 高性能计算与多模态处理的探索之旅:英伟达GH200性能优化与GPT-4V的算力加速未来
高性能计算与多模态处理的探索之旅:英伟达GH200性能优化与GPT-4V的算力加速未来
★多模态大模型;GPU算力;LLMS;LLM;LMM;GPT-4V;GH200;图像识别;目标定位;图像描述;视觉问答;视觉对话;英伟达;Nvidia;H100;L40s;A100;H100;A800;H800,AI算力,AI算法
随着人工智能技术的不断发展,多模态大模型成为越来越重要的发展趋势。多模态大模型通过融合视觉等多种感知能力来扩展语言模型,实现更强大的通用人工智能。GPT-4V(GPT-4 近日开放的视觉模态)大型多模型(LMMs)扩展大型语言模型(LLMs)以增强多感知技能(如视觉理解等)从而实现更强大的通用智能。本文着重对GPT-4V进行深入分析,以进一步深化对LMM的理解。在此本文分析核心是GPT-4V可以执行的任务,同时包含用于探测其能力质量和通用性的测试样本。
研究结果表明,GPT-4V在处理交错多模态输入方面有着前所未有的能力,并且其通用性使其成为一个强大的多模态综合智能系统。GPT-4V的独特能力主要表现在理解输入图像上绘制的视觉标记,同时还能产生新的人机交互方法如视觉指引提示。本文将探讨GPT-4V的初步探索、多模态对算力影响、英伟达最强AI芯片GH200究竟强在哪里,以及蓝海大脑大模型训练平台等多个方面的内容。
GPT-4V的初步探索
本文采用定性案例设计方法,对GPT-4V进行全面探索。着重以案例方式进行评估,而非传统的定量评测,旨在激发后续研究建立针对大型多模态模型的评估基准。考虑到不同的交互模式可能会对模型表现产生影响,因此主要采用零样本提示的方式,以减少对上下文示例的依赖,从而更好地评估GPT-4V独立处理复杂多模态输入的能力。
一、GPT-4V的输入模式
GPT-4V是一个文本输入的单模型语言系统,同时具备接受图像-文本对输入的能力。作为纯文本输入模型,GPT-4V表现出强大的语言处理能力。对于文本输入,GPT-4V只需要纯文本输入和输出即可完成各种语言和编码任务。GPT-4V的另一个应用模式是接受单个图像-文本对输入,可以完成各种视觉及视觉语言任务(如图像识别、目标定位、图像描述、视觉问答、视觉对话以及生成密集式图像描述等)。此外,GPT-4V还支持交错的图像-文本输入模式,这种灵活的输入方式使其具有更广泛的应用场景,比如计算多张收据图片的总税额、从多图片中提取查询信息,以及关联交错的图像文本信息等。处理这种交错输入也是少样本学习和其他高级提示技术的基础,从而进一步增强GPT-4V的适用范围。


GPT-4V支持使用多图像和交错图像-文本输入
二、GPT-4V的工作方式和提示技术

GPT-4V可以理解并遵循文本指令,生成所需的文本输出或学会完成一项新任务。红色表示信息较少的答案。
GPT-4V的独特优势在于其强大自然语言指令理解和遵循能力。指令可以用自然语言形式规定各种视觉语言任务所需的输出文本格式。此外,GPT-4V能够通过理解复杂指令来完成具有挑战性的任务,如包含中间步骤的抽象推理问题。GPT-4V具有适应未知应用和任务的巨大潜力。
1、视觉指向和视觉引用提示
指点是人与人之间互动的基本方面,为提供可比的交互渠道,探索各种形式的“指点”来表示图片中的空间兴趣区域(如数字坐标框、箭头、框、圈、手绘等)。鉴于图像上绘制的灵活性,提出一种新的提示方式即“视觉指代提示”,通过编辑输入图像的像素来指定目标(如画视觉指示器或手写场景文字)。不同于传统文本提示,视觉指代提示通过图像像素编辑来完成任务。例如:可以基于画出的对象生成简单描述,同时保持对整体场景的理解,或者将指定对象与场景文本索引关联起来,或者回答贴边或刁钻角度的问题等。
2、视觉+文本提示
视觉引用提示可以与其他图像文本提示结合使用,呈现简洁细致的界面。GPT-4V展现出强大的提示灵活性,特别是在集成不同输入格式以及无缝混合指导方面。GPT-4V具有强大的泛化性和灵活性,可以像人类一样理解多模态指令,并具有适应未知任务的能力。
同时GPT-4V能处理多模态指令(包括图像、子图像、文本、场景文本和视觉指针),这使其具有更强的扩展能力和通用性。此外,GPT-4V可将抽象语言指令与视觉示例关联,作为多模态演示,这比仅文本指令或上下文少样本学习更符合人类学习方式。

