 介绍一款基于昆仑芯AI加速卡的高效模型推理部署框架
介绍一款基于昆仑芯AI加速卡的高效模型推理部署框架
引言
昆仑芯科技公众号全新栏目“用芯指南”重磅推出!面向AI行业技术从业者,系列好文将提供手把手的昆仑芯产品使用指南。第一期围绕昆仑芯自研效能工具——昆仑芯Anyinfer展开,这是一款基于昆仑芯AI加速卡的高效模型推理部署框架。种种行业痛点,昆仑芯Anyinfer轻松搞定。
当下,AI技术蓬勃发展,AI算法应用需求井喷。行业技术从业者在项目的不同阶段面临种种现实问题,这些问题无疑也增加了项目的复杂性和不确定性:
算法选型:
技术从业者极有可能遇到不同框架格式的算法模型;即便是同一个开源算法的实现,也可能是经过不同训练框架导出,因此模型的保存格式也会有所不同。
算法验证:
想在AI加速卡上评估算法的推理效果,就要针对不同推理框架的接口构造上百行代码的推理程序;如果效果不达预期,可能还需要更换其他框架的模型,这就需要重新构造一份不同的推理程序......
真正到了算法部署阶段,则将迎来更加严峻的挑战。
以上种种业内痛点,是否也在困扰您?看完这篇,基于昆仑芯AI加速卡的高效模型推理部署框架——昆仑芯Anyinfer,帮您一键全搞定!
1昆仑芯Anyinfer
1.昆仑芯Anyinfer架构图
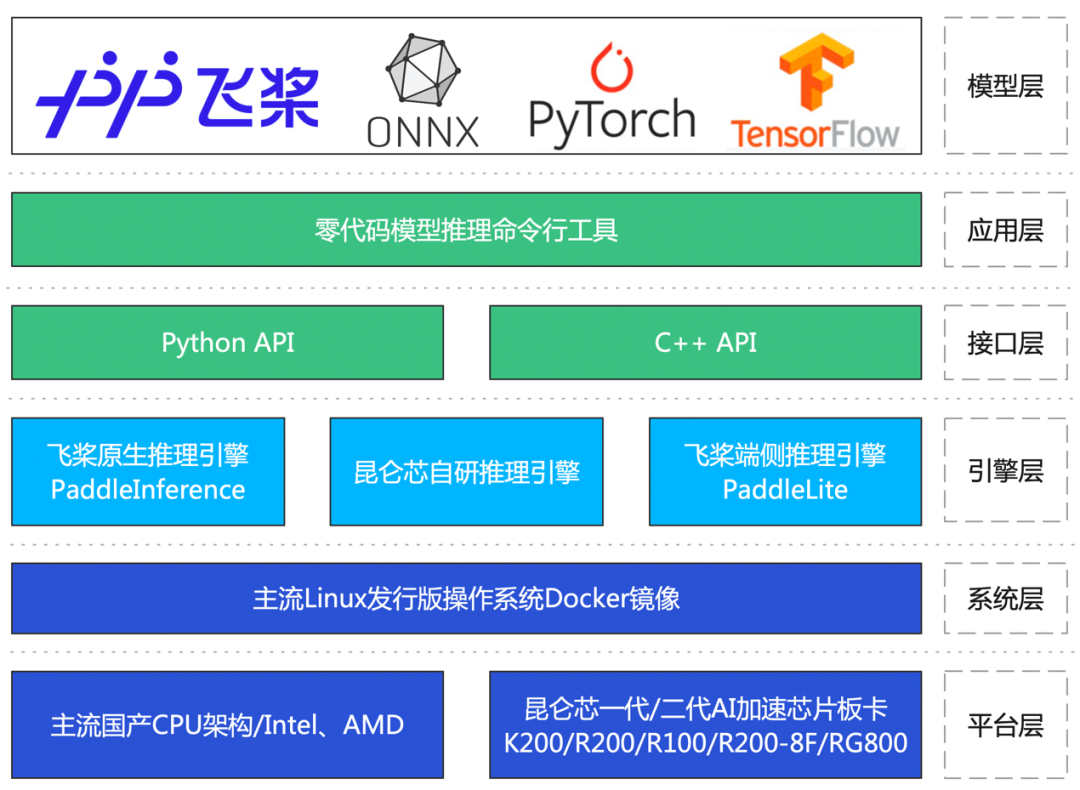
