 为什么GPU获得了如此多的缓存?
为什么GPU获得了如此多的缓存?
不久之前,如果您想要一个内置大量缓存的处理器,那么 CPU 是显而易见的选择。现在,即使是预算级 GPU 也比几年前的高端 CPU 配备了更多的内存。
那么,什么改变了呢?为什么图形芯片突然需要比通用中央处理器更多的缓存?两者之间的专用内存是否不同?我们将来会看到 GPU 拥有千兆字节的缓存吗?
为了回答这些问题,我们需要深入了解最新芯片的内部结构,观察这些年来的变化。
TL;DR:为什么 GPU 获得了如此多的缓存?
由于 GPU 现在不仅用于图形,还用于各种应用程序,因此低级数据缓存的大小不断增大。为了提高通用计算能力,图形芯片需要更大的缓存。这确保没有数学核心闲置等待数据。
末级缓存已大幅扩展,以抵消 DRAM 性能未能跟上处理器性能进步的事实。大量的 L2 或 L3 高速缓存可减少高速缓存未命中。这还可以防止内核闲置,并最大限度地减少对非常宽的内存总线的需求。
此外,渲染技术(尤其是光线追踪)的进步对 GPU 的缓存层次结构提出了巨大的要求。大型末级缓存对于确保使用这些技术时的游戏性能保持可玩性至关重要。
缓存课程 101
要全面讨论缓存这个话题,我们首先必须了解缓存是什么以及它的意义。所有处理器都需要内存来存储它们处理的数字和计算结果。他们还需要有关任务的具体说明,例如要执行哪些计算。这些指令以数字方式存储和传送。
这种存储器通常称为 RAM(随机存取存储器)。每个带有处理器的电子设备都配备有 RAM。几十年来,PC 一直采用DRAM(“D”代表动态)作为数据的临时存储,而磁盘驱动器作为长期存储。
自发明以来,DRAM 已经取得了巨大的进步,随着时间的推移,速度呈指数级增长。数据存储也是如此,曾经占据主导地位但速度缓慢的硬盘正在被快速的固态存储 (SSD)所取代。然而,尽管取得了这些进步,与基本处理器执行单个计算的速度相比,这两种类型的内存仍然慢得要命。
即使是一组 DDR5-8200 也不够快
虽然芯片可以在几纳秒内将两个数字相加,但检索这些值或存储结果可能需要数百到数千纳秒——即使使用最快的可用 RAM。如果没有办法解决这个问题,那么 PC 也不会比 20 世纪 70 年代的 PC 好多少,尽管它们的时钟速度要高得多。
值得庆幸的是,SRAM(静态 RAM)可以弥补这一差距。SRAM 由与执行计算的处理器中的晶体管相同的晶体管制成。这意味着 SRAM 可以直接集成到芯片中并以芯片的速度运行。它靠近逻辑单元,将数据检索或存储时间缩短至数十纳秒。
这样做的缺点是,即使单个存储位所需的晶体管的布置以及其他必要的电路也会占用相当大的空间。使用当前的制造技术,64 MB SRAM 的大小大致相当于 2 GB DRAM。
AMD Zen 4 小芯片的大部分是缓存(红色 + 黄色框)。
这就是为什么现代处理器整合了各种 SRAM 块——有些很小,仅包含几个位,而另一些则包含几个 MB。这些较大的块绕过了 DRAM 的缓慢问题,显着提高了芯片性能。
这些内存类型根据其用途有不同的名称,但最流行的称为“缓存”。这就是讨论变得有点复杂的地方。
为等级制度欢呼
处理器核心内的逻辑单元通常处理小数据。它们接收的指令和处理的数字很少大于 64 位。因此,存储这些值的最小 SRAM 块的大小相似,称为“寄存器”。
为了确保这些单元不会停止等待下一组命令或数据,芯片通常会预取这些信息并保留频繁发出的信息。该数据存储在两个不同的 SRAM 组中,通常称为 1 级指令缓存和 1 级数据缓存。顾名思义,每个都有其保存的特定类型的数据。尽管它们很重要,但它们的范围并不广泛。例如,AMD 最近的桌面处理器为每个处理器分配 32 kB。
