 华为提出Sorted LLaMA:SoFT代替SFT,训练多合一大语言模型
华为提出Sorted LLaMA:SoFT代替SFT,训练多合一大语言模型
ChatGPT、LLaMa等大型语言模型(LLMs)在自然语言处理领域带来的革命性进步。通过有监督微调(SFT)的训练方式,这些模型拥有强大的上下文学习能力,在各种任务中都展现了超凡的表现。然而,它们也有一个不小的问题——庞大的存储空间和高昂的计算资源成本。
但现在,研究人员们为我们带来了一项新的解决方案——SortedNet。它允许我们在一个大型模型内创建多个“子模型”,每一个都有自己专门的任务责任区。这意味着我们可以根据自己的需求和可用资源来选择适合的子模型,从而大幅度减少存储空间和计算资源的需求。
而这一切的背后,是一项名为Sorted Fine-Tuning(SoFT)的新训练技术。SoFT让我们可以在一个训练周期内产出多个子模型,无需任何额外的预训练步骤。此外,这项技术还揭示了模型的中间层也能够产生高质量的输出,这一点在之前的研究中常常被忽视。
为了证明这种方法的有效性,研究人员使用了LLaMa 2 13B和Stanford Alpaca数据集进行测试和验证。他们不仅对比了SFT和SoFT这两种方法,还创建了多个不同层次的子模型来确定哪些层最能产出高质量的结果。测试结果令人鼓舞——使用SoFT创建的子模型不仅运行速度更快,而且能够保持或甚至超越原始模型的性能水平。
让我们一起深入了解一下SortedNet和SoFT技术吧!

Paper:Sorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic Inference Using Sorted Fine-Tuning
Link:https://arxiv.org/abs/2309.08968
Many-in-One LLMs
在介绍这篇研究之前,先让我们了解一下什么是Many-in-One。
深度神经网络通常存在过多的参数,导致模型部署的成本增加。此外,在实际应用中,这些过度参数化的深度神经网络需要为具有不同需求和计算预算的客户提供服务。为了满足这些多样化的需求,可以考虑训练不同大小的模型,但这将非常昂贵(涉及训练和内存成本),或者另一种选择是训练Many-in-One网络。