2.昆仑芯Anyinfer核心优势
A强兼容性
在多个平台上支持零代码推理PaddlePaddle、PyTorch、ONNX、TensorFlow等多个主流框架格式的众多领域模型。
B高人效
内置多款推理引擎,针对不同领域,用户无需学习特定框架编程接口,更不用编写多份推理程序,零代码验证模型在不同框架中的效果。
C零代码
只需一行命令,即可完成模型验证评估,无需依据模型构建输入数据,也无需撰写模型转换、前后处理及推理脚本代码。
D部署友好
支持C++与Python两套接口逻辑统一的API,用户在生产环境中部署模型更方便。
2运行演示
1. 快速完成算法模型验证评估
一行命令,即可轻松验证模型精度、一键评估模型的推理性能等关键指标。
AONNX、PyTorch和TensorFlow模型在昆仑芯AI加速卡和CPU上的计算精度对比
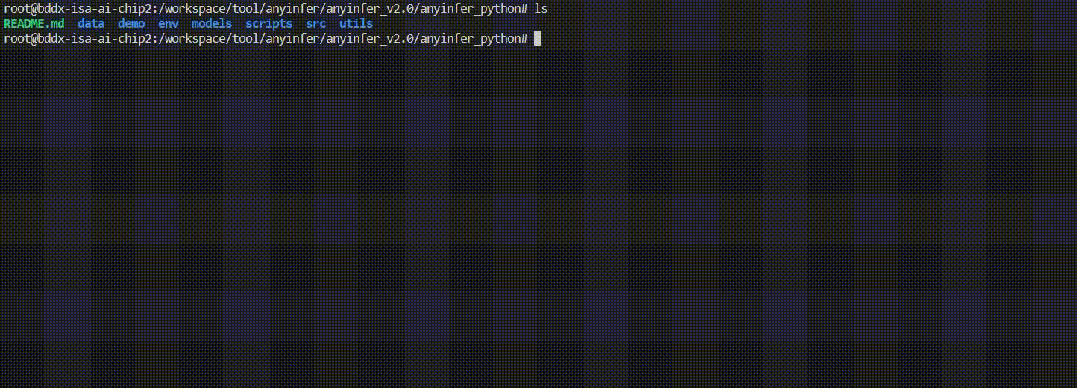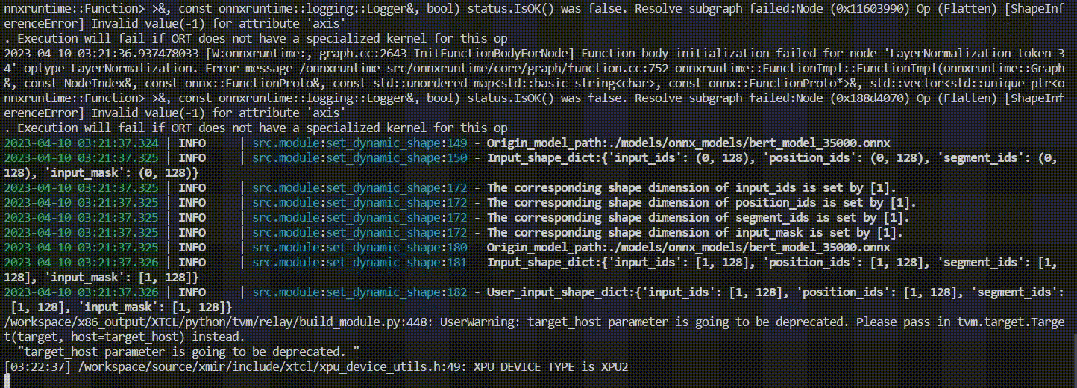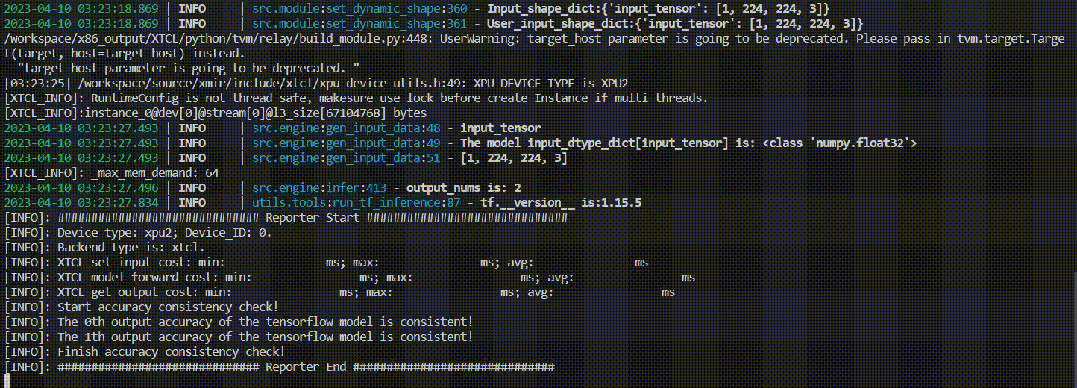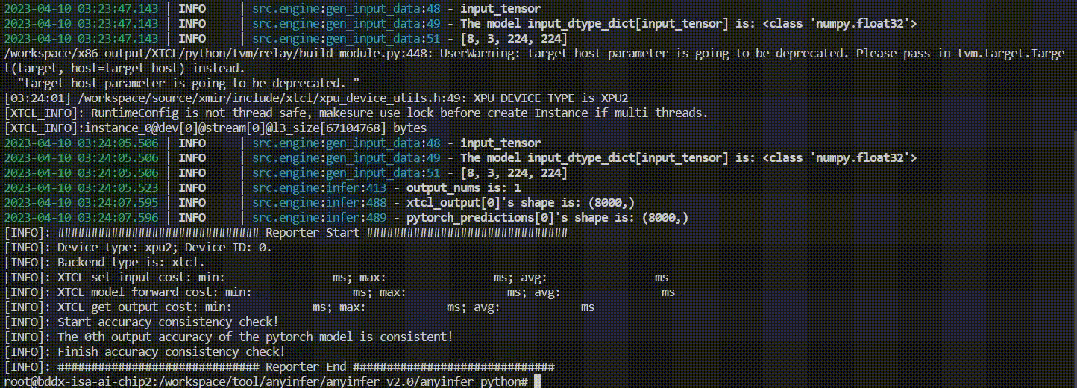
BPaddlePaddle模型在昆仑芯AI加速卡上的推理性能统计

