 TPU-MLIR量化敏感层分析,提升模型推理精度
TPU-MLIR量化敏感层分析,提升模型推理精度
背景介绍
TPU-MLIR编译器可以将机器学习模型转换成算能芯片上运行的bmodel模型。由于浮点数的计算需要消耗更多的计算资源和存储空间,实际应用中往往采用量化后的模型(也称定点模型)进行推理。相比于浮点数模型,量化模型的推理精度会有一定程度的损失。当精度损失较大时,需要搜索模型中对精度影响较大的层,即敏感层,将其改回浮点类型,生成混精度模型进行推理。
以mobilenet-v2网络为例,使用ILSVRC-2012数据验证集的5万张图片验证浮点数模型和量化模型(表格中分别记为FLOAT和INT8)的精度,INT8模型的Top1精度降低了3.2%,Top5精度降低了2%。
| Type | Top1 (%) | Top5 (%) |
|---|---|---|
| FLOAT | 70.72 | 89.81 |
| INT8 | 67.53 | 87.84 |
敏感层搜索
TPU-MLIR的敏感层搜索功能会计算网络模型中的每一层分别由浮点数类型转成定点数类型后,对网络模型输出造成的损失。同时,由于量化threshold值也会影响定点模型的精度,敏感层搜索功能考虑了三种量化方法——KL、MAX和Percentile对精度的影响。KL方法首先统计FLOAT模型tensor绝对值的直方图(2048个bin),得到参考概率分布P,随后用INT8类型去模拟表达这个直方图(128个bin),得到量化概率分布Q,在不同的截取位置计算P和Q的KL散度,最小散度对应的截取位置记为KL方法得到的threshold值。MAX方法是用FLOAT模型tensor绝对值的最大值作为量化threshold。Percentile方法则是通过统计FLOAT模型tensor绝对值的百分位数来确定threshold。
算法流程
敏感层搜索算法的流程图如下:
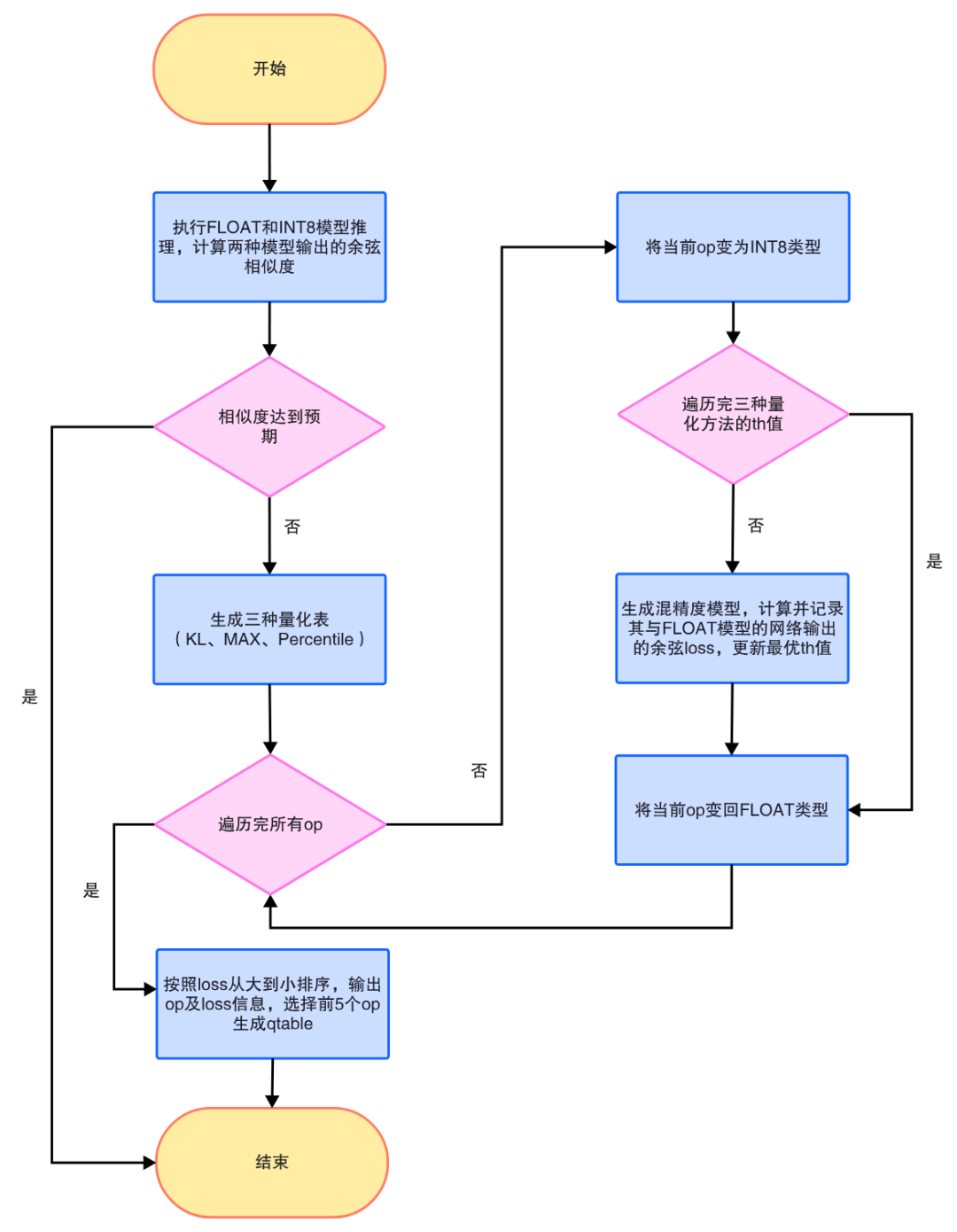 敏感层搜索流程图
敏感层搜索流程图
- 在搜索之前需要先判断FLOAT模型和INT8模型的相似度,用一定数目的图片(比如30张)进行推理,计算两种模型输出结果的余弦相似度的平均值,如果平均值达到预设值,比如0.99,则认为INT8模型与FLOAT模型的相似度较高,不需要进行敏感层搜索。
- 对于该模型,生成三种量化方法对应的量化表。
- 循环每个op及每种量化方法,将该op改为INT8类型,并采用对应量化方法下的threshold,生成混精度模型,计算其与FLOAT模型网络输出的loss(1减余弦相似度),记录最优threshold,即最低loss值对应的threshold,随后将该op改回FLOAT类型。
- 将所有op按照loss从大到小排序,选择排名前五的op生成qtable。
在搜索过程中,对于每个op及其每种threshold值下生成的混精度模型与FLOAT模型的loss,以及最终按照loss排序的所有op信息(包括op的名字、类型和loss),均会记录在log日志中,用户可以通过查看log日志,手动调整qtable文件。
使用方法
敏感层搜索需要输入从model_transform步骤得到的mlir文件,run_calibration步骤得到的量化表,推理用的数据集等,使用命令如下:
run_sensitive_layer.pymobilenet.mlir\
--dataset../ILSVRC2012\
--input_num100\
--inference_num30\
--max_float_layers5\
--expected_cos0.99\
--post_processpostprocess.py\
--calibration_tablemobilenet_cali_table\
--chipbm1684\
-omobilenet_qtable
各项参数的含义如下表所示:
| 参数名称 | 含义 |