约束提示以JSON格式返回。图像是样本的示例id。红色的突出显示错误的答案。
在大型语言模型(LLM)中,The_Dawn_of_LMMs:Preliminary_Explorations_with_GPT-4V(ision)报告中观察到一种新的上下文少样本学习能力,即LLM可以通过添加格式相同的上下文示例生成预期输出,无需参数更新。类似的能力也在多模态模型中被观察到,查询输入为格式化的图像-文本对。展示GPT-4V的上下文少样本学习能力,强调在某些情况下,充分的示例数量至关重要,特别是在零射或一射指令不足时。
例如,在速度计的复杂场景中,GPT-4V在提供2个上下文示例后成功预测正确读数。在另一个多步推理的线图案例中,只有在给出额外示例的二射提示下,GPT-4V才能得出正确结论。这些验证实例展示了上下文少样本学习对提升LMM性能的重要作用,成为可行的微调替代选择。

在读取速度计的挑战性场景下的零射击性能。GPT-4V即使采用不同的提示方式,也能够准确读取速度表并避免失败。红色表示错误的答案。
三、视觉语言能力
1、不同域的图像描述
GPT-4V在处理“图像-文字对”输入时的能力和泛化性。要求其生成自然语言描述并涵盖以下主题:名人识别、地标识别、食物识别、医学图像理解、Logo识别、场景理解和逆向示例。
名人识别方面,GPT-4V能够准确识别不同背景的名人并理解场景与背景信息,例如在2023年G7峰会上识别总统演讲。
地标识别方面,GPT-4V可以准确描述地标并生成生动详细的叙述,捕捉地标本质。
食物识别方面,GPT-4V能够准确识别各种菜肴并捕捉菜肴的复杂细节。
医学图像理解方面,GPT-4V可以识别X光牙齿结构并能根据CT扫描判断潜在问题。
Logo识别方面,GPT-4V可以准确描述Logo的设计和含义。
场景理解方面,GPT-4V可以描述道路场景中的车辆位置、颜色并读取路标限速提示。
逆向示例方面,当遇到误导性问题时,GPT-4V可以正确描述图像内容,不被误导。

