 中科院&旷视提出DropPos:全新的自监督视觉预训练代理任务
中科院&旷视提出DropPos:全新的自监督视觉预训练代理任务
0. 基本信息

DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions. InNeurIPS 2023.
论文:arxiv.org/pdf/2309.03576
代码:github.com/Haochen-Wang409/DropPos
今天介绍我们在自监督视觉预训练领域的一篇原创工作DropPos:Pre-Training Vision Transformers by Reconstructing Dropped Positions.
目前 DropPos 已被 NeurIPS 2023 接收,相关代码已开源,有任何问题欢迎在 GitHub 提出。
1. TL;DR
我们提出了一种全新的自监督代理任务 DropPos,首先在 ViT 前向过程中屏蔽掉大量的 position embeddings (PE),然后利用简单的 cross-entropy loss 训练模型,让模型重建那些无 PE token 的位置信息。这个及其简单的代理任务就能在多种下游任务上取得有竞争力的性能。
2. Motivation
在 MoCo v3 的论文中有一个很有趣的现象:ViT 带与不带 position embedding,在 ImageNet 上的分类精度相差无几。

表 1. MoCo v3 中的实验现象 (原文第 6 页)
这一实验结果背后,隐含着「ViT 的建模主要关注于不同 patch 的 visual appearence,对于 position 的 awareness 较差」这一信息。即,如果把图片切 patch 然后再随机打乱之后,ViT 能够在乱序的情况下准确识别该图片的类别。这一点和人类直觉有很大出入。同时,有可能是因为 ViT 过拟合到了 ImageNet 这个特定数据集导致的。
基于此,我们首先做了一些 tiny experiments,探究 position awareness 与模型的识别准确率到底是否有正相关的关系。具体来说,我们冻结了 MoCo v3 和 MAE 的 pre-train/fine-tune 权重,在其后接一个全连接层,并用 position classification 这个任务做 linear probing。即,在 forward 过程中随机丢弃 75% 的 PE,并把 ViT 的 feature 映射到 196 维 (一张图有 14x14 个 patch),期望让最终的线性层正确分类该 patch 的位置。