虽然不是很大,但这些缓存足以容纳大量命令和数据,确保内核不会闲置。然而,为了维持这种数据流,必须持续提供缓存。当核心需要 1 级缓存 (L1) 中不存在的特定值时,L2 缓存就变得至关重要。
L2 缓存是一个更大的块,存储各种数据。请记住,单个内核具有多个逻辑单元线。如果没有 L2,L1 缓存很快就会被淹没。现代处理器具有多个内核,因此需要引入另一个为所有内核提供服务的缓存层:三级 (L3) 缓存。它的范围甚至更广,跨越了几个 MB。从历史上看,某些 CPU 甚至具有第四级。
英特尔 Raptor Lake CPU 之一的单个 P 核的图像。淡蓝色的各种网格点缀在结构周围,是寄存器和各种缓存的混合体。您可以在此网站上查看每个部分的更详细细分。然而,本质上,L1 缓存位于核心的中央,而 L2 则占据右侧部分。
处理器中的最后一级缓存通常充当来自系统 DRAM 的任何数据在继续传输之前的第一个调用端口,但情况并非总是如此。这是关于缓存的部分,往往会变得非常复杂,但这对于理解为什么 CPU 和 GPU 具有截然不同的缓存安排也至关重要。
SRAM 块的整个系统的使用方式被称为芯片的缓存层次结构,它的变化很大,具体取决于架构的年龄和芯片的目标扇区等因素。但对于CPU来说,有一些方面总是相同的,其中之一就是层次结构的连贯性。
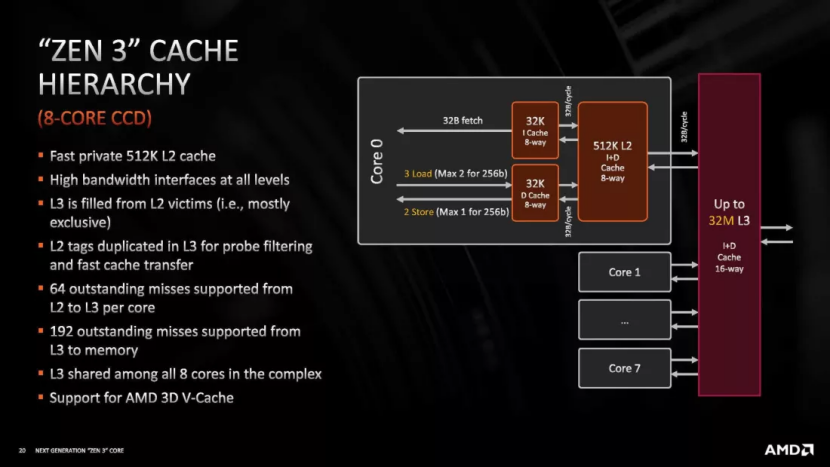
高速缓存中的数据可以从系统的 DRAM 复制。如果某个核心对其进行修改,则必须同时更新 DRAM 版本。因此,CPU缓存结构具有确保数据准确性和及时更新的机制。这种复杂的设计增加了复杂性,在处理器领域,复杂性转化为晶体管,进而转化为空间。
这就是为什么前几级缓存不是很大的原因 — 不仅因为 SRAM 非常宽敞,还因为需要所有其他系统来保持其一致性。然而,并不是每个处理器都需要这个,并且有一种非常特定的类型通常完全避开它。
GPU 的方式:核心优先于缓存
今天的图形芯片,从内部结构和功能来看,形成于2007年。当时Nvidia和ATI都发布了统一着色器GPU,但对于后者来说,真正的变化发生在5年后。
2012 年,AMD(当时已收购ATI)推出了下一代图形核心(GCN) 架构。这种设计至今仍在使用,尽管它已经经历了重大修改并演变成RDNA和 CDNA 等形式。我们将参考 GCN 来阐明 CPU 和 GPU 之间的缓存差异,因为它提供了一个清晰的示例。
跳到 2017 年,让我们将 AMD 的Ryzen 7 1800X CPU(上图)与 Radeon RX Vega 64 GPU进行对比。前者有8个核心,每个核心包含8条管道。其中四个管道处理标准数学运算,两个专门用于广泛的浮点计算,最后两个负责数据管理。其缓存层次结构如下:64 kB L1 指令、32 kB L1 数据、512 kB L2 和 16 MB L3。
Vega 64 GPU 具有 4 个处理块。每个块都包含 64 个管道,通常称为计算单元 (CU)。此外,每个CU可容纳四组16个逻辑单元。每个 CU 都拥有 16 kB 的 L1 数据缓存和 64 kB 的暂存存储器,本质上充当没有一致性机制的缓存(AMD 将其标记为本地数据共享)。
此外,还有两个高速缓存(16 kB L1 指令和 32 kB L1 数据)可满足四个 CU 组的需要。Vega GPU 还拥有 4 MB 二级缓存,位于两个带中,一个位于底部,另一个位于下图顶部附近。
该特定图形处理器的芯片面积是 Ryzen 芯片尺寸的两倍。然而,它的缓存占用的空间比CPU中的要小得多。与 CPU 相比,为什么该 GPU 保持最小的缓存,特别是在 L2 段方面?