名人识别和描述结果:GPT-4V可以识别各种名人描述视觉信息(包括他们的职业、行动、背景和事件)细节
2、对象定位、计数和密集字幕
GPT-4V在理解图像中人与物体的空间关系方面表现出色,能够分析图像中的空间信息并正确理解人与物体的相对位置。GPT-4V在物体计数方面的能力,能成功计算出图像中出现的物体数量,如苹果、橙子和人。但在物体被遮挡或场景混乱时,计数可能会出错。
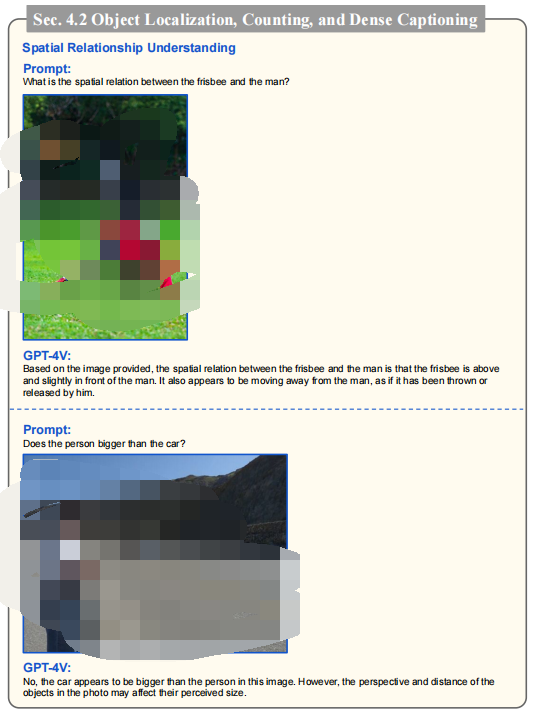
空间关系理解结果:GPT-4V能够识别图像中物体之间的空间关系
3、物体定位
物体定位是计算机视觉中的一项难题,而GPT-4V模型在初步实验中能够通过简单的文本提示生成边界框坐标来定位图像中的人物,但在复杂场景中可能会遇到挑战。在场景或背景相对简单且较少混乱时,定位结果具有潜力,但更复杂的场景(如物体遮挡)中,模型仍需要进一步的提示技术来提升物体定位性能。在目标定位结果方面,GPT-4V能够近似边界框坐标的指定对象,但在更复杂的场景中模型仍有局限性。

4、密集字幕生成
密集字幕生成需要对每个图像区域做出详细描述,通常需要一个复杂的系统,包含目标检测器、名人识别模型和图像字幕生成模型。为了考察本模型在密集字幕生成方面的能力,采用文本提示形式,结果显示模型成功地定位和识别图像中的个体,并提供了简洁的描述。

密集字幕的结果:成功为输入图像生成详细的说明
四、多模态知识和常识
GPT-4V在解释表情包和理解幽默元素方面表现出色,能从文本和图像中收集信息并理解幽默效果。在科学知识推理任务中,GPT-4V也能够正确回答涵盖广泛主题的问题。此外,GPT-4V在多模态常识推理方面也表现出强大的能力,能够利用图像中的边界框识别个体执行的动作,并推断出场景中的细节。在更具体的输入提示下,还能够辨别图像中的微妙线索并提供可能的假设。

笑话和模因理解的结果:GPT-4V展示了令人印象深刻的能力理解表情包中的幽默
五、场景文本、表格、图表和文档推理
GPT-4V能准确地识别和解读图像中的场景文本,包括手写和打印文本,并能提取关键数学信息解决问题。此外,对图表、流程图、x轴、y轴等细节均有理解和推理能力,还能将流程图的详细信息转化为Python代码。GPT-4V也能理解各种类型文档(如平面图、海报和考卷)并提供合理的回答。在更具挑战性的案例中,GPT-4V展示出令人印象深刻的结果,但偶尔可能会遗漏一些实现细节。

场景文本识别结果:GPT-4V可以识别许多具有挑战性的场景文本场景
六、多语言多模式理解
GPT-4V通过自然图像测试成功识别不同语言的输入文本提示,并生成相应正确语言的图像描述。在涉及多语言场景文字识别的场景中,GPT-4V能够正确识别和理解不同场景中的文字,并将其翻译成不同语言。此外,在多元文化理解能力测试中,GPT-4V能够理解文化细微差别并生成合理的多语言描述。

多语言图像描述的结果:GPT-4V能够根据图像生成不同语言的描述
七、与人类的互动视觉参考提示
在人机交互中,指向特定空间位置的能力至关重要,特别是在多模态系统中的视觉对话。GPT-4V能够很好地理解在图像上直接绘制的视觉指示。因此提出了一种名为“视觉引用提示”的新型模型交互方法。其核心思想是将视觉指示或场景文本编辑绘制在图像像素空间中,作为人类参考指令。
最后,科学家们探索了使GPT-4V生成视觉指针输出来与人类进行交互的方法。这些视觉指针对于人类和机器都是直观的,成为人机交互的良好渠道。GPT-4V可以识别不同类型的视觉标记作为指针,并生成具有基础描述的字幕。与传统的视觉语言模型相比,能够处理更具挑战性的问题,即生成专注于特定感兴趣区域的视觉描述。此外,GPT-4V可以理解坐标,并在没有额外的框令牌微调的情况下实现空间引用。尽管存在一些空间不精确问题,但与文本坐标相比,GPT-4V在带有叠加视觉指示的提示下能够更可靠地工作。

