 3D 飞行时间应用快速入门
3D 飞行时间应用快速入门

作者:Stephen Evanczuk
3D 飞行时间 (ToF)成像为视频成像提供了一种有效的替代方法,可用于包括工业安全、机器人导航、手势控制界面等在内的广泛应用。但是,这种方法需要慎重整合光学设计、精密定时电路和信号处理功能,常常会让开发人员难以实现有效的3D ToF 平台。
本文将说明 ToF 技术的微妙之处,然后展示两个现成的 3D ToF 套件——Analog Devices 的 AD-96TOF1-EBZ 开发平台和ESPROS Photonics 的 EPC660 评估套件,介绍它们如何帮助开发人员快速设计 3D ToF 应用原型,并获得所需的经验来实现 3D ToF设计以满足开发人员的独特要求。
什么是 ToF 技术?
ToF 技术基于一个大家熟悉的原理,即物体与某个源点之间的距离可以通过测量源点发射能量的时间与源点收到反射信号的时间之差来得出(图 1)。
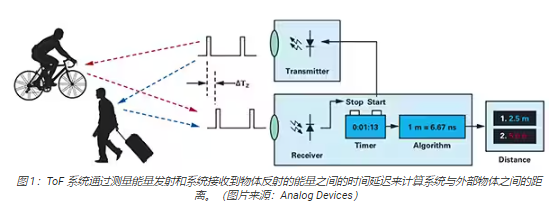
尽管基本原理相同,ToF 解决方案却千差万别,并且因为采用不同的基础技术——包括超声波、光检测和测距 (LiDAR)、相机、毫米波 (mmWave)射频信号——而具有一些固有的能力和局限性:
超声波 ToF 解决方案成本低,但物体的范围和空间分辨率有限
光学 ToF 解决方案可以实现比超声波系统更高的范围和空间分辨率,但会受到浓雾或烟雾的影响
基于毫米波技术的解决方案通常更为复杂和昂贵,但不受烟、雾或雨的影响,能在较大范围内工作,并提供有关目标物体的速度和航向的信息
制造商可以根据需要利用不同技术的能力来满足特定需求。例如,超声波传感器非常适合检测障碍物,可以帮助机器人越过道路,或帮助驾驶员停车。相比之下,毫米波技术可为车辆提供长距离感测能力,从而在其他传感器因为恶劣天气状况而无法工作的情况下,也能检测到正在接近的道路危险。
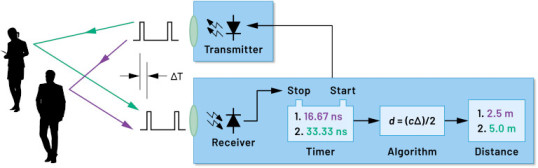
ToF 设计可以围绕一对发射器/接收器来构建。例如,简单的光学 ToF 设计在概念上仅需一个 LED来照亮某个目标区域,以及一个光电二极管来检测该目标区域内物体的反射。尽管如此,这种看似简单的设计仍需要精确的定时和同步电路来测量延迟。另外,可能需要调制和解调电路来将照明信号与背景源区分开来,或支持更复杂的连续波方法。
随着开发人员努力提高信噪比 (SNR) 并消除 ToF系统中的伪影,设计复杂度迅速攀升。让复杂性进一步加剧的是,更先进的检测解决方案会采用多个发射器和接收器来跟踪多个物体,或支持更复杂的运动跟踪算法。例如,毫米波系统常常会运用多个接收器来跟踪多个独立物体的航向和速度。(请参阅“使用毫米波雷达套件快速开发精密目标检测设计”。)
3D 光学 ToF 系统
3D 光学 ToF 系统扩展了使用更多接收器的理念,即采用通常基于电荷耦合器件 (CCD) 阵列的成像传感器。当一组透镜将某个目标区域聚焦到 CCD阵列上时,该区域中的相应点会反射光线,返回的光线会为 CCD 阵列中的每个电荷储存器件充电。到达 CCD阵列的反射光与脉冲或连续波照明同步后,基本上分别在一系列窗口或相位中得到捕获。此类数据会经过进一步处理,可创建一个由体素 (VOlume piXEL) 组成的3D 深度图,其值表示到目标区域中相应点的距离。
像视频中的帧一样,可以依次捕获各个深度图,以提供具有时间分辨率(仅受图像捕获系统的帧率限制)和空间分辨率(仅受 CCD阵列和光学系统限制)的测量结果。随着更大的 320 x 240 CCD 成像仪的出现,更高分辨率的 3D 光学 ToF系统能应用于更广泛的领域,包括工业自动化和无人机 (UAV),甚至手势界面(图 2)。