鉴于其“核心”数量明显高于 Ryzen 芯片,人们可能会预计,总共有 4096 个数学单元,因此需要大量缓存来维持稳定的数据供应。然而,CPU 和 GPU 工作负载有根本的不同。
虽然 Ryzen 芯片可以同时管理多达 16 个线程并处理 16 个不同的命令,但 Vega 处理器可能会处理更多数量的线程,但其 CU 通常执行相同的指令。
此外,每个 CU 内的数学单元在一个周期内同步执行相同的计算。这种一致性将它们归类为 SIMT(单指令、多线程)设备。GPU 按顺序运行,很少偏离其他处理路线。
相比之下,CPU 处理各种指令,同时确保数据一致性。相反,GPU 重复执行类似的任务,消除了数据一致性的需要并不断重新启动其操作。
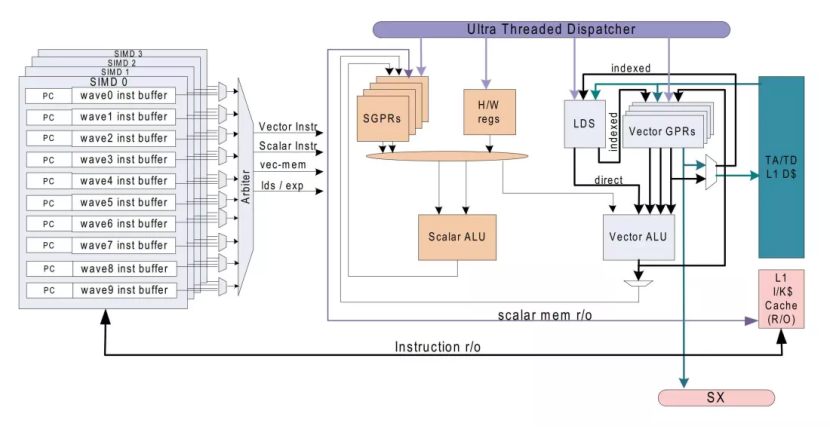
GCN计算单元的内部结构。很简单,是吗?
由于渲染 3D 图形的任务主要由重复的数学运算组成,因此 GPU 不需要像 CPU 那样复杂。相反,GPU 被设计为大规模并行,可同时处理数千个数据点。这就是为什么与中央处理器相比,它们的缓存较小,但内核数量却多得多。
然而,如果是这样的话,为什么 AMD 和 Nvidia 的最新显卡拥有大量缓存,甚至是廉价型号?Radeon RX 7600只有 2 MB 的 L2,但也有 32 MB 的 L3;Nvidia 的GeForce RTX 4060没有 L3,但它配备了 24 MB L2。
当谈到他们的光环产品时,数字是巨大的——GeForce RTX 4090拥有 72 MB 的 L2,而Radeon RX 6800 / 6900卡中的 AMD Navi 21 芯片则拥有 128 MB 的 L3!
这里有很多东西需要解开——例如,为什么 AMD 在这么长时间内保持如此小的缓存,然后突然增加它们的大小并投入大量的 L3 以达到良好的效果?
为什么 Nvidia 将 L1 大小增加这么多,但将 L2 保持相对较小,只是为了复制 AMD 并让 L2 缓存疯狂?