Many-in-One解决方案是在一个神经网络模型内部包含多个子网络,每个子网络可以执行不同的任务或具有不同的结构。这个方法的目标是将多个任务或模型结构整合到一个统一的网络中,从而提高模型的通用性和适应性。例如:
早期退出(Early Exit):在训练过程中,Early Exit在除了最后的预测层之外,还在网络的特定中间层上添加了额外的预测头。这些预测头在需要时提供中间预测,可以实现更快的推断速度。
层丢弃(Drop Layer),通过在训练期间随机丢弃层来训练具有任意深度的网络。
最近,LLMs引起了广泛的关注。为了使LLMs适应这些多样化的需求,研究者提出了两种适应方法:参数高效调整(PEFT)和模型压缩。
PEFT:核心主干模型保持不变,而只更新一些适配器参数。这些适配器的作用就像是在LLMs上进行微调,使其适应不同的任务和需求。有一些PEFT的变种,比如LoRA、KRONA、Adapter、DyLoRA、Ladder Side-Tuning和Compacter等。这些方法可以让LLMs更加灵活,但仍然无法提供动态大小的LLMs。
模型压缩:在模型压缩中,大型模型通过知识蒸馏、修剪和量化等压缩方法来减小尺寸。这些方法可以生成不同尺寸的模型,但需要分别对每个压缩模型进行训练,而且它们也不是多合一模型。
现在,再回到Many in one LLMs的概念。这是一种非常有趣的想法,它们可以同时适应多种不同的任务和需求。但到目前为止,我们还没有看到发布的多合一LLM模型。因此,在这项研究中,研究人员将一种SortedNet的训练方法应用到LLaMA 13B模型上,这将成为第一个Many in one LLM。
方法
这项研究的方法涉及将大型语言模型(LLMs)转化为多合一模型,灵感来自SortedNet方法,主要步骤如下:
形成子网络:首先需要将LLMs划分为多个子网络。子网络的深度(即前n层的子模型)用fn(x; θn)表示。在这项研究中,选择的语言模型是LLaMA2 13B,总共包括40层。因此,定义了一系列不同层数的子网络,如12层、16层、20层等。
计算子网络的输出:每个子模型的输出将通过使用原始网络最后一层的共享输出预测头来进行预测。需要注意的是,在LLaMA模型中,输出预测头之前存在一个RMSNorm层,该归一化层被添加到每个子模型的共享预测头之前。研究人员认为,这种归一化对于Sorted LLama在所有子模型上更好地泛化至关重要。
