 NeurIPS 2023 | 扩散模型解决多任务强化学习问题
NeurIPS 2023 | 扩散模型解决多任务强化学习问题

扩散模型(diffusion model)在 CV 领域甚至 NLP 领域都已经有了令人印象深刻的表现。最近的一些工作开始将 diffusion model 用于强化学习(RL)中来解决序列决策问题,它们主要利用 diffusion model 来建模分布复杂的轨迹或提高策略的表达性。
但是, 这些工作仍然局限于单一任务单一数据集,无法得到能同时解决多种任务的通用智能体。那么,diffusion model 能否解决多任务强化学习问题呢?我们最近提出的一篇新工作——“Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning”,旨在解决这个问题并希望启发后续通用决策智能的研究:

论文链接:
https://arxiv.org/abs/2305.18459

背景
数据驱动的大模型在 CV 和 NLP 领域已经获得巨大成功,我们认为这背后源于模型的强表达性和数据集的多样性和广泛性。基于此,我们将最近出圈的生成式扩散模型(diffusion model)扩展到多任务强化学习领域(multi-task reinforcement learning),利用 large-scale 的离线多任务数据集训练得到通用智能体。 目前解决多任务强化学习的工作大多基于 Transformer 架构,它们通常对模型的规模,数据集的质量都有很高的要求,这对于实际训练来说是代价高昂的。基于 TD-learning 的强化学习方法则常常面临 distribution-shift 的挑战,在多任务数据集下这个问题尤甚,而我们将序列决策过程建模成条件式生成问题(conditional generative process),通过最大化 likelihood 来学习,有效避免了 distribution shift 的问题。

方法
具体来说,我们发现 diffusion model 不仅能很好地输出 action 进行实时决策,同样能够建模完整的(s,a,r,s')的 transition 来生成数据进行数据增强提升强化学习策略的性能,具体框架如图所示:
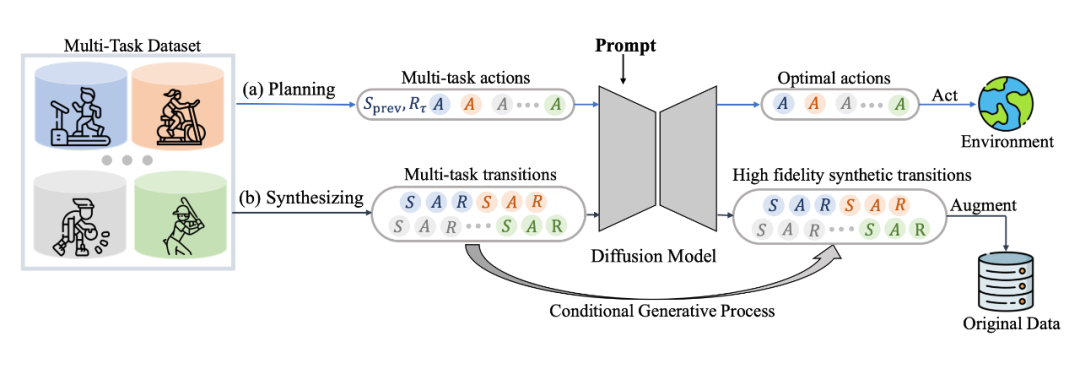
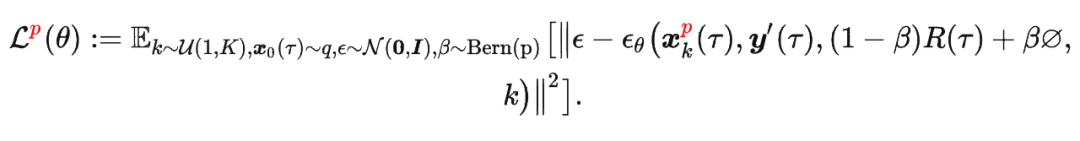 其中
其中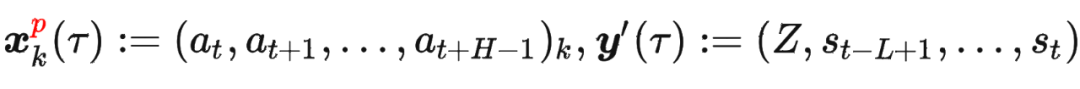 是轨迹的标准化累积回报, 是 Demonstration Prompt,可以表示为:
是轨迹的标准化累积回报, 是 Demonstration Prompt,可以表示为:

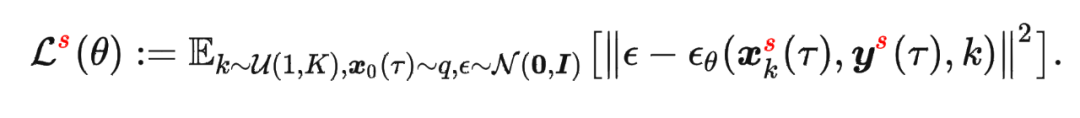 其中
其中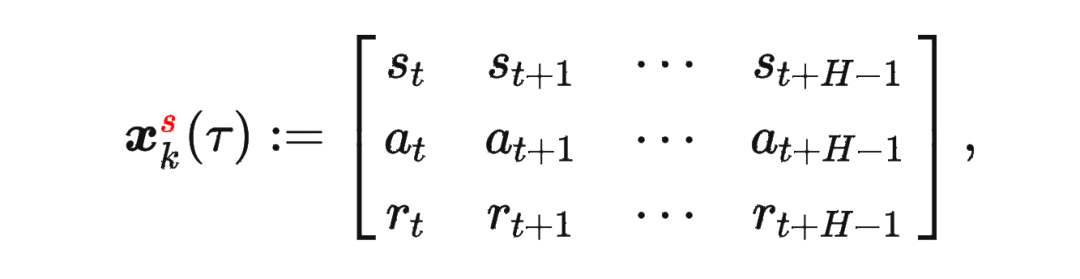
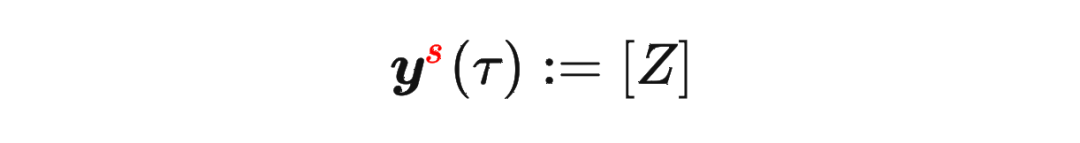

模型结构
为了更好地建模多任务数据,并且统一多样化的输入数据,我们用 transformer 架构替换了传统的 U-Net 网络,网络结构图如下:
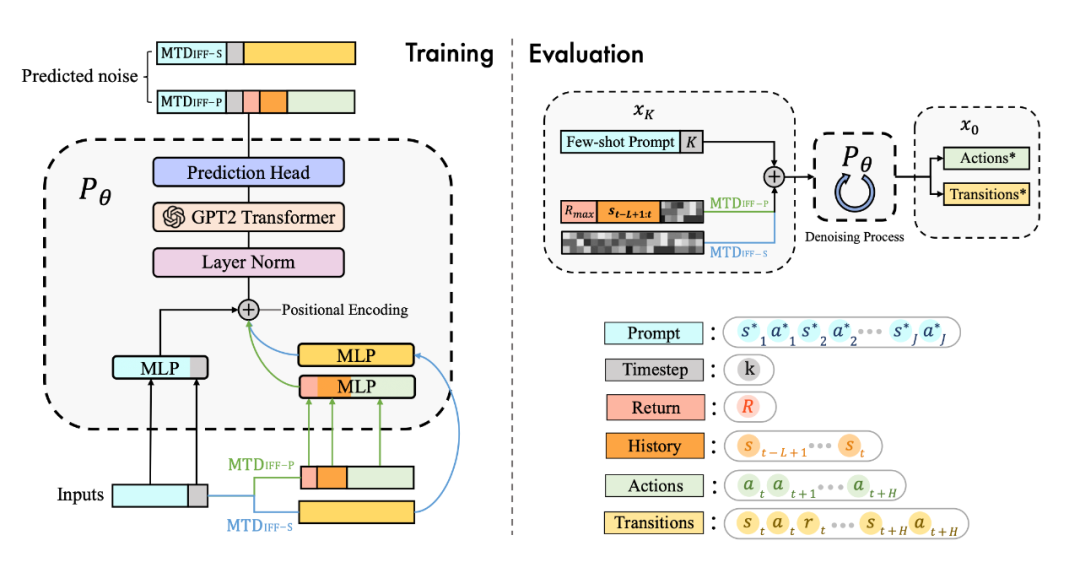

