 Linux中提高指令缓存命中率
Linux中提高指令缓存命中率
提高指令缓存命中率
前面说的是数据缓存,现在看看指令缓存命中率该如何提高。
有一个数组array,数组元素内容为0-255之间的随机数:
int array[N];
for (i = 0; i < TESTN; i++)
array[i] = rand() % 256;
现在,要把数组中数字小于128的元素置为0,并且对数组排序。
大家应该都能想到,有两种方法:
- 先遍历数组,把小于128的元素置为0,然 后排序 。
- 先对数组排序 , 再遍历数组 ,把小于128的元素置为0。
for(i = 0; i < N; i++) {
if (array [i] < 128)
array[i] = 0;
}
sort(array, array +N);
先排序后遍历的速度会比较快,为什么?
因为在for循环中会执行很多次if分支判断语句,而CPU拥有分支预测器。
如果分支预测器可以预测接下来要执行的分支(执行if还是执行else),那么就可以提前把这些指令放到缓存中,CPU执行的时候就会很快了。
如果一个数组的内容完全随机的话,那么分支预测器就很难进行正确的预测。但如果数组内容是有序的,它就会根据历史命中数据的情况对未来进行预测,那命中率就会很高,所以先排序后遍历的速度会比较快。
怎么验证指令缓存命中率的情况呢?
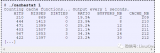
在Linux下,可以使用Perf性能分析工具进行验证。通过-e选项,指定branch-loads和branch-loads-misses事件,可以分别统计出分支预测成功的次数和 分支预测失败的次数 ,通过L1-icache-load-misses事件也能统计一级缓存中指令未命中的次数。但是,这些性能事件都属于硬件事件,perf工具能否统计这些事件取决于CPU是否支持以及芯片原厂是否去实现了该接口,我看很多都是不支持或者没实现的。
另外,在Linux内核中,可以看到大量的likely和unlikely宏,并且它们都出现if语句中,这 两个宏的作用就是为了提高性能 。
这是显示预测概率的宏,如果你觉得CPU的分支预测不准,但if中条件为"真"的概率很高,那么你就可以使用likely()括起来,以此提升性能。
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
if (likely(a == 1)) …
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Linux
+关注
关注
87文章
11391浏览量
211745 -
指令
+关注
关注
1文章
614浏览量
36012 -
缓存
+关注
关注
1文章
244浏览量
26883 -
数组
+关注
关注
1文章
419浏览量
26185
发布评论请先 登录
相关推荐
CPU一级缓存与二级缓存深度分析
CPU缓存:通过优化的的读取机制,可以使CPU读取缓存的命中率非常高,也就是说CPU下一次要读取的数据90%都在缓存中,只有大约10%需要从内存读取。
AM335x SDK关于cache的命中率,请问有能改善cache命中率的有效方法吗?请问怎么才能控制RAM映射到cache?
()④CP15DCacheEnable()⑤CP15DCacheCleanFlush()①~④确定能使cache无效/有效吗?⑤是否有清除cache的功能?■二:关于cache的命中率 请问有能改善cache命中率的有效方法
发表于 06-21 04:06
缓存命中率低的原因是什么?
汇编中加载数据用的是LDW,5个cycle之后就会到达寄存器,并没有体现出缓存命中率的问题。LDW是固定5个cycle,请问缓存命中率低,带来的延迟体现在什么地方?难道是LDW之前,有
发表于 05-25 08:46
基于节点中心性度量的缓存机制
为了降低内容中心网络的缓存内容冗余度和提高缓存内容命中率,提出一种基于节点中心性度量的缓存机制(CMC)。CMC利用控制器获取整个网络的拓扑
发表于 01-17 11:00
•0次下载
基于概率存储的启发式住处中心网络内容缓存方法
概率时综合考虑内容热度和缓存放置收益,即内容热度越高,放置收益越大的内容被缓存的概率越高。实验结果表明,PCP在缓存服务率、缓存
发表于 02-11 11:16
•0次下载
Web代理服务器缓存优化
Web代理服务器缓存能在一定程度上减少网络拥塞现象和用户的访问延迟,减轻服务器负载。然而Web代理缓存的缓存命中率和字节命中率较低,并不能很
发表于 03-06 10:00
•0次下载
基于节点热度与缓存替换率的ICN协作缓存
内容,考虑网络流量在不同区域和不同时间段内的差异性,周期性地计算节点热度和缓存替换率,并将其作为内容是否被缓存在节点上的度量指标。实验结果表明,相对于LCE和CLFM策略,该策略能有效降低平均请求跳数和源端
发表于 03-29 15:17
•1次下载
一种基于内容优先级的缓存替换策略PFC
,将其作为缓存替换的参考因子进行缓存替换决策,以提高重要内容的命中率和可用性。在 ndnsim仿真平台上的测试结果表明,相比LRU和FIFO策略,PF℃策略在不影响全局
发表于 03-24 14:48
•9次下载

把进程绑定到某个 CPU 上运行是怎么实现?
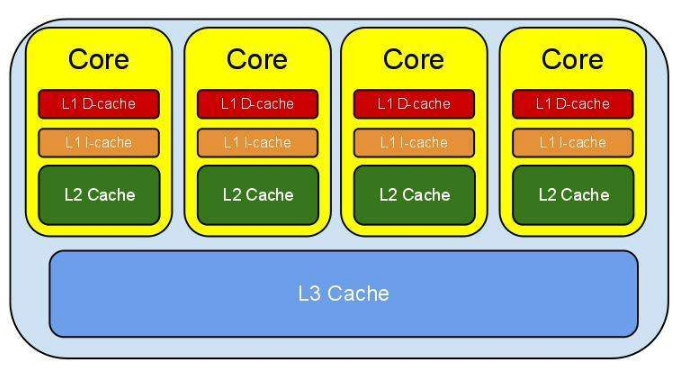
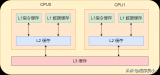
、L2缓存,而L3缓存是共用的。如果一个进程在核心间来回切换,各个核心的缓存命中率就会受到影响。相反如果进程不管如何调度,都始终可以在一个核心上执行,那么其数据的L1、L2





 工商网监
工商网监
评论