 记录一次hard fault on handler的解决过程
记录一次hard fault on handler的解决过程
背景
最近在做一个OTA的功能时,遇到一个hard fault on handler的问题,前前后后排查了将近2天,才将此问题解决,因此做一个记录,方便其它工程师,遇到此类问题的时候有个参考。
环境
rt-thread v4.1.0
lwip2.1.2
cJSON-lastest
使能了posix的select和poll
CmBacktrace v1.3.0
使能了ulog组件
问题和排查过程
最开始遇到问题的时候,报以下错误
psr: 0xa100000f
r00: 0xffffffff
r01: 0x2000def4
r02: 0xffffffff
r03: 0x7fffffff
r04: 0x00000000
r05: 0x20017f18
r06: 0x20000358
r07: 0xdeadbeef
r08: 0x00000000
r09: 0x00000001
r10: 0xdeadbeef
r11: 0xdeadbeef
r12: 0x00000000
lr: 0x08042ed9
pc: 0x08042ef8
hard fault on handler
bus fault:
SCB_CFSR_BFSR:0x82 PRECISERR SCB->BFAR:FFFFFFFF
使用CmBacktrace软件包定位问题
后来在论坛搜索相关的关键词,有人推荐使用CmBacktrace软件包,于是去安装此软件包,但是安装了以后,报如下错误
thread pri status sp stack size max used left tick error
rf_led 10 suspend 0x00000080 0x00000100 50% 0x0000000a 000
rf_send 10 suspend 0x000000a0 0x00000800 16% 0x00000009 000
rf_read 10 suspend 0x000000c0 0x00000200 39% 0x00000003 000
可以看到,CmBacktrace没有打印完全,这时候我又去CmBacktrace的github仓库,看有没有人提相关的issue,发现是因为我打开了ulog组件导致的,具体可以参考这个issue
Usage fault下没输出关键的call_stack信息
然后我按照链接,手动修改CmBacktrace的打印宏定义为rt_kprintf,使用CmBacktrace的cmb_test的除零测试命令测试以后,可以正常打印了,这时候我太开心了,以为问题基本上可以定位了,然而我发现我高兴的还是太早了。
在cmb_test正常以后,当我把问题再次复现时,CmBacktrace打印的信息,还是不全,和之前完全没有变化!!!如下所示。
thread pri status sp stack size max used left tick error
rf_led 10 suspend 0x00000080 0x00000100 50% 0x0000000a 000
rf_send 10 suspend 0x000000a0 0x00000800 16% 0x00000009 000
rf_read 10 suspend 0x000000c0 0x00000200 39% 0x00000003 000
这就非常奇怪了,明明使用CmBacktrace的除零测试是OK的,为什么还是打印不正常呢?
使用PC和LR反推
看样子是不能用CmBacktrace了,也许是我使用的姿势不对,也许是其他问题,那就只能靠自己了。
我试着按照文章的方法去排查,结果发现复现问题的时候,是在rtthread的timer里面,如下图所示
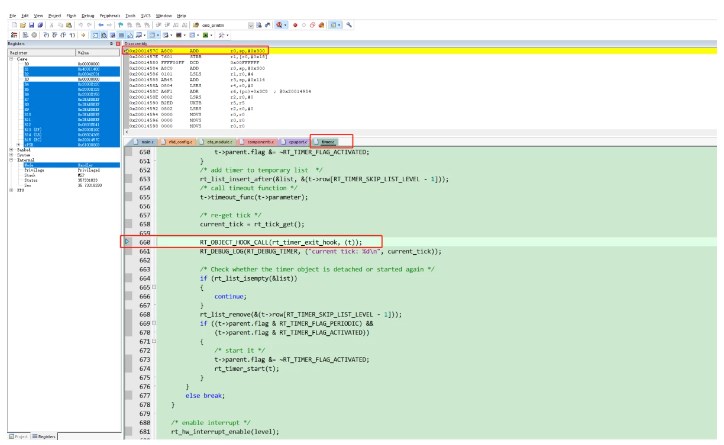
这就让我犯难了,这不会是rt-thread的问题吧,rt-thread这么多年了,难道我一用就出问题?