与大多数基于相机的方法不同,3D ToF 系统可以在阴影或光照不断变化的条件下提供精确结果。这些系统会提供自己的照明,通常使用激光器或大功率红外LED(例如 Lumileds 的 Luxeon IR LED),这些 LED 能以此类系统使用的兆赫兹 (MHz) 开关速率工作。与立体摄像机等方法不同,3DToF 系统提供了一种紧凑型解决方案来生成详细的距离信息。
预置解决方案
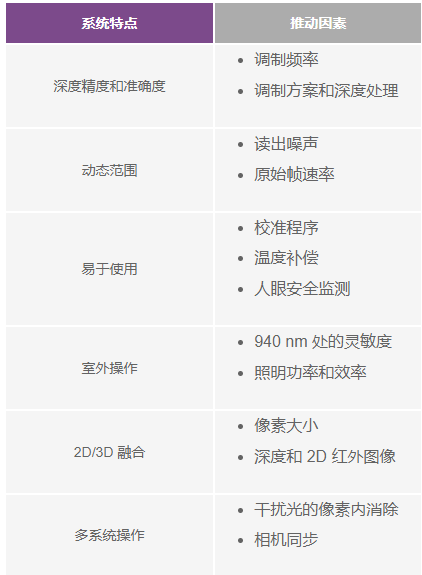
然而,为了实现 3D ToF系统,开发人员面临多项设计挑战。除了前面提到的定时电路之外,这些系统还依赖于精心设计的信号处理流水线,该流水线须进行优化,以便针对每个窗口或相位测量快速读取CCD 阵列中的结果,然后完成所需的处理,将原始数据转换为深度图。先进的 3D ToF 成像仪如 ESPROS Photonics 的EPC660-CSP68-007 ToF 成像仪,集 320 x 240 CCD 阵列与所需的全部配套定时和信号处理能力于一体,可执行 3D ToF测量并提供每像素 12 位距离数据(图 3)。

ESPROS Photonics 的 EPC660-007 卡边缘连接器芯片载板将 epc650 成像仪安装在 37.25 x 36.00 毫米 (mm)的印刷电路板(PC 板)上,并配有去耦电容器和卡边缘连接器。尽管此芯片载板解决了 3D ToF
系统设计中的基本硬件接口问题,但开发人员要负责在前端完成适当光学设计,并在后端提供处理资源。ESPROS Photonics 的 epc660评估套件提供完整的 3D ToF 应用开发环境,其中包括预置 3D ToF 成像系统和相关软件,无需开发人员完成上述任务(图 4)。

ESPROS 套件设计用于评估和快速原型开发,提供了一个预装配好的相机系统,其中整合了 epc660 CC 芯片载板、光学透镜组件和一组八个LED。除相机系统外,BeagleBone Black 处理器板具有 512 MB RAM 和 4 GB 闪存,可用作主机控制器和应用处理资源。
ESPROS 还提供了 epc660评估套件支持软件,该软件可从其网站下载。该软件需要密码才能打开,密码可从该公司的当地销售办事处索取。获得该软件的使用权后,开发人员只需使用所提供的配置文件之一运行一个图形用户界面(GUI) 应用程序,即可开始操作相机系统。此外,GUI应用程序还提供了控制和显示窗口,可用于设置其他参数,包括空间和时间滤波器设置,以及用于查看结果。开发人员可以毫不费力地使用该套件实时捕获深度图,并将其用作自己的应用软件输入。
增强分辨率的 3D ToF 系统
诸如 ESPROS epc660 之类的 320 x 240成像仪可以服务于许多应用,但分辨率可能不足以检测手势界面中的微小移动,或在不严格限制目标范围的情况下区分微小物体。对于这些应用,基于 640 x 480 ToF传感器的现成开发套件的出现,能够让开发人员快速开发高分辨率应用原型。
Seeed Technology 的 DepthEye Turbo 深度相机将 640 x 480 ToF 传感器、四个 850 纳米 (nm)
垂直腔表面发射激光器 (VCSEL) 二极管、照明和感测操作电路、电源及 USB 接口支持集成在一个尺寸为 57 x 57 x 51 mm的自足式立方体中。软件支持通过开源的 libPointCloud SDK github 存储库提供,并支持 Linux、Windows、Mac OS 和Android 平台。
除了 C++ 驱动程序、库和示例代码之外,libPointCloud SDK 发行版还包括用于快速开发原型的 Python API和可视化工具。在主机开发平台上安装发行包之后,开发人员可以通过 USB将相机连接到计算机,然后即可开始使用可视化工具显示相位、幅度或点云图;这些图本质上是使用纹理表面渲染的增强深度图,可提供更平滑的 3D 图像(图 5)。

