 pipeline高端玩法—看下FlushNext的用法
pipeline高端玩法—看下FlushNext的用法
看完了flush,再看下flushNext的用法
》flushNext
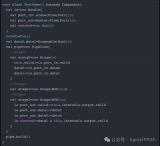
在Stage里,有关flushNext提供的API有:
defflushNext():Unit = flushNext(ConditionalContext.isTrue)
defflushNext(cond : Bool):Unit = internals.request.flushNext += cond
调用flushNext,最终会将flushNext的需求暂存到internals.request.flushNext中。
在Pipeline中,propagateRequirements函数中对于每一级Stage的处理:
varflushNext = stage.internals.request.flushNext.nonEmpty generate orR(stage.internals.request.flushNext)
如果flushNext不为空,则将所有条件或后得到flushNext电路对象。

在上面的这段描述中,针对驱动当前Stage的Conntection处理,flushNext电路将会被存储在clFlushNext(l)中。如果flushNext不为空(line:5),可以看到在line7:9行处理时,不管flush是存在,都会创建一个flush电路对象,也就意味着一般情况下flush,flushNext不需要同时使用。
而在line11:14中,以M2S为例,alwasContainsSlaveToken为True,会将flushNext清空。此时在line16:17时,仅会对驱动当前Stage的Stage Master调动flushIt函数,也就意味着flushNext将会向前传播,前级相当于执行flushIt。
clFlushNext的使用仅在Connection中使用到。还是以M2S为例,其处理逻辑为:
if(flushNext != null&& !flushPreserveInput) s.valid clearWhen(flushNext && s.ready)
在这里,如果flushNext不为空(flushPreserveInput默认为true),s.valid仅会在slave端ready和flushNext同时为高时才会清零。对比flush操作:
if (flush!= null&& !flushPreserveInput) s.valid clearWhen(flush)
也就意味着flushNext存在ready的情况下才具有意义。
》example
结合上面的分析,flushNext与flush的最大区别在于存在ready传播的情况。这里先给出一个flsuhIt的例子: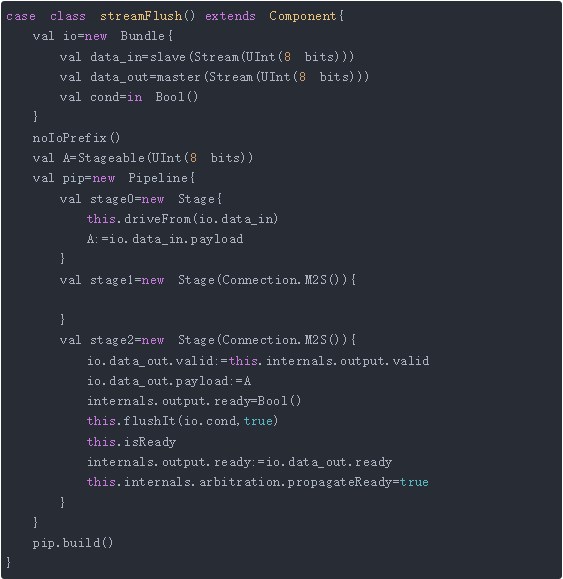
这里是一个三级pipeline,最后一级调用flushIt操作,flushRoot参数传递为true。
采用下面的仿真代码:
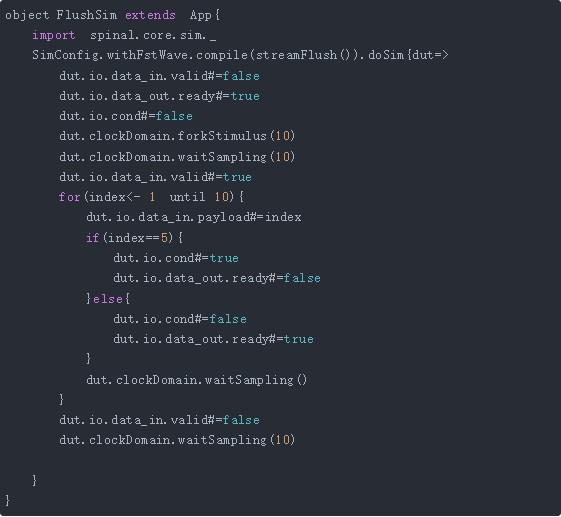
我们这里在index==5时将cond拉高一拍,data_out.ready拉低一拍。
仿真波形如下:

可以看到,由于这里流水线为3级,在index=5时执行flush数据3,4,5不会从data_out有效输出。
将flushRoot参数修改为false:

cond为高时data_out.valid仍然为高电平,下一个时钟周期拉低。虽然此时ready为低电平,这个数据没有被消耗,但其拉低时间不考虑ready信号的高低电平。
再将上面的代码换成flushNext:

可以看到,虽然cond为高,但其仍会坚持将此时已经传播到stage2的3给稳定传输出去,仅有4,5不会被data_out输出。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19461浏览量
231421 -
仿真器
+关注
关注
14文章
1019浏览量
83984 -
Pipeline
+关注
关注
0文章
28浏览量
9392
原文标题:pipeline高端玩法(八)—FlushNext
文章出处:【微信号:Spinal FPGA,微信公众号:Spinal FPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
总结一下STM32串口的用法
Pipeline ADCs Come of Age
Pipeline ADCs Come of Age
流水线模数转换器的时代-Pipeline ADCs Come
如何降低开发门槛助力音视频创新玩法
修改V4L2的Video Pipeline的devicetree
Ping命令的7个基础用法
SpinalHDL里pipeline的设计思路


pipeline高端玩法—优先级介绍
什么是pipeline?Go中构建流数据pipeline的技术
浅析SpinalHDL中Pipeline中的复位定制





 工商网监
工商网监
评论