 计算机视觉走向何方?参会ICCV的一些感想
计算机视觉走向何方?参会ICCV的一些感想
ICCV结束了。对我来说,这次的highlight就是第一天下午的"Quo vadis, computer vision“ workshop。“Quo vadis"是拉丁语,意思是“我们去向何方“。
四年前的CVPR,也有过一场类似的workshop(Computer Vision After 5 Years),今年这次workshop,主办方也让四年前也在的大佬们回顾了自己当年的predictions,看看谁是大预言家(spoiler: Jitendra Malik)。这场 workshop是我这几年来参加的各种会议里最有意思的。可惜因为听的太投入,并没有很多的图片记录,现在我意识到似乎主办方并不会上传slides。所以这篇文章里我就简单谈谈我自己的一些感想,而不是记录这个会议。
Ignorance or faith on LLM?
今年最火的莫过于LLM。LLM的成功刺激了很多相关的vision research。然而许多的vision-language的研究其实都是基于一种对LLM的faith,而并没有在深入思考这一切的合理性。David Forsyth问道:why would anyone believe that:
Visual knowledge is the same as linguistic knowledge
You can describe the world of an image properly in words
LLMs can do vision (anything)? if you ask nicely.
深入来看,这其实是一个关于vision和language区别的问题。但其实在我看来这些问题都很奇怪,可能因为我自己也觉得这些想法都很absurd。对我来说,更有意思的问题可能是:vision systems的什么knowledge是LLM做不了的,我们又该怎么做?在这里提一个idea,不知道未来有没有机会去好好做:我们有没有可能对稠密的vision空间进行一个approximate decomposition,分解成几个子空间的积?(其中一个子空间就可以是离散的language空间)
Data over algorithms
这个主题是我非常认同的。四年前,我写过一篇文章(Andre:思考无标注数据的可用极限),提出的也是我们要重视数据的研究,而不是算法的研究。今天依然适用。Alyosha Efros这次也再次强调了这个方向的本质性。
需要解释的是,什么是"data research"。并不是说直接去做数据集才是data research,而是说从data层面开始思考模型的有效性,learning process,generalization ability,等等。从这个角度讲,从data中学习知识 (self-supervised learning)是data research,研究如何克服data shift的影响(OOD, open-world)当然也是data research,这里不再赘述了。
Video与视觉大模型
这个主题是今年开始进入我的视野的。年初随着stable diffusion, segment anything model的出现,我们不少人开始思考视觉大模型该是什么形态,我与组里不少同学聊天后的感受就是要做video。在五月份的ICLR时,我与Ben Poole还有3DGP的作者也交流了不少(顺带表示ICLR的参会体验比ICCV好太多了),感受就是现在3D问题大概就是两个思路:1. 希望随着depth camera的引入,会有更多海量的3D data,直接训出3D大模型;2. 希望video大模型直接绕开explicit 3D modeling的需求,建成vision大模型。这次ICCV另一个MMFM上,Vincent Sitzman也提出了一个类似的思路,但是他直接把video和3d modeling结合了起来(然而我并没有特别跟上他讲的东西,希望之后talk能有slides让我再学习学习)。
讲了上面这么多,我就是想说video很可能是我们走向视觉大模型的路。这次quo vadis workshop上,Jitendra的分享主要也是指出video的重要性。他指出:video有两个用处:
Exteroception:建立对外部世界的认识。We build mental models of behavior (physical, social ...) and use them to interpret, predict, and control
Proprioception:建立对自己的认识。Helps produce an episodic memory situated in space and time, and guides action in a context-specific way。
他还给出了一个对video的思考框架,短video对应了movement/physical action,长video对应了goal/intention,而一个完整的action就是movement + goal。
当然,这些都是比较高屋建瓴的观点了。但对于我们这些正在地上爬的人当然还是有好处的。(另外,Jitendra还认为token-based LLM可能不是最终的模型,因为它不能很好地capture 4D world,同时complexity也太高)。
Embodied AI?
