 C语言开发如何将错误扼杀在编译阶段
C语言开发如何将错误扼杀在编译阶段

你有没有想过,C语言一些简单的语法规则,可以做出很巧妙的方法。
举个例子,C语言的数组长度是不允许是负数的,当然常识中数组长度为负数好像也没什么意义。
例如int arr[1];是对的,而int arr[-1];是错的。
这个规则很简单,也很容易理解,当然也不会引人关注。
但是呢,我说可以用这个语法规则做C语言assert断言错误检查,你信么?优秀的程序员,一般都是想尽一切办法将程序的错误尽可能地被拦截在运行之前,即编译阶段和预编译阶段的,而不是流出到运行阶段,更不是发生在用户手里的产品中。对于预编译阶段的错误拦截,比较简单,通过#if和#error等预编译指令就可以做到,例如1. FreeRTOS中的Priority检查,用户必须将优先级定义大于或等于1,否则就报错
这是因为,程序设计里如果遇到configMAX_PRIORITIES < 1的情况,可能会导致更严重的错误。
所以这种在预编译阶段拦截了这个错误,是很有作用的2. FreeRTOS中的运行时状态获取函数,必须依赖于configUSE_TRACE_FACILITY的定义
void vTaskGetRunTimeStats( char *pcWriteBuffer )
{
TaskStatus_t *pxTaskStatusArray;
UBaseType_t uxArraySize, x;
uint32_t ulTotalTime, ulStatsAsPercentage;
{
}
因为,这个函数很依赖其他其他的函数实现或者资源定义,那么这个configUSE_TRACE_FACILITY管理了这些
3. 版本检查,如果你设计一个比较通用的功能,可以用到很多项目中去,为了方便管理和迭代更新,就要对这个功能模块做版本定义。那么不同版本之间就存在差异,可能存在不兼容的情况,此时就可以用预编译指令做这种兼容的检查
通过预编译指令来检查错误是很有限的,因为预编译指令能检查的是立即数和一些逻辑关系。于是,我们还要考虑编译阶段的错误检查,即对在编译阶段产生的结果做检查。例如,unsigned long或者void*的长度检查即sizeof(unsignedlong)或sizeof(void*)的值,就必须在编译阶段由于unsigned long和void*的长度在不同芯片架构上可能存在差异,如果你的程序依赖这个类型的长度,那必须要检查其长度是否为你设计的那样。像这种#if sizeof(unsigned long) == 4是不正确的做法,因为预编译无法计算sizeof(unsigned long)那么有没有一种情况能确保sizeof(unsigned long)的值是4才不出错呢?也许你会想到一个叫assert的东西,例如FreeRTOS里面定义的
既可以这样使用configASSERT(sizeof(unsigned long) == 4),如果sizeof(unsignedlong) == 4,那么程序是“静悄悄”的,当做啥事都没发生,但是如果sizeof(unsigned long) == 8,那么程序就会进入for( ;; );无法自拔。但是这种做法是运行阶段的,必须要在程序已经集成好并让其在实际环境中运行才能发现这种错误,排查起来成本还是有点高。那么有没有一种办法可以让其扼杀在编译阶段呢?答案是有的,像C++11和C11就支持这种assert了,名叫STATIC_ASSERT,需要包含头文件assert.h。但是,如果我还没用到C11,也想用这种STATIC_ASSERT呢,有没有办法自己实现一个?答案也是可以的,需要想个窍门,例如从数组的长度入手。像int arr[1];这种定义是没有问题的,但int arr[-1];却是会引起编译器报错的,我们就可以基于这种东西做文章了,即将数组长度换成检查条件COND,即如果COND为TRUE就不报错,为FALSE就报错通过一顿反复尝试,搞成这样或许就可以了
int arr[(!!(COND))*2-1];
这里(!!(COND))*2-1没有一个符号是多余的,简单解释下:1.(COND),这里加了一层括号,防止COND是个比较复杂的表达式,可能引发未知的优先级问题;2.(!!(COND)),这里有两个感叹号,即逻辑取反再取反。也许你会觉得有点奇怪,!!TRUE不就是TURE吗,!!FALSE也是FALSE啊,双层取反是不是有点多余。那你就要认真思考下TRUE和FALSE的定义了,C语言中的FALSE是0,而非0是TRUE,这个非0就有很多发挥空间了,例如整数100,也是TRUE,但是!!100就会变成1,这里的(!!(COND))就是让其结果变成0或者1,而不是其他数。3.通过2的解释,就很容易理解(!!(COND))*2-1这可以保证这个结果是1或者-1,而不存在其他数值。因为,我们的目的要的是int arr[1];或者int arr[-1];即可。
定义一个数组用在程序中间好像用起来没那么友好,可以换成
typedef int arr[(!!(COND))*2-1];
为了还能看到多一点点错误信息,还可以将其定义成宏,并带多一个参数,这就成了这样
defineSTATIC_ASSERT(COND,MSG)typedefchar static_assertion_##MSG[(!!(COND))*2-1]
在这个基础上再搞定其他的,就可以这样了
// token pasting madness:
接着,判断sizeof(unsigned long) 是否为4,就可以这样
STATIC_ASSERT(sizeof(unsignedlong)==4,unsigned_long_size_is_not_4_error);
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
C语言
+关注
关注
183文章
7646浏览量
146205 -
C++
+关注
关注
22文章
2131浏览量
77425 -
编译
+关注
关注
0文章
696浏览量
35297
原文标题:C语言开发如何将错误扼杀在编译阶段
文章出处:【微信号:embedded_sw,微信公众号:嵌入式软件实战派】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
Rust语言中错误处理的机制
在Rust语言中,错误处理是一项非常重要的任务。由于Rust语言采用静态类型检查,在编译时就能发现很多潜在的错误,这使得程序员能够更加自信和
如何将高级C语言编译成机器码
器各个阶段做得事情,这里不做详细介绍,感兴趣的粉丝可以自己找资料学习。C语言的编译器有很多种,在我们芯片行业,主要有GCC和LLVM。下面框图简单的描述了一个CPU
发表于 06-01 16:53
C语言编译过程中的错误分析
语言的最大特点是:功能强、使用方便灵活。C编译的程序对语法检查并不象其它高级语言那么严格,这就给编程人员留下“灵活的余地”,但还是由于这个灵活给程序的调试
发表于 09-11 11:43
•1559次阅读
C语言编程时常犯的18种错误
C语言的最大特点是:功能强、使用方便灵活。C编译的程序对语法检查并不象其它高级语言那么严格,这就给编程人员留下“灵活的余地”,但还是由于这个
如何将C源代码从MPLAB C18编译器移植到MPLAB XC8C编译器的详细概述
本文档介绍了针对PIC18 MCU的MPLAB® C编译器(以前的说法,本文档称为MPLAB C18)与MPLAB XC8 C编译器间的差异
发表于 06-07 09:28
•30次下载