GPT-4V理解图像上的视觉指针
受GPT-4V在理解和处理视觉指向上能力的启发,提出一种新的与GPT-4V交互的方式,即视觉参照提示。这种方式利用了在输入图像的像素空间进行直接编辑的技巧,从而为人机交互增添新的可能性。例如,GPT-4V能够自然地将箭头指向的对象与给定的对象索引关联起来;能够理解图像上书写的问题并指向相应的边缘或角度;可以指向图中的任意区域。
视觉参照提示提供一种全新的交互方式,有望促进各种不同应用案例的实现。GPT-4V能够生成自己的指示输出,从而进一步促进人机交互中的闭环交互过程。例如,通过让GPT-4V在文本格式中预测区域坐标来生成视觉指示输出。在提示中包含例子引导指令有助于GPT-4V理解坐标的定义,进而生成更好的指示输出。这种迭代指示生成、理解和执行的能力将有助于GPT-4V在各种复杂的视觉推理任务中取得更好的表现。

视觉参考提示直接编辑输入图像作为输入提示,如绘图视觉指针和场景文本。作为文本提示的补充,视觉引用提示提供了一个更微妙和自然的交互。例如,(1)将有指向的对象与索引相关联,(2)指向对图像进行质疑,(3)在文件和表格中突出线条,(4)绘制图案在图像上,以及许多其他新颖的用例。
八、情商测验
GPT-4V在人类互动中展现出同理心和情商,理解和分享人类的情感。根据人类情商测试的定义,检验了其在以下方面的能力:
1、识别和解读面部表情中的情感
2、理解视觉内容如何引发情感
3、在期望的情感和情绪态度下生成适当的文本输出

GPT-4V了解不同的视觉内容如何激发人类的情感
接下来探讨GPT-4V在理解视觉内容如何引发情感方面的能力。这种能力至关重要,因为要能预测不同的视觉内容如何唤起人类的情感并做出相应的反应(如愤怒、惊叹和恐惧)。这种能力在家用机器人等使用场景中具有极其重要的意义。

GPT-4V根据社会标准和规范来判断图像美学
除理解视觉情感,GPT-4V还能与人类主观判断保持一致,如审美观点。如图所示,GPT-4V可以根据社会标准判断图像的美学。

GPT-4V能根据感知到的情绪,有效生成与所需情绪相匹配的适当文本输出。例如GPT-4V能根据提示描述右边的恐怖图像,使其更加可怕或令人安心。这展示了其在实现情绪感知人机交流方面的潜力。
多模态对算力影响的探讨
一、CLIP 打开图文对齐大门,或成为实现多模态的核心基础
目前视觉+语言的多模态大模型相对主流的方法为:借助预训练好的大语言模型和图像编码器,用一个图文特征对齐模块来连接,从而让语言模型理解图像特征并进行更深层的问答推理。
根据 OpenAI 及微软目前官方发布的 GPT-4V 相关新闻与论文,并不能详细了解其实现多模态,尤其是视觉模型的具体方法,或许可以从 OpenAI 发布的 CLIP 以及其迭代后的 BLIP、BLIP2 等模型上,初步了解多模态大模型的实现方式。
1、CLIP 模型实现了图像与文本的特征对齐,基础架构已于 2021 年发布
过去的计算机视觉系统主要被训练为图像分类模型,这限制了它们在处理未知类别时的泛化能力。为了获取大量广泛的弱监督训练数据,直接从原始文本中学习视觉表示,成为一种更有前途的方法。
OpenAI在2021年提出的CLIP模型采用了图像文本对比学习的预训练方法,这种预训练模型可以在大规模数据上学习将图像视觉特征与相匹配的文本进行关联。即使不进行微调,也可以直接用于下游视觉任务,达到不错的效果。CLIP克服了以往需要大量标注数据的限制。