目标函数:为了训练这些子网络,定义了每个子模型的损失函数Ln(x; θn)。总损失L是所有子模型和主模型的损失之和。
训练数据集:在这项研究中,使用了Stanford Alpaca数据集,该数据集包含了5.2万个指令跟随示例的演示。
评估:除了评估最后一层的嵌入质量外,还评估了从第1到第n个块的中间输出的嵌入质量。Panda-LM基准用于比较不同子模型的输出。Panda-LM使用一个大型语言模型来评估来自两个源的生成文本的质量。最终的评估结果包括胜利次数、失败次数和验证集中的平局次数。最终得分是通过特定的公式计算出来,表示模型在指令跟随任务上的性能,得分范围在-1到1之间。
Baseline:作者对LLama2 13B模型进行了微调,采用了两种不同的设置作为基线:常规监督微调(SFT)和排序微调(SoFT)。其中,常规监督式微调是常见做法,主要关注网络的最后一层的训练。在这种情况下,只对网络的最后一层进行微调。排序微调(SoFT)下,计算从第12层到第40层(最后一层)的多个输出的损失,分为四个间隔,并同时训练多个模型,就像在前面的部分中解释的那样。
实验结果
对于生成模型的不同层排序信息的影响是什么?
研究者首先关注了在不同层次的生成模型中对信息进行排序的效果。他们进行了一系列实验,生成了不同层次的响应,并使用PandaLM评估器进行了成对比较。结果显示,Sorted Fine-Tuning对于将学到的知识传递到中间层具有显著影响。在自动评估中,Sorted LLaMA在几乎所有层次上都表现出色,远远超过了常规微调(SFT)。
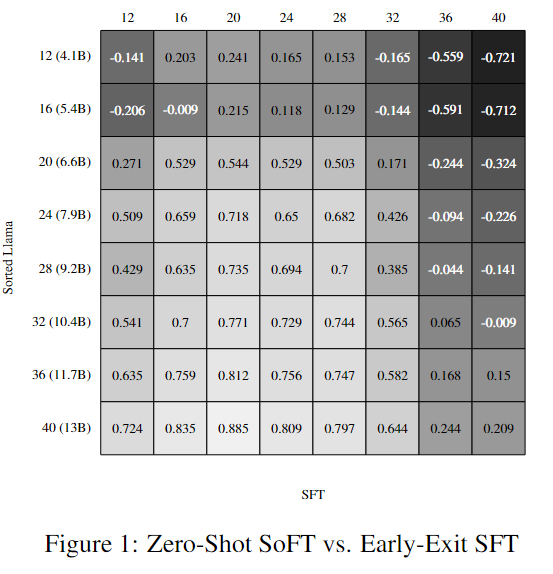
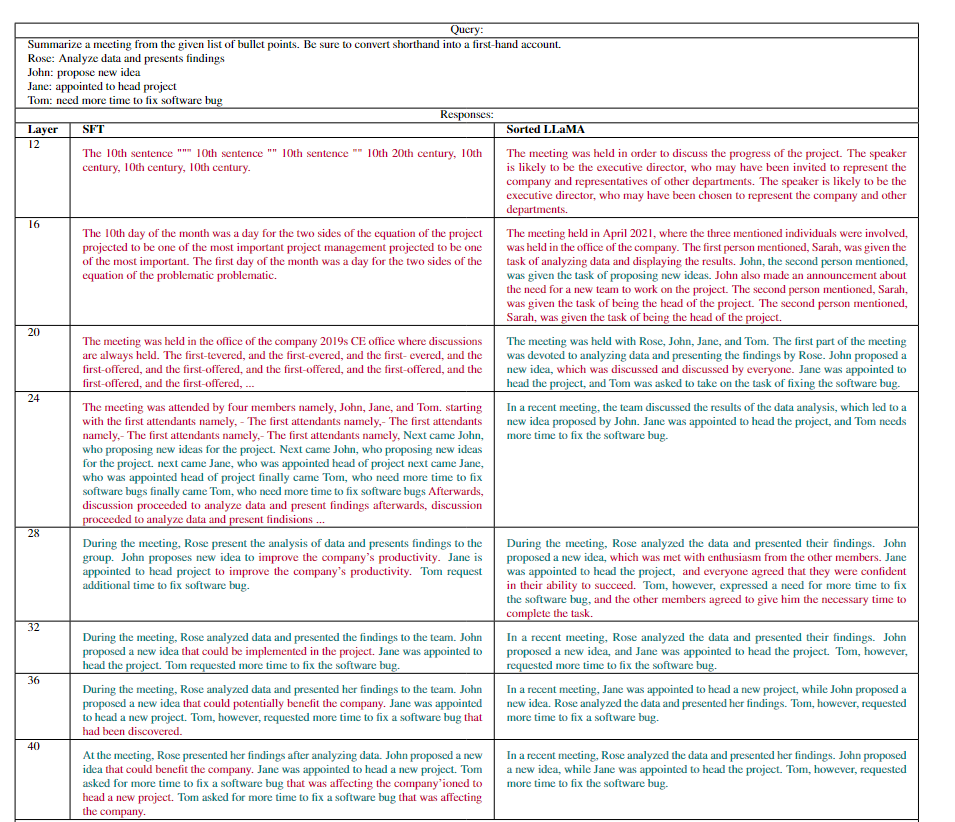
需要注意的是,尽管对SoFT的性能进行了zero-shot评估,但为了更好地理解SFT层次的结果,研究者进行了额外的训练——对每个子模型的分类层进行训练。可以注意到,与Sorted LLaMA的第12层相比,SFT的第12层性能略好。下表是一个生成的回复例子,可以看到SFT中较早层的生成文本大多是乱码的。当我们进入SFT中的较高层时,生成的文本变得越来越有意义,这使得与Sorted LLAMA层的比较更加合理。
