 英伟达江郎才尽,下一代芯片架构变化只是封装
英伟达江郎才尽,下一代芯片架构变化只是封装

2023年8月23日,英伟达宣布下一代汽车芯片Thor量产时间略有推迟,正式量产在2026财年,英伟达的财政年度与自然年相差11个月,也就是说正式量产最迟可能是2026年1月。
FY2019-FY2024H1英伟达自动驾驶及AI座舱业绩情况
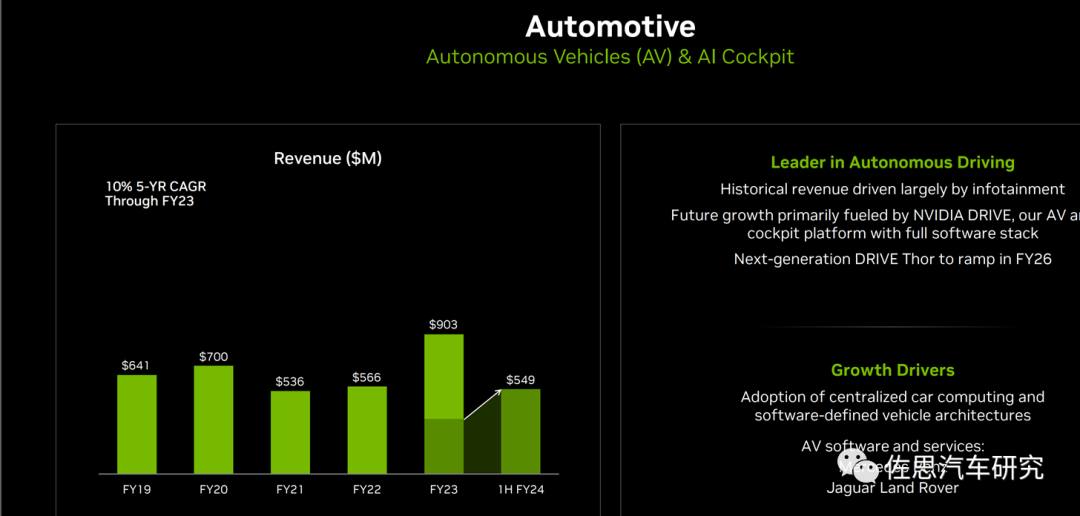
图片来源:英伟达
英伟达通常两年升级一次芯片架构。在2022年英伟达透露即将在2024年推出Blackwell架构,而Thor也会采用Blackwell架构。
Blackwell是致敬美国统计学家,加利福尼亚大学伯克利分校统计学名誉教授,拉奥-布莱克韦尔定理的提出者之一David Harold Blackwell。
英伟达Blackwell架构