GPU 中的 G不再只是图形
这种转变的原因有很多,但对于 Nvidia 来说,这种转变是由 GPU 使用方式的变化推动的。尽管它们被称为图形处理单元,但这些芯片的用途不仅仅是在屏幕上显示令人印象深刻的图像。
虽然绝大多数 GPU 都擅长此功能,但这些芯片已经超越了渲染的范围。他们现在处理多个学科的数据处理和科学算法中的数学负载,包括工程、物理、化学、生物学、医学、经济学和地理学。原因?因为他们非常擅长同时对数千个数据点进行相同的计算。
尽管 CPU 也可以执行此功能,但对于某些任务,单个 GPU 的效率可以与多个中央处理器一样高效。随着 Nvidia 的 GPU 向通用化发展,芯片内逻辑单元的数量及其运行速度都呈指数级增长。
Nvidia 第一个用于严肃通用计算的“显卡”——2007 年的 Tesla C870
Nvidia 在 2007 年首次涉足严肃的通用计算领域,以 Tesla C870 为标志。该卡的架构在其缓存层次结构中只有两级(技术上可以争论为 2.5,但让我们回避这一争论),确保了 L1 缓存足够广泛,可以持续向所有单位提供数据。更快的 VRAM 支持了这一点。二级缓存的大小也有所增加,尽管与我们现在看到的情况完全不同。
Nvidia 的第一批统一着色器 GPU只需要 16 kB 的 L1 数据(以及少量的指令和其他值),但在几年内就跃升至 64 kB。对于过去的两种架构,GeForce 芯片具有 128 kB L1,其服务器级处理器甚至更多。
第一批芯片中的 L1 缓存只需服务 10 个逻辑单元(8 个通用 + 2 个特殊功能)。当Pascal 架构出现时(与 AMD 的 RX Vega 64 大致同一时代),缓存已增长至 96 kB,可容纳 150 多个逻辑单元。
当然,该缓存从 L2 获取数据,并且随着这些单元的簇数量随着每一代的增加而增加,L2 缓存的数量也随之增加。然而,自 2012 年以来,每个逻辑集群(更广为人知的流式多处理器,SM)的 L2 数量一直保持相对不变,约为 70 到 130 MB。当然,最新的 Ada Lovelace 架构是个例外,我们稍后会回到这个架构。
多年来,AMD 的重点主要集中在 CPU 上,而图形部门在人员配置和预算方面相对较小。不过,作为基本设计,GCN 运行得非常好,在 PC、游戏机、笔记本电脑、工作站和服务器中找到了应用。
虽然AMD的图形处理器可能并不总是人们能买到的最快的,但它已经足够好了,而且这些芯片的缓存结构似乎不需要认真更新。但是,尽管 CPU 和 GPU 飞速发展,但事实证明,还有另一个难题很难改进。
DRAM进展缓慢
GCN 的后继者是 2019 年的 RDNA 架构,AMD 重新调整了一切,以便他们的新 GPU 使用三级缓存,同时仍然保持相对较小的规模。然后,在其后续RDNA 2 设计中,AMD 利用其在 CPU 缓存工程方面的专业知识将第四级缓存硬塞到芯片中,该缓存比之前 GPU 中看到的任何缓存都要大得多。
但为什么要做出这样的改变,特别是当这些芯片主要用于游戏并且 GCN 缓存多年来只进行了最小的修改时?
原因很简单:
芯片尺寸和复杂性:
