 聚焦PCIE3&4的接收端均衡技术
聚焦PCIE3&4的接收端均衡技术

PCIe接口自从被推出以来,已经成为了PC和Server上最重要的接口。为了更高了数据吞吐率,PCI-SIG组织不断刷新接口标准,从PCIe 3.0的8GT/s数据速率,到PCIe 4.0的16GT/s数据速率,再到PCIe 5.0的32GT/x。PCI-SIG组织实现了在速率翻倍的同时,仍能保持使用普通的FR4板材和廉价接插件,主要源自两个方面的改进,一是使用128b/130b编码来代替8b/10b编码,使得编码效率大幅提高;另一个是使用动态均衡技术,来代替先前代的静态均衡技术。
这里聚焦于PCIe 3.0和4.0中的动态均衡技术,介绍其原理、实现及其相关的一致性测试。这样一种动态均衡技术,在spec中被称作“Link Equalization”(链路均衡,简称为LEQ)。本系列文章分上下两篇,本文理论篇主要介绍PCIe 3.0/4.0的链路均衡的工作原理,下一篇实践篇则侧重于链路均衡的测试和调试。
PCIe 3.0 & 4.0的链路均衡
在PCIe 3.0和4.0中的链路均衡技术相较于先前代要复杂得多,这样一种动态均衡技术可以分为两个方面进行讨论。
均衡特性方面:从这个方面来说,相对于先前代的均衡来说,3.0和4.0中的均衡技术的硬件性能指标要求更高了。
协议方面:为了实现动态地调整均衡设置,需要协议层的配合,这是通过PHY层的LTSSM状态机中的Recovery.Equalization子状态来实现的。
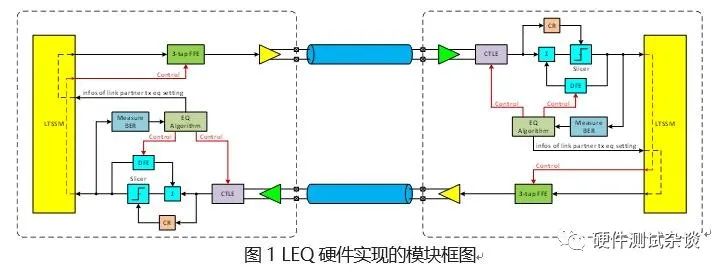
先来从均衡特性的角度来看看PCIe 3.0和4.0的均衡,如下展示了在PCIe 3.0/4.0中所使用的全部均衡技术,在Tx端有FFE(Feed Forward Equalizer,前馈均衡器);在Rx端有:CTLE(Continuous Time Linear Equalizer,连续时间线性均衡器)和DFE(Decision Feedback Equalizer,判决反馈均衡器)。通过FFE和CTLE,可以去除大部分由ISI所引入的抖动;通过DFE可以进一步去除ISI,它还能去除部分的阻抗失配所造成的反射。通过这些均衡处理,就能够最大程度上地保证在接收端判决输入处将眼图打开。
除了上述这些均衡特性上的支持外,在协议层(LTSSM)中还规定需要通过协议的方式来动态调整链路上的均衡设定值,这整个过程称作链路均衡(Link Equalization,LEQ)。在链路均衡过程中:
本地端按照某个初始Tx EQ的设定来发送数据;
对端在接收到数据时,会根据误码率或信号质量来判断该Tx EQ是否合适;
若不合适,对端会通过协议向本地端请求一个新的Tx EQ值;
本地端在接收到这个请求值之后,会改变Tx EQ的值。