代表性视觉大模型发布时间
2、CLIP 的输入是配对好的图片-文本对,输出为对应特征,然后在特征上进行对比学习,即可以实现 zero-shot 的图像分类
CLIP模型接受一系列图像和对应的描述文本组成的训练样本对作为输入。图像通过图像编码器提取视觉特征,而文本则通过文本编码器提取语义特征。模型会计算每一张图像的视觉特征与相匹配的文本特征之间的相似度,作为正样本;同时也会计算每一张图像的视觉特征与不匹配的文本特征之间的相似度,作为负样本。CLIP的训练目标是最大程度地提高所有正样本对的相似度,并最小程度地降低所有负样本对的相似度。这意味着,匹配的图像和文本对之间的特征尽可能相似,而不匹配的图像和文本对之间的特征尽可能不同。通过这种预训练方式,CLIP模型可以广泛应用于下游的图像理解任务中,无需进行额外的微调。
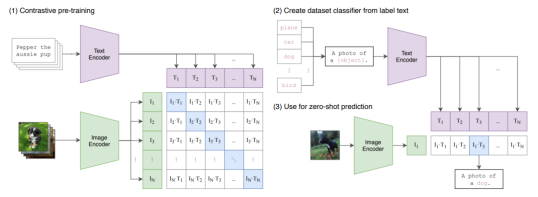
CLIP 训练方法
在零样本图像分类中使用CLIP模型,首先根据每个类别设计描述文本,如“一张{label}的图片”。通过输入这些描述文本来提取文本特征。假设有n个类别,那么就会得到n个文本特征向量。然后,输入需要预测的图像,提取其图像特征,并计算这个图像特征与n个类别文本特征的相似度。相似度最高的类别对应的文本标签就是模型对该图像的预测。进一步将相似度转化为logits,经过softmax处理后,得到每个类别的预测概率。预训练的CLIP模型可以直接用于上述零样本分类,无需进行额外的训练或微调。
3、CLIP 最大的创新在于使用超大规模的数据集进行直接训练,简单而有效
CLIP模型的创新之处在于,它没有提出新的网络架构,而是采用高效的图像文本匹配模型,并在大型数据集上进行训练。在发布CLIP之前,主要的视觉数据集,如COCO和VisualGenome,都是人工标注的,质量很好,但数据量只有数百万级别。相比之下,YFCC100M有1亿个数据,但质量参差不齐,经过过滤后只剩下1500万个,与ImageNet的数据规模相当。由于数据量不足,OpenAI构建了包含40亿个数据点的WIT数据集,通过5000万个查询生成,每个查询对应约20万张图像文本对的数据量,这个数据量与训练GPT-2相当。WIT大数据量的存在使得CLIP模型的训练更加充分。
4、2021 年,最优的模型大约需要 256 张 英伟达V100、训练 12 天,效果即可显著优于传统视觉系统
OpenAI训练了一系列CLIP模型,基于多种ResNet和Vision Transformer架构。最大的ResNet模型使用592个NVIDIAV100 GPU进行18天的训练,而最大的ViT模型则使用256个V100 GPU进行12天的训练。结果显示,ViT模型优于ResNet模型,更大的ViT模型优于较小的ViT模型。最终的最优模型是ViT-L/14@336px。相比早期的工作,CLIP在零样本分类上的表现有了显著的提升,显示出其在零样本学习能力上达到了新的高度。