Blackwell架构将采用COPA-GPU设计。很多人认为COPA-GPU就是Chiplet,不过COPA-GPU不是严格意义上的Chiplet,众所周知,英伟达一直对Chiplet缺乏兴趣。在2017年英伟达曾提出非常近似Chiplet的MCM设计,但在2021年12月,英伟达发表了一篇名为《GPU Domain Specialization via Composable On-Package Architecture》的论文,应该就是Blackwell架构的论文,这篇论文则否定了Chiplet设计。
2017年6月英伟达发表论文《MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability》提出了MCM设计。
MCM-GPU设计
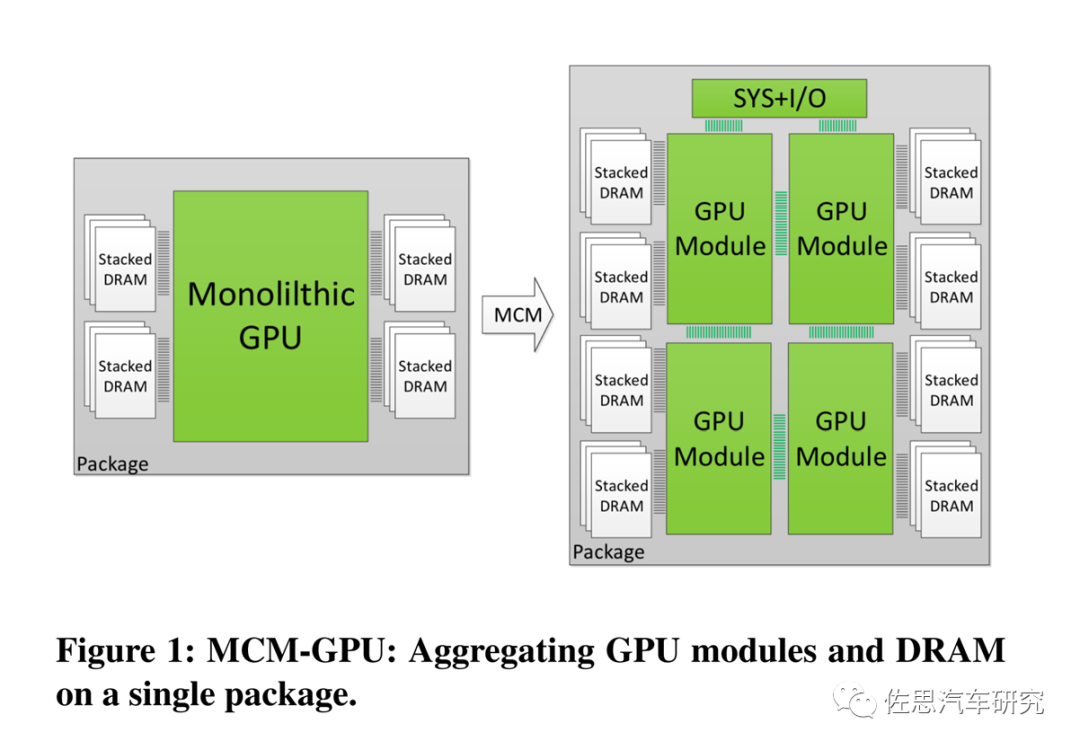
图片来源:英伟达
MCM-GPU设计基本就是现在比较火爆的Chiplet设计,但英伟达一直未将MCM付诸实际设计中。