Analog Devices 的 AD-96TOF1-EBZ 3D ToF 评估套件提供了一个更为开放的硬件设计,它由一对板构建,专门使用Raspberry Pi 的 Raspberry Pi 3 Model B+ 或 Raspberry Pi 4 作为主机控制器和本地处理资源(图 6)。

该套件的模拟前端 (AFE) 板容纳了光学组件、CCD阵列和缓冲器、固件存储以及一个处理器;该处理器管理相机的整体操作,包括照明定时、传感器同步和深度图生成。第二块板容纳了四个 850 nm VCSEL激光二极管和驱动器,能连接到 AFE 板,以使激光二极管环绕光学组件,如上图所示。
Analog Devices 通过开源的 3D ToF 软件套件来支持 AD-96TOF1-EBZ 套件,软件套件含有 3D ToF SDK 以及C/C++、Python、Matlab 的示例代码和包封。为了在网络环境中同时支持主机应用和底层硬件交互,Analog Devices 将 SDK划分为两部分:一个是针对 USB 和网络连接优化的主机部分,一个是在嵌入式 Linux 上运行并基于 Video4Linux2 (V4L2)驱动程序的底层部分(图 7)。

这个支持网络的 SDK 允许联网主机上运行的应用程序与 ToF 硬件系统远程协作,以访问相机并捕获深度数据。此外,用户程序也可以在嵌入式 Linux部分中运行,并充分利用该层级提供的高级选项。
作为软件分发的一部分,Analog Devices 提供了示例代码来展示关键的底层操作功能,例如在主机上以及在本地使用嵌入式 Linux进行相机初始化、基本帧捕获、远程访问和跨平台捕获。其他示例应用程序基于这些基本操作而构建,用以说明如何在更高级别的应用(如点云生成)中使用捕获的数据。事实上,有一个示例应用程序展示了如何使用深度神经网络(DNN) 推理模型对相机系统生成的数据进行分类。该 DNN 示例应用程序 (dnn.py) 用 Python编写,逐步展示了获取数据和通过推理模型准备数据分类的过程(清单 1)。
import aditofpython as tof
import numpy as np
import cv2 as cv
。。. try:
net = cv.dnn.readNetFromCaffe(args.prototxt, args.weights)
except:
print(“Error: Please give the correct location of the prototxt and
caffemodel”)
sys.exit(1)
swapRB = False
classNames = {0: ‘background’,
1: ‘aeroplane’, 2: ‘bicycle’, 3: ‘bird’, 4: ‘boat’,
5: ‘bottle’, 6: ‘bus’, 7: ‘car’, 8: ‘cat’, 9: ‘chair’,
10: ‘cow’, 11: ‘diningtable’, 12: ‘dog’, 13: ‘horse’,
14: ‘motorbike’, 15: ‘person’, 16: ‘pottedplant’,
17: ‘sheep’, 18: ‘sofa’, 19: ‘train’, 20: ‘tvmonitor’}
system = tof.System()
status = system.initialize()
if not status:
print(“system.initialize() failed with status: ”, status)
cameras = []
status = system.getCameraList(cameras)
。。. while True:
Capture frame-by-frame
status = cameras[0].requestFrame(frame)
if not status:
print(“cameras[0].requestFrame() failed with status: ”, status)
depth_map = np.array(frame.getData(tof.FrameDataType.Depth), dtype=“uint16”,
copy=False)
ir_map = np.array(frame.getData(tof.FrameDataType.IR), dtype=“uint16”,
copy=False)
Creation of the IR image
ir_map = ir_map[0: int(ir_map.shape[0] / 2), :]
ir_map = np.float32(ir_map)
distance_scale_ir = 255.0 / camera_range
ir_map = distance_scale_ir * ir_map
ir_map = np.uint8(ir_map)
ir_map = cv.cvtColor(ir_map, cv.COLOR_GRAY2RGB)
Creation of the Depth image
new_shape = (int(depth_map.shape[0] / 2), depth_map.shape[1])
depth_map = np.resize(depth_map, new_shape)
distance_map = depth_map
depth_map = np.float32(depth_map)
distance_scale = 255.0 / camera_range
depth_map = distance_scale * depth_map
depth_map = np.uint8(depth_map)
depth_map = cv.applyColorMap(depth_map, cv.COLORMAP_RAINBOW)
Combine depth and IR for more accurate results
result = cv.addWeighted(ir_map, 0.4, depth_map, 0.6, 0)
Start the computations for object detection using DNN
blob = cv.dnn.blobFromImage(result, inScaleFactor, (inWidth, inHeight),
(meanVal, meanVal, meanVal), swapRB)
net.setInput(blob)
detections = net.forward()
。。. for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence 》 thr:
class_id = int(detections[0, 0, i, 1])
。。. if class_id in classNames:
value_x = int(center[0])
value_y = int(center[1])
label = classNames[class_id] + “: ” +
“{0:.3f}”.format(distance_map[value_x, value_y] / 1000.0 * 0.3) + “ ” +
“meters”
。。. # Show image with object detection
cv.namedWindow(WINDOW_NAME, cv.WINDOW_AUTOSIZE)
cv.imshow(WINDOW_NAME, result)
Show Depth map
cv.namedWindow(WINDOW_NAME_DEPTH, cv.WINDOW_AUTOSIZE)
cv.imshow(WINDOW_NAME_DEPTH, depth_map)
清单 1:摘自 Analog Devices 的 3D ToF SDK 发行版中示例应用程序的代码片段,展示了获取深度和 IR
图像并通过推理模型进行分类所需的几个步骤。(代码来源:Analog Devices)
该过程首先使用 OpenCV 的 DNN 方法 (cv.dnn.readNetFromCaffe) 读取现有推理模型的网络和相关权重。本例中的模型是Google MobileNet Single Shot Detector (SSD) 检测网络的 Caffe实现,该网络以使用相对较小的模型大小实现高精度而闻名。在使用支持的类标识符和类标签加载类名称之后,该示例应用程序识别可用的相机并执行一系列初始化例程(未显示在清单1 中)。
示例代码的大部分内容是准备深度图 (depth_map) 和 IR 图 (ir_map),然后将其 (cv.addWeighted)合并成单个数组以提高精度。最后,代码调用另一个 OpenCV DNN 方法 (cv.dnn.blobFromImage),该方法将合并的图像转换为推理所需的四维blob 数据类型。下一行代码将得到的 blob 设置为推理模型的输入 (net.setInput(blob))。对 net.forward()的调用将激活返回分类结果的推理模型。示例应用程序的其余部分识别超过预设阈值的分类结果,并为这些结果生成标签和边框,来显示捕获的图像数据、由推理模型识别的标签及其与相机的距离(图 8)。