CLIP 与以往视觉分类模型效果比较
CLIP通过预训练图像文本匹配,将视觉和语义特征映射到统一的嵌入空间,从而架起文本和图像理解之间的桥梁。这一技术的出现,使得在多模态上下文中进行推理成为可能。基于CLIP等模型,大规模语言模型如ChatGPT获得了视觉理解的能力。CLIP系列模型为视觉语言统一预训练奠定了基础,是实现多模态ChatGPT的关键所在。
二、多模态应用空间广阔,算力需求或呈量级式提升
多模态模型的训练对算力需求有数量级的提升,可能需要数万张GPU卡。有报道称,与GPT-3.5相当的大规模语言模型Inflection在训练时使用了约3500张英伟达H100 GPU。对于初创公司来说,训练大型语言模型通常需要数千张H100 GPU,而微调过程则需要数十到数百张。还有报道显示,GPT-4可能在1万到2.5万张英伟达A100 GPU上进行训练,而GPT-5需要的H100 GPU数量可能是2.5万到5万张,相比GPT-3.5的规模提升了约10倍。
在推理阶段,从数据量来看,图像、视频和语音相对于文本交互提升了数个数量级,导致算力需求急剧扩张。
1、在文本方面,从搜索到邮件主流软件已逐步开放
Outlook和Gmail等主流电子邮件服务商已经支持ChatGPT功能。Outlook允许根据不同需求自动生成电子邮件回复,而Gmail用户可以通过ChatGPT AI生成完整的电子邮件。此外,Chrome浏览器也提供免费支持。据统计,全球每天发送超过3300亿封电子邮件,其中近一半是垃圾邮件。在邮件客户端中,Gmail和Outlook的市场占有率分别是27.2%和7.8%。估算非垃圾邮件量,Outlook日均邮件数量约为137亿封。根据邮件平均长度统计,考虑文本存储格式的影响,估算Outlook日均邮件数据量约为25.52TB。假设ChatGPT在Outlook邮件场景中的使用率为1%,每日可能需要处理生成的数据量约261GB,比当前问答场景提升近8倍。
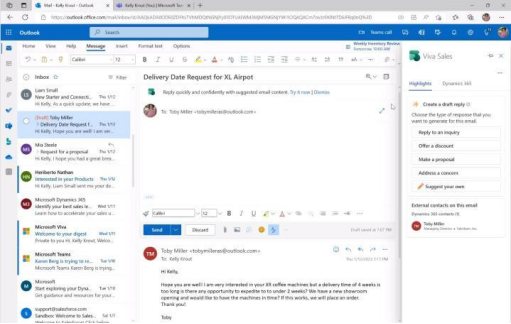
Outlook 利用 GPT 生成邮件
2、语音:Teams 已于 OpenAI 结合,大幅提升线上会议效率
微软的Teams平台已经与OpenAI实现了结合,支持自动生成会议纪要、章节划分、时间标记等多种功能。用户每月支付10美元后,可以使用GPT-3.5模型,获得自动生成会议纪要、实时翻译、章节划分、时间轴标记等服务。Teams平台拥有多种主要功能,其中包括自动生成纪要、40种语言的实时翻译、AI章节划分、个性化时间标记、保护隐私的水印和加密等。这些功能可以帮助用户提高工作效率,节省时间成本,丰富会议体验,而自动生成的纪要和章节划分尤其有益。Teams实现与GPT-3.5的融合,代表了移动互联时代生产力工具的新方向,为用户提供更智能化的服务。
通过实时翻译与字幕,减少会议期间的语言障碍
随着语音输入在大模型中的应用在Teams平台中得到日益广泛的应用,其新增数据量的需求也将得到相应的提升。数字音频的存储原理表明,采样频率、量化位数以及声道数都会影响其存储量。在电话质量的音频中,采用8kHz的采样率、8bit的量化、双声道的存储方式,其存储量约为每秒2字节。假设在Teams的语音交互场景下,ChatGPT每天需要处理1小时的音频数据,那么每天新增的数据量需求约为7200字节,即7.03KB。
考虑到Teams目前日活跃用户已过亿,我们可以估算,如果所有用户都使用1小时的音频交互,那么每天新增的数据量需求约为7.03KB * 1亿 = 703GB。相比当前的文本交互,语音数据量需求提升了约200倍。因此,语音交互场景的引入将给AI系统带来数据量级的显著提升。
音频数字化后的数据量计算方式为:以字节为单位,模拟波形声音被数字化后音频文件的存储量(假定未经压缩)为:存储量=采样频率(Hz)x量化位数(bit)/8x声道数x时间。这种计算方式可以帮助我们更好地理解和预测音频数据存储的需求。