通过这一动态过程,就能够保证链路上的Tx EQ为最优值。与此同时,本地端和对端也会同时调整Rx EQ。通过动态地调整Tx EQ和Rx EQ,就能够灵活地适应不同的信道情况。
发送端的均衡:FFE
在PCIe 3.0 & 4.0中使用的都是3-tap FFE,如图 2a所示。其中, 为数字信号,建模时取值为±1; 为FFE的抽头系数; 为发送端的模拟信号输出。
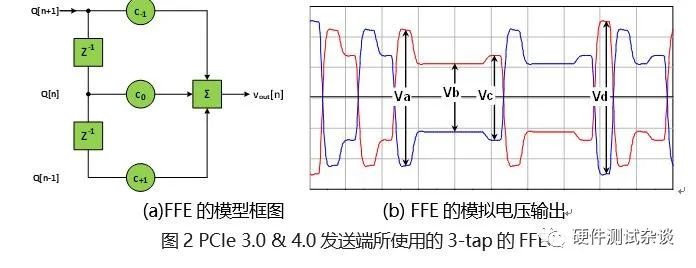
理想情况下的差分电压幅度有:23÷2=4种可能性,这四个电压幅度在PCIe标准中(如图 2b所示)分别被标记为Va,Vb,Vc,Vd。
其中,Vb被称作去加重电压(de-emphasis voltage),Vc被称作预冲电压(preshoot voltage);Vd被称作最大幅度电压(boost voltage),PCIe标准中没有为Va取一个专门的名字。在此基础上,标准中通过三组比值来完备地描述FFE的性能:
若不加限制的来说,那么 形成的组合有无穷多个。但并不是所有的组合在实际应用中都是合适的。其中一个最重要的约束条件就是:去加重电压Vb不能过小,过小的去加重电压会导致输出信号在接收端的眼高过低。因此通过BOOST比值对去加重地电压幅值进行限制:对于满摆幅的Tx输出,规范要求BOOST≤9.5dB;对于减摆幅的Tx输出,规范要求BOOST≤3.5dB。最终会形成一个如图 3类似的矩阵表,图中系数的粒度为1/24。在实际应用中可以是其他的粒度值,例如1/64;更小的粒度能够使系数空间的取值可能性更多,在LEQ调节时也更精细。
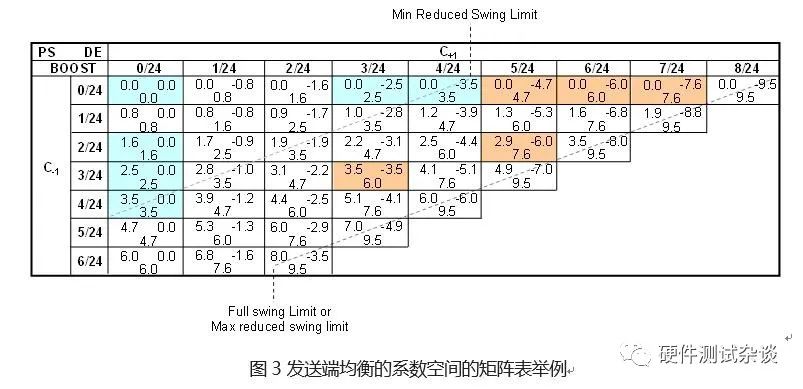
鉴于系数空间上的取值可能性较多,PCI-SIG协会在开发协议的过程中,广泛地研究了在不同插入损耗下最优的系数取值组合;最后选定了若干个特定的系数取值组合,并把它们称作预设定值(preset),在实际的LEQ过程中,链路双方就可以先采用预设定值进行粗调;若还认为链路的均衡设置仍然没有达到最优,可以进一步通过系数空间的方式进行细调,最终达到速度和精度的平衡。
接收端的均衡:CTLE和DFE
在PCIe 3.0 & 4.0 基础规范中,并没有明确地规定接收端的结构是怎样的;而只是从测量的角度对接收端性能进行了规定。相反地,在规范中定义了一个行为级CTLE和行为级DFE。这些行为级模型可以作为设计指南;并且为了使得待测对象能够通过规范的要求,一般来说用户所设计的接收端性能至少要等于这些行为级模型的性能,可以强于这些行为级模型,但不能弱于这些行为级模型。
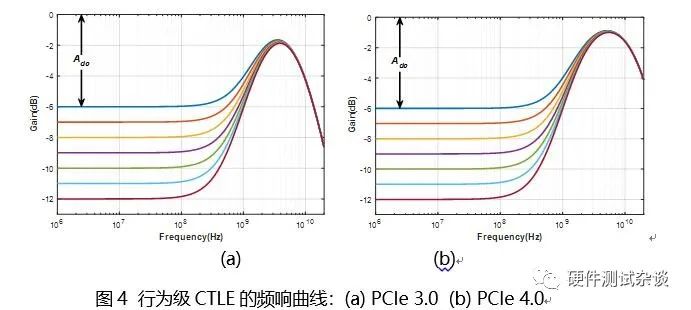
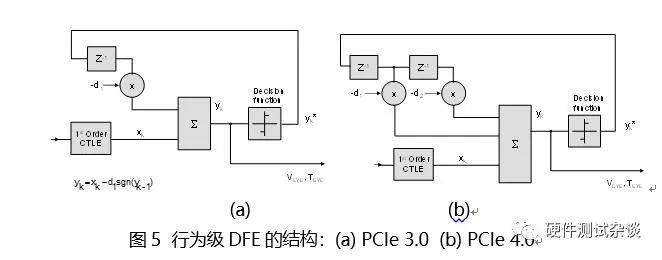