表 2. Position awareness 对于下游任务的影响
表中结果表明,fine-tune 后的模型权重,更适合预测位置这一任务。说明「强大的对位置的建模能力,对于图像分类任务是有益的」。基于此,我们想探究一种能够提升 ViT 对于位置建模能力的全新自监督代理任务。
一种可行的方案是「简单地把 ViT 的 PE 随机丢弃一部分,然后让模型预测这些不带 PE 的 token 的精确位置」,即 reconstructDroppedPositions (DropPos).
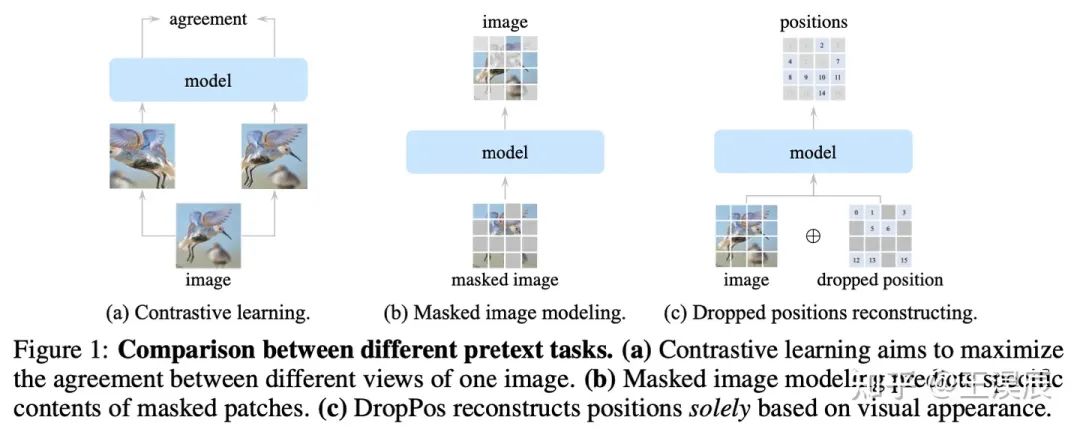
图 1. DropPos 与 CL 和 MIM 的对比
DropPos 有如下的优势:
对比 CL,DropPos 不需要精心设计的数据增强 (例如 multi-crop)。
对比 MIM,DropPos 不需要精心设计的掩码策略和重建目标。
下面我们介绍 DropPos 的具体运行流程
3. Method
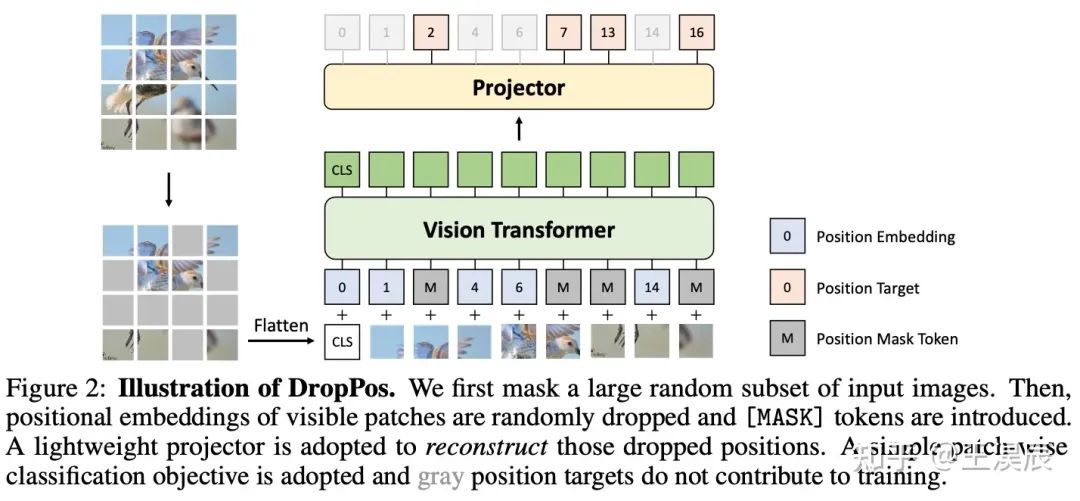
图 2. DropPos 的流程图
即使 DropPos 的想法很直观也很简单,但这类方法一直没有成为预训练的主流,主要是由于在设计上有以下三个难点:
如果简单地把所有 PE 丢弃,让模型直接重建每个 patch 的位置,会导致上下游的 discrepency。因为下游任务需要 PE,而上游预训练的模型又完全没见过 PE。
ViT 对于 long-range 的建模能力很强,这个简单的位置重建任务可能没办法让模型学到非常 high-level 的语义特征。
看上去相似的不同 patch (例如纯色的背景) 的位置无需被精准重建,因此决定哪些 patch 的位置需要被重建非常关键。
针对上述难点,我们提出了三个解决手段:
针对问题一,我们采用了一个简单的随机丢弃策略。每次训练过程中丢弃 75% 的 PE,保留 25% 的 PE。
针对问题二,我们采取了高比例的 patch mask,既能提高代理任务的难度,又能加快训练的速度。
针对问题三,我们提出了 position smoothing 和 attentive reconstruction 的策略。
3.1 DropPos 前向过程