虽然合并更多缓存级别确实使芯片设计复杂化,但它可以防止芯片变得过大。更小的芯片意味着可以从单个硅晶圆中提取更多的单元,从而使生产更具成本效益。
内存速度与处理器速度
多年来,处理器速度一直在持续增长,但 DRAM 却未能跟上这一步伐。例如,在 Radeon RX Vega 64 中,AMD 利用高带宽内存 (HBM) 来提高 VRAM 和 GPU 之间的数据传输速率。这些模块显示在主 GPU 芯片左侧上方,本质上是堆叠在一起的多个 DRAM 芯片,有助于每个周期读取或写入更多数据。然而,HBM 非常昂贵。理想情况下,显卡应具有充足的内存、大量的总线,并且全部都以高速运行。但由于 DRAM 的结构,其性能无法提升到与 CPU 或 GPU 相匹配。
当计算所需的数据不存在于缓存中时(通常称为“缓存未命中”),必须从 VRAM 中获取数据。由于此过程比从缓存中检索速度慢,因此等待 DRAM 中存储的数据只会导致需要数据的线程停滞。即使使用现代图形芯片,这种情况也经常发生。
这种情况实际上一直在发生,即使使用最新的图形芯片,但随着它们变得越来越强大,缓存未命中正在成为高分辨率下的一个重要性能限制。
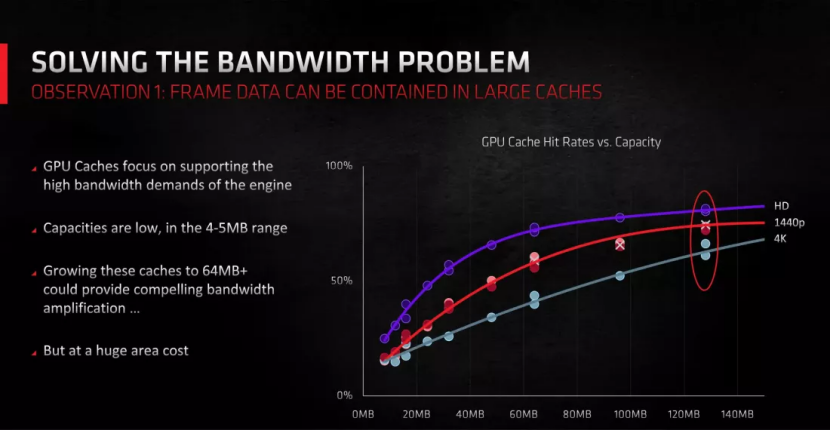
在 GPU 中,最后一级缓存的结构使得每个 VRAM 模块的接口都有其专用的 SRAM 片。其余处理器利用交叉连接系统来访问任何模块。通过 GCN 和首次 RDNA 设计,AMD 通常采用 256 或 512 kB L3 切片。但在 RDNA 2 中,每片的大小激增至 16 至 32 MB,令人印象深刻。
这一调整不仅大幅减少了 DRAM 读取引起的线程延迟,还减少了对超宽内存总线的需求。更宽的总线需要更广阔的 GPU 芯片周长来容纳所有内存接口。
虽然由于固有的长延迟,大量缓存可能会很麻烦且缓慢,但 AMD 的设计却恰恰相反——庞大的 L3 缓存使 RDNA 2 芯片的性能与拥有更宽内存总线的性能相当,同时将芯片尺寸保持在低于控制。
Nvidia 紧随其后,推出了最新一代的 Ada Lovelace,出于同样的原因,之前的 Ampere 设计在其最大的消费级 GPU 中的最大二级缓存大小为 6 MB,但在新设计中显着增加。完整的 AD102 芯片(RTX 4090 中使用的是其精简版本)包含 96 MB 的二级缓存。
至于为什么他们不只是采用另一级缓存并将其做得非常大,可能是因为在这一领域没有与 AMD 相同水平的专业知识,或者可能不想看起来像是直接复制该公司。当人们查看芯片时,如上所示,无论如何,所有二级缓存实际上并没有占用芯片上的太多空间。
除了通用GPU计算的兴起外,还有一个原因导致末级缓存现在这么大,这与渲染领域的最新热门话题:光线追踪有关。
大图形需要大数据
无需过多介绍该过程的细节,最新游戏中使用的光线追踪行为涉及执行看似相当简单的算法 - 从 3D 世界中相机的位置画一条线,通过帧的一个像素,并追踪其在空间中的路径。当它与一个对象交互时,检查它是什么以及它是否可见,然后从那里计算出像素的颜色。
事情远不止这些,但这是基本过程。光线追踪要求如此高的原因之一是对象检查。计算出光线所到达的物体的所有细节是一项艰巨的任务,因此为了帮助加快例程,使用了一种称为包围体层次结构(简称 BVH)的东西。
