 打通AI芯片到大模型训练的算力桥梁,开放加速设计指南强力助推
打通AI芯片到大模型训练的算力桥梁,开放加速设计指南强力助推
北京2023年10月17日/美通社/ -- 日前,2023全球AI芯片峰会(GACS 2023)在深圳市举行,AI芯片产业链顶尖企业、专家学者齐聚,围绕生成式AI与大模型算力需求、AI芯片高效落地等产业议题进行研讨分享。
面向大模型时代的计算需求,算力创新已不仅是单个处理器微架构和芯片工艺的突破,而需要产业携手进行软硬件全栈系统架构全面创新。当前各类AI芯片创新仍面临存储墙、功耗墙等架构痼疾,随着开放的通用指令架构、互联总线、AI加速器、开源的操作系统、模型框架、工具链和软件纷纷涌现,开放开源的算力系统创新,已经成为实现AI芯片转化为高效算力的二级引擎。
会上,浪潮信息分享了在开放加速计算系统领域的最新成果《开放加速规范AI服务器设计指南》,通过系统平台层面的技术创新,携手产业上下游加速生成式AI算力产业发展。

大模型推动算力产业步入系统级创新时代
随着制程工艺逼近天花板,AI芯片正迎来架构创新的黄金时代,诸多创新者正通过越来越广泛的创新思路来绕过摩尔定律濒临极限的瓶颈,围绕架构创新,AI芯片产业正从早期的百花齐放,向更深更多维层面发展。
与此同时,参数量高达数千亿的大模型创新往往需要在成百上千的AI服务器组成的平台上进行训练。面向AIGC的算力能力考量的不仅仅是单一芯片、或者是单一服务器,而是包含计算、存储、网络设备,软件、框架、模型组件,机柜、制冷、供电基础设施等在内的一体化高度集成的智算集群。
因此,要将AI芯片真正转化为大模型算力,需要产业链上下游携手从规模化算力部署的角度进行系统级创新,统筹考虑大模型训练需求特点,设计构建算力系统,以实现全局最优的性能、能效或TCO指标。
开放加速设计指南,打通从芯片到大模型的算力桥梁
2019年,开放计算组织OCP面向大模型训练发布了开放加速计算(OAI)技术标准,旨在促进上下游协同,降低产业创新成本和周期。开放加速计算(OAI)系统架构具备更高的散热和互联能力,可以承载具有更高算力的芯片,同时具备非常强的跨节点扩展能力。因为天然适用于大规模深度学习神经网络,已经在全球范围内得到芯片、系统及应用厂商的广泛参与支持。
大模型训练对开放加速计算系统的总功耗、总线速率、电流密度的需求不断提升,给系统设计带来了巨大的挑战。因此,浪潮信息基于系统研发和大模型工程实践经验,将从AI芯片到大模型算力系统所需完成的体系结构、信号完整性、散热、可靠性、架构设计等大量系统性设计标准进行细化总结,发布了面向生成式AI场景的《开放加速规范AI服务器指南》(以下简称《指南》),提出四大设计原则、全栈设计方法,包括硬件设计参考、管理接口规范和性能测试标准。
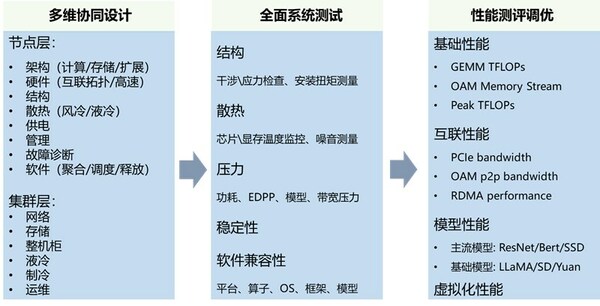
《开放加速规范AI服务器指南》全栈设计方法
《开放加速规范AI服务器指南》统筹考虑大模型分布式训练对于计算、网络和存储的需求特点,提供了从节点层到集群层的AI芯片应用部署全栈设计参考。包括各项硬件规范、电气规范、时序规范,并提供管理、故障诊断和网络拓扑设计等软硬协同参考,旨在通过节点层/集群层多维协同设计确保AI服务器节点和服务器集群以超大规模集群互连的大模型训练能力。
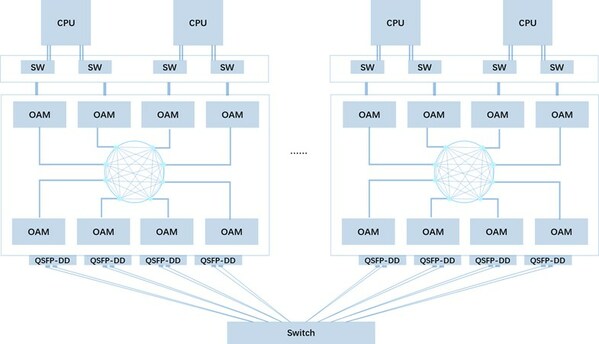
