 生成式AI的功能简述
生成式AI的功能简述
翻译:武卓 英特尔AI软件布道师;杨亦诚 英特尔 AI软件工程师
在过去的一年里,我们看到了生成式AI用例和模型的爆炸式增长。现在几乎每周都会针对不同的领域发布新的值得注意的生成式模型,这些模型在不断增加的数据集上训练,具有各种计算复杂性。使用像LoRA这样的方法,可以在非常适度的训练加速器上微调大模型,这解锁了对基础模型的更多修改。由于资源消耗,部署这些模型仍然是挑战,并且高度依赖于在云端部署模型。
随着 OpenVINO 2023.1 版本的发布,我们希望将生成式 AI 的强大功能引入常规台式机和笔记本电脑,让这些模型可以运行在在资源受限的本地环境中,并被您尝试集成到自己的应用程序中。我们在整个产品中针对这些场景进行了优化,实现了一些关键功能,并为我们的下一步工作计划奠定了基础。
也就是说,我们的变化不仅限于生成式AI,我们还改进了产品的其它部分,并希望它能使您的工作更轻松,并为您带来额外的价值。让我们来看看这些变化到底是什么。
生成式AI功能
大模型的整体堆栈优化。来自生成式AI家族的模型有一个共同点——它们亟需资源。模型尺寸巨大,运行它们所需的内存量非常高,对内存带宽的需求也非常大。例如不必要的权重搬运这样简单的问题,都可能会导致由于内存不足而无法运行模型。
为了更好地适应这一点,我们已经跨推理堆栈工作,包括 CPU 和 GPU(集成显卡和独立显卡),目标就是优化我们使用这些模型的方式,包括优化读取和编译模型所需的内存,优化如何处理模型的输入和输出张量以及其他内部结构,从而缩短模型执行时间。
大型语言模型的权重量化。LLM 在执行时需要大量的内存带宽。为了对此进行优化,我们在 NNCF(神经网络压缩框架)优化框架和 CPU 推理中实现了 int8 LLM 权重量化功能。
使用此功能时,NNCF 将生成优化的 IR 模型文件,与精度为 fp16 的常规模型文件相比,该文件能够将尺寸减小一半。IR 文件将在 CPU 插件中被执行额外的优化,这将改善延迟并减少运行时内存消耗。GPU 的类似功能正在实施中,并将在后续发布的版本中提供。
更容易转换模型。大多数LLM目前来自基于PyTorch的环境。要转换这些模型,您现在可以使用我们的直接 PyTorch 转换功能。对于LLM,与我们之前通过ONNX格式的路径相比,这大大加快了转换时间并减少了内存需求。
总体而言,由于我们的优化,我们能够在CPU和GPU上均能提高 LLM 性能。[WZ1]此外,我们还按 倍数级减少了运行这些模型所需的内存量。在某些情况下,新版本OpenVINO可以让我们运行那些以前由于内存不足而失败的模型。我们一直在数十个不同规模和不同任务的LLM上验证我们的工作,以确保我们的方法能够很好地扩展到我们所有的平台和支持的操作系统。
我们的转换API和权重量化功能也集成到Hugging Face optimum-intel扩展中,允许您使用OpenVINO作为推理堆栈运行生成式模型,或以方便的方式将模型导出为OpenVINO格式。
简化您的工作流
不再需要开发包,提供统一的工具。从 2023.1 版本开始,我们不再要求您为运行时和开发环境分别安装单独的软件包。我们一直致力于简化我们的工具,并将所有必要的组件集成到单个 OpenVINO软件包中。这也意味着模型转换和推理可以通过所有OpenVINO分发机制以统一的方式获得:pip,conda,brew和archive。
此外,从此版本开始,OpenVINO Python API 可从所有支持最低要求 Python 版本 (3.7) 的软件包中获得。这意味着除了以前可用的 pip 之外,还有conda、brew和指定的 apt 版本。