实验
我们首先在 Meta-World MT50 上开展实验并与 baselines 进行比较,我们在两种数据集上进行实验,分别是包含大量专家数据,从 SAC-single-agent 中的 replay buffer 中收集到的 Near-optimal data(100M);以及从 Near-optimal data 中降采样得到基本不包含专家数据的 Sub-optimal data(50M)。实验结果如下:
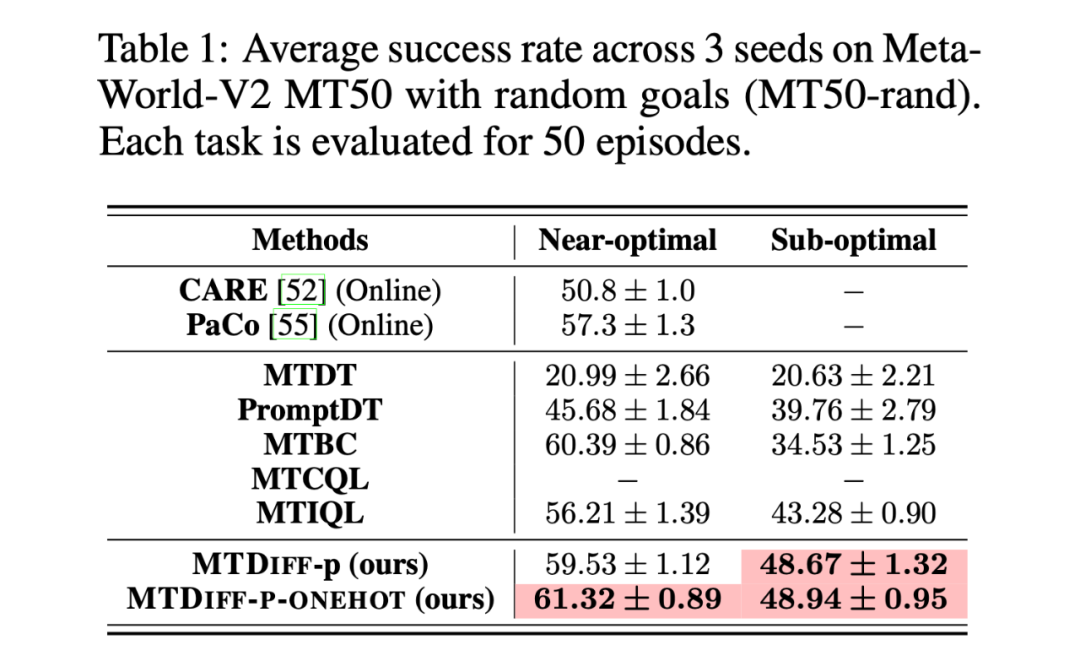
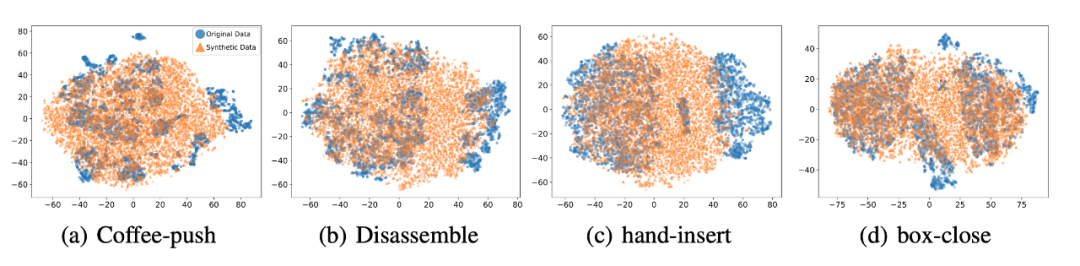
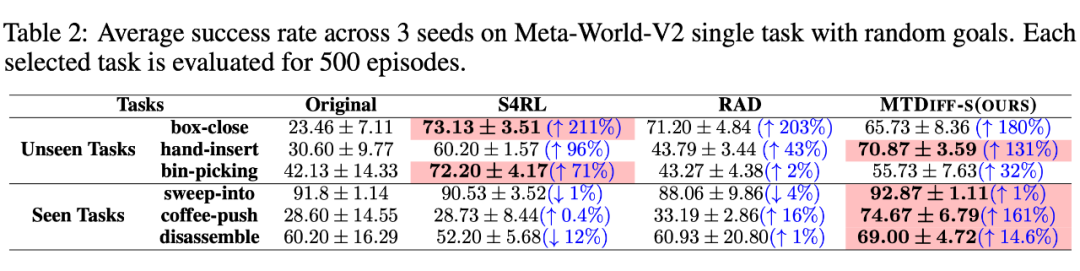 我们选取 45 个任务的 Near-optimal data 训练 ,从表中我们可以观察到在 见过的任务上,我们的方法均取得了最好的性能。甚至给定一段 demonstration prompt, 能泛化到没见过的任务上并取得较好的表现。我们选取四个任务对原数据和 生成的数据做 T-SNE 可视化分析,发现我们生成的数据的分布基本匹配原数据分布,并且在不偏离的基础上扩展了分布,使数据覆盖更加全面。
我们选取 45 个任务的 Near-optimal data 训练 ,从表中我们可以观察到在 见过的任务上,我们的方法均取得了最好的性能。甚至给定一段 demonstration prompt, 能泛化到没见过的任务上并取得较好的表现。我们选取四个任务对原数据和 生成的数据做 T-SNE 可视化分析,发现我们生成的数据的分布基本匹配原数据分布,并且在不偏离的基础上扩展了分布,使数据覆盖更加全面。