根据微软公开数据,Teams平台的日活跃用户数量从2020年的1.15亿增长到了2022年的2.7亿。假设Teams的会议总时长与用户数成比例增长,那么2022年Teams的会议总时长估计约为60亿分钟。根据音频存储原理,以电话质量参数估算,60亿分钟音频对应的存储量约为671GB。假设约50%的用户使用ChatGPT生成会议纪要,那么Teams新增语音数据需求约为336GB。需要注意的是,这只是基于电话音质的参数估算,而实际上音频采样率和码率的差异可能会导致实际数据量更大。另外,使用ChatGPT生成纪要的用户比例也可能会有所调整,从而影响最终的需求。
3、图片:Filmora 接入 OpenAI 服务,实现“文生图”及“图生图”
Filmora视频制作软件已集成OpenAI功能,可通过一键智能生成图片素材。万兴科技为Filmora提供了对OpenAI AI绘图能力的支持,用户只需简单描绘出形状,即可在几秒钟内获得AI生成的完整图像。在最新的情人节版本中,Filmora实现了从“文生图”到“图生图”的转换,用户只需输入简单文本即可获得高质量的AI生成图片。这代表了创作工具与AI结合的新方向。通过与OpenAI的结合,Filmora可以帮助普通用户轻松获得高质量图像,从而辅助视频创作。未来,Filmora预计将加入更多AI生成内容的功能,为用户提供更智能高效的创作体验。
Wondershare Filmora 一键“创作”图片
根据Filmora的图片参数估算,其OpenAI生成图片每天的输出数据量约为586GB。Filmora的默认分辨率为1920*1080,每张图片约为6MB。假设每月活跃用户数为300万,每天调用OpenAI 10万次,则每天的数据量约为586GB。万兴科技旗下的亿图脑图也已集成了AI生成内容功能,用户只需输入文本即可自动生成各种脑图。这种技术的应用场景非常广泛,包括营销、出版、艺术、医疗等领域。未来,预计AI生成图像的应用空间将会进一步扩大。
4、视频:AIGC 辅助生成动画,星辰大海拉开序幕
AIGC技术在商业动画片《犬与少年》中的应用前景广阔。该作品由Netflix、小冰公司日本分部(rinna)、WIT STUDIO共同创作。小冰公司是一家独立的技术研发实体,前身为微软人工智能小冰团队,2020年分拆为独立公司。2022年11月7日,小冰公司完成总额10亿元的新融资,用于加速AI Being小冰框架技术研发,并宣布升级其人工智能数字员工(AI Being Employee)产品线,包括大模型对话引擎、3D神经网络渲染、超级自然语音及AIGC人工智能内容生成。小冰公司的业务覆盖全球多个国家和地区,拥有众多用户和观众。
《犬与少年》AI 参与制作
Runway Gen2已开放,视频生成费用为0.2美元。Runway宣布开放Gen-1和Gen-2模型,免费提供给公众试用,发布视频长度4秒,每秒消耗5积分。若积分用尽,用户可以选择付费使用,0.01美元/积分,即生成一个视频需要0.2美元。Gen-2只需文字、图像或文字加图像的描述即可快速生成相关视频,是市场上首个公开可用的文本到视频模型。视频单秒输出数据量达1MB,预示着未来星辰大海的序幕正在拉开。随着AIGC技术在影视剧集、宣传视频等领域逐步渗透,视频创作效率有望显著提升。
综上所述,得出以下结论:目前ChatGPT和AIGC的应用场景远未被完全挖掘,语音、图片、视频等多种形式的输入输出将为内容创作领域带来革命性变化。更广泛的数据形态、更多的应用场景和更深入的用户体验将增加对人工智能算力的需求,这可能导致算力的高速扩张时代到来。
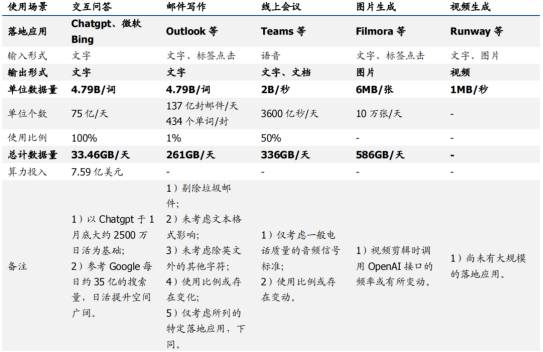
OpenAI 大模型各类场景数据量测算
三、英伟达最强AI芯片GH200究竟强在哪里?
