 架构师写的BUG会是什么样的
架构师写的BUG会是什么样的
部门新来了个架构师,BAT背景,住在三环,开宝马上班,有车位。
小伙话不多,但一旦说话斩钉截铁,带着无法撼动的自信。原因就是,有他着数亿高并发经验,每一秒钟的请求,都是其他企业运行一年也无法企及的。这就让人非常羡慕,毕竟他靠这个比我赚的钱要多。
俗话说,要想在公司不出事故,那就不要写代码。干活多了容易出事,一身轻松无人问津,这就是现实。
但有时候还是要看成果的。新来的研发领导不懂技术,但他懂技术指标,所以就统计大家提交git的数量,如果git活动是一片绿色如A股,那就算过关了。
架构师思来想去,决定领一个并发量最高的需求 :统计接口的平均响应时间和启动以来的请求数。
为什么说它的并发量高呢?这是因为,它是统计所有接口的,自然比每一个接口的请求量都要大。AOP代码一包,每个接口都得从他这里走一圈。
该我们的架构师上场了。代码如图。
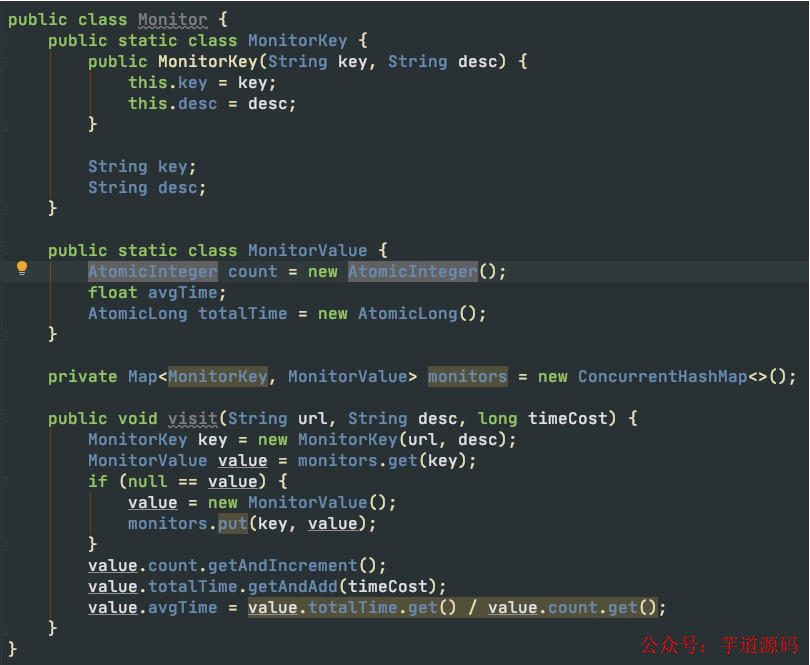
架构师说,我的代码不需要做注释。所谓的注释,都是给垃圾代码用的。我深以为是,他明显是受到了Netflix公司的影响。
程序考虑到了高并发场景,使用了线程安全的ConcurrentHashMap,然后每次通过监控key取出相应的数据,然后在value上递增。这么简单的代码,确实不需要增加什么注释。
作为项目里并发量最高 的代码,出于对高级架构师的信任,我们并不需要做什么代码review,也不需要做什么测试。大家都很忙,代码您呐,到线上遛一遛吧。
我建议你先找一找代码的问题,如果你发现了问题,那就比架构师还厉害;如果你没发现,也不证明你比架构师弱,没有什么好伤心的。
装B遭雷劈,线上运行一段时间后,内存溢出了。
大家吵吵个没完,毕竟xjjdog说过,内存溢出问题的排查周期很长,大约平均需要40天左右才能解决问题。在大家开始论证的时候,架构师偷偷的启动了Eclipse MAT 。MAT用来分析内存问题是非常合适的,但前提是你需要把堆栈给捣鼓下来。
架构师会用jmap,最主要的是权限大,于是自己搞了一份拷贝到线下分析。
我能理解到他的心情,毕竟问题定位到自己的代码不是一件什么值得高兴的事情。他发现内存的堆里面,满满的全是MonitorKey和MonitorValue。
Monitor$MonitorKey@15aeb7ab
我和架构师关系比较好,于是他问我:咱们的接口是不是特别的多?
我说:不是啊,你别看访问量大,就这么个狗屁业务能有多少接口?几百个撑了天了。
他说:我在堆里发现了几千万个...