总结
我们提出了一种基于扩散模型(diffusion model)的一种新的、通用性强的多任务强化学习解决方案,它不仅可以通过单个模型高效完成多任务决策,而且可以对原数据集进行增强,从而提升各种离线算法的性能。我们未来将把 迁移到更加多样、更加通用的场景,旨在深入挖掘其出色的生成能力和数据建模能力,解决更加困难的任务。同时,我们会将 迁移到真实控制场景,并尝试优化其推理速度以适应某些需要高频控制的任务。
原文标题:NeurIPS 2023 | 扩散模型解决多任务强化学习问题
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2951文章
48242浏览量
419474
原文标题:NeurIPS 2023 | 扩散模型解决多任务强化学习问题
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
在阿里云PAI平台的机器人感知强化学习规模化实践
物理 AI 正在迅速从基础运动控制迈向更复杂的环境理解。传统机器人强化学习(RL)长期依赖本体感知(proprioception),包括关节角度、力矩反馈和内部状态,来训练灵巧的运动技能。

Momenta R7强化学习世界模型实现量产首发
等话题展开深度对话,正式宣布Momenta R7强化学习世界模型实现量产首发,标志着智能驾驶从“看见世界”到“理解世界”的全新跨越,物理AI正式从技术理念走向规模化量产落地。
Momenta R7强化学习世界模型助力上汽大众ID. ERA 9X正式上市
2026年4月25日,上汽大众全新旗舰SUV ID. ERA 9X于2026北京国际汽车展览会期间正式上市,并将全球首发搭载Momenta R7强化学习世界模型。这意味着Momenta R7率先在全球强化学习+世界
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
近日,上汽奥迪宣布旗下 E5 Sportback 车型升级搭载 全新Momenta 强化学习大模型。
上汽大众ID. ERA 9X全球首发搭载Momenta R7强化学习世界模型
3月30日,Momenta R7强化学习世界模型全球首发搭载车型——上汽大众ID. ERA 9X正式开启预售。
Momenta R6强化学习大模型上车东风日产NX8
3月20日,东风日产NX8技术暨预售发布会在广州举办,官宣Momenta R6强化学习大模型正式上车东风日产新能源SUV——NX8。以全球顶级大厂合力,融合先锋科技力量,打造更适配全家出行的智能SUV,开启合资品牌智能化全新赛道。
Momenta强化学习大模型助力别克至境世家纯电版正式上市
3月17日,别克至境世家纯电版正式上市,这是别克与Momenta强化学习大模型的又一次深度联手。融合别克在MPV市场深耕27年的技术积淀,以更从容的智慧驾控,重新定义豪华与自在的出行体验。
Momenta R7强化学习世界模型即将推出
3月16日,上汽大众举办以“人本科技”为主题的ID. ERA技术发布会,首次揭晓了ID. ERA 系列包括智能辅助驾驶在内的诸多核心技术亮点。会上,Momenta CEO曹旭东正式宣布:Momenta R7强化学习世界模型即将推出,并将全球首发搭载于上汽大众全新旗舰SUV
自动驾驶中常提的离线强化学习是什么?
[首发于智驾最前沿微信公众号]在之前谈及自动驾驶模型学习时,详细聊过强化学习的作用,由于强化学习能让大模型通过交互学到策略,不需要固定的规则

强化学习会让自动驾驶模型学习更快吗?
[首发于智驾最前沿微信公众号]在谈及自动驾驶大模型训练时,有的技术方案会采用模仿学习,而有些会采用强化学习。同样作为大模型的训练方式,强化学习

多智能体强化学习(MARL)核心概念与算法概览
训练单个RL智能体的过程非常简单,那么我们现在换一个场景,同时训练五个智能体,而且每个都有自己的目标、只能看到部分信息,还能互相帮忙。这就是多智能体强化学习

上汽别克至境E7首发搭载Momenta R6强化学习大模型
别克至境家族迎来新成员——大五座智能SUV别克至境E7首发。新车将搭载Momenta R6强化学习大模型,带来全场景的智能出行体验。
今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
智元推出真机强化学习,机器人训练周期从“数周”减至“数十分钟” 近日,智元机器人宣布其研发的真机强化学习技术,已在与龙旗科技合作的验证产线中成功落地。据介绍,此次落地的真机强化学习方案,机器人
发表于 11-05 09:44
•1199次阅读
自动驾驶中常提的“强化学习”是个啥?
[首发于智驾最前沿微信公众号]在谈及自动驾驶时,有些方案中会提到“强化学习(Reinforcement Learning,简称RL)”,强化学习是一类让机器通过试错来学会做决策的技术。简单理解




评论