发送端的输出在经过一段很长的FR4走线之后,仅仅使用CTLE,可能是不够的。因此在PCIe 3.0 & 4.0中,还使用了DFE的技术。在3.0中,使用1-tap的DFE,而在4.0,由于速率相对于3.0翻倍了;所以使用2-tap的DFE,以便移除更大的ISI。
与线性均衡器FFE和CTLE相比,DFE为一种非线性均衡器。DFE的基本想法是:若已经正确接收了之前的比特数据的话;那么先前的比特数据对当前比特所产生的影响就是已知的;从而我们就可以通过反馈的方式进行补偿,这样就能够进一步消除抖动和噪声的影响。不难看出这里的非线性体现在:反馈回来的信号是经过判决之后的数字信号;而判决电路是一种非线性电路。显然,反馈通路上的抽头数目越多,那么对抖动和噪声的消除可能就越好;这也就是为什么3.0中使用1-tap的DFE,而在4.0中使用2-tap的DFE。
链路均衡过程
链路上的两端刚开始建立通信的时候,并不知道整个信道的物理特性是怎样的,例如插入损耗多大,是否有阻抗不连续等。由于PCIe 3.0和4.0的插入损耗允许的变化范围很大,一个静态的均衡设置并不能覆盖所有的情况。这样就需要链路上的双方根据当前物理信道的特性,来动态地调整均衡设置,使得均衡设置对于当前的物理信道来说是最优的。假设Port A和Port B是一个链路上的两端,那么链路均衡过程要做的事情有:
配置Port A和Port B的初始均衡设置;
配置从Port A Tx à Port B Rx这一方向的均衡设置;
配置从Port B Tx à Port A Rx这一方向的均衡设置;
下面我们以Port A Tx à Port B Rx这一方向来说明链路均衡时如何实现的。如图 6所示,在8GTs/或者16GT/s速率下的链路开始建立通信时,是以初始的未优化的TX EQ在发送TS1/TS2序列,并且Port A在TS1/TS2序列中表明其所用的TX EQ的值。
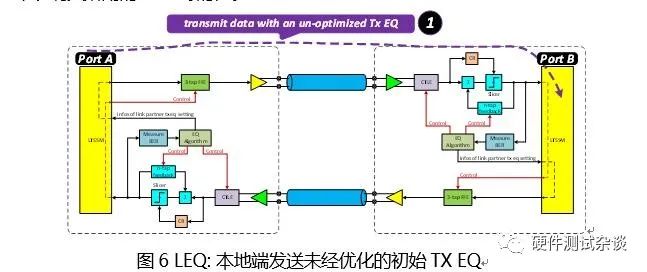
当Port B Rx在接收到这些TS1/TS2序列时,芯片内部存在一块电路或者一套算法来评估当前的TX EQ是否合适,若认为不合适,就会如图7所示,发送TS1序列来请求一个新的TX EQ。
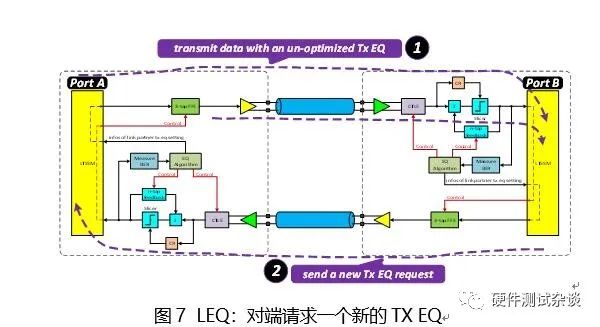
随后,Port A会接收到请求设置TX EQ的TS1序列,如图8所示,调整其TX端的FFE的设置。
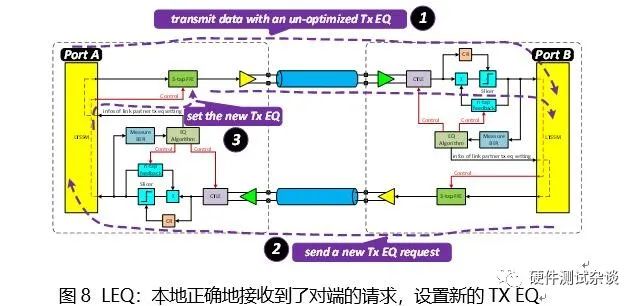
Port A在调整完Tx FFE的设置之后,如图9所示,会将新的TX EQ设置值更新到TS1/TS2的序列之中,发送到Port B端。若Port B仍然觉得这个时候的TX EQ不是最优,那么仍然会重复图中的2~4步骤,直到达到最优的TX EQ。当然上述过程并不能无限进行下去,必须要在大概32ms的范围进行完。