说完他就不言语了,因为他发现里面有不少是一样的接口。一定是参数的原因,所以他在代码里加了这个,把?后面的给截断了。
key=key.split("\?")[0];
结果发布到线上,过不了多久内存又溢出了。这次终于引起了大牛们的注意,经过大家的分析,发现代码是忘了给MonitorKey重写equals和hashCode方法了。
我不禁脸红起来。作为好朋友,我不应该让他出这个丑。但我又是隐隐快乐的,因为他工资比我高。
所以这就是一个很大的问题。很多同学对HashMap的知识点对答如流,甚至还专门记忆了红黑树。但换一个方式去问,却又一脸懵逼。
其中一种问法是这样的:一个普通的对象,能够作为HashMap的key么?
答案显然是可以的,但需要注意重写hashCode和equals方法。如果忘记重写的话,大概率会造成内存泄漏。
很不幸,现实中忘记的案例很多。大牛架构师也会中招。
代码重写hashCode和equals方法后,线上就再也没发生过内存溢出。
等等,还没完。毕竟是架构师,仅仅这样一个bug还是证明不了水平的。架构师写的bug,肯定非比寻常。
这种事出现的多了,研发领导对技术的权威性就不再是那么感冒。我们决定从并发量最高的代码开始,进行一下代码review。
很不幸,架构师的visit代码出现问题了。虽然问题不是很大,但它毕竟是个问题。
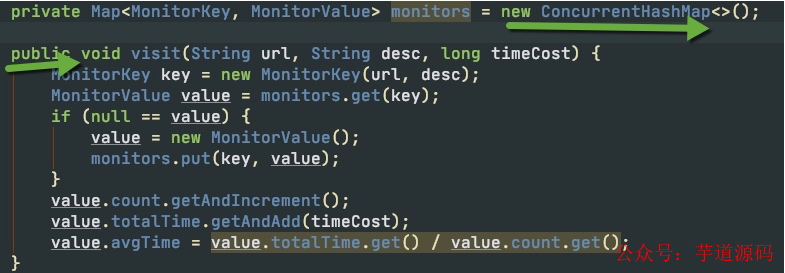
在统计数据的时候,代码使用了ConcurrentHashMap,但它并没有什么卵用。
visit方法,首先拿出了key,然后判空,再塞值。这明显不是一个原子操作。
线程1:获取key为a的值 线程2:获取key为a的值 线程1:a为null,生成一个b 线程2:a为null,生成一个c 线程1:保存a=b 线程2:保存a=c
此时,B丢了。
业务可以忍受,但严谨的技术大牛们忍受不了,提出了修改的意见。
架构师说,给visit方法加个synchronized不就成了。
publicsynchronizedvoidvisit(Stringurl,Stringdesc,longtimeCost)
我说不行。有更优雅的写法,效率更高。那就是使用putIfAbsent方法,代码改动如下:
MonitorKeykey=newMonitorKey(url,desc); MonitorValuevalue=monitors.putIfAbsent(key,newMonitorValue()); value.count.getAndIncrement(); value.totalTime.getAndAdd(timeCost); value.avgTime=value.totalTime.get()/value.count.get();
大家就这两种方式争论了起来。
技术总监托着腮想了半天,看了看争的面红耳赤的同学们,说:这就是我不放心你们的缘故。线上环境要尽量保持稳定性,做最小的变更。既然加个synchronized就能够很容易简单解决的问题,为啥不直接用呢?下面这种代码改动太大,有风险。
总监接着把头转向我:这个BUG非比寻常,为了让大家引以为戒,你来做整个事故的复盘。把问题的排查和得到的教训分享给大家,让大家向这种至简的架构看齐。我们平常的工作中,也要尽量以结果导向为主,用什么手段无所谓,能漂亮把事情办好就行 。
这就是此篇文章的由来,我虚心受教,同时也明白自己的工资是涨不上去了。
编辑:黄飞
-
堆栈
+关注
关注
0文章
182浏览量
19753 -
代码
+关注
关注
30文章
4779浏览量
68519 -
架构师
+关注
关注
0文章
47浏览量
4620
原文标题:架构师写的BUG,非比寻常
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
kintex产品架构设计文档(成为架构师也是电子人不错的选...
架构师的能力锻炼
好的架构师为什么是出色的程序员
女性会更适合做架构师?
一位支付宝架构师自述从工程师到架构师的成长之路
开发工程师和架构师的区别
前端工程师转型架构师的经历
什么是 SoC 设计中的系统架构师?





 工商网监
工商网监
评论