2.获取模型性能分析报告,为下一步模型优化做足准备
在初步完成算法模型的验证评估后,可利用昆仑芯Anyinfer深入研究模型中各个层面的性能,包括推理框架层面和算子执行层面等,助力进一步调优模型的推理性能。

一键开启昆仑芯自研推理引擎的性能分析模式,统计框架层和算子层面的计算耗时

一键开启Paddle inference的性能分析模式,统计框架层和算子层面的耗时
3. 模型的基础性能调优
完成对模型的性能评估后,可以使用基础的调优方法来提高模型的推理性能。昆仑芯Anyinfer提供了一项非常便捷的功能:最佳QPS搜索。此功能将以往需要修改多个参数并多次执行的操作化繁为简,快速确定最适合项目需求的配置,提高用户体验。

搜索最佳QPS
4. 模型的高性能部署
完成算法模型的验证后,最关键的一步来了!昆仑芯Anyinfer可轻松应对生产环境部署这一挑战。仅需三个统一的C++接口,即可顺利将验证后的模型部署至生产环境中。
此外,昆仑芯Anyinfer还提供了方便的调试功能,例如算子的自动精度对比、模型转换等。同时,也提供了丰富的使用示例,包括多输入、多线程、多进程、多流推理等。种种行业痛点,昆仑芯Anyinfer轻松搞定。简洁而强大的解决方案,帮您把模型推理部署变得简单、高效。
目前,昆仑芯Anyinfer已在多个行业客户中投入使用,切实降低了行业客户人力成本,提高了项目交付效率,助力客户在行业竞争中取得领先优势。
审核编辑:汤梓红
-
算法
+关注
关注
23文章
4629浏览量
93275 -
AI
+关注
关注
87文章
31493浏览量
270150 -
模型
+关注
关注
1文章
3298浏览量
49163 -
昆仑芯科技
+关注
关注
0文章
28浏览量
644
原文标题:一键搞定!昆仑芯Anyinfer助您零代码实现昆仑芯AI加速卡模型推理
文章出处:【微信号:昆仑芯科技,微信公众号:昆仑芯科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大模型向边端侧部署,AI加速卡朝高算力、小体积发展
EdgeBoard FZ5 边缘AI计算盒及计算卡
Dllite_micro (轻量级的 AI 推理框架)
MLU220-M.2边缘端智能加速卡支持相关资料介绍
压缩模型会加速推理吗?
LCD转VGA视频加速卡
基于NVIDIA Triton的AI模型高效部署实践

昆仑芯完成OpenCloudOS社区首个兼容性认证,软硬协同加速AI技术落地
HPC领域的一款大杀器-HBX-G500大带宽加速卡

瞬变对AI加速卡供电的影响





 工商网监
工商网监
评论