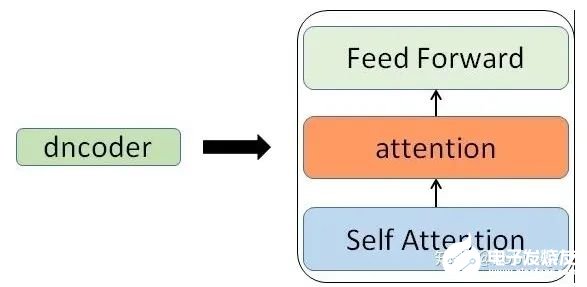
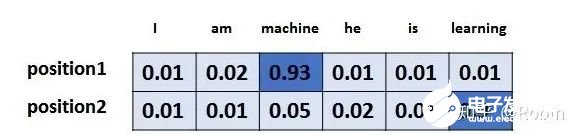
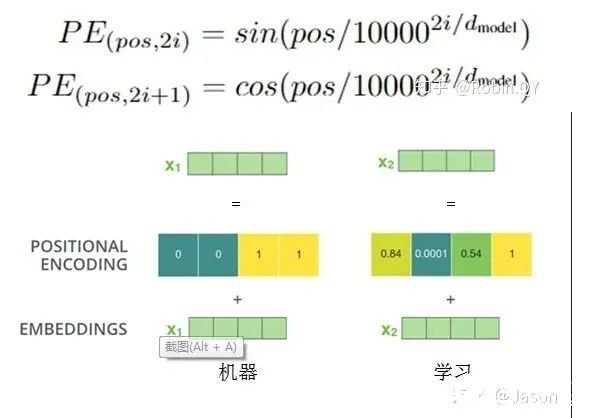
6. 十分钟,深入浅出理解Transformer
原文:https://mp.weixin.qq.com/s/xtyP6cg6vROOXe1vlPEEewTransformer是一个利用注意力机制来提高模型训练速度的模型。关于注意力机制可以参看这篇文章(https://zhuanlan.zhihu.com/p/52119092),trasnformer可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。那什么是transformer呢?你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。

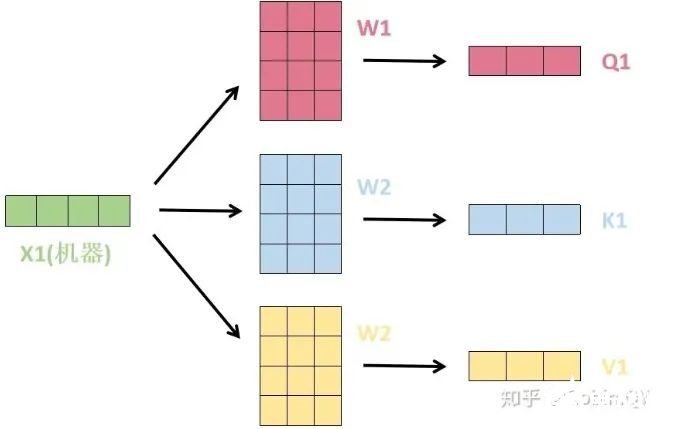
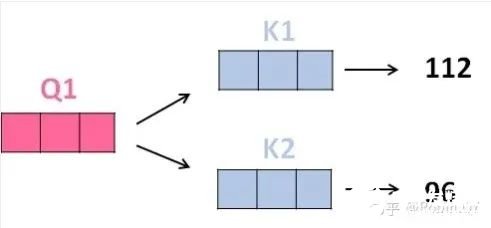
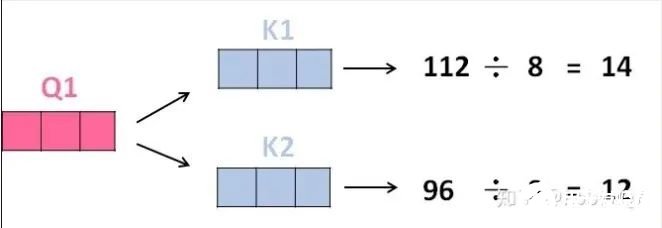
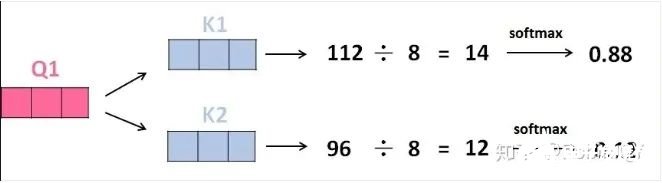
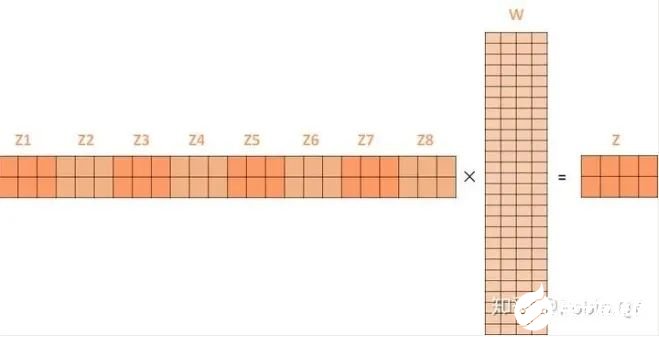
3、将得分分别除以一个特定数值8(K向量的维度的平方根,通常K向量的维度是64)这能让梯度更加稳定,则得到结果如下:

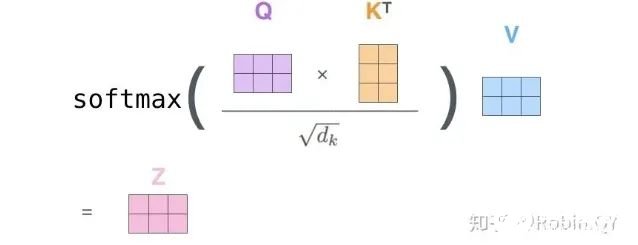
 将上述的过程总结为一个公式就可以用下图表示:
将上述的过程总结为一个公式就可以用下图表示:

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
RT-Thread
+关注
关注
31文章
1293浏览量
40224
原文标题:【AI简报20230922期】华人AI芯片挑战英伟达,深入浅出理解Transformer
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英伟达收购AI初创公司Run:ai
全球领先的芯片制造商英伟达近日正式完成了对以色列人工智能初创公司Run:ai的收购。这一收购案在经过欧盟反垄断机构的严格审查后,最终获得了批准,标志着
OpenAI领投Rain AI,挑战英伟达AI芯片市场地位
巨头英伟达展开有力竞争。 为了加强其领导团队,Rain AI于2024年6月成功聘请前苹果公司芯片执行官Jean-Didier Allegrucci担任硬件工程负责人。这一举措无疑为R
英伟达投资日本AI公司Sakana AI
英伟达现身日本人工智能研发初创公司Sakana AI的A轮融资名单中;据悉;Sakana AI的A轮融资而完成超过1亿美元,此次融资由New Enterprise Associates
深入浅出系列之代码可读性
原创声明:该文章是个人在项目中亲历后的经验总结和分享,如有搬运需求请注明出处。 这是“深入浅出系列”文章的第一篇,主要记录和分享程序设计的一些思想和方法论,如果读者觉得所有受用,还请“一键三连
只能跑Transformer的AI芯片,却号称全球最快?
电子发烧友网报道(文/周凯扬)近日,一家由哈佛辍学生成立的初创公司Etched,宣布了他们在打造的一款“专用”AI芯片Sohu。据其声称该芯片的速度将是英伟
英伟达Blackwell芯片已投产,预告未来AI芯片发展
英伟达创始人兼CEO黄仁勋近日宣布,公司旗下的Blackwell芯片已正式投入生产。这款芯片是英伟达
英伟达:NVIDIA目标不是AI芯片,而是AI工厂
佐思汽研发布《2024年英伟达AI与汽车业务分析报告暨 汽车新四化每周观察2024年5月第1期》报告
英伟达首席执行官黄仁勋:AI模型推动英伟达AI芯片需求
近来,以ChatGPT为代表的AI聊天机器人已经导致英伟达AI芯片供应紧张。然而,随着能够创造视频并进行近似人类交流的新型
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
2024年3月19日,[英伟达]CEO[黄仁勋]在GTC大会上公布了新一代AI芯片架构BLACKWELL,并推出基于该架构的超级芯片GB20
发表于 05-13 17:16
新思科技携手英伟达:基于加速计算、生成式AI和Omniverse释放下一代EDA潜能
将双方数十年的合作深入扩展到新思科技EDA全套技术栈 摘要: 新思科技携手英伟达,将其领先的AI驱动型电子设计自动化(EDA)全套技术栈部署于英伟
发表于 03-20 13:43
•287次阅读

“网红”芯片Groq让英伟达蒸发5600亿
鉴于ChatGPT的广泛应用,引发了AI算力需求的迅猛增长,使得英伟达的AI芯片供不应求,出现大规模短缺。如今,
英伟达:预计下一代AI芯片B100短缺,计划扩产并采用新架构
近期热门的 H100 芯片运期短缩数天后,英伟达新型 AI 旗舰芯片 B100搭载全新的 Bla

英伟达涉足定制芯片,聚焦云计算与AI市场
作为全球高端AI芯片市场80%份额的霸主,英伟达自2023以来股价上涨超过两倍,2024年市值高达1.73万亿美元。知名公司如微软、OpenAI、Meta纷纷采购





 工商网监
工商网监
评论