英伟达一直坚持Monolithic单一光刻设计,这是因为die与die之间通讯带宽永远无法和monolithic内部的通讯带宽相比,换句话说Chiplet不适合高AI算力场合,在纯CPU领域是Chiplet的最佳应用领域。
MCM-GPU架构
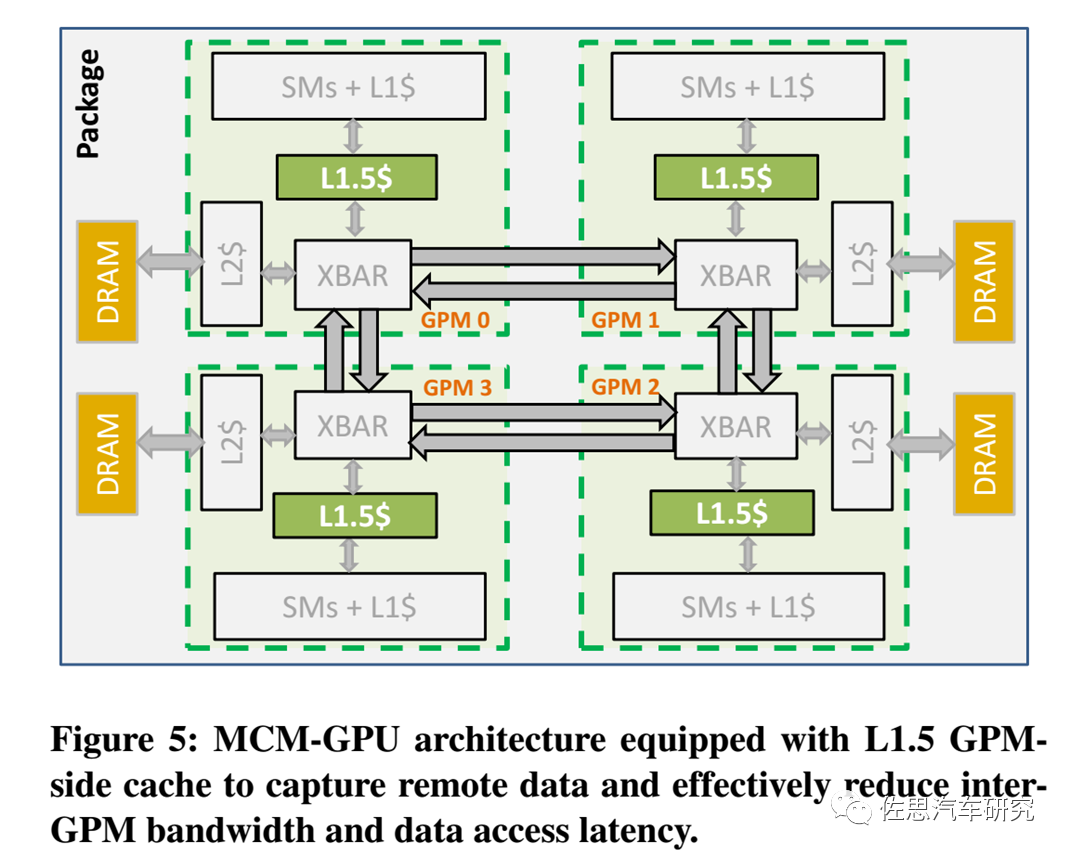
图片来源:英伟达
英伟达2017年论文提及的MCM-GPU架构如上图。英伟达在MCM-GPU架构里主要引入了L1.5缓存,它介于L1缓存和L2缓存之间,XBAR是Crossbar,英伟达的解释是The Crossbar (XBAR) is responsible for carrying packets from a given source unit to a specific destination unit,有点像交换或路由。GPM就是GPU模块。
不同容量L1.5缓存下各种应用的速度对比
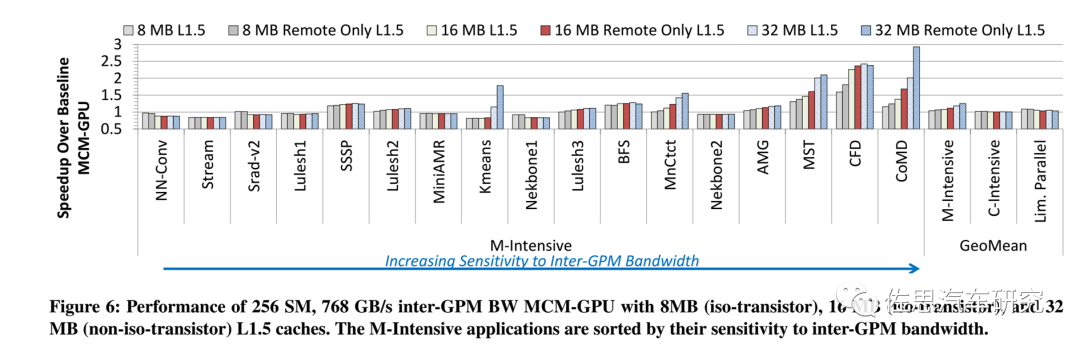