算法 1. DropPos 的前向过程
DropPos 的前向过程包括两段 mask,分别是第一步 patch mask (类似 MAE),和第二步的 position mask (用可学习的 position mask 代替 dropped positions)。具体可以参见上方的伪代码。
3.2 Objective
我们使用了一个最简单的 cross-entropy loss 作为预训练的目标函数:
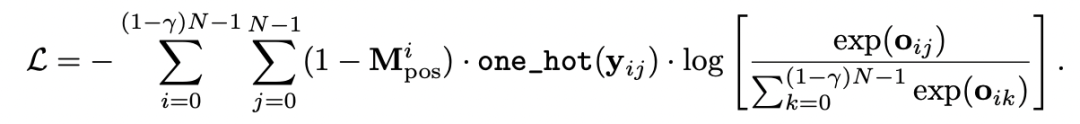
其中,o 是模型的输出,即第 i 个 patch 的预测位置是 j 的 logit,y 是真实的位置信息。
gamma 是第一步的 patch mask ratio,N 为总 patch 数量。
Mpose是 0-1 的 position mask,1 表示该 patch 带有 PE,不应当被重建,而 0 表示该 patch 不带 PE,需要被重建。
我们接下来引入 position smoothing 和 attentive reconstruction 技术来松弛这个问题,以解决相似但不同 patch 的位置重建问题。
3.2.1 Position Smoothing
我们采用一个高斯核来平滑原本的 position targets
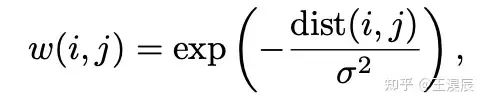
