 OpenVINO场景文字检测与文字识别教程
OpenVINO场景文字检测与文字识别教程

作者:贾志刚英特尔边缘计算创新大使
01OpenVINO场景文字检测
OpenVINO是英特尔推出的深度学习模型部署框架,当前最新版本是OpenVINO2023版本。OpenVINO2023自带各种常见视觉任务支持的预训练模型库Model Zoo,其中支持场景文字检测的网络模型是来自Model Zoo中名称为:text-detection-0003的模型(基于PixelLink架构的场景文字检测网络)。
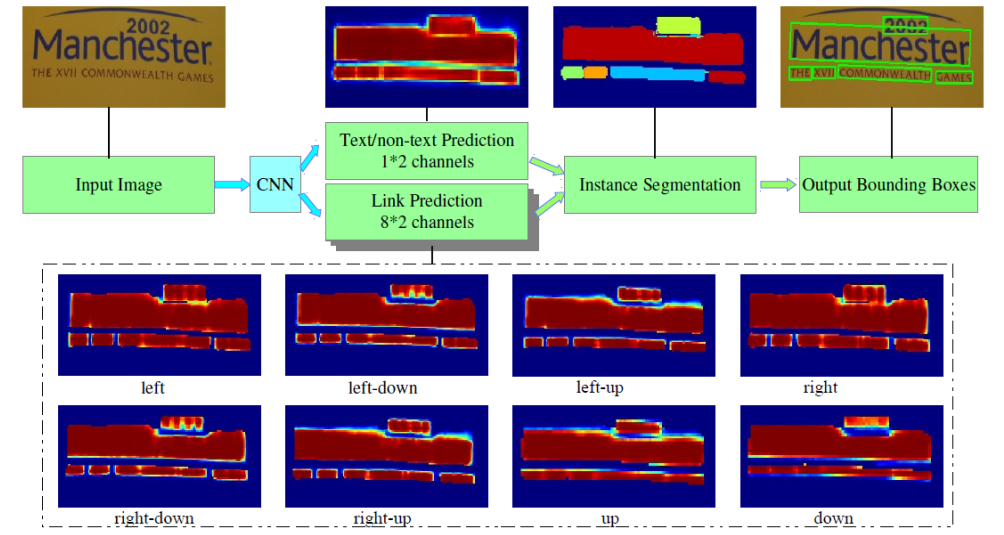
图-1 PixelLink网络模型架构
图-1中的PixelLink场景文字检测模型的输入与输出格式说明
输入格式:
1x3x768x1280 BGR彩色图像
输出格式:
name: "model/link_logits_/add", [1x16x192x320] – pixelLink的输出 name: "model/segm_logits/add", [1x2x192x320] – 像素分类text/no text
左滑查看更多
02OpenVINO文字识别
OpenVINO支持文字识别(数字与英文)的模型是来自Model Zoo中名称为:text-recognition-0012d的模型,是典型的CRNN结构模型。(基于类似VGG卷积结构backbone与双向LSTM编解码头的文字识别网络)
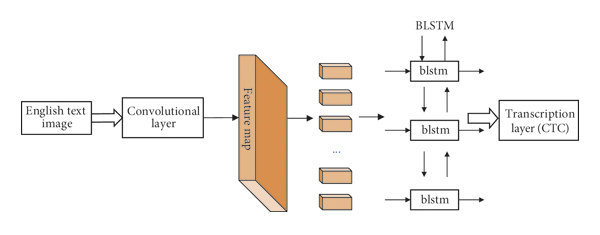
图-2 CRNN网络模型架构
图-2文本识别模型的输入与输出格式如下:
输入格式:1x1x32x120
输出格式:30, 1, 37
输出解释是基于CTC贪心解析方式,其中37字符集长度,字符集为:0123456789abcdefghijklmnopqrstuvwxyz#
#表示空白。
03MediaPipe手势识别
谷歌在2020年发布的mediapipe开发包说起,这个开发包集成了包含手势姿态等各种landmark检测与跟踪算法。其中支持手势识别是通过两个模型实现,一个是模型是检测手掌,另外一个模型是实现手掌的landmakr标记。