不破不立
不可能,绝对不可能,一定是我用的姿势不对,再换一个姿势吧,不破不立,由于我的代码是分模块的,于是我就将自己感觉有问题的模块,一个一个注释掉,如下图所示,从后面往前面一个一个注释,每注释一个模块,我就看看是否还会发生hardfualt
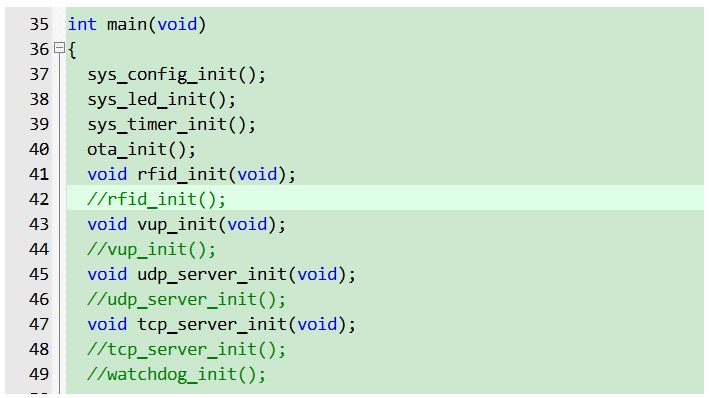
当我把ota_init模块注释掉的时候,发现hardfualt没了,这…这怎么可能呢,这个模块我之前测试过的呀,跑了两天都是正常的。
然后我发现,设备每次出现hardfault的时候,系统的tick都是553600ms左右,如下所示,换算成分钟也就是9分钟这样,9分钟,9分钟,9分钟,9分钟的时候还没有出现hardfualt,我的ota模块,是每10分钟去服务器拉取一次做版本检测,这么说,是这里的问题了?
| /
RT - Thread Operating System
/ | 4.1.0 build Jan 6 2023 17:42:12
2006 - 2022 Copyright by RT-Thread team
lwIP-2.1.2 initialized!
[4416] I/sal.skt: Socket Abstraction Layer initialize success.
[4574] I/rfid_config: reader.id : 4403061904001
[4579] I/rfid_config: reader.beep : 0
[4584] I/rfid_config: report.interval : 60
[4588] I/rfid_config: reader.power : 10
[4594] D/ota_module: ota_flag == ERASE_IAP_FLAG
msh />[4715] D/rfid_module: rfid_report tag
[65630] D/rfid_module: rfid_report tag
[126649] D/rfid_module: rfid_report tag
[187613] D/rfid_module: rfid_report tag
[248612] D/rfid_module: rfid_report tag
[309611] D/rfid_module: rfid_report tag
[370595] D/rfid_module: rfid_report tag
[430629] D/rfid_module: rfid_report tag
[491631] D/rfid_module: rfid_report tag
[552598] D/rfid_module: rfid_report tag
thread pri status sp stack size max used left tick error
tcp_ser 10 suspend 0x000001d8 0x00000800 25% 0x0000000a 000
udp_ser 10 suspend 0x00000228 0x00000400 53% 0x0000000a 000
rf_led 10 suspend 0x00000080 0x00000100 50% 0x0000000a 000
rf_send 10 suspend 0x000000a0 0x00000800 16% 0x00000003 000
rf_read 10 suspend 0x000000c0 0x00000200 37% 0x00000004 000
| /
RT - Thread Operating System
/ | 4.1.0 build Jan 6 2023 17:42:12
2006 - 2022 Copyright by RT-Thread team
lwIP-2.1.2 initialized!
[4416] I/sal.skt: Socket Abstraction Layer initialize success.
[4574] I/rfid_config: reader.id : 4403061904001
[4579] I/rfid_config: reader.beep : 0
[4584] I/rfid_config: report.interval : 60
[4588] I/rfid_config: reader.power : 10
[4594] D/ota_module: ota_flag == ERASE_IAP_FLAG
msh />[4716] D/rfid_module: rfid_report tag
[65642] D/rfid_module: rfid_report tag
[126601] D/rfid_module: rfid_report tag
[151604] D/rfid_module: rfid_report tag
[187619] D/rfid_module: rfid_report tag
[248596] D/rfid_module: rfid_report tag
[309616] D/rfid_module: rfid_report tag
[370621] D/rfid_module: rfid_report tag
[431620] D/rfid_module: rfid_report tag
[492616] D/rfid_module: rfid_report tag
[553600] D/rfid_module: rfid_report tag
thread pri status sp stack size max used left tick error
rf_led 10 suspend 0x00000080 0x00000100 50% 0x0000000a 000
rf_send 10 suspend 0x000000a0 0x00000800 16% 0x00000009 000
rf_read 10 suspend 0x000000c0 0x00000200 39% 0x00000003 000
于是我把OTA的时间改成每10秒一次,果然10秒以后,就出现了hardfault
峰回路转
那么问题很明确了,就是这个OTA模块的问题,于是我在OTA模块里面打断点排查,发现在socket里面,发送UDP数据包的时候,就出现了hardfault,如下所示

这会是数组越界导致的吗?于是我开始排查在这个udp发送函数前面的代码,仔细排查以后,没发现有数组越界的现象。线索又断了….怎么办呢?我左思右想,问题就出现在这,到底是什么原因?