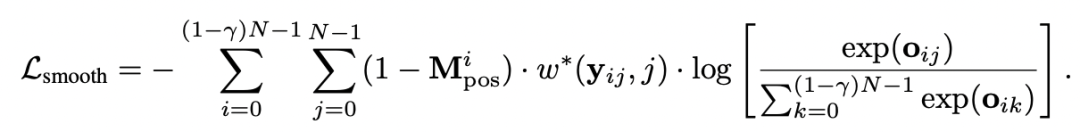
此处,w(i, j) 表示当真实位置为 i,而预测位置为 j 时,平滑后的 position target。
此外,我们还让 sigma 自大变小,让模型一开始不要过分关注精确的位置重建,而训练后期则越来越关注于精准的位置重建。
3.2.2 Attentive Reconstruction
我们采用 [CLS] token 和其他 patch 的相似度作为亲和力矩阵,作为目标函数的额外权重。
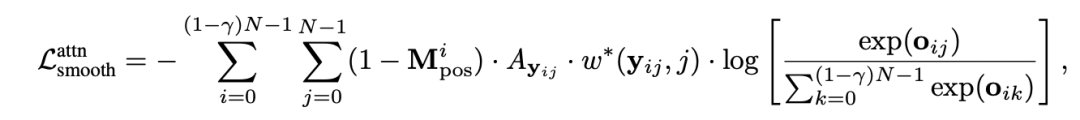
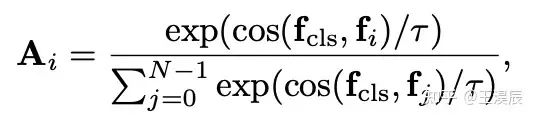
其中 f 为不同 token 的特征,tau 为超参数,控制了 affinity 的平滑程度。
4. Experiments
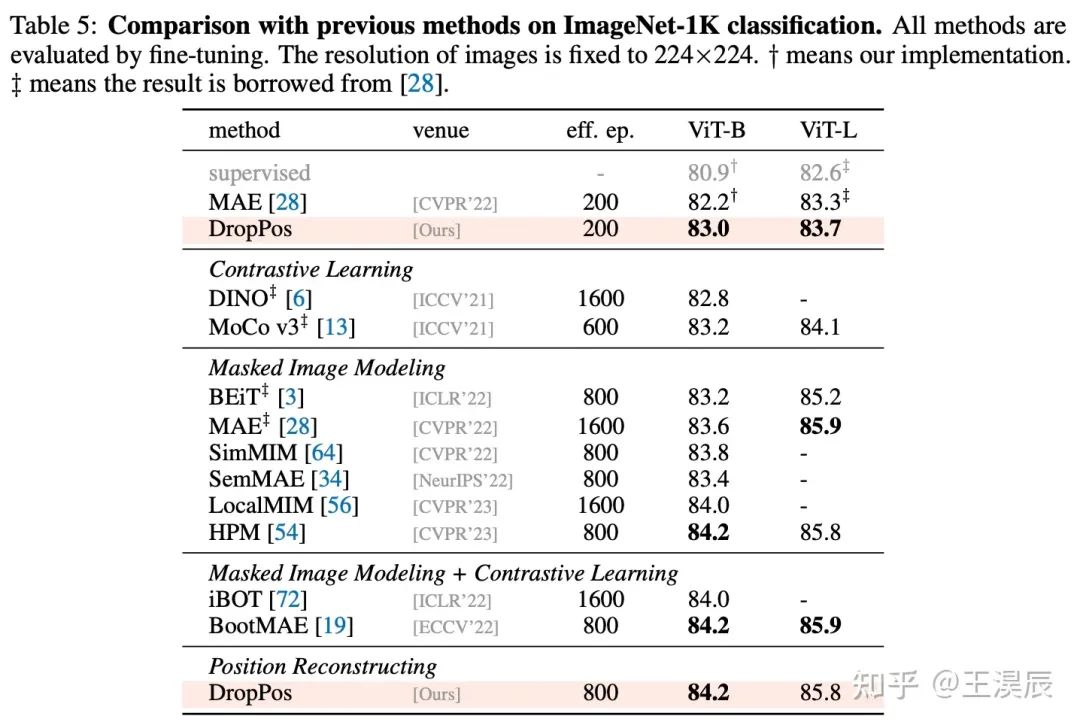
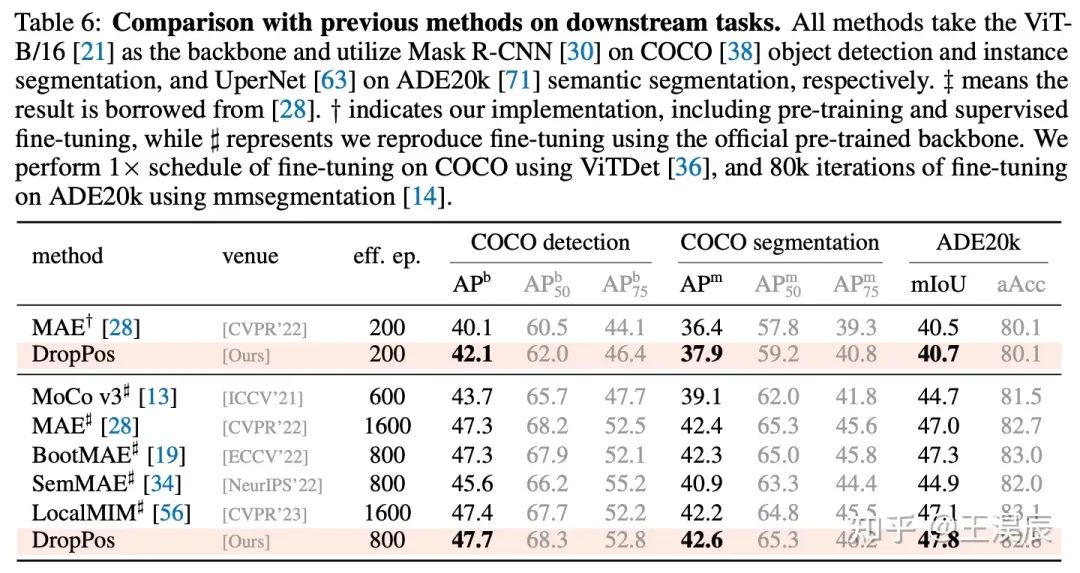
4.1 与其他方法的对比
4.2 消融实验
本文主要有四个超参:patch mask ratio (gamma),position mask ratio (gamma_pos),sigma,和 tau。

