 多场景通吃,INDEMIND视觉导航方案赋能服务机器人更多可能
多场景通吃,INDEMIND视觉导航方案赋能服务机器人更多可能
打破场景限制,不一样的“斜杠青年”。
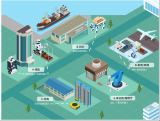
随着服务机器人不断进入到商场、超市、写字楼、酒店等新场景,场景的多样化和复杂度也在明显提升,由于场景的独特性,对于机器人的要求也千差万别,这意味机器人需要更强大的适应性,并同时满足使用体验、成本等要求。
那么该如何提升机器人的场景适应能力?INDEMIND围绕环境感知、地图构建、智能避障、交互及云端平台等方面,进行了更深层次的探索。
与人相同,“眼睛”是机器人感知世界的基础,想要让机器人看的更多,懂得更多,视觉技术是必然选择,可以看到,市面上出现了一大批以单线或多线激光雷达为核心的多传感器融合技术,使机器人的环境感知能力得到显著提升,且在功能表现上,还有着激光雷达精度高和稳定性高的特点,然而这两类方案的缺点也较明显。
单线融合方案一是环境适应能力较差,对于环境特征单一的长走廊等场景,误差较高,容易偏离路径,二是重定位能力差,运行过程中一旦丢失位置,难以重新定位;多线融合方案一旦出现故障,会导致整个系统宕机,且这类方案成本高昂,目前也主要应用于大多数商用机器人。
如果大胆换个思路,以视觉为核心的多传感器融合技术是否可行?
作为计算机视觉技术行业的佼佼者,INDEMIND进行了5年时间的死磕。在技术在实现上,INDEMIND基于独有的立体视觉技术,设计了以视觉传感器为主导的标准化、模块化的多传感器融合架构,通过遵循INDEMIND的标准定义接口,可快速加入IMU、里程计、激光雷达、GNSS等多种传感器,实现“积木式”加装,能够实现高精度、高稳定性、低成本的3D环境感知,走通了一条不同于激光雷达方案的新路径。
与此同时,INDEMIND还拥有超过100个使用场景的海量数据,对于清洁、配送、导览、安防等多种工作场景有着深度理解,配合视觉多融合感知技术,能进一步提升机器人的环境感知能力。
事实上,提升环境感知能力,仅是解决机器人场景适应问题的第一步,避障、交互、作业逻辑上的提升,才是适应问题中的真正痛点。
实时构建语义地图,让地图更丰富
基于INDEMIND立体视觉技术,机器人支持全场景二维地图、三维地图及语义地图自主创建,支持地图动态更新及智能禁区,且建图精度可达厘米级,达到激光雷达方案同等水平。三维语义地图让机器人有了懂得人类“常识”的能力,为实现更高层级的智能避障、智能交互、智能作业提供了底层支持。
智能决策引擎,赋予机器人“逻辑思维”
想让机器人更像人,首先需要机器人能够模仿人的决策,也即是智能决策技术。它需要把信息感知(认知)、(基于知识图谱、数据和机器学习)决策和执行过程有机地统一起来。而INDEMIND在开发上,采用了设备端、云端智能决策平台、大数据平台三端结合的模式建立一套智能决策引擎,并且能够基于关键数据不断更新算法模型,持续提升场景处理和问题应对能力。
借助智能决策引擎,在避障上,机器人可做出类人规避动作的精细化操作,能够让机器人有策略的实现智能避障(如根据障碍物不同做出不同规避距离);在交互上,可通过语音、手势、动作等自然语言指令,命令机器人进行安全、搜寻、跟随、自主寻路、定向清扫等多种智能逻辑,让机器人发挥真正价值。
随着核心技术的积累和成熟,INDEMIND面向10-100kg级商用机器人推出了「商用机器人AI Kit」自主导航方案。不同于机器人移动底盘,「商用机器人AI Kit」在硬件选择和外形上可根据实际开发需求灵活适配,适用性大大提升,同时满足商用机器人导航定位、智能避障、路径规划、决策交互等核心功能的开发,实现了商用场景全覆盖,能够满足清洁、配送、导览、安防等多种商用机器人开发需求。
需要提到的是,相较于激光雷达多传感器融合方案,成本能够下降60-80%。
从市场反馈来看,INDEMIND已和国内外多家巨头客户达成合作,受到了广泛认可。目前,INDEMIND已签署订单超2万台,三年预期订单将超10万台。其中与传统清洁设备厂商ICE合作的中型清洁机器人Cobi18,已在全球十几个国家批量部署,且在欧美市场实现运行零故障。
审核编辑 黄宇
-
机器人
+关注
关注
210文章
28187浏览量
206418 -
激光雷达
+关注
关注
967文章
3937浏览量
189566 -
VSLAM
+关注
关注
0文章
23浏览量
4308 -
INDEMIND
+关注
关注
1文章
29浏览量
3576
发布评论请先 登录
相关推荐
【书籍评测活动NO.51】具身智能机器人系统 | 了解AI的下一个浪潮!
TE Connectivity 赋能下一代服务机器人

工业机器人视觉技术的应用分为哪几种?
Al大模型机器人
机器人视觉的应用范围

基于FPGA EtherCAT的六自由度机器人视觉伺服控制设计
TE Connectivity无线连接方案,赋能下一代服务机器人的革新未来
银牛微电子3D视觉感知方案赋能小米CyberDog系列仿生四足机器人
AMR机器人如何赋能智慧物流?

视觉、激光、结构光?扫地机器人导航避障技术盘点
机器人基于开源的多模态语言视觉大模型

富唯智能机器人集成了协作机器人、移动机器人和视觉引导技术
基于视觉的自主导航移动抓取机器人搭建方案





 工商网监
工商网监
评论