图-3手势landmark点位说明
04OpenVINO与MediaPipe库的安装
pip install openvino==2023.0.2 pip install mediapipe
左滑查看更多
请先安装好OpenCV-Python开发包依赖。
05应用构建说明
首先基于OpenCV打开USB摄像头或者笔记本的web cam,读取视频帧,然后在每一帧中完成手势landmark检测,根据检测到手势landmark数据,分别获取左右手的食指指尖位置坐标(图-3中的第八个点位),这样就得到了手势选择的ROI区域,同时把当前帧的图像送入到OpenVINO场景文字识别模块中,完成场景文字识别,最后对比手势选择的区域与场景文字识别结果每个区域,计算它们的并交比,并交比阈值大于0.5的,就返回该区域对应的OCR识别结果,并显示到界面上。整个流程如下:
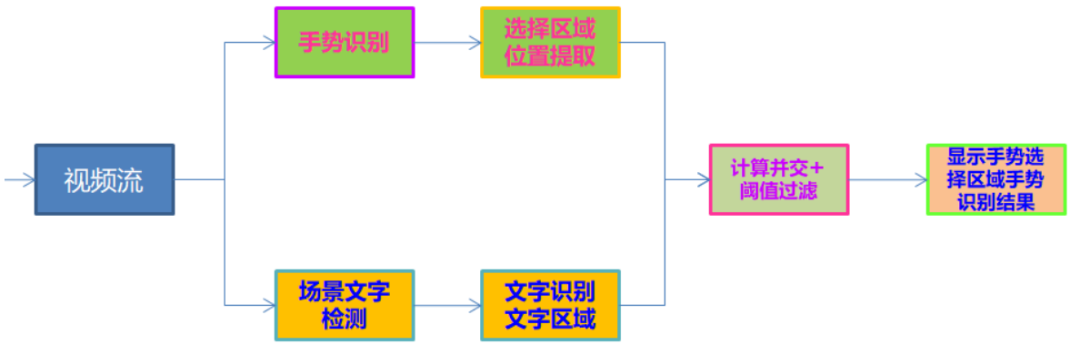
图-4程序执行流程图
06代码实现
根据图-4的程序执行流程图,把场景文字检测与识别部分封装到了一个类TextDetectAndRecognizer,最终实现的主程序代码如下:
import cv2 as cv
import numpy as np
import mediapipe as mp
from text_detector import TextDetectAndRecognizer
digit_nums = ['0','1', '2','3','4','5','6','7','8','9','a','b','c','d','e','f','g',
'h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','#']
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
x0 = 0
y0 = 0
detector = TextDetectAndRecognizer()
# For webcam input:
cap = cv.VideoCapture(0)
cap.set(cv.CAP_PROP_FRAME_HEIGHT, 1080)
cap.set(cv.CAP_PROP_FRAME_WIDTH, 1920)
height = cap.get(cv.CAP_PROP_FRAME_HEIGHT)
width = cap.get(cv.CAP_PROP_FRAME_WIDTH)
# out = cv.VideoWriter("D:/test777.mp4", cv.VideoWriter_fourcc('D', 'I', 'V', 'X'), 15, (np.int(width), np.int(height)), True)
with mp_hands.Hands(
min_detection_confidence=0.75,
min_tracking_confidence=0.5) as hands:
while cap.isOpened():
success, image = cap.read()
if not success:
break
image.flags.writeable = False
h, w, c = image.shape
image = cv.cvtColor(image, cv.COLOR_BGR2RGB)
results = hands.process(image)
image = cv.cvtColor(image, cv.COLOR_RGB2BGR)
x1 = -1
y1 = -1
x2 = -1
y2 = -1
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS)
for idx, landmark in enumerate(hand_landmarks.landmark):
x0 = np.int(landmark.x * w)
y0 = np.int(landmark.y * h)
cv.circle(image, (x0, y0), 4, (0, 0, 255), 4, cv.LINE_AA)
if idx == 8 and x1 == -1 and y1 == -1:
x1 = x0
y1 = y0
cv.circle(image, (x1, y1), 4, (0, 255, 0), 4, cv.LINE_AA)
if idx == 8 and x1 > 0 and y1 > 0:
x2 = x0
y2 = y0
cv.circle(image, (x2, y2), 4, (0, 255, 0), 4, cv.LINE_AA)
if abs(x1-x2) > 10 and abs(y1-y2) > 10 and x1 > 0 and x2 > 0:
if x1 < x2:
cv.rectangle(image, (x1, y1), (x2, y2), (255, 0, 0), 2, 8)
text = detector.inference_image(image, (x1, y1, x2, y2))
cv.putText(image, text, (x1, y1), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 2)
else:
cv.rectangle(image, (x2, y2), (x1, y1), (255, 0, 0), 2, 8)
text = detector.inference_image(image, (x2, y2, x1, y1))
cv.putText(image, text, (x2, y2), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 2)
# Flip the image horizontally for a selfie-view display.
cv.imshow('MediaPipe Hands', image)
# out.write(image)
if cv.waitKey(1) & 0xFF == 27:
break
cap.release()
# out.release()
左滑查看更多
07移植到AlxBoard开发板上
在爱克斯开发板上安装好MediaPipe即可,OpenVINO不用安装了,因为爱克斯开发板自带OpenCV与OpenVINO,然后就可以直接把python代码文件copy过去,插上USB摄像头,直接使用命令行工具运行对应的python文件,就可以直接用了,这样就在AlxBoard开发板上实现了基于手势选择区域的场景文字识别应用。
08后续指南
安装语音播报支持包:
pip install pyttsx
AlxBorad开发板是支持3.5mm耳机mic接口,支持语音播报的,如果把区域选择识别的文字,通过pyttsx直接播报就可以实现从手势识别到语音播报了,自动跟读卡片单词启蒙学英语,后续实现一波,请继续关注我们。
审核编辑:汤梓红
-
英特尔
+关注
关注
61文章
10329浏览量
181167 -
开发套件
+关注
关注
2文章
230浏览量
25274 -
深度学习
+关注
关注
73文章
5611浏览量
124666 -
OpenVINO
+关注
关注
0文章
118浏览量
822
原文标题:在英特尔开发套件上打造指哪识哪的OCR应用|开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
瑞芯微(EASY EAI)RV1126B OCR文字识别

基于SnapDragonBoard410C文字识别
基于AI通用文字识别能力,检测和识别文档翻拍、街景翻拍等图片中的文字
TH-OCR文字识别系统介绍
基于matlab的文字识别算法
基于FPGA的OCR文字识别技术的深度解析
如何提取和检测视频中的文字?数字视频中文字的检测提取技术的分析
如何在电脑中对图片文字进行局部识别
浅析HarmonyOS基于AI的通用文字识别技术
图片文字识别:揭开数字世界的神秘面纱
基于OpenVINO+OpenCV的OCR处理流程化实现




评论