GH200和H100属于同一代产品,其AI计算芯片架构相同,计算能力相当。但是,GH200的内存容量比H100大了3.5倍,这对于需要处理更复杂模型或更大数据量的AI任务来说更加有利。因此,GH200相较于H100的优势在于其更大容量的内存,而不是计算能力。
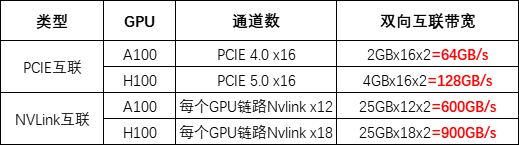
GH200包含一个Grace CPU芯片和一个Hopper GPU芯片,两者通过高速NVLink-C2C互连,带宽高达900GB/s,实现了紧密的CPU和GPU数据交换。这使得GH200的GPU能够直接访问CPU内存。相比之下,在H100系统中,CPU和GPU通常仅通过PCIe连接,即使是最新一代的带宽也只有128GB/s,不及GH200的NVLink-C2C的七分之一。因此,通过芯片级别的优化设计,GH200实现了更高效的CPU-GPU内存共享,这对于需要频繁进行CPU-GPU数据交换的AI计算更加友好。
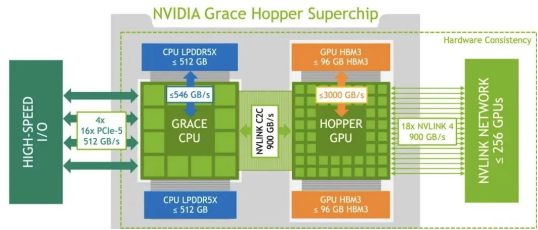
每个GH200集成512GB CPU内存和96GB GPU HBM3内存。Hopper GPU通过NVLink-C2C访问Grace CPU全部内存。相比之下,单颗H100最多80GB HBM3内存,且无法高效连接CPU。基于GH200的DGX GH200集群,256个GPU连接后共享144TB内存(计算方式:(480GB+96GB)* 256)。DGX GH200适用于存在GPU内存瓶颈的AI和HPC应用。GH200通过超大内存和CPU-GPU互联,可以加速这些应用。
蓝海大脑大模型训练平台
蓝海大脑大模型训练平台提供强大的算力支持,包括基于开放加速模组高速互联的AI加速器。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能I/O扩展,同时可以扩展至万卡AI集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当BMC收到PSU故障或错误警告(如断电、电涌,过热),自动强制系统的CPU进入ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI及大数据等领域。
一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
1、处理器CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC™ 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC™ 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、显卡GPU:
NVIDIA L40S GPU 48GB
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW×8
审核编辑 黄宇
-
人工智能
+关注
关注
1791文章
47229浏览量
238329 -
语言模型
+关注
关注
0文章
522浏览量
10271 -
英伟达
+关注
关注
22文章
3772浏览量
91011
发布评论请先 登录
相关推荐
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
英伟达DPU的过“芯”之处
搭载256颗GH200超级芯片的超级计算机
英伟达新发GH200对PCB的影响如何?

生成式AI新增多重亮点,英伟达推出超级芯片GH200 Grace

gh200和h100性能对比
gh200芯片参数介绍
gh200相比gh100的区别
gh200和超级计算机哪个牛
gh200和超级计算机哪个牛
英伟达GH200、特斯拉Dojo超级算力集群,性能爆棚!算力之争加剧!

178页,128个案例,GPT-4V医疗领域全面测评,离临床应用与实际决策尚有距离






 工商网监
工商网监
评论