 RabbitMQ通信模型中的work模型
RabbitMQ通信模型中的work模型
上一篇文章中,简单的介绍了一下RabbitMQ,以及安装和hello world。
有的小伙伴留言说看不懂其中的方法参数,这里先解释一下几个基本的方法参数。
// 声明队列方法
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
/**
* param1:queue 队列的名字
* param2:durable 是否持久化;比如现在发送到队列里面的消息,如果没有持久化,重启这个队列后数 据会丢失(false) true:重启之后数据依然在
* param3:exclusive 是否排外(是否是当前连接的专属队列),排外的意思是:
* 1:连接关闭之后 这个队列是否自动删除(false:不自动删除)
* 2:是否允许其他通道来进行访问这个数据(false:不允许)
* param4:autoDelete 是否自动删除
* 就是当最后一个连接断开的时候,是否自动删除这个队列(false:不删除)
* param5:arguments(map) 声明队列的时候,附带的一些参数
*/
// 发送数据到队列
channel.basicPublish("", QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, "第一个队列消息...".getBytes());
/**
* param1:exchange 交换机 没有就设置为 "" 值就可以了
* param2:routingKey 路由的key 现在没有设置key,直接使用队列的名字
* param3:BasicProperties 发送数据到队列的时候,是否要带一些参数。
* MessageProperties.PERSISTENT_TEXT_PLAIN表示没有带任何参数
* param4:body 向队列中发送的消息数据
*/
Work模型
work模型称为工作队列或者竞争消费者模式,多个消费者消费的数据之和才是原来队列中的所有数据,适用于流量的削峰。
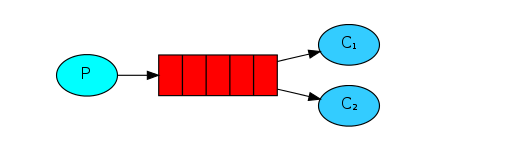
img
演示
写个简单的测试:
生产者
public class Producer { private static final String QUEUE_NAME = "queue_work_1"; public static void main(String[] args) throws IOException, TimeoutException { Connection connection = ConnectionUtils.getConnection(); Channel channel = connection.createChannel(); channel.queueDeclare(QUEUE_NAME, false, false, false, null); for (int i = 0; i < 100; i++) { channel.basicPublish("", QUEUE_NAME, null, ("work模型:" + i).getBytes()); } channel.close(); connection.close(); } }消费者
// 消费者1 public class Consumer { private static final String QUEUE_NAME = "queue_work_1"; public static void main(String[] args) throws IOException, TimeoutException { Connection connection = ConnectionUtils.getConnection(); Channel channel = connection.createChannel(); channel.queueDeclare(QUEUE_NAME, false, false, false, null); // channel.basicQos(0, 1, false); DefaultConsumer defaultConsumer = new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { System.out.println(System.currentTimeMillis() + "消费者1接收到信息:" + new String(body)); channel.basicAck(envelope.getDeliveryTag(), false); } }; channel.basicConsume(QUEUE_NAME, false, defaultConsumer); } }// 消费者2 public class Consumer2 { private static final String QUEUE_NAME = "queue_work_1"; public static void main(String[] args) throws IOException, TimeoutException { Connection connection = ConnectionUtils.getConnection(); Channel channel = connection.createChannel(); channel.queueDeclare(QUEUE_NAME, false, false, false, null); // channel.basicQos(0, 1, false); DefaultConsumer defaultConsumer = new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { System.out.println(System.currentTimeMillis() + "消费者2接收到信息:" + new String(body)); channel.basicAck(envelope.getDeliveryTag(), false); // 这里加了个延迟,表示处理业务时间 try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } } }; channel.basicConsume(QUEUE_NAME, false, defaultConsumer); } }结果
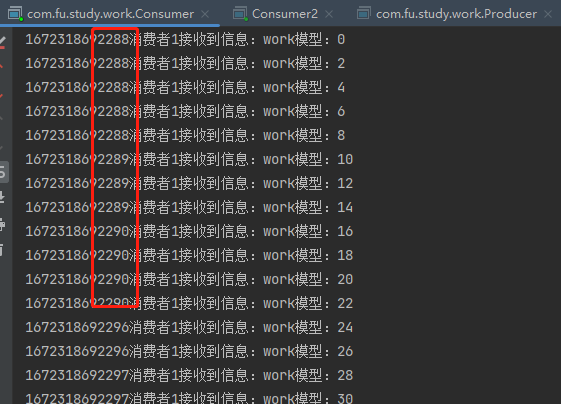
image-20221229210012145