图片来源:英伟达
上图是英伟达2017年论文仿真不同容量L1.5缓存下各种应用的速度对比,不过彼时各种应用还是各种浮点数学运算和存储密集型算子,而非深度学习。
Transformer时代相对CNN时代,存储密集型算子所占比例大幅增加。
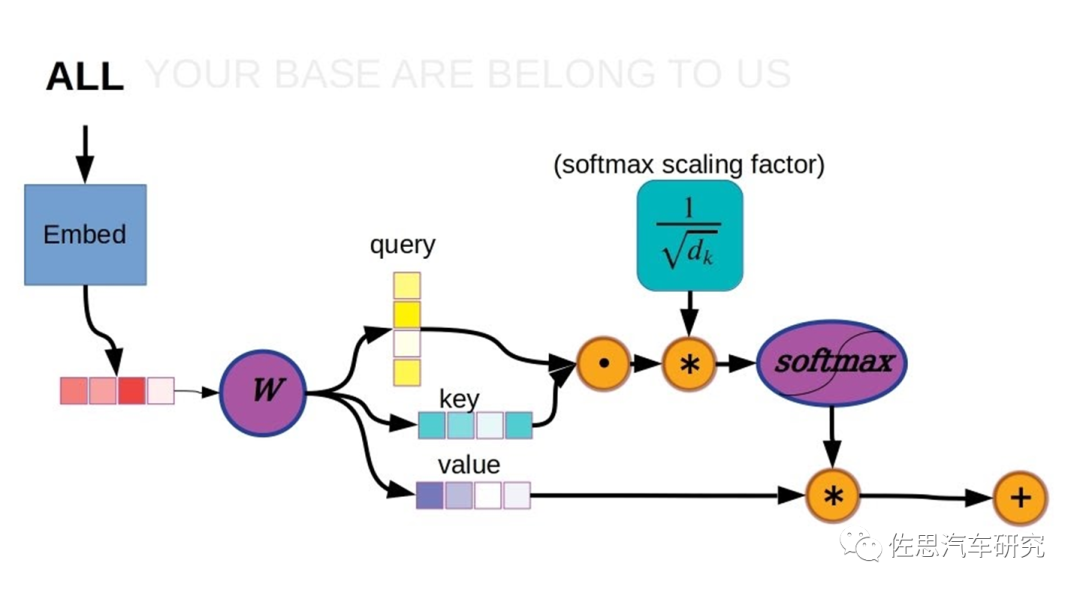
以上是Transformer的计算过程,在此计算过程中,矩阵乘法是典型的计算密集型算子,也叫GEMM(通用矩阵乘法)。存储密集型算子分两种,一种是矢量或张量的神经激活,多非线性运算,也叫GEMV (通用矩阵矢量乘法)。另一种是逐点元素型element-wise,典型的如矩阵反转,实际没有任何运算,只是存储行列对调。
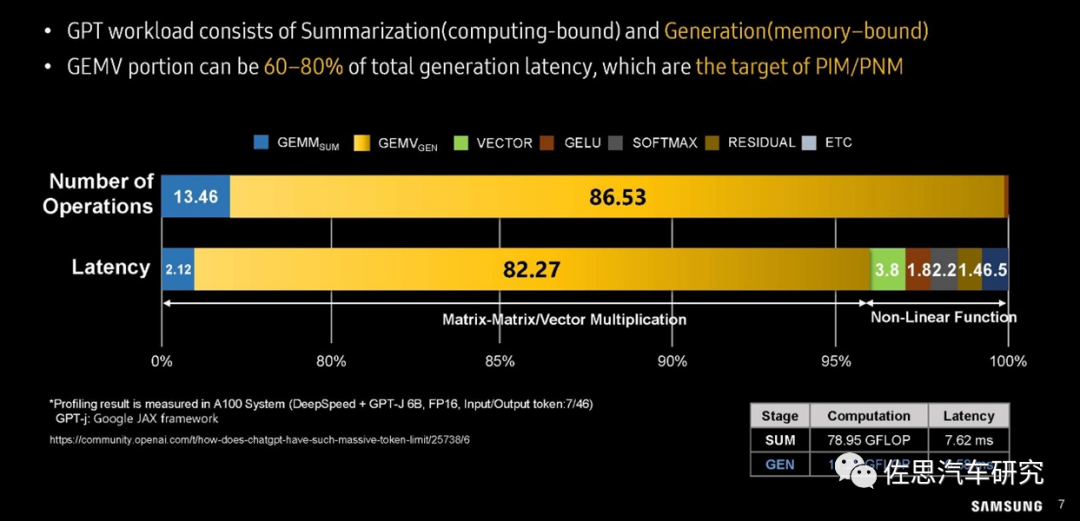
图片来源:三星
