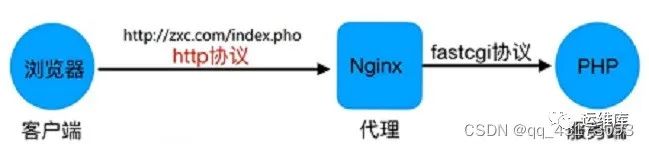
 Nginx架构和工作原理
Nginx架构和工作原理
什么是惊群效应?
第一次听到的这个名词的时候觉得很是有趣,不知道是个什么意思,总觉得又是奇怪的中文翻译导致的。
复杂的说(来源于网络)TLDR;
惊群效应(thundering herd)是指多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群效应。
简单的讲(我的大白话)
有一道雷打下来,把很多人都吵醒了,但只有其中一个人去收衣服了。也就是:有一个请求过来了,把很多进程都唤醒了,但只有其中一个能最终处理。
原因&问题
说起来其实也简单,多数时候为了提高应用的请求处理能力,会使用多进程(多线程)去监听请求,当请求来时,因为都有能力处理,所以就都被唤醒了。
而问题就是,最终还是只能有一个进程能来处理。当请求多了,不停地唤醒、休眠、唤醒、休眠,做了很多的无用功,上下文切换又累,对吧。那怎么解决这个问题呢?下面就是今天要看的重点,我们看看 nginx 是如何解决这个问题的。
Nginx 架构
第一点我们需要了解 nginx 大致的架构是怎么样的。nginx 将进程分为 master 和 worker 两类,非常常见的一种 M-S 策略,也就是 master 负责统筹管理 worker,当然它也负责如:启动、读取配置文件,监听处理各种信号等工作。
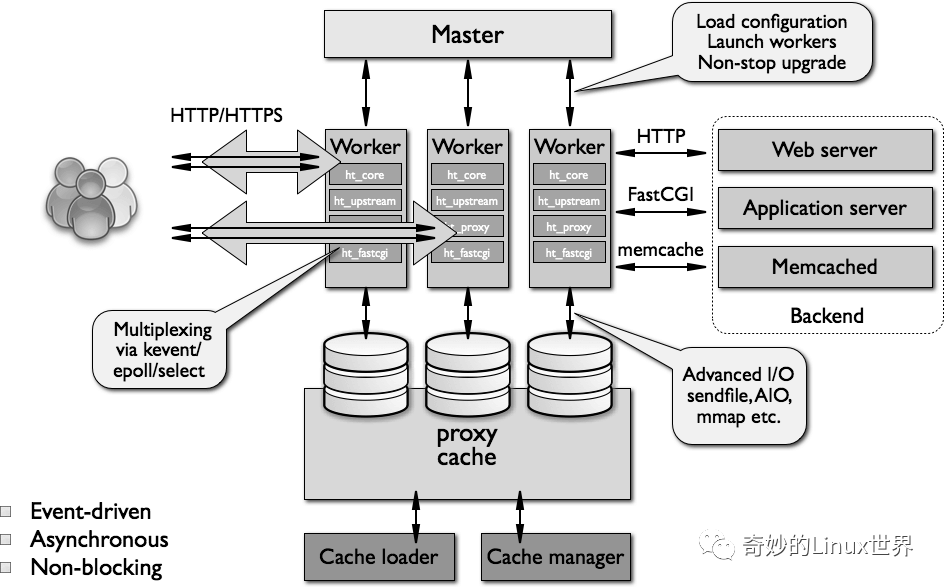
图片来自:https://aosabook.org/en/v2/nginx.html
但是,第一个要注意的问题就出现了,master 的工作有且只有这些,对于请求来说它是不管的,就如同图中所示,请求是直接被 worker 处理的。如此一来,请求应该被哪个 worker 处理呢?worker 内部又是如何处理请求的呢?