基于板端QSFP-DD的跨节点互连拓扑
由于架构复杂度高、芯片种类多、高速信号多、系统功耗大等特点,异构加速计算节点常面临故障率高的问题。因此,《指南》提供了详细的系统测试指导,对结构、散热、压力、稳定性、软件兼容性等方面的测试要点进行了全面梳理,帮助用户最大程度降低系统生产、部署、运行过程中的故障风险,提高系统稳定性,减少断点对训练持续性的影响。
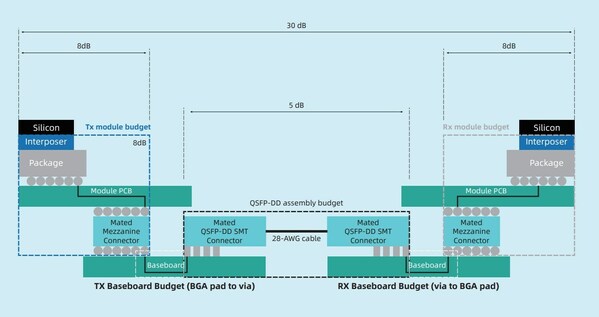
OAM互连信号损耗要求
不同于通用计算系统,面向生成式AI的加速计算系统具有软硬件强耦合特性。为了提高开放加速计算系统的算力可用性,《指南》给出了八类AI主流业务和三类AIGC大模型基准测评和调优方法,以确保开放加速计算系统能够有效支撑当前主流大模型的创新应用。
AI芯片厂商可以基于《指南》快速将符合开放加速规范的AI芯片落地成高可用高可靠高性能的大模型算力系统,提高系统适配和集群部署效率,减少芯片合作伙伴在系统层面的研发成本投入,加速生成式AI算力产业的创新步伐。
全栈协同,高效释放大模型创新生产力
目前,浪潮信息已经基于开放加速规范发布了三代AI服务器产品,和10余家芯片伙伴实现了多元AI计算产品的创新研发。多元算力产品方案得到了众多用户的认可,已经在多个智算中心应用落地,成功支持GPT-2、源1.0及实验室自研蛋白质结构预测等多个超大规模巨量模型的高效训练。
同时,为进一步解决大模型算力的系统全栈问题、兼容适配问题、性能优化问题等,浪潮信息基于大模型自身实践与服务客户的专业经验,推出OGAI大模型智算软件栈,能够为大模型业务提供AI算力系统环境部署、算力调度及开发管理的完整软件栈和工具链,帮助更多企业顺利跨越大模型研发应用门槛,充分释放大模型算力价值。
作为全球领先的AI算力基础设施供应商,浪潮信息将通过智算系统软硬件高度协同进行持续创新,携手产业伙伴加速AI算力繁荣发展并充分释放算力生产力,推动实现"助百模,智千行",加速生成式AI产业创新。
审核编辑 黄宇
-
芯片
+关注
关注
455文章
50697浏览量
423037 -
半导体
+关注
关注
334文章
27267浏览量
217952 -
AI
+关注
关注
87文章
30689浏览量
268848 -
算力
+关注
关注
1文章
963浏览量
14786 -
大模型
+关注
关注
2文章
2416浏览量
2628
发布评论请先 登录
相关推荐
《算力芯片 高性能 CPUGPUNPU 微架构分析》第3篇阅读心得:GPU革命:从图形引擎到AI加速器的蜕变
亿铸科技熊大鹏探讨AI大算力芯片的挑战与解决策略
如何训练自己的AI大模型
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
【「大模型时代的基础架构」阅读体验】+ 未知领域的感受
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南
万卡集群解决大模型训算力需求,建设面临哪些挑战

科大讯飞发布“讯飞星火V3.5”:基于全国产算力训练的全民开放大模型
Open AI进军芯片业技术突破与市场机遇

AGI时代的奠基石:Agent+算力+大模型是构建AI未来的三驾马车吗?





 工商网监
工商网监
评论