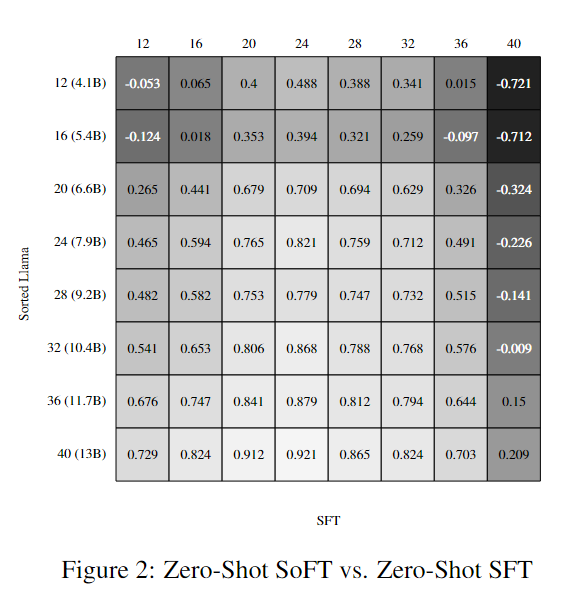
这一部分的实验结果呈现出了Sorted Fine-Tuning对于LLama2模型性能的积极影响,尤其是在中间层次的性能上,这为后续的研究提供了重要基准。
此外,结果还突显了Sorted Fine-Tuning能够生成性能强大且尺寸较小的子模型,这些子模型与原始模型的性能相媲美。在接下来的图表中,研究者进行了SFT和SoFT在不同条件下的评估,结果显示,无论是零-shot还是Early-Exit,两种方法的结果几乎没有变化。这些实验证明了Sorted Fine-Tuning的鲁棒性和有效性。
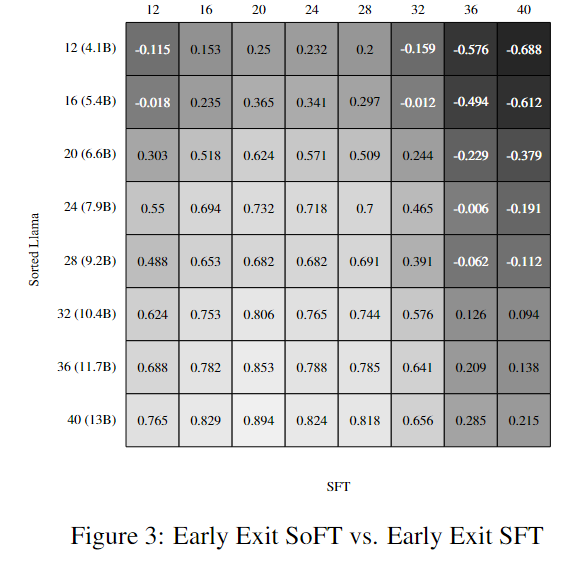
结果分析
SoFT和SFT学习到的概率分布对比
研究者使用Kullback-Leibler(KL)散度作为度量标准来衡量两个概率分布之间的相似性。
下图(a)比较了Sorted LLaMA和SFT子模型在不同输出位置上的概率分布。首先,图(a)左展示了与SFT模型的最后一层以及从第12层到第36层的层次之间的比较。可以明显看出,与生成初始标记后的最后一层相比,即使在较高的层次,如36和32,输出分布迅速发散。需要注意的是,这种评估是在zero-shot方式下生成的,没有调整分类器头。
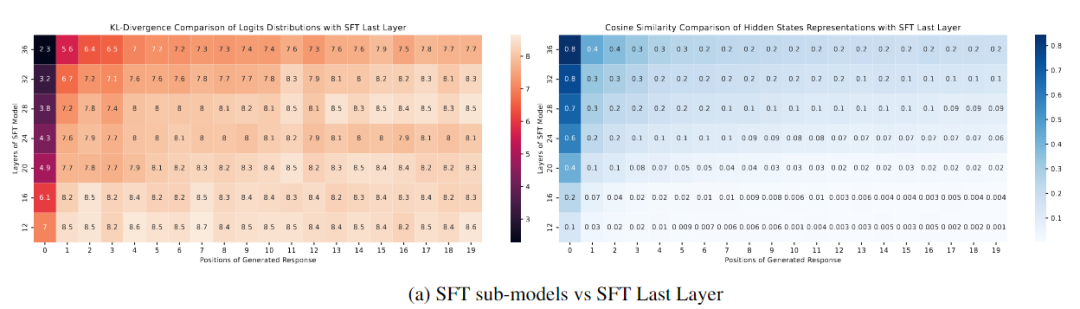
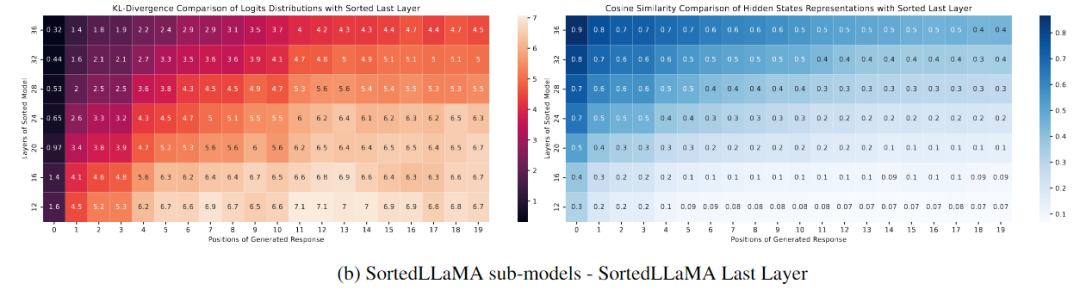
下图(b)显示了在Sorted LLaMA中,随着我们靠近最后一层,生成结果的可能性分布越来越接近完整尺寸子模型,至少在生成文本的初始位置上是如此。
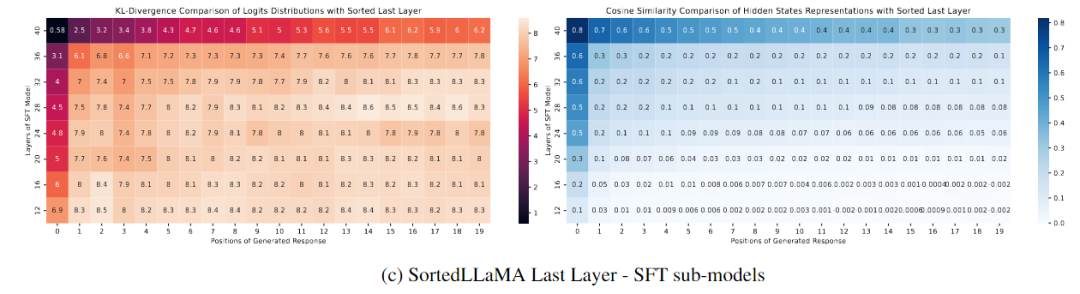
下图(c)展示了不同SFT层次与最后一个Sorted LLaMA层次之间的比较。图中显示,只有SFT的完整尺寸输出分布接近排序的完整尺寸模型,而其他层次的分布在生成文本的初始步骤中与SoFT相比迅速发散。
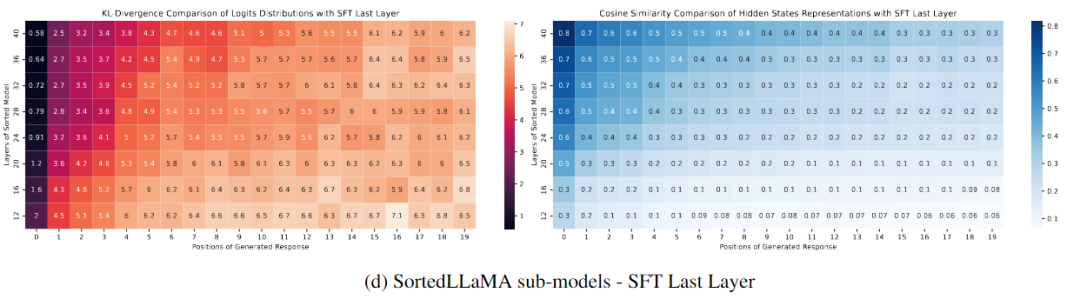
