 普罗米修斯:接近完美的监控系统
普罗米修斯:接近完美的监控系统
普罗米修斯(Prometheus)是一个SoundCloud公司开源的监控系统。当年,由于SoundCloud公司生产了太多的服务,传统的监控已经无法满足监控需求,于是他们在2012年决定着手开发新的监控系统,即普罗米修斯。
普罗米修斯(下称普罗)的作者 Matt T.Proud 在2012年加入SoundCloud公司,他从google的监控系统Borgmon中获得灵感,与另一名工程师Julius Volz合作开发了开源的普罗,后来其他开发人员陆续加入到该项目,最终于2015年正式发布。
普罗基于Go语言开发,其架构图如下:
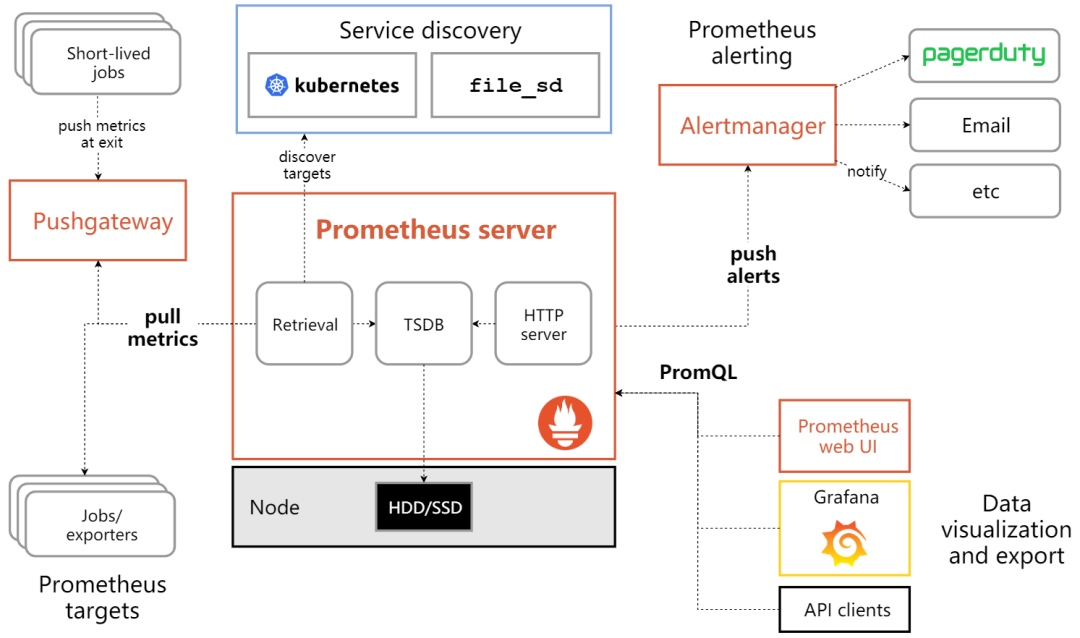
其中:
- Prometheus Server: 用数据的采集和存储,PromQL查询,报警配置。
- Push gateway: 用于批量,短期的监控数据的汇报总节点。
- Exporters: 各种汇报数据的exporter,例如汇报机器数据的node_exporter,汇报MondogDB信息的 MongoDB_exporter 等等。
- Alertmanager: 用于高级通知管理。
1.怎么采集监控数据?