上图中,在运算操作数量上,GEMV所占比例高达86.53%,在大模型运算延迟分析上,82.27%的延迟都来自GEMV;GEMM占比只有2.12%;非线性运算也就是神经元激活部分占的比例也远高于GEMM。
三星对GPU利用率的分析
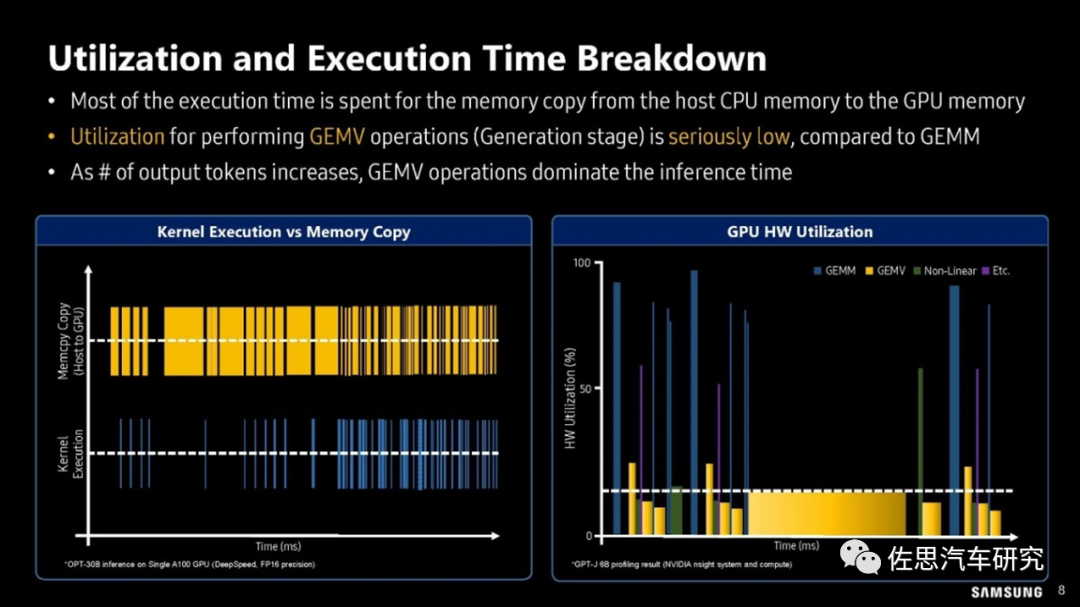
图片来源:三星
上图可以看出在GEMV算子时,GPU的利用率很低,一般不超过20%,换句话说80%的时间GPU都是在等待存储数据的搬运。GPU的灵活性还是比较高的,如果换做灵活性比较差的AI专用加速器,如谷歌的TPU,那么GEMV的利用率会更低,不到10%甚至5%。
三星的GPT瓶颈分析
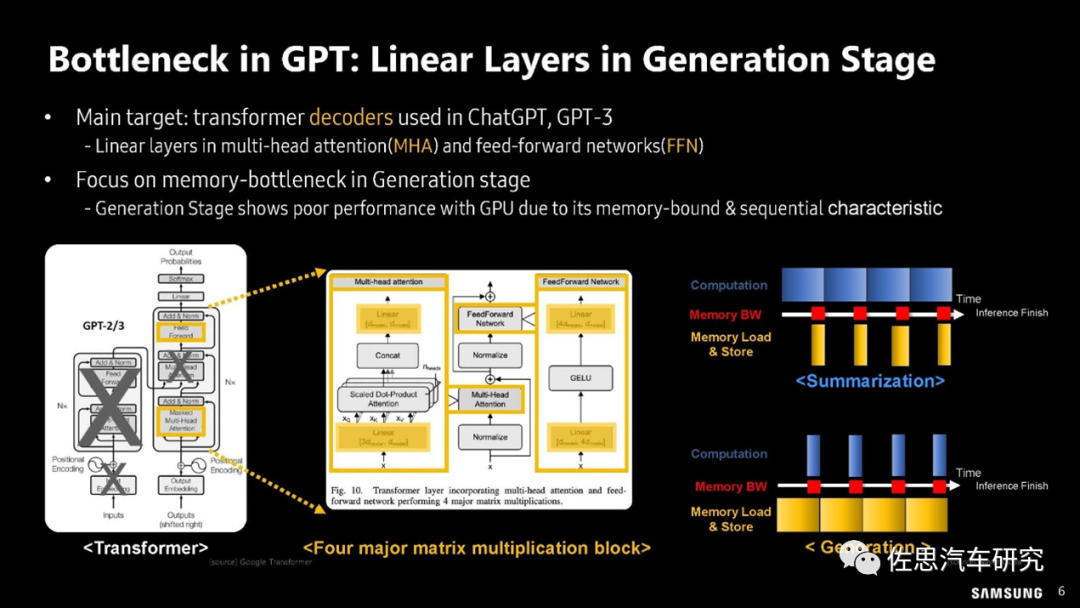
图片来源:三星
Roof-line访存与算力模型
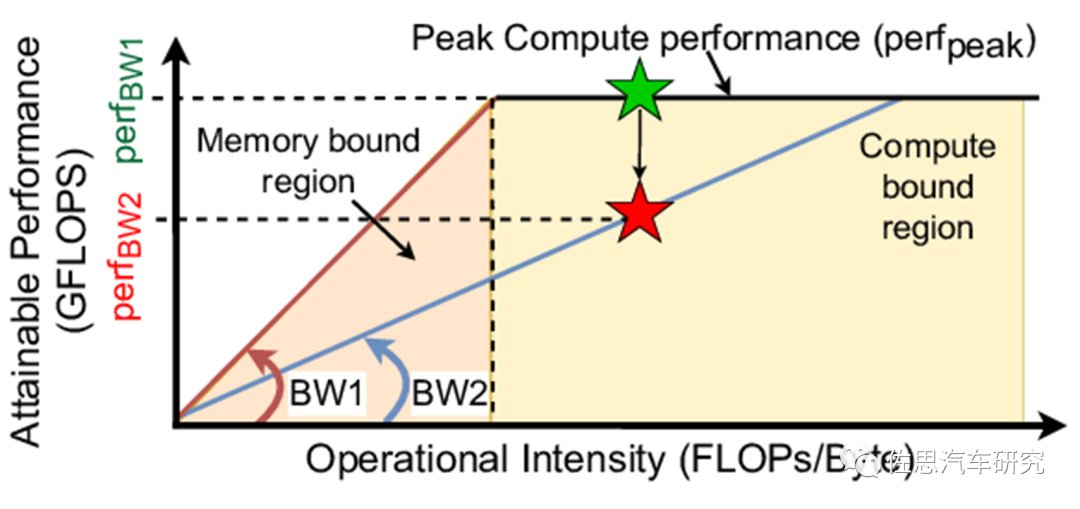
图片来源:互联网
上图是鼎鼎大名的roof-line访存与算力模型。
COPA-GPU架构