柳暗花明
udp发送,udp发送,会不会是这个线程爆栈了,于是我瞟了一眼这个线程的栈大小,哎哟我去,512字节。
thread = rt_thread_create("ota", ota_thread, RT_NULL, 512, 10, 10);
那我就改一下吧,改1024试试,果然,正常了….松了一口气…
原来这个线程的栈是1024字节的,后面我使用ps命令看了这个线程栈的利用率还很低,于是我改成了512字节,这也就是说,为什么我之前测试了2天这个模块都是正常的,现在却不行了。因为我使用ps命令的时候,那会才运行了几分钟,看到的线程栈利用率是没有调用udp发送函数的,也就是说,那会看到的栈利用率,是不准的,那时候我去减小它,肯定就容易出问题了
当系统正常以后,我再次去ps,发现线程实际的栈利用率是92%,如下所示(前面的ps是没有调用udp函数之前的,后面的ps是调用udp函数以后的,这时候的栈我设置的大小是1024),也就是说,512字节,肯定是不够的,甚至1024都快爆了,还得增大。
thread pri status sp stack size max used left tick error
ota 10 suspend 0x0000007c 0x00000400 32% 0x00000005 000
sys_led 10 suspend 0x0000007c 0x00000100 48% 0x0000000a 000
tshell 20 running 0x00000094 0x00001000 13% 0x00000003 000
tcpip 10 suspend 0x000000d0 0x00002000 07% 0x00000014 000
etx 12 suspend 0x00000094 0x00000400 14% 0x00000010 000
erx 12 suspend 0x00000094 0x00000400 56% 0x00000010 000
sys work 23 suspend 0x00000060 0x00000800 53% 0x0000000a 000
tidle0 31 ready 0x00000048 0x00000100 45% 0x00000009 000
timer 4 suspend 0x00000064 0x00000200 24% 0x00000009 000
main 10 suspend 0x00000084 0x00000800 33% 0x0000000e 000
msh />
msh />
msh />
msh />
msh />[14598] D/udp_module: send success
[14628] D/ota_module: ota_flag == ERASE_IAP_FLAG
ps
thread pri status sp stack size max used left tick error
ota 10 suspend 0x0000007c 0x00000400 92% 0x00000001 000
sys_led 10 suspend 0x0000007c 0x00000100 48% 0x0000000a 000
tshell 20 running 0x0000020c 0x00001000 13% 0x00000007 000
tcpip 10 suspend 0x000000d0 0x00002000 07% 0x00000014 000
etx 12 suspend 0x00000094 0x00000400 14% 0x00000010 000
erx 12 suspend 0x00000094 0x00000400 56% 0x00000010 000
sys work 23 suspend 0x00000060 0x00000800 53% 0x0000000a 000
tidle0 31 ready 0x00000058 0x00000100 45% 0x00000018 000
timer 4 suspend 0x00000064 0x00000200 24% 0x00000009 000
main 10 suspend 0x00000084 0x00000800 33% 0x0000000e 000
总结
使用了网络的线程,一定要将线程栈开大一点,512字节肯定是不够的,最少1536字节以上
使用ps命令打印出来的线程栈最大使用率,是在代码运行过一段时间以后,才准的,比如我的代码中,udp发送数据是在系统启动10分钟以后才运行到,所以我在前面几分钟的时候使用的ps命令看,ota线程是没有爆栈的,只有在运行到这个网络发送数据的代码,这个栈才会溢出。
因此如果有一些代码不是立即运行的,在调试的时候,可以把这个时间提前,尽量让系统上电以后,把所有的代码都能跑一遍,这样对于一些跑了一段时间才出现栈溢出的问题,比较容易复现,容易复现也就容易解决。
或者可以在调试代码的时候,可以把线程栈设置大一些,让代码先能够正常跑起来,然后跑个几天,再去ps一下看看栈的最大利用率,几天以后所有的代码、流程应该基本上都跑过一遍了,这时候的栈利用率才是比较准的,这时候才去优化这个栈大小,会比较合适。
在遇到hardfault的时候,不要怕,用工具不行,我们就手动一个一个模块去排查,把问题的范围缩小,尽管耗费的时间会长一点,但是总会定位到问题的。
最后我想,如果rt-thread可以在栈溢出的时候,自动检测并且定位出来就好了,比如我这个ota的线程栈溢出了,rt-thread就告诉我,xxxx线程栈溢出啦,你得开辟大一点,就好了。
-
OTA
+关注
关注
7文章
582浏览量
35263 -
LwIP协议栈
+关注
关注
0文章
19浏览量
7379 -
RT-Thread
+关注
关注
31文章
1293浏览量
40211 -
UDP通信
+关注
关注
0文章
21浏览量
1928
发布评论请先 登录
相关推荐
【经验】飞思卡尔工程师教你如何定位Kinetis MCU Hard Fault 异常
通过SPI往SD卡写数据出现bus hard_fault该怎样去解决这个问题呢
记录一次hard fault on handler的解决过程
新手求助删掉某一行LOG_I会导致hard fault on handler?
程序在运行一段时间后报In Hard Fault Handler错误怎么解决?
程序在运行一段时间后报In Hard Fault Handler错误的原因?怎么解决?
程序在运行一段时间后报In Hard Fault Handler错误的原因?
单片机硬错误排查方法

STM32H750上使用PCROP后导致Hard Fault





 工商网监
工商网监
评论