image-20221229210046184
可以看出来:100条消息,消费者之间是平分的,消费者1 几乎是瞬间完成,消费者2 则是慢慢吞吞的运行完毕,消费者1大量时间处于空闲状态,消费者2则一直忙碌。这显然是不适用于实际开发中。
我们需要遵从一个原则,就是 能者多劳 ,消费越快的人,消费的越多;
现在我们把消费者1和2的代码中 // channel.basicQos(0, 1, false); 这行代码取消注释,再次运行;

image-20221229211317632

image-20221229211335782
现在的结果就比较符合能者多劳,虽然你干的多,但是工资是一样的呀~
work模型的一个主要的方法是basicQos();这里也解释一下其参数:
// 设置限流机制
channel.basicQos(0, 1, false);
/**
* param1: prefetchSize,消息本身的大小 如果设置为0 那么表示对消息本身的大小不限制
* param2: prefetchCount,告诉rabbitmq不要一次性给消费者推送大于N个消息
* param3:global,是否将上面的设置应用于整个通道,false表示只应用于当前消费者
*/
小结
本文到这里就结束了,主要介绍了RabbitMQ通信模型中的work模型,适用于限流、削峰等应用场景。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
数据
+关注
关注
8文章
7223浏览量
90169 -
通信
+关注
关注
18文章
6114浏览量
136768 -
模型
+关注
关注
1文章
3415浏览量
49475 -
Work
+关注
关注
0文章
9浏览量
9103 -
rabbitmq
+关注
关注
0文章
18浏览量
1067
发布评论请先 登录
相关推荐
CAN总线通信协议模型概述 CAN总线通信模型作用
参照 ISO/OSI 标准模型,CAN 总线的通信参考模型如图 9-1 所示。这 4 层结构的功能如下:• 物理层规定了节点的全部电气特性,在一个网络里,要实现不同节点间的数据传输,所有节点的物理层
发表于 12-14 14:17
MQTT的通信模型及消息
MQTT通信模型 MQTT协议是基于客户端-服务器模型,在协议中主要有三种身份:发布者(Publisher)、服务器(Broker) 以及订阅者(Subscriber)。 并且消息发布者可以
发表于 01-19 15:57
基于VxWorks实时操作系统的通信模型该怎样去设计?
多任务实时操作系统VxWorks是什么?与传统通信机制相比,模块间通信模型有什么优势?基于VxWorks实时操作系统的通信模型该怎样去设计?
发表于 04-26 06:25
移动Agent位置透明通信模型的设计
提出一种高效可靠的移动Agent通信模型――D-C通信模型,结合域名字解析器和移动Agent系统中的Communicator实现移动Agent之间的通信。通过引入一种基于全局的、与位置
发表于 04-16 08:53
•26次下载
过程控制工业以太网通信模型探讨
提出了建立在交换式以太网和IEEE 802.1Q/P 技术基础上用于过程控制的以太网通信模型REPC,并进行了分析。关键词:通信模型工业以太网 过程控制Abstract: REPC, a communication model of in
发表于 06-19 08:34
•27次下载
数据网格中基于优化机制的通信模型
针对基于多计算机机群构成的网格的大规模并行计算的需要,对多级分组通信模型的单一机群分组通信进行了研究。探讨了在单一机群内的主动节点、被动节点个数和各个计算节点
发表于 06-25 13:52
•12次下载
基于VxWorks的通信模型设计
本文提出了一种任务间的通信模型,将用于网络通信的UDP方式引进到任务间的通信中,使通信更加灵活和便于管理,改善了整个系统的性能。
发表于 06-01 10:07
•1079次阅读
企业资产管理系统中通信模型的研究与实现
为了改善企业资产管理(EAM)系统在用户体验、模块间数据传输效率及耦合度等方面的不足,构建了基于Silverlight与WCF技术研究与实现EAM系统中的通信模型。利用Silverlight构建客户端提升
发表于 07-06 16:57
•34次下载
RabbitMQ中的路由模型(direct)
路由模型 RabbitMQ 提供了五种不同的通信模型,上一篇文章中,简单的介绍了一下RabbitMQ的发布订阅
什么是通信模型DDS
完成的,它相当于是ROS机器人系统中的神经网络。 通信模型 DDS的核心是通信,能够实现通信的模型和软件框架非常多,这里我们列出常用的四种





 工商网监
工商网监
评论