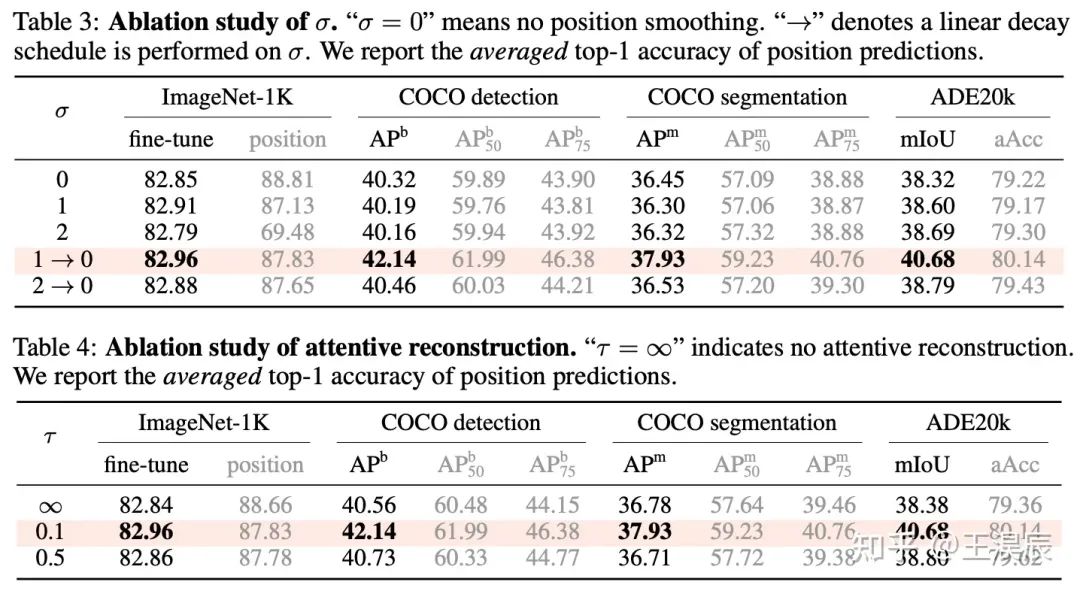
由表,我们可以得出一些比较有趣的结论:
一般来说,更高的 position 重建精度会带来更高的下游任务性能。
上述结论存在例外:当 sigma = 0 时,即不做位置平滑时,位置预测精度高,而下游任务表现反而低;当 tau = inf 时,即不做 attentive reconstruction 时,位置预测精度高,而下游表现反而低。
因此,过分关注于预测每一个 patch 的精确的位置,会导致局部最优,对于下游任务不利。

上图是 DropPos 位置重建的可视化结果,黑色 patch 代表的是前向过程中被 mask 掉的 patch;白色 patch 的位置被错误重建,而剩余 patch 的位置被精准重建。
DropPos 在极端情况 (例如 gamma=0.75) 时,依然可以做到大部分 patch 的精准重建。
-
模型
+关注
关注
1文章
3372浏览量
49313 -
视觉
+关注
关注
1文章
147浏览量
24043 -
旷视
+关注
关注
0文章
77浏览量
6609
原文标题:NeurIPS 2023 | 中科院&旷视提出DropPos:全新的自监督视觉预训练代理任务
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
中科院剖析 LED怎样克服困难
0055《最优控制理论(中科院)》科学出版社-2003.pdf(4M)
中科院深耕网络摄像机领域
中科院清库房-20V600A稳流电源
中科院3D打印机CEST400|国产工业级3D打印机

微软在ICML 2019上提出了一个全新的通用预训练方法MASS

基于Transformer架构的文档图像自监督预训练技术
复旦&amp;微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?

NeurIPS 2023 | 全新的自监督视觉预训练代理任务:DropPos






 工商网监
工商网监
评论