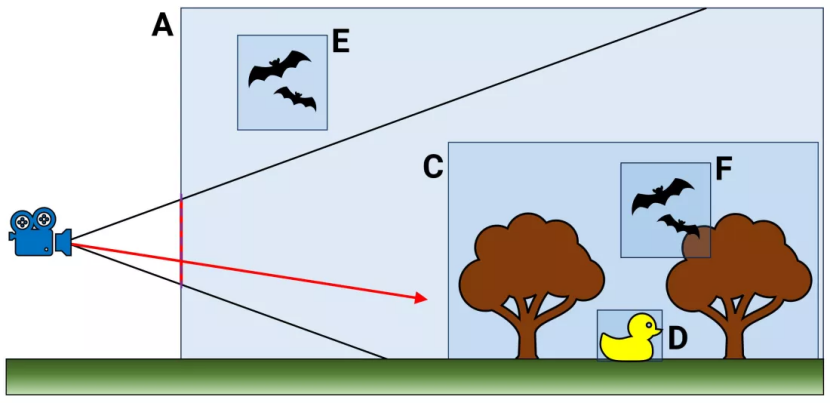
可以将其视为 3D 场景中使用的所有对象的大型数据库 - 每个条目不仅提供有关结构是什么的信息,还提供有关其与其他对象的关系的信息。以上面(极其简单化)的例子为例。
层次结构的顶部从体积 A 开始。其他所有内容都包含在其中,但请注意,体积 E 位于体积 C 之外,后者本身包含 D 和 F。当光线投射到此场景中时(红色箭头),遍历层次结构时会发生一个过程,检查光线路径经过的体积。
然而,BVH像树一样排列,遍历只需沿着检查结果命中的分支进行。因此,体积 E 可以立即被拒绝,因为它不是射线显然会穿过的 C 的一部分。当然,现代游戏中 BVH 的实际情况要复杂得多。
我们拍摄了《赛博朋克 2077》的快照,暂停了游戏的渲染中帧,向您展示如何通过增加三角形层来构建任何一个给定场景。
现在,尝试想象从您的眼睛开始追踪一条线,穿过监视器中的一个像素,然后尝试准确确定哪个三角形将与光线相交。这就是为什么 BVH 的使用如此重要,并且它大大加快了整个过程。
在这个特定的游戏中,与许多采用光线追踪来照亮整个场景的游戏一样,BVH 包含两种类型的多个数据库:顶级加速结构 (TLAS) 和底层加速结构 (BLAS)。
前者本质上是对整个世界的大概览,而不仅仅是我们所看到的很小的一部分。在使用 Nvidia 显卡的 PC 上,它看起来像这样:
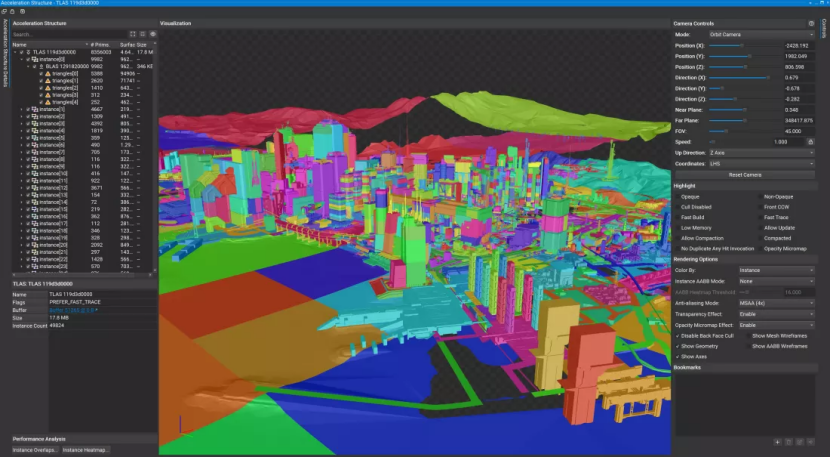
我们稍微放大了一些,以便向您展示其中包含的一些细节,但正如您所看到的,它非常大 — 大小几乎为 18 MB。请注意该列表是实例之一,并且每个实例都包含至少一个 BLAS。游戏只使用了两个 TLAS 结构(第二个要小得多),但总共有数千个 BLAS。
下面的衣服是世界上看到的角色可能穿着的一件衣服。拥有这么多可能看起来很荒谬,但这种层次结构意味着如果这个特定的 BLAS 不在光线路径中的更大父结构中,则它永远不会在渲染的着色阶段被检查或使用。

对于我们的《赛博朋克 2077》快照,总共使用了 11,360 个 BLAS,占用的内存比 TLAS 多得多。然而,由于 GPU 现在拥有大量缓存,因此有足够的空间将后者存储在该 SRAM 中,并从 VRAM 传输许多相关的 BLAS,从而使光线追踪过程变得更快。
所谓的渲染圣杯实际上仍然只有那些拥有最好显卡的人才能获得,即便如此,也需要采用额外的技术(例如图像升级和帧生成)来将整体性能带入可玩的领域。
BVH、数千个核心和 GPU 中的专用光线追踪单元使这一切成为可能,但巨大的缓存为这一切提供了急需的推动力。
皇冠的竞争者
一旦几代 GPU 架构过去,拥有大量 L2 或 L3 缓存的图形芯片将成为常态,而不是新设计的独特卖点。GPU将继续在广泛的通用场景中使用,光线追踪将在游戏中变得越来越普遍,而DRAM仍将落后于处理器技术的发展。
话虽如此,当涉及到 SRAM 中时,GPU 并不会完全满足要求。事实上,现在有一些例外。