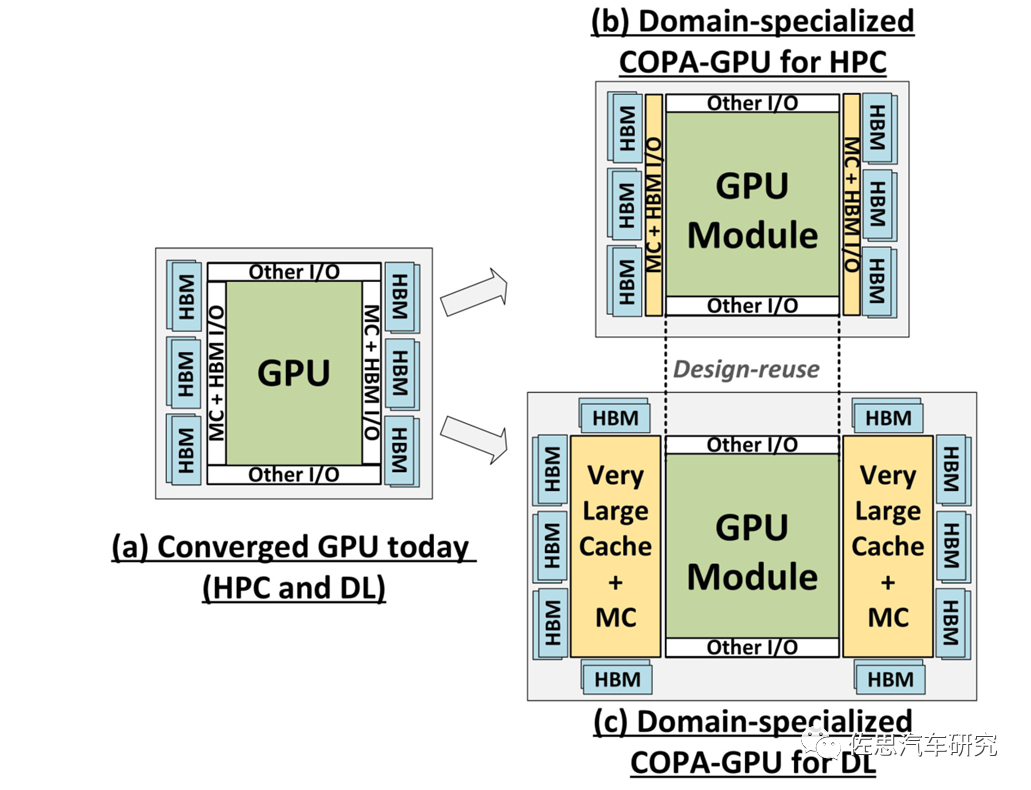
图片来源:英伟达
上图是2021年12月英伟达论文提出的COPA-GPU架构,实际就是把一个特别大容量的L2缓存die分离出来。因为如果还是monolithic设计,那么整个die的面积会超过1000平方毫米,不过***决定了芯片的最大die size不超过880平方毫米,所以必须将L2分离。
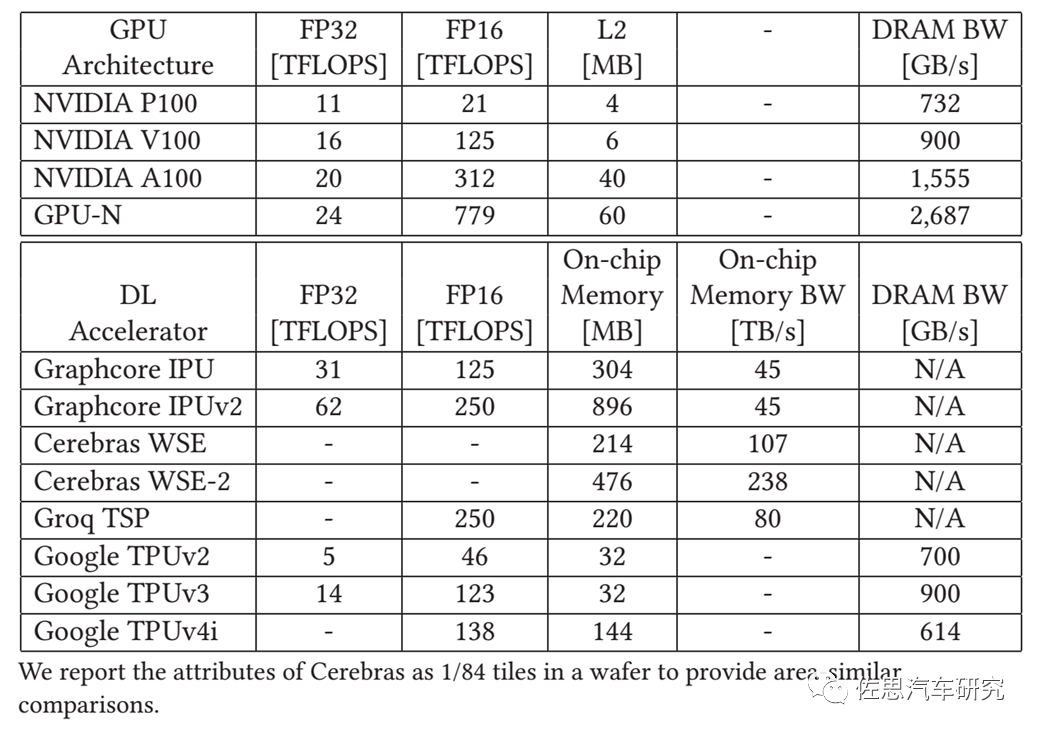
注:GPU-N就是英伟达的COPA-GPU。
图片来源:英伟达
不同容量L2缓存对应的延迟
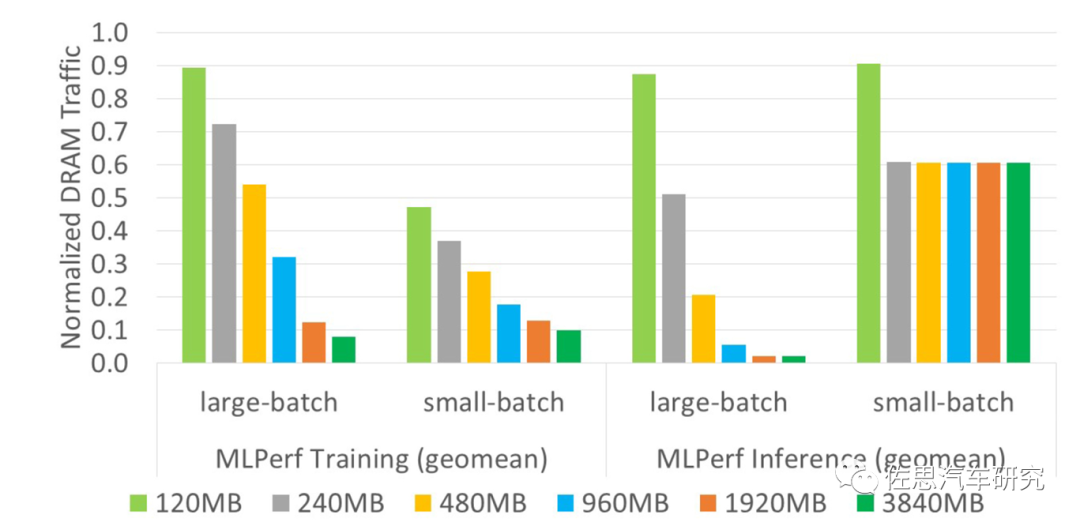
图片来源:英伟达
上图是不同容量L2缓存对应的延迟情况,显然L2缓存越高,延迟越低,不过在small-batch时不明显。
几种COPA-GPU的封装分析
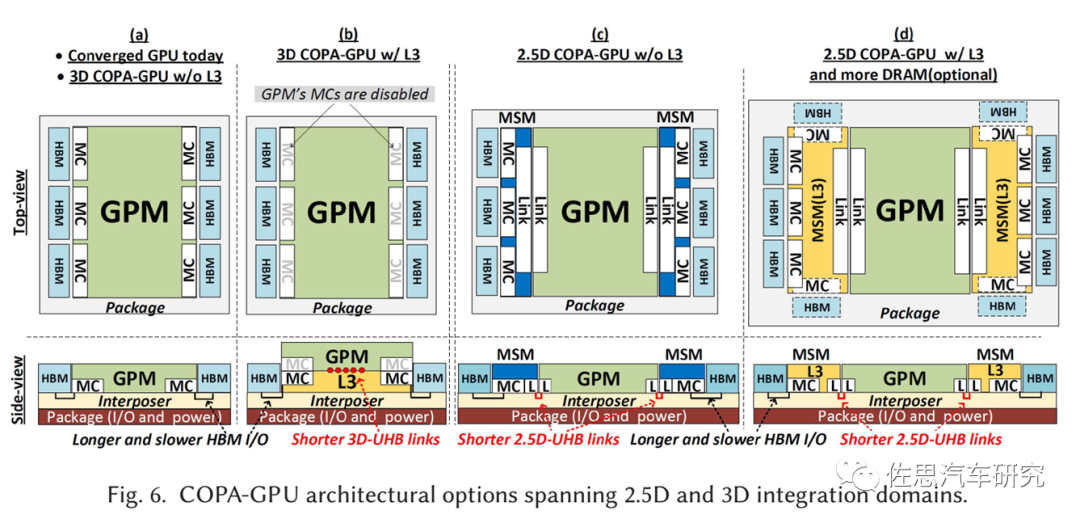