要采集目标(主机或服务)的监控数据,首先就要在被采集目标上安装采集组件,这种采集组件被称为Exporter。prometheus.io官网上有很多这种exporter,比如:
Consul exporter ( official )
Memcached exporter ( official )
MySQL server exporter ( official )
Node/system metrics exporter ( official )
HAProxy exporter ( official )
RabbitMQ exporter
Grok exporter
InfluxDB exporter ( official )
这些exporter能为我们采集目标的监控数据,然后传输给普罗米修斯。这时候,exporter会暴露一个http接口,普罗米修斯通过HTTP协议使用Pull的方式周期性拉取相应的数据。
不过,普罗也提供了Push模式来进行数据传输,通过增加 Push Gateway这个中间商实现 ,你可以将数据推送到Push Gateway,普罗再通过Pull的方式从Push Gateway获取数据。
这就是为什么你从架构图里能看到两个 Pull metrics 的原因,一个是采集器直接被Server拉取数据(pull);另一个是采集器主动Push数据到Push Gateway,Server再对Push Gateway主动拉取数据(pull)。
采集数据的主要流程如下:
- Prometheus server 定期从静态配置的主机或服务发现的 targets 拉取数据(zookeeper,consul,DNS SRV Lookup等方式)
- 当新拉取的数据大于配置内存缓存区的时候,Prometheus会将数据持久化到磁盘,也可以远程持久化到云端。
- Prometheus通过PromQL、API、Console和其他可视化组件如Grafana、Promdash展示数据。
- Prometheus 可以配置rules,然后定时查询数据,当条件触发的时候,会将告警推送到配置的Alertmanager。
- Alertmanager收到告警的时候,会根据配置,聚合,去重,降噪,最后发出警告。
2.采集的数据结构与指标类型
2.1 数据结构
了解普罗米修斯的数据结构对于了解整个普罗生态非常重要。普罗采用键值对作为其基本的数据结构:
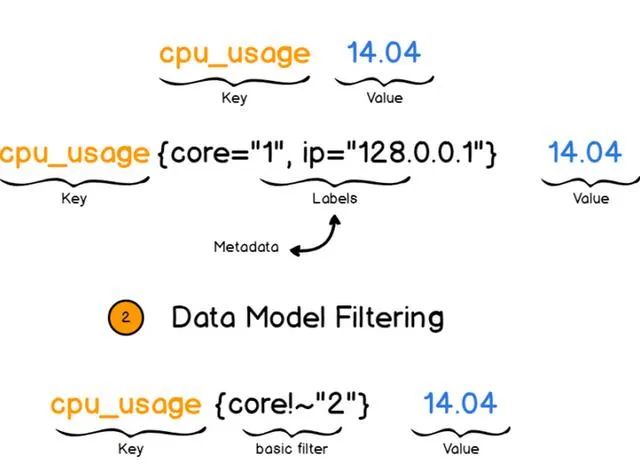
Key是指标名字,Value是该指标的值,此外Metadata(元信息)也非常重要,也可称之为labels(标签信息)。这些标签信息指定了当前这个值属于哪个云区域下的哪台机器,如果没有labels,数据有可能会被丢失。
2.2 指标类型
普罗米修斯的监控指标有4种基本类型:
1 . Counter (计数器 ):
计数器是我们最简单的指标类型。比如你想统计某个网站的HTTP错误总数,这时候就用计数器。
计数器的值只能增加或重置为0,因此特别适合计算某个时段上某个时间的发生次数,即指标随时间演变发生的变化。
2.Gauges
Gauges可以用于处理随时间增加或减少的指标,比如内存变化、温度变化。
这可能是最常见的指标类型,不过它也有一定缺点:如果系统每5秒发送一次指标,普罗服务每15秒抓取一次数据,那么这期间可能会丢失一些指标,如果你基于这些数据做汇总分析计算,则结果的准确性会有所下滑。
3.Histogram(直方图 )
直方图是一种更复杂的度量标准类型。它为我们的指标提供了额外信息,例如观察值的总和及其数量,常用于跟踪事件发生的规模。
比如,为了监控性能指标,我们希望在有20%的服务器请求响应时间超过300毫秒时发送告警。对于涉及比例的指标就可以考虑使用直方图。
4.Summary(摘要)
摘要更高级一些,是对直方图的扩展。除了提供观察的总和和计数之外,它们还提供滑动窗口上的分位数度量。分位数是将概率密度划分为相等概率范围的方法。