我们不是在谈论 AMD 的 X3D 系列 Ryzen CPU,尽管Ryzen 9 7950X3D配备了惊人的 128 MB L3 缓存(英特尔最大的消费级 CPU Core i9-13900K仅 36 MB)。不过,它仍然是 AMD 产品,特别是 EPYC 9000 系列服务器处理器中的最新产品。
售价 14,756 美元的 EPYC 9684X由 13 个小芯片组成,其中 12 个小芯片容纳处理器的核心和缓存。每个芯片都包含 8 个核心和一个 64 MB 的 AMD 3D V 缓存片,位于小芯片的内置 32 MB L3 缓存之上。总而言之,末级缓存总计达到 1152 MB,令人难以置信!即使是 16 核版本(9174F)也拥有 256 MB 内存,尽管它仍然不是你所说的便宜,价格为 3,840 美元。
当然,此类处理器并不是为普通人及其游戏电脑而设计的,而且其物理尺寸、价格标签和功耗数据都非常大,我们不会在普通处理器中看到类似的处理器。台式电脑使用多年。
部分原因是,与用于逻辑单元的半导体电路不同,随着每个新工艺节点(芯片的制造方法)缩小 SRAM 变得越来越困难。AMD 的 EPYC 处理器拥有如此多的缓存,仅仅是因为散热器下方有很多芯片。
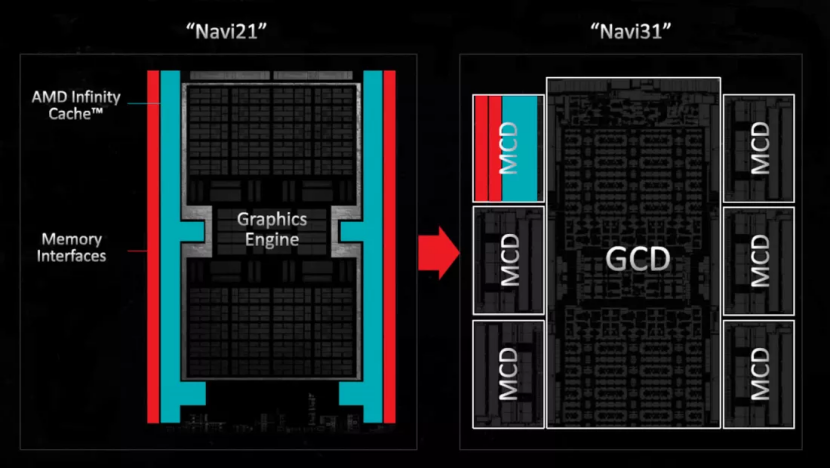
所有 GPU 在未来的某个时候可能都会走类似的路线,AMD 的高端 Radeon 9000 型号已经这样做了,内存接口和相关的 L3 缓存片被安置在与主处理芯片不同的小芯片中。
不过,使用更大的缓存会带来收益递减,因此不要指望 GPU 到处都有千兆字节的缓存。但即便如此,最近的变化还是相当引人注目的。
二十年前,图形芯片中的缓存非常少,只有几 kB 的 SRAM。现在,您可以花不到 400 美元购买一张具有如此大缓存的显卡,您可以将整个原始 Doom 放入其中 - 两倍!
GPU 确实是缓存之王。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19078浏览量
228725 -
DRAM
+关注
关注
40文章
2297浏览量
183189 -
晶体管
+关注
关注
77文章
9598浏览量
137604 -
SSD
+关注
关注
20文章
2829浏览量
117086 -
随机存取存储器
+关注
关注
0文章
44浏览量
8948
原文标题:为什么GPU是新的缓存之王?
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片GPU
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
国产GPU厂商砺算科技获3.28亿元融资
X Square获得1050万美元A轮融资
CPU渲染和GPU渲染优劣分析

为什么GPU对AI如此重要?
广和通获得UL Solutions WTDP目击实验室资质
NVLink技术之GPU与GPU的通信

这届CES展会上获得了创新奖的工业AR产品长什么样?

如何选择合适的本地缓存?
mybatis一级缓存和二级缓存的原理
盘点那些强大又低调的Java缓存





 工商网监
工商网监
评论