图片来源:英伟达
从英伟达的论文里我们看不到架构方面的丝毫改进,只有封装领域的改变。这篇论文实际应该由台积电来写,因为英伟达完全无法掌控芯片的封测工艺,CoWoS就是为英伟达这种设计而设计的,而CoWoS诞生在10年以前。
大模型不断消耗更多的算力和存储,这显然违背了自然界效率至上的原则,或许人类正在错误的道路上狂奔。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
-
gpu
+关注
关注
28文章
5283浏览量
136093 -
芯片架构
+关注
关注
1文章
33浏览量
14904 -
英伟达
+关注
关注
23文章
4116浏览量
99645
原文标题:英伟达江郎才尽,下一代芯片架构变化只是封装
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
FT 5000 Smart Transceiver:下一代智能网络芯片的卓越之选
伟创力携手博通,推进下一代AI液冷解决方案落地

面向下一代GPU VPD架构的供电系统超低压大电流测试方案 —— 费思N系列电子负载技术解析与应用实践

华为在MWC 2026正式发布下一代WAN目标网架构

罗姆面向下一代800 VDC架构发布电源解决方案白皮书
Microchip推出下一代Switchtec Gen 6 PCIe交换芯片
Telechips与Arm合作开发下一代IVI芯片Dolphin7
英伟达下一代Rubin芯片已流片
适用于下一代 GGE 和 HSPA 手机的多模/多频段 PAM skyworksinc

安森美携手英伟达推动下一代AI数据中心发展
驱动下一代E/E架构的神经脉络进化—10BASE-T1S

下一代高速芯片晶体管解制造问题解决了!
下一代PX5 RTOS具有哪些优势
NVIDIA 采用纳微半导体开发新一代数据中心电源架构 800V HVDC 方案,赋能下一代AI兆瓦级算力需求



评论