 昇腾910和含光800性能对比
昇腾910和含光800性能对比
有网友问昇腾910和含光800性能对比;华为推出的昇腾910性能强大,而含光800则是阿里巴巴发布的含光800AI芯片。
2019年9月25日,阿里巴巴发布含光800AI芯片;含光800是高性能的AI推理芯片。该芯片推理性能达到78563 IPS,能效比500 IPS/W。
含光800AI芯片基于RISC-V和阿里自有算法,含光800芯片性能的突破得益于软硬件的协同创新:硬件层面采用自研芯片架构,通过推理加速等技术有效解决芯片性能瓶颈问题;软件层面集成了达摩院先进算法,针对CNN及视觉类算法深度优化计算、存储密度,可实现大网络模型在一颗NPU上完成计算。
含光800AI芯片相比传统GPU算力,性价比提升100%。根据云栖大会的现场演示结果显示,比如拍立淘商品库每天新增10亿商品图片,使用传统GPU算力识别需要1小时,使用含光800后可缩减至5分钟。
据阿里介绍含光NPU采用TSMC 12nm工艺制程,可提供全球最高单芯片AI推理性能。 在HGAI模型的推理应用中,含光NPU每秒钟可处理高达78000 IPS的图片,是同类处理器的数十倍性能。
目前含光800目前已被应用到阿里巴巴旗下的的多个业务场景,比如图像视频分析、城市大脑、搜索优化等等。
2019年8月23日,华为发布AI芯片Ascend 910(昇腾910)。
据华为官方介绍,昇腾910AI处理器,基于自研华为达芬奇架构3D Cube技术,实现业界最佳AI性能与能效,架构灵活伸缩,支持云边端全栈全场景应用。
除了基于达芬奇架构的AI核外,昇腾910还集成了多个CPU、DVPP和任务调度器(Task Scheduler),因而具有自我管理能力,可以充分发挥其高算力的优势。
昇腾910集成了HCCS、PCIe 4.0和RoCE v2接口,为构建横向扩展(Scale Out)和纵向扩展(Scale Up)系统提供了灵活高效的方法。HCCS是华为自研的高速互联接口,片内RoCE可用于节点间直接互联。最新的PCIe 4.0的吞吐量比上一代提升一倍。
昇腾910算力是国际顶尖AI芯片的2倍,相当50个当前最新最强的CPU;其训练速度,也比当前最新最强的芯片提升了50%-100%。同时华为还发布了配套的新一代AI开源计算框架MindSpore。两者搭配性能最大化利用芯片算力。
新一代的AI开源计算框架MindSpore创新编程范式,使得工程师更容易使用;该计算框架可满足终端、边缘计算、云全场景需求,能更好保护数据隐私;可开源,形成广阔应用生态。
昇腾910半精度(FP16)算力达256 TFLOPS。(还有一个说法是昇腾910的半精度(FP16)算力达到320 TFLOPS);而整数精度(INT8)算力达到 640 TOPS,(还有一个说法是整数精度(INT8)算力达到512 Tera-OPS;小编认为一个数值可能是设计参数值,一个可能是极值)功耗 310W,采用 7nm 先进工艺。此外,昇腾 910 集成了 HCCS、PCIe 4.0 和 RoCE v2 接口,为构建横向扩展 (Scale Out)和纵向扩展(Scale Up)系统提供了灵活高效的方法。
比如华为的Atlas 900 AI训练集群,算力达到了256 PFLOPS。要实现这样的算力,如果采用通用CPU需要6195个机柜,用GPU需要208个机柜,而NPU如昇腾只要128个机柜,这归功于昇腾架构对深度学习业务的优化。而且最终,华为只用了16个机柜来实现。
此外,昇腾910为国产AI芯片助力,华为盘古大模型从算力(昇腾算力,昇腾的底层架构也是华为自创的)、芯片使能、AI框架(MindSpore AI计算框架)到AI平台(AI开发生产线ModelArts)实现了全栈自主创新。
-
gpu
+关注
关注
28文章
4828浏览量
129744 -
NPU
+关注
关注
2文章
300浏览量
18961 -
AI芯片
+关注
关注
17文章
1925浏览量
35384 -
昇腾910
+关注
关注
0文章
14浏览量
6878 -
含光800
+关注
关注
0文章
3浏览量
1726
发布评论请先 登录
相关推荐
润和软件将持续深化“昇腾+DeepSeek”技术路线

昇腾推理服务器+DeepSeek大模型 技术培训在图为科技成功举办

华为推出昇腾DeepSeek大模型一体机
迅龙软件出席华为昇腾APN伙伴大会,获昇腾APN钻石伙伴授牌及两项大奖

喜讯 英码科技受邀出席华为昇腾APN伙伴大会,正式成为「昇腾钻石部件伙伴」,喜获多个重磅奖项!

谷东科技民航维修智能决策大模型荣获华为昇腾技术认证
研华发布高性能工业边缘 AI 算力方案 携手昇腾引领边缘 AI 革新

中软国际荣膺华为昇腾万里伙伴计划认证级应用软件伙伴证书
昇腾与昇思原生,助力智谱打造自主创新大模型体系!

香橙派亮相昇腾AI开发者创享日,打造“AI+鸿蒙”高算力开发板

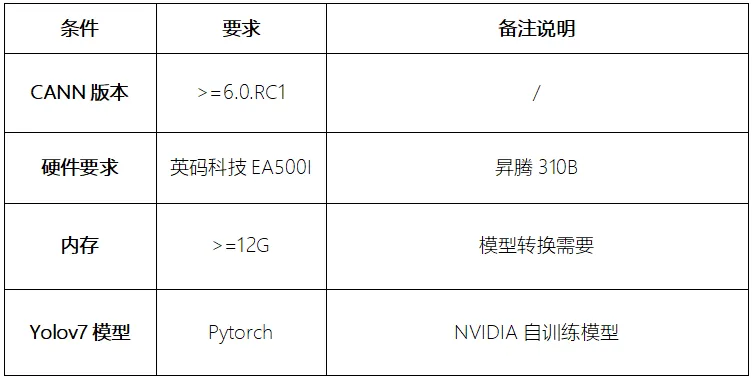
基于昇腾AI Yolov7模型迁移到昇腾平台EA500I边缘计算盒子的实操指南
英码科技受邀参加鲲鹏昇腾南北双峰会, 共同打造数智化新质生产力!
华为发布会大模型翻车?昇腾社区回应!





 工商网监
工商网监
评论