|---|---|
| dataset | 用于量化和推理的数据集,推荐使用bad case |
| input_num | 用于量化的图片数目 |
| inference_num | 用于推理的图片数目 |
| max_float_layers | qtable中的op数目 |
| expected_cos | INT8模型和FLOAT模型的余弦相似度阈值,达到阈值则不进行敏感层搜索 |
| post_process | 用户自定义后处理文件路径,后处理函数需要命名为PostProcess |
| calibration_table | run_calibration步骤得到的量化表 |
| chip | 使用的芯片类型 |
| o | 生成的qtable名称 |
敏感层搜索程序会生成如下文件:
- 用于生成混精度模型的qtable,每行记录了需要转回FLOAT的op及转换类型,例如:input3.1 F32;
- 经过调优后的新量化表new_cali_table,在原始量化表的基础上,更新了每个op的threshold值为三种量化方法中最优的threshold;
- 搜索日志SensitiveLayerSearch,记录整个搜索过程中,每个op在每种量化方法下,混精度模型与FLOAT模型的loss;
注意,在model_deploy步骤生成混精度模型时,需要使用qtable和新量化表。
精度测试结果
仍以前述精度测试采用的mobilenet-v2网络为例,使用ILSVRC2012数据集中的100张图片做量化,30张图片做推理,敏感层搜索总共耗时402秒,占用内存800M,输出结果信息如下:
the layer input3.1 is 0 sensitive layer, loss is 0.008808857469573828, type is top.Conv
the layer input11.1 is 1 sensitive layer, loss is 0.0016958347875666302, type is top.Conv
the layer input128.1 is 2 sensitive layer, loss is 0.0015641432811860367, type is top.Conv
the layer input130.1 is 3 sensitive layer, loss is 0.0014325751094084183, type is top.Scale
the layer input127.1 is 4 sensitive layer, loss is 0.0011817314259702227, type is top.Add
the layer input13.1 is 5 sensitive layer, loss is 0.001018420214596527, type is top.Scale
the layer 787 is 6 sensitive layer, loss is 0.0008603856180608993, type is top.Scale
the layer input2.1 is 7 sensitive layer, loss is 0.0007558935451825732, type is top.Scale
the layer input119.1 is 8 sensitive layer, loss is 0.000727441637624282, type is top.Add
the layer input0.1 is 9 sensitive layer, loss is 0.0007138056757098887, type is top.Conv
the layer input110.1 is 10 sensitive layer, loss is 0.000662179506136229, type is top.Conv
......