图(d)比较了所有排序层次的输出分布与最后一个SFT层次的输出分布。与图4c(左)相比,图4d(左)显示Sorted LLaMA甚至在较低层次的初始输出标记上也能保持与SFT完整尺寸模型接近的输出分布。
总结
这项工作提出了Sorted LLaMA,它是一种基于Sorted Fine-Tuning而不是监督微调获得的多合一LLaMA模型,用于动态推理。Sorted LLaMA释放了中间层的潜在表示能力,提供了无需预训练或与模型压缩相关的额外开销的动态自适应能力。它为NLP领域中生成语言模型的优化提供了有前途的途径。
SoFT使这些模型的部署更加高效。由于所有子模型仍然是原始模型的组成部分,因此存储要求和不同计算需求之间的过渡成本最小化,使得在推理期间管理多个模型成为现实。
这些分析结果揭示了Sorted Fine-Tuning对于生成模型的输出分布的影响,特别是在不同的模型层次上,以及Sorted LLaMA在保持输出分布方面的能力。这些结果有助于更深入地理解Sorted Fine-Tuning方法的效果。
-
华为
+关注
关注
216文章
34690浏览量
253787 -
模型
+关注
关注
1文章
3415浏览量
49473 -
语言模型
+关注
关注
0文章
550浏览量
10422 -
ChatGPT
+关注
关注
29文章
1578浏览量
8285
原文标题:华为提出Sorted LLaMA:SoFT代替SFT,训练多合一大语言模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【飞腾派4G版免费试用】仙女姐姐的嵌入式实验室之五~LLaMA.cpp及3B“小模型”OpenBuddy-StableLM-3B
【大语言模型:原理与工程实践】大语言模型的预训练
Multilingual多语言预训练语言模型的套路
一种基于乱序语言模型的预训练模型-PERT
基于预训练模型和语言增强的零样本视觉学习

Meta发布一款可以使用文本提示生成代码的大型语言模型Code Llama

大语言模型(LLM)预训练数据集调研分析

大语言模型简介:基于大语言模型模型全家桶Amazon Bedrock
Meta推出最强开源模型Llama 3 要挑战GPT
Llama 3 语言模型应用

用Ollama轻松搞定Llama 3.2 Vision模型本地部署






 工商网监
工商网监
评论