正如 Analog Devices 的 DNN 示例应用程序所示,开发人员可以结合使用 3D ToF深度图与机器学习方法,来创建更复杂的应用功能。虽然要求低延迟响应的应用程序更有可能使用 C/C++ 来构建这些功能,但基本步骤是一样的。
通过使用 3D ToF数据和高性能推理模型,工业机器人系统可以更安全地将其动作与其他设备同步,甚至在人与机器人紧密协作的“协作机器人”环境中与人同步。借助不同的推理模型,另一个应用程序可以使用高分辨率3D ToF 相机,对手势界面涉及的精细动作进行分类。在汽车应用中,这种方法可以帮助提高高级辅助驾驶系统 (ADAS) 的精度,同时能充分利用 3D ToF系统提供的高时空分辨率。
总结
在几乎所有依赖系统与其他物体之间距离精确测量的系统中,ToF 技术都起着关键作用。在诸多 ToF 技术中,光学 3D ToF可以同时提供高空间分辨率和高时间分辨率,因而能够更精细地区分更小的物体,并对其相对距离进行更精确的监测。
但是,要利用这项技术,开发人员需要应对与这些系统的光学设计、精确定时和同步信号采集相关的多种挑战。如本文所述,诸如 Analog Devices 的AD-96TOF1-EBZ 开发平台和 ESPROS Photonics 的 EPC660 评估套件之类预置 3D ToF系统的推出,消除了将该技术应用于工业系统、手势界面、汽车安全系统等领域的上述障碍。
-
CCD
+关注
关注
32文章
907浏览量
149922 -
接收器
+关注
关注
15文章
2655浏览量
77661 -
3D
+关注
关注
9文章
3031浏览量
115785 -
TOF
+关注
关注
9文章
551浏览量
38696 -
视频成像
+关注
关注
0文章
3浏览量
6343
发布评论请先 登录
高精度3D飞行时间,让物理世界在数字空间清晰可见

Voxel 3D 飞行时间传感器机器人视觉参考设计
3D模拟飞机飞行串口
3D成像:飞行时间法(ToF)可望推动CMOS图像传感器的发展
采用3D飞行时间传感器控制汽车内部的摄像系统
苹果在iPad上首次应用AR/VR 或将搭载3D飞行时间后部传感器
松下飞行时间图像传感器能获取最远200米3D信息
3D飞行时间技术在深度测量和物体检测领域中发挥着重要作用
ADI和Microsoft为3D成像启用飞行时间技术
飞行时间系统设计的应用概述
Hydra3D+飞行时间传感器,打造新一代3D视觉系统






评论