Nginx 使用 epoll
接下来我们就要知道 nginx 是如何使用 epoll 来处理请求的。下面可能会涉及到一些源码的内容,但不用担心,你不需要全部理解,只需要知道它们的作用就可以了。顺便我会简单描述一下我是如何去找到这些源码的位置的。
Master 的工作
其实 Master 并不是毫无作为,至少端口是它来占的。
ngx_open_listening_sockets(ngx_cycle_t*cycle)
{
.....
for(i=0;i< cycle->listening.nelts;i++){
.....
if(bind(s,ls[i].sockaddr,ls[i].socklen)==-1){
if(listen(s,ls[i].backlog)==-1){
}
那么,根据我们 nginx.conf 的配置文件,看需要监听哪个端口,于是就去 bind 的了,这里没问题。
【发现源码】这里我是直接在代码里面搜 bind 方法去找的,因为我知道,不管你怎么样,你总是要绑定端口的
然后是创建 worker 的,虽不起眼,但很关键。https://github.com/nginx/nginx/blob/b489ba83e9be446923facfe1a2fe392be3095d1f/src/os/unix/ngx_process.c#L186
ngx_spawn_process(ngx_cycle_t*cycle,ngx_spawn_proc_ptproc,void*data,
char*name,ngx_int_trespawn)
{
....
pid=fork();
【发现源码】这里我直接搜 fork,整个项目里面需要 fork 的情况只有两个地方,很快就找到了 worker
由于是 fork 创建的,也就是复制了一份 task_struct 结构。所以 master 的几乎全部它都有。
Worker 的工作
Nginx 有一个分模块的思想,它将不同功能分成了不同的模块,而 epoll 自然就是在 ngx_epoll_module.c 中了
ngx_epoll_init(ngx_cycle_t*cycle,ngx_msec_ttimer) { ngx_epoll_conf_t*epcf; epcf=ngx_event_get_conf(cycle->conf_ctx,ngx_epoll_module); if(ep==-1){ ep=epoll_create(cycle->connection_n/2);
其他不重要,就连 epoll_ctl 和 epoll_wait 也不重要了,这里你需要知道的就是,从调用链路来看,是 worker 创建的 epoll 对象,也就是每个 worker 都有自己的 epoll 对象,而监听的sokcet 是一样的!
【发现源码】这里更加直接,搜索 epoll_create 肯定就能找到
问题的关键
此时问题的关键基本就能了解了,每个 worker 都有处理能力,请求来了此时应该唤醒谁呢?讲道理那不是所有 epoll 都会有事件,所有 worker 都 accept 请求?显然这样是不行的。那么 nginx 是如何解决的呢?
如何解决
解决方式一共有三种,下面我们一个个来看:
accept_mutex(应用层的解决方案)
EPOLLEXCLUSIVE(内核层的解决方案)
SO_REUSEPORT(内核层的解决方案)
accept_mutex
看到 mutex 可能你就知道了,锁嘛!这也是对于高并发处理的 ”基操“ 遇事不决加锁,没错,加锁肯定能解决问题。