run result:
int8 outputs_cos:0.978847 old
mix model outputs_cos:0.989741
Output mix quantization table to mobilenet_qtable
total time:402.15848112106323
观察可知,input3.1的loss最大,且值为其他op的至少5倍。尝试只将input3.1加进qtable,其他层都保持INT8类型不变,生成混精度模型,在ILSVRC2012验证集上进行推理,精度如下:
| Type | Top1 (%) | Top5 (%) |
|---|---|---|
| FLOAT | 70.72 | 89.81 |
| INT8 | 67.53 | 87.84 |
| MIX(oricali) | 68.19 | 88.33 |
| MIX(newcali) | 69.07 | 88.73 |
上表中,MIX(oricali)代表使用原始量化表的混精度模型,MIX(newcali)代表使用新量化表的混精度模型,可以看出,基于三种量化方法的threshold调优,也对模型的精度起到了正向影响。相比于INT8模型,混精度模型的Top1精度提升1.5%,Top5精度提升约1%。
对比混精度搜索
混精度搜索是TPU-MLIR中的另一个量化调优搜索功能,它的核心思想是先寻找到layer_cos不满足要求的层,再将该层及其下一层均从INT8转回FLOAT,生成混精度模型,计算其与FLOAT模型输出的余弦相似度,如果余弦相似度达到预设值,则停止搜索。注意,混精度搜索只有在op表现较差,即混精度模型与FLOAT模型输出相似度低于INT8模型与FLOAT模型输出相似度时,才会将op类型从FLOAT置回INT8,否则不会改变op的精度类型。所以混精度搜索不需要从头进行推理,耗时较短。这两种方法的对比如下:
| 对比情况 | 敏感层搜索 | 混精度搜索 |
|---|---|---|
| 核心思想 | 循环所有op,找对网络输出影响最大的层 | 以单层layer的相似度为入口,网络输出的相似度为停止条件 |
| 考虑多种量化方法 | 只考虑KL方法 | |
| 修改量化表 | 使用原始量化表 | |
| 考虑相邻两层 | 只考虑单层 | |
| 考虑layer_cos | 暂未考虑 | |
| 考虑网络输出的余弦相似度 | ||
| 手动修改qtable | 使用程序生成的qtable即可 | |
| 支持用户自定义后处理 | 暂不支持 | |
| 遍历所有op | 有skip规则,并且达到预设cos后直接停止 | |
| op类型转换规则 | 从FLOAT变为INT8,算loss | 从INT8变回FLOAT,算cos |
混精度搜索从网络输入开始,不断搜索对网络输出相似度有提升的层加入qtable,直到网络输出相似度达到预设值后终止搜索。该方法可能会漏掉靠近网络输出部分的敏感层,而敏感层搜索方法会遍历所有op,不会出现这种遗漏,这也是敏感层搜索的优势之处。在实际应用中,用户可以先使用速度较快的混精度搜索,如果没能达到预期效果,再使用敏感层搜索功能进行全局遍历。
结语
敏感层搜索功能旨在寻找模型量化时对精度影响较大的层,它会遍历模型中的所有op及三种量化方法,选择最优的量化threshold,记录所有op的loss。将搜索到的敏感层设定为浮点数类型,其余层设定为定点数类型,生成混合精度模型,可以提升模型推理的精度。目前的敏感层搜索功能在mobilenet-v2网络中表现优异,只需要将loss最大的一层置为FLOAT,就可以获得1.5%的精度提升。与混精度搜索方法相比,敏感层搜索虽然耗时更久,但它考虑了所有op和三种量化方法,不会遗漏靠近网络输出部分的敏感层。未来可以考虑从三个方面对敏感层搜索功能进行优化:1) 结合混精度搜索的优点,在搜索时考虑每层及其邻近层对网络输出的综合影响;2) 在生成qtable时,不是根据用户设定的数目,选择loss最大的前N层,而是通过计算,将能让网络输出相似度达到预设值的op均加入qtable;3) 在遍历op的过程中考虑并行,缩短搜索时间。
-
模型
+关注
关注
1文章
3436浏览量
49587 -
机器学习
+关注
关注
66文章
8466浏览量
133600 -
TPU
+关注
关注
0文章
146浏览量
20925
发布评论请先 登录
相关推荐
【幸狐Omni3576边缘计算套件试用体验】RKNN 推理测试与图像识别
AI大模型在汽车应用中的推理、降本与可解释性研究









 工商网监
工商网监
评论