对比直方图:
- 直方图随时间汇总值,给出总和和计数函数,使得易于查看给定指标的变化趋势。
- 而摘要则给出了滑动窗口上的分位数(即随时间不断变化)。
3.实例概念
随着分布式架构的不断发展和云解决方案的普及,现在的架构已经变得越来越复杂了。
分布式的服务器复制和分发成了日常架构的必备组件。我们举一个经典的Web架构,该架构由3个后端Web服务器组成。在该例子中,我们要监视Web服务器返回的HTTP错误的数量。
使用普罗米修斯语言,单个Web服务器单元称为实例(主机实例)。该任务是计算所有实例的HTTP错误数量。

事实上,这甚至可以说是最简单的架构了,再复杂一点,实例不仅能是主机实例,还能是服务实例,因此你需要增加一个instance_type的标签标记主机或服务。
再再复杂一点,同样的IP,可能存在于不同云区域下,这属于不同的机器,因此还需要一个cloud标签,最终该数据结构可能会变为:
cpu_usage {job="1", instance="128.0.0.1", cloud="0", instance_type="0"}
4.数据可视化
如果使用过基于InfluxDB的数据库,你可能会熟悉InfluxQL。普罗米修斯也内置了自己的SQL查询语言用于查询和检索数据,这个内置的语言就是PromQL。
我们前面说过,普罗米修斯的数据是用键值对表示的。PromQL也用相同的语法查询和返回结果集。
PromQL会处理两种向量:
即时向量:表示当前时间,某个指标的数据向量。
时间范围向量:表示过去某时间范围内,某个指标的数据向量。
如针对8核CPU的使用率:
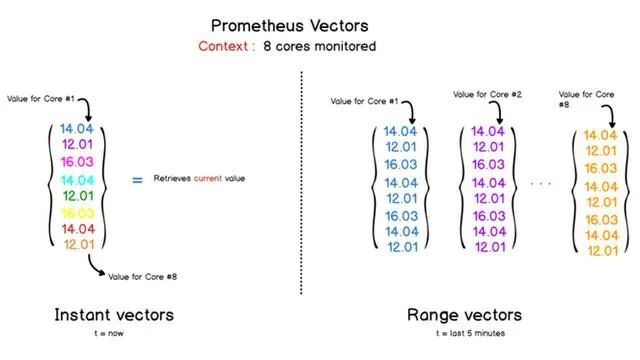
知道怎么提取数据后,可视化数据就简单了。
Grafana是一个大型可视化系统,功能强大,可以创建自己的自定义面板,支持多种数据来源,当然也支持普罗米修斯。
通过配置数据源,Grafana会使用相应的SQL拉取并绘制图表,能直接看到普罗米修斯的各个指标数据图表:
更方便的是,Grafana有很多仪表盘模板供你使用,只要import模板进行简单的配置,就能得到以下效果:
5.应用前景
普罗米修斯非常强大,可以应用到各行各业。
5.1 DevOps
为了观察整个服务体系是否在正常运转,运维非常需要监控系统。在实例的创建速度和销毁速度一样快的容器世界中,灵活配置各类容器的监控项并迅速安装启动监控是非常重要的。
5.2 金融行业
金融服务巨头Northern Trust于2017年6月选择普罗米修斯,不是为了进行应用程序的监视,而是为了更好地了解其某些硬件的运作情况。Northern Trust使用普罗米修斯监控其平台上的750多种微服务。
5.3 汽车行业
Life360是一款用于定位、行车安全和家庭成员之间共享信息的移动应用程序,他们需要给用户提供稳定的定位服务,而原有的监控方案都非常局限,无法监视到所有组件的工作状态。
因此该公司使用普罗米修斯来监视其MySQL多主群集和一个12节点的Cassandra环,该环可容纳约4TB的数据。普罗米修斯在初步测试中表现良好。
在普罗米修斯的有限部署之后,Life360报告了监控方面的巨大进步,并设想在其数据中心基础架构的其他部分中使用它。
总而言之,普罗米修斯这样的分布式监控系统,在未来的世界中用处可能会越来越大,它或许将会成为监控领域寡头式的存在,希望我们能熟悉这个工具,并在以后的架构和实践中使用它解决系统和应用监控的问题。
-
数据
+关注
关注
8文章
7193浏览量
89824 -
存储
+关注
关注
13文章
4367浏览量
86260 -
监控系统
+关注
关注
21文章
3949浏览量
177649 -
开源
+关注
关注
3文章
3421浏览量
42785
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论