 NCNN在Core3566模组上的部署和测试
NCNN在Core3566模组上的部署和测试
得益于四核A55的性能,NCNN跑起来应该问题不大,本文主要介绍NCNN在Core3566 模组上的部署和测试。
一、NCNN介绍
ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架。 ncnn 从设计之初深刻考虑手机端的部署和使用。 无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。 基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行, 开发出人工智能 APP,将 AI 带到你的指尖。 ncnn 目前已在腾讯多款应用中使用,如:QQ,Qzone,微信,天天 P 图等。
ncnn: NCNN是腾讯优图实验室首个开源项目,是一个为手机端极致优化的高性能神经网络前向计算框架。
二、源码下载&编译
(一)源码下载
在NCNN的github(github.com/Tencent/ncnn)拉源码。
linaro@linaro-alip:/userdata$ sudo git clone https://github.com/Tencent/ncnn.git
Cloning into 'ncnn'...
remote: Enumerating objects: 32651, done.
remote: Counting objects: 100% (5798/5798), done.
remote: Compressing objects: 100% (309/309), done.
remote: Total 32651 (delta 5637), reused 5500 (delta 5489), pack-reused 26853
Receiving objects: 100% (32651/32651), 22.79 MiB | 8.51 MiB/s, done.
Resolving deltas: 100% (27724/27724), done.
Checking out files: 100% (3285/3285), done.
linaro@linaro-alip:/userdata$
(二)源码编译
考虑到四核A55的能力,加上NCNN本身也支持板上直接编译,所以就不去PC上搞交叉编译了。
Debian包自带gcc,所以就不需要在Core3566 模组编译安装了,顶多更新下。
linaro@linaro-alip:/userdata$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/aarch64-linux-gnu/8/lto-wrapper
Target: aarch64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Debian 8.3.0-6' --with-bugurl=file:///usr/share/doc/gcc-8/README.Bugs --enable-languages=c,ada,c++,go,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-8 --program-prefix=aarch64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-bootstrap --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-libquadmath --disable-libquadmath-support --enable-plugin --enable-default-pie --with-system-zlib --disable-libphobos --enable-multiarch --enable-fix-cortex-a53-843419 --disable-werror --enable-checking=release --build=aarch64-linux-gnu --host=aarch64-linux-gnu --target=aarch64-linux-gnu
Thread model: posix
gcc version 8.3.0 (Debian 8.3.0-6)
按照下面步骤的顺序:
cd < ncnn-root-dir >
mkdir -pbuild-aarch64-linux-gnu
cdbuild-aarch64-linux-gnu
cmake -DCMAKE_TOOLCHAIN_FILE=../toolchains/aarch64-linux-gnu.toolchain.cmake ..
make -j$(nproc)
操作及log如下:
可以看出编译还是很耗资源。
最终生成了可执行程序。
linaro@linaro-alip:/userdata/ncnn/build-aarch64-linux-gnu$ file benchmark/benchncnn
benchmark/benchncnn: ELF 64-bit LSB pie executable, ARM aarch64, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, for GNU/Linux 3.7.0, BuildID[sha1]=16473ecd5c28b183841b2925c3d87c7cd23a060e, not stripped
linaro@linaro-alip:/userdata/ncnn/build-aarch64-linux-gnu$
三、测试
将生成的可执行文件拷贝到原目录的benchmark/文件夹中,因为这里面有测试需要的模型数据。

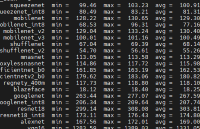
执行一下,几个模型测试都跑个遍:
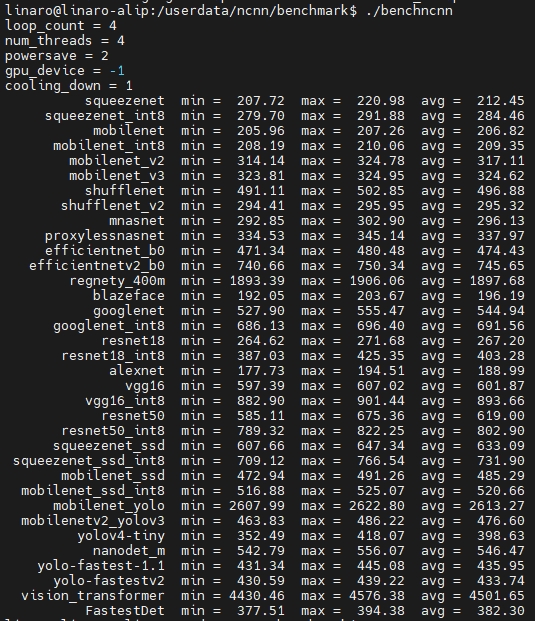
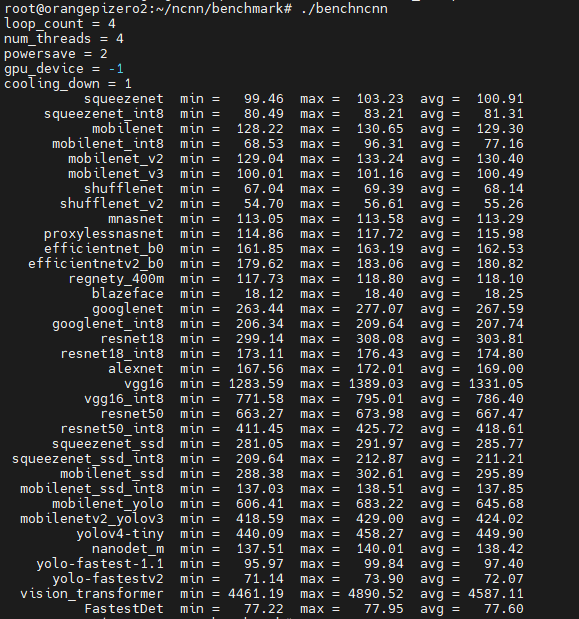
得分数据还是比较能反映RK3566的实力,基本上每项都是H616得分的2倍。贴个H616的测试分数,对比下。
-
AI
+关注
关注
87文章
30946浏览量
269186 -
人工智能
+关注
关注
1791文章
47314浏览量
238603 -
源码
+关注
关注
8文章
642浏览量
29226 -
模组
+关注
关注
6文章
1496浏览量
30405
发布评论请先 登录
相关推荐

【幸狐Core3566模组试用体验】Linux系统烧写和体验

在AvaotaA1全志T527开发板上部署ncnn
如何在RK3308嵌入式开发板上使用ncnn部署mobilenetv2_ssdlite模型呢
【芒果派MangoPi MQ Quad】NCNN在MangoPi MQ Quad上的部署和测试
【幸狐 Core3566 模组试用体验】幸狐 Core3566 模组开箱
【幸狐 Core3566 模组试用体验】Linux系统烧写和体验
【幸狐 Core3566 模组试用体验】基于openCV的猫脸识别
【幸狐 Core3566 模组试用体验】RK3566的CoreMark
【幸狐 Core3566 模组试用体验】开箱篇
【幸狐 Core3566 模组试用体验】EMMC烧写镜像
【幸狐 Core3566 模组试用体验】NCNN在Core3566 模组上的部署和测试

NCNN在MangoPi MQ Quad上的部署和测试





 工商网监
工商网监
评论