具体代码就不展示了,其中细节很多,但本质很容易理解,就是当请求来了,谁拿到了这个锁,谁就去处理。没拿到的就不管了。锁的问题很直接,除了慢没啥不好的,但至少很公平。
EPOLLEXCLUSIVE
EPOLLEXCLUSIVE 是 2016 年 4.5+ 内核新添加的一个 epoll 的标识。它降低了多个进程/线程通过 epoll_ctl 添加共享 fd 引发的惊群概率,使得一个事件发生时,只唤醒一个正在 epoll_wait 阻塞等待唤醒的进程(而不是全部唤醒)。
关键是:每次内核只唤醒一个睡眠的进程处理资源
但,这个方案不是完美的解决了,它仅是降低了概率哦。为什么这样说呢?相比于原来全部唤醒,那肯定是好了不少,降低了冲突。但由于本质来说 socket 是共享的,当前进程处理完成的时间不确定,在后面被唤醒的进程可能会发现当前的 socket 已经被之前唤醒的进程处理掉了。
SO_REUSEPORT
Nginx 在 1.9.1 版本加入了这个功能
其本质是利用了 Linux 的 reuseport 的特性,使用 reuseport 内核允许多个进程 listening socket 到同一个端口上,而从内核层面做了负载均衡,每次唤醒其中一个进程。
反应到 Nginx 上就是,每个 Worker 进程都创建独立的 listening socket,监听相同的端口,accept 时只有一个进程会获得连接。效果就和下图所示一样。
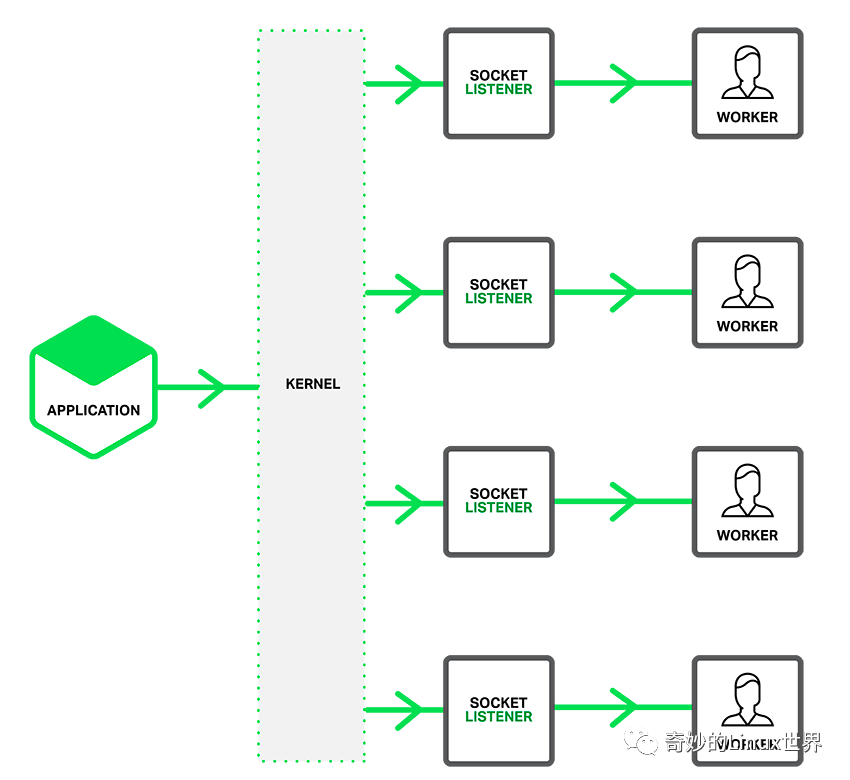
而使用方式则是:
http{
server{
listen80reuseport;
server_namelocalhost;
#...
}
}
从官方的测试情况来看确实是厉害
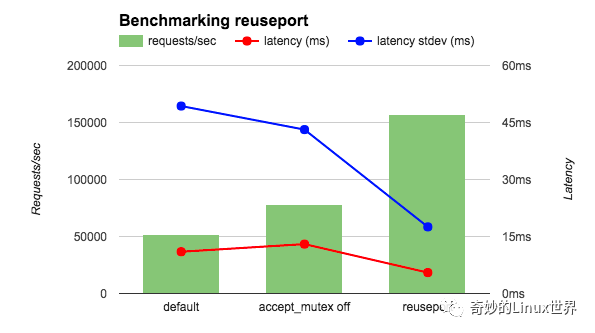
当然,正所谓:完事无绝对,技术无银弹。这个方案的问题在于内核是不知道你忙还是不忙的。只会无脑的丢给你。与之前的抢锁对比,抢锁的进程一定是不忙的,现在手上的工作都已经忙不过来了,没机会去抢锁了;而这个方案可能导致,如果当前进程忙不过来了,还是会只要根据 reuseport 的负载规则轮到你了就会发送给你,所以会导致有的请求被前面慢的请求卡住了。
总结
本文,从了解什么 ”惊群效应“ 到 nginx 架构和 epoll 处理的原理,最终分析三种不同的处理 “惊群效应” 的方案。分析到这里,我想你应该明白其实 nginx 这个多队列服务模型是所存在的一些问题,只不过绝大多数场景已经完完全全够用了。
审核编辑:汤梓红
-
Linux
+关注
关注
87文章
11219浏览量
208872 -
源码
+关注
关注
8文章
633浏览量
29134 -
多线程
+关注
关注
0文章
277浏览量
19919 -
nginx
+关注
关注
0文章
142浏览量
12161 -
epoll
+关注
关注
0文章
28浏览量
2947
原文标题:Nginx 是如何解决惊群效应的?
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Linux上Nginx获得最佳性能的8种方法
nginx重启命令linux步骤是什么?
nginx重启命令linux步骤是什么?
nginx错误页面配置
主要学习下nginx的安装配置
Gnutella文件共享体系架构的工作原理
一文读懂Nginx、Apache工作原理
Nginx架构介绍 Nginx服务器模型分析

Nginx搭建流行架构LNMP的步骤
Nginx目录结构有哪些
Nginx 如何实现高性能低消耗





 工商网监
工商网监
评论