最后,可能大家从上面一段论述中也已经能感觉出来了,许多大佬们正把embodied AI作为一个最终的目标。Antonio Torralba给了一个很有意思的talk,说我们是时候要返璞归真,从focus on performance on benchmarks回到"the original goal"。对他来说,这个goal就是embodied AI。有意思的是, Antonio提出的设想是 small network, big sensing,他称作embodied perception。他举了个例子:人光光味蕾上的传感器就比我们现在最先进的机器人身上全部的传感器要多。然而就在第二天的BRAVO workshop上,Wayve的Jamie Shotton给出了完全相反的框架:lightweight sensors + big model。考虑到传感器的价格,Jamie的想法可能现在这个时候是更合适的。不过也许最终Antonio的想法才最make sense。

Antonio的小模型,大感知
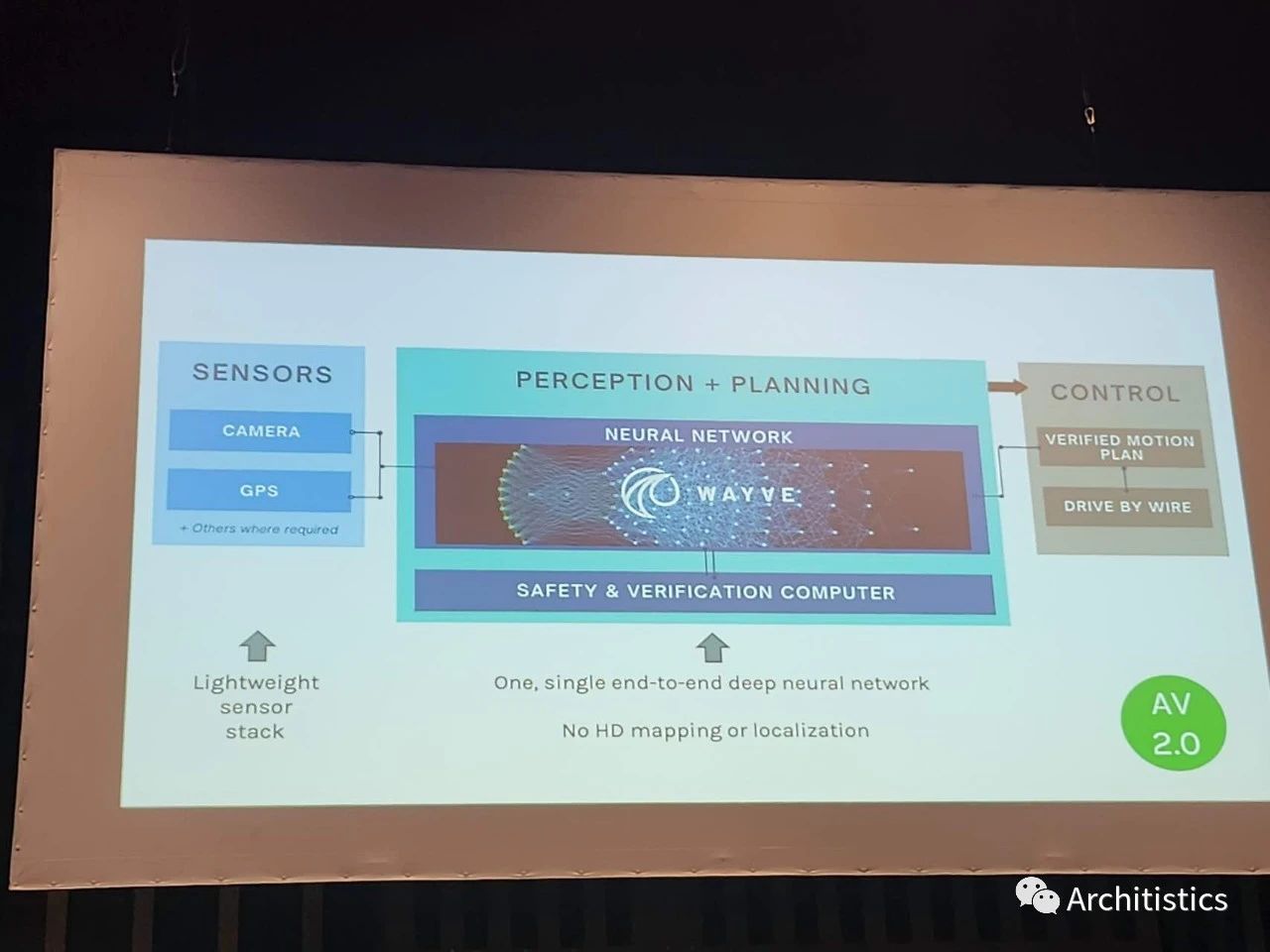
Jamie的大模型,小感知
闲话就说到这里了。这次ICCV还是有不少有意思的talks,希望之后能有公开的videos/slides。最后,祝愿各位同仁们都能继续做自己感兴趣的方向,做出令自己满意的工作!
-
计算机视觉
+关注
关注
8文章
1698浏览量
46011 -
数据集
+关注
关注
4文章
1208浏览量
24716 -
LLM
+关注
关注
0文章
289浏览量
351
原文标题:计算机视觉走向何方?参会ICCV的一些感想
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
计算机视觉的五大技术
计算机视觉的工作原理和应用
计算机视觉与人工智能的关系是什么
计算机视觉与智能感知是干嘛的
机器视觉与计算机视觉的区别
计算机视觉的主要研究方向
计算机视觉的十大算法






 工商网监
工商网监
评论