 NUS&深大提出VisorGPT:为可控文本图像生成定制空间条件
NUS&深大提出VisorGPT:为可控文本图像生成定制空间条件

论文简介
可控扩散模型如ControlNet、T2I-Adapter和GLIGEN等可通过额外添加的空间条件如人体姿态、目标框来控制生成图像中内容的具体布局。使用从已有的图像中提取的人体姿态、目标框或者数据集中的标注作为空间限制条件,上述方法已经获得了非常好的可控图像生成效果。那么如何更友好、方便地获得空间限制条件?或者说如何自定义空间条件用于可控图像生成呢?例如自定义空间条件中物体的类别、大小、数量、以及表示形式(目标框、关键点、和实例掩码)。
本文将空间条件中物体的形状、位置以及它们之间的关系等性质总结为视觉先验(Visual Prior),并使用Transformer Decoder以Generative Pre-Training的方式来建模上述视觉先验。因此,我们可以从学习好的先验中通过Prompt从多个层面,例如表示形式(目标框、关键点、实例掩码)、物体类别、大小和数量,来采样空间限制条件。我们设想,随着可控扩散模型生成能力的提升,以此可以针对性地生成图像用于特定场景下的数据补充,例如拥挤场景下的人体姿态估计和目标检测。
方法介绍
表1 训练数据
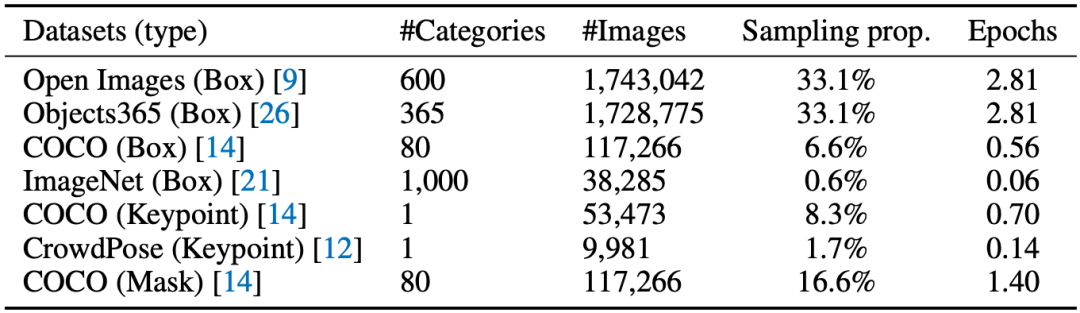
本文从当前公开的数据集中整理收集了七种数据,如表1所示。为了以Generative Pre-Training的方式学习视觉先验并且添加序列输出的可定制功能,本文提出以下两种Prompt模板:

使用上述模板可以将表1中训练数据中每一张图片的标注格式化成一个序列x。在训练过程中,我们使用BPE算法将每个序列x编码成tokens={u1,u2,…,u3},并通过极大化似然来学习视觉先验,如下式:
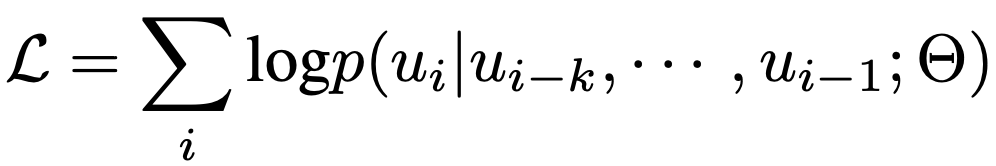
最后,我们可以从上述方式学习获得的模型中定制序列输出,如下图所示。
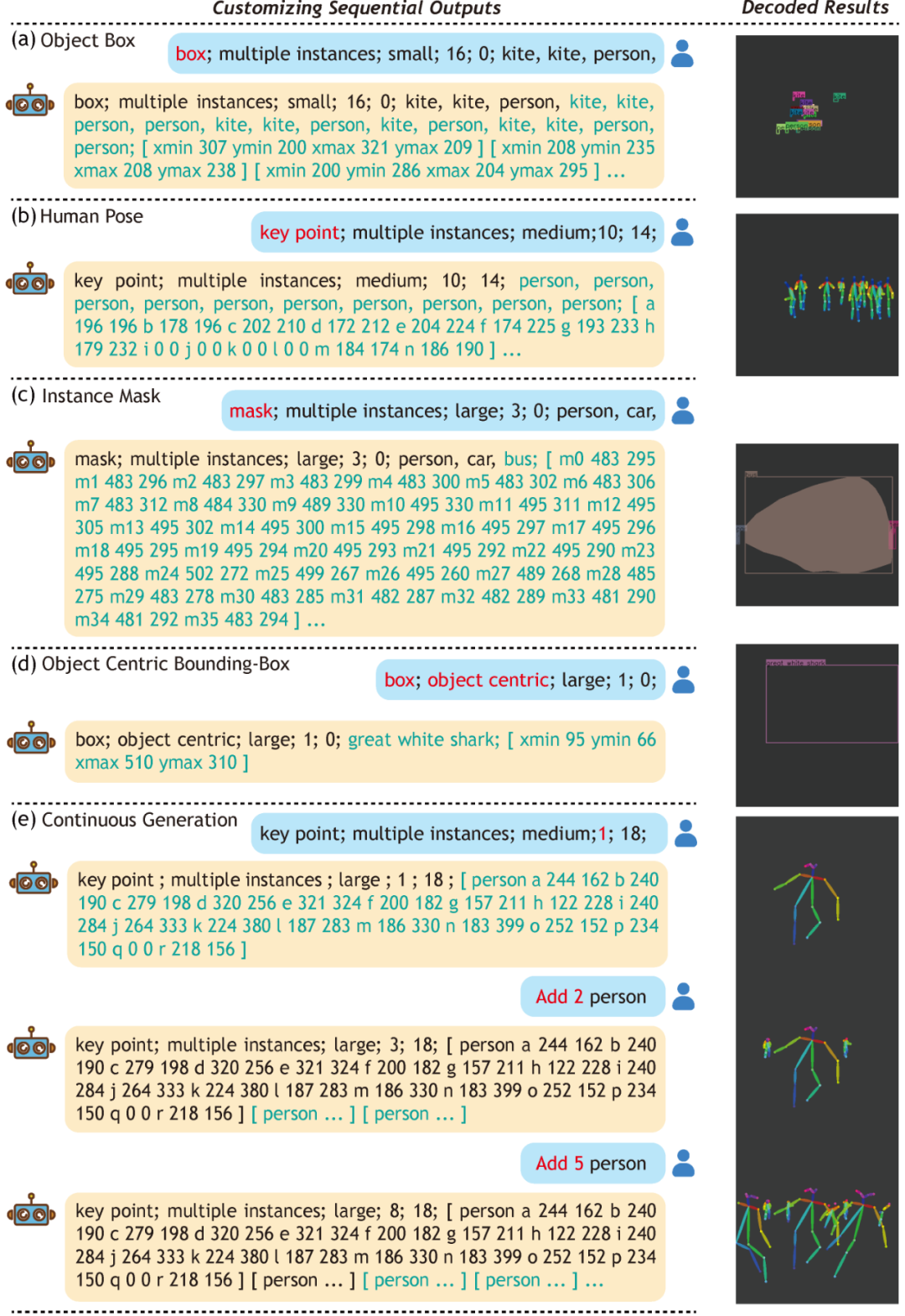
图1 定制序列输出
效果展示



-
模型
+关注
关注
1文章
3831浏览量
52287 -
数据集
+关注
关注
4文章
1240浏览量
26264 -
图像生成
+关注
关注
0文章
26浏览量
7185
原文标题:NeurIPS 2023 | NUS&深大提出VisorGPT:为可控文本图像生成定制空间条件
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【高端人才招聘】格见半导体 资深数字后端工程师 上海&成都
LoRa1121 FCC&CE认证 多频段LoRa无线通讯模块规格书
探秘EV系列0.8 Amp敏感可控硅:特性、应用与设计要点
30/35 Amp高温双向可控硅——QJxx30xH4 & QJxx35xH4系列的特性与应用
【深度实战】MYD-LR3576 AMP非对称多核开发指南:从配置到实战

罗德与施瓦茨宣布推出新频段 R&amp;amp;S ZNB3000 矢量网络分析仪,频率高达 54 GHz

rt-thread studio debug生成了elf &amp; map,为什么不生成反汇编呢?
1218 MHz 高输出 GaN CATV 功率倍增器 Amp扩音器 skyworksinc

870 MHz、25 dB 增益 CATV 功率倍增器 Amp扩音器 skyworksinc
1 GHz、28 dB 增益 CATV 功率倍增器 Amp扩音器 skyworksinc
CS86706适用1~3节锂电应用,内置升压模块,2×30W立体声&amp;amp;50W单声道R类音频功率放大器

关于鸿蒙App上架中“AI文本生成模块的资质证明文件”的情况说明
新知|Verizon与AT&amp;amp;T也可以手机直接连接卫星了

rt-thread studio debug生成了elf &amp;amp; map,为什么不生成反汇编?
多模块配置!YU系列USB、Type-C连接器为工控机打造&amp;quot;全能型&amp;quot;数据传输方案




评论