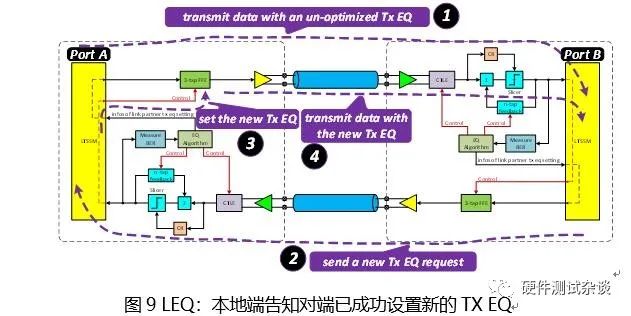
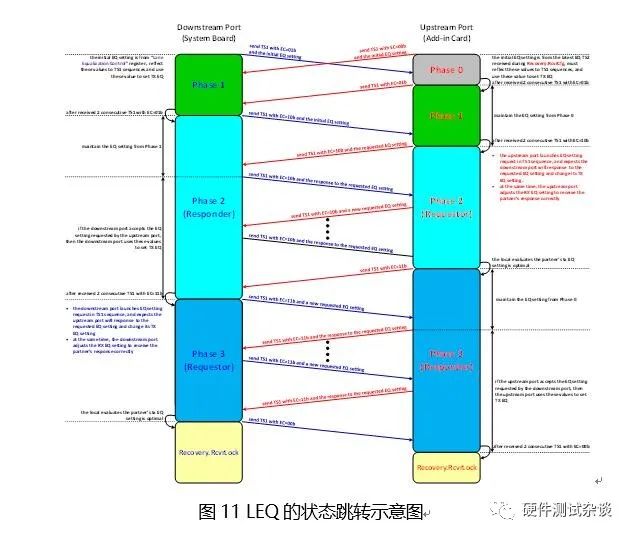
在上述24步骤的同时,Port B的RX端也在不停地调整其RX EQ,如图 10所示。如图6图10中所讨论的,LEQ是基于请求-响应机制来完成动态均衡的。在PCIe的规范中,LEQ总共包含四个阶段:Phase 0、Phase 1、Phase 2、Phase 3。其中上行端口包含全部四个过程;而下行端口不包含Phase 0。
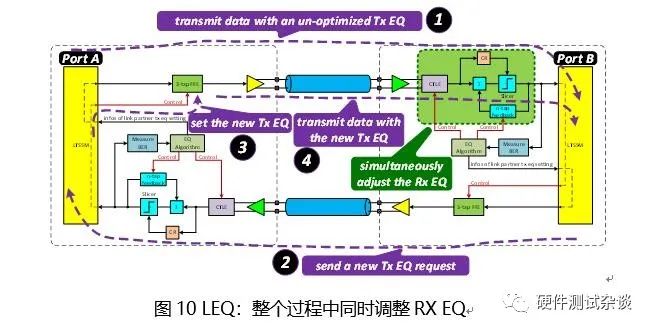
通过图11不难看出,在LEQ过程中,上行端口和下行端口的行为是有区别的。以上描述的是在LEQ过程中链路上的双方如何调整Tx EQ。而对于Rx EQ,根据Base规范中的说明,在整个LEQ的过程、以及在后续正常工作的过程中,链路双方都可以一直调整Rx EQ。
审核编辑:刘清
-
编码器
+关注
关注
45文章
4022浏览量
143708 -
均衡器
+关注
关注
9文章
228浏览量
32355 -
boost电路
+关注
关注
3文章
165浏览量
31589 -
PCIe接口
+关注
关注
0文章
130浏览量
10662 -
FFE
+关注
关注
0文章
8浏览量
1400
原文标题:PCIE3&4的接收端均衡技术
文章出处:【微信号:硬件测试杂谈,微信公众号:硬件测试杂谈】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
PCIe Gen3/Gen4接收端链路均衡测试(上篇:理论篇)
PCIe Gen3/Gen4接收端链路均衡测试(下篇:实践篇)
基于PCIe和V4L2的8通道视频采集&显示IP
供应EMI测试接收机R&S ESCI

力科PCIE 3.0系列文章之二——PCIE 3.0的动态均衡测试挑战

如何区分Java中的&amp;和&amp;&amp;
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),为true,你敢信?

HarmonyOS &amp;amp;amp;润和HiSpark 实战开发,“码”上评选活动,邀您来赛!!!

一个严谨的STM32串口DMA发送&amp;接收(1.5Mbps波特率)机制
Channel怎么来匹配?发射端均衡器和接收端均衡器有怎么样的玩法?
Open RAN的未来及其对AT&amp;T的意义
onsemi LV/MV MOSFET 产品介绍 &amp;amp; 行业应用




评论