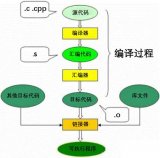
解析C语言编译过程中所做的工作
过程是有帮助的。而且清楚的了解编译链接过程还对我们在编程时定位错误,以及编程时尽量调动编译器的检测错误会有很大的帮助的。
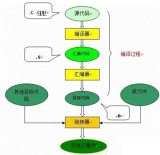
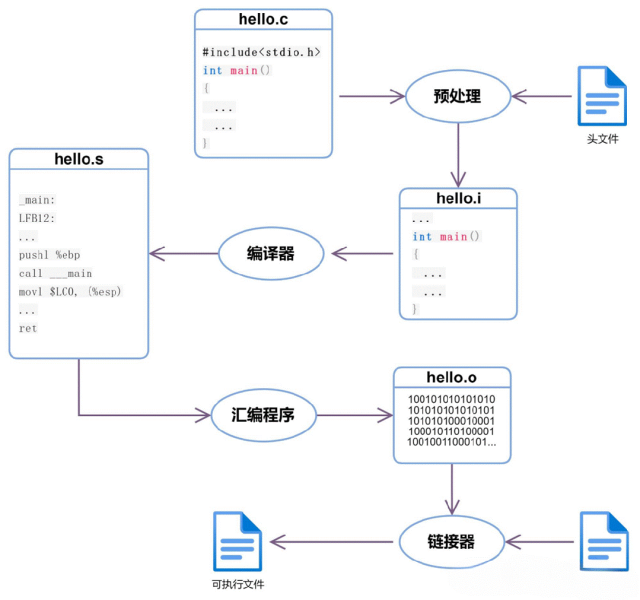
C语言关键字分别发生在哪个阶段
以下C语言关键字,分别发生在哪个阶段? 第一个,define。 首先得纠正一下,define 并不是C语言里面的关键字,即使加了井号,也不是



评论