更高效、更友好的模型转换。我们正在推出OpenVINO模型转换工具 (OVC),该工具正在取代我们众所周知的离线模型转换任务中的模型优化器 (MO) 工具。该工具以OpenVINO包形式提供,依靠内部模型前端来读取框架格式,不需要原始框架来执行模型转换。例如,如果您想将TF模型转换为OpenVINO,则不需要安装TensorFlow。同样,如果您想简单地在 OpenVINO运行时中读取此模型以进行推理而无需转换,同样也不需要 TensorFlow。
为了在 Python 脚本中转换模型,我们进一步改进了convert_model API。例如,它允许将模型从 PyTorch 对象转换为 OpenVINO模型,并编译模型以进行推理或将其保存到 IR格式,请参见以下示例:
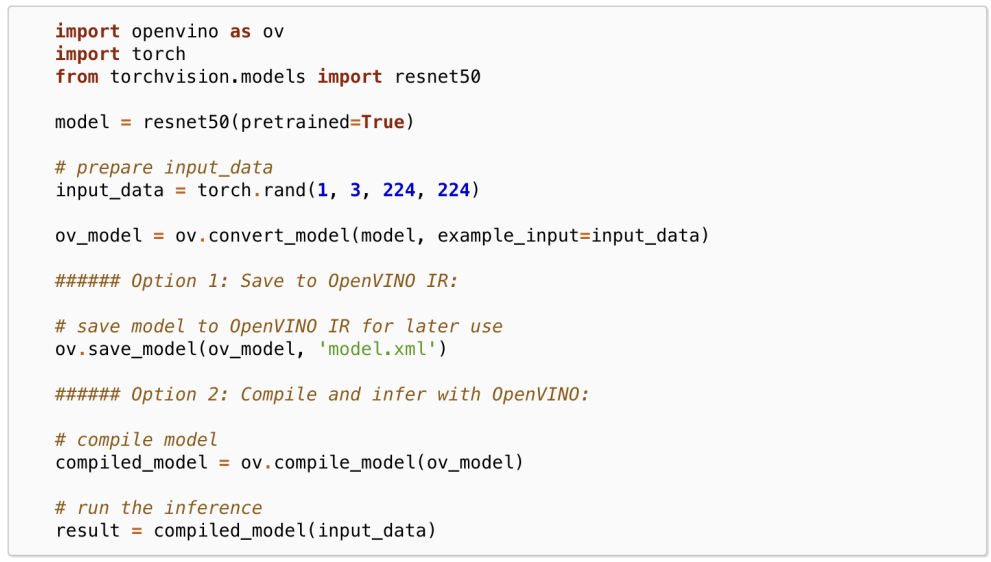
请注意,我们还简化了我们的Python API,可以直接从OpenVINO命名空间获得这些API,因此这一切变得更简单了。您仍然可以从旧命名空间访问函数,如果您需要 mo 工具,可以安装 OpenVINO-dev。这个工具本身也仍然可用,但我们建议迁移到 ovc 工具。
默认切换到 fp16 IR。随着转换工具的变化,我们现在切换到使用 fp16 精度作为 IR 中的数据类型。这允许将模型大小减小 一半(相对FP32精度的模型),并且根据我们执行的测试对准确性没有影响。值得一提的是,IR 精度不会影响硬件插件的执行精度,默认情况下,插件始终以最佳性能继续执行。
更好的PyTorch兼容性
前面已经提到,直接转换PyTorch模型的功能现在已经成熟,该方案已经被集成在我们的 HuggingFace optimum-intel中进行模型转换。因此,现在转换模型更容易,因为您绕过了 ONNX 格式的额外步骤(我们仍然无限制地支持)。
为了使OpenVINO更接近PyTorch生态系统,我们引入了对torch.compile和相应后端的支持。您现在可以通过 OpenVINO堆栈运行您的模型,方法是通过torch.compile编译它并指定 OpenVINO 作为后端!
如下例所示:

此功能正在积极增强,我们期待更好的性能和操作覆盖范围,但它已经在我们的集成中使用,例如Stable Diffusion WebUI。
令人兴奋的新Notebook用例
为了展示您可以直接从笔记本电脑上试用的新功能,我们制作了一些Jupyter notebooks示例并更新了现有notebooks。以下是最令我们兴奋的:
基于大语言模型的聊天机器人(LLM Chatbot):
文生图模型StableDiffusion XL:
文生图模型 Tiny SD:
生成音乐模型 MusicGen:
生成视频模型Text-to-video:
审核编辑:汤梓红
-
英特尔
+关注
关注
61文章
10025浏览量
172499 -
AI
+关注
关注
87文章
31845浏览量
270677 -
pytorch
+关注
关注
2文章
808浏览量
13395 -
OpenVINO
+关注
关注
0文章
99浏览量
253
原文标题:介绍OpenVINO™ 2023.1:在边缘端赋能生成式AI|开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

什么是生成式AI?生成式AI的四大优势
虹软图像深度恢复技术与生成式AI的创新 生成式AI助力
利用 NVIDIA Jetson 实现生成式 AI






 工商网监
工商网监
评论