 开源LLEMMA发布:超越未公开的顶尖模型,可直接应用于工具和定理证明
开源LLEMMA发布:超越未公开的顶尖模型,可直接应用于工具和定理证明
今天向大家介绍一个新的开源大语言模型——LLEMMA,这是一个专为数学研究而设计的前沿语言模型。

LLEMMA解数学题的一个示例
LLEMMA的诞生源于在Proof-Pile-2数据集上对Code Llama模型的深度训练。这个数据集是一个科学论文、数学相关网页和数学代码的综合体。
过去虽然有数学专用的模型,但许多模型都有各种限制。例如,有的模型是封闭访问,这使得它们无法为更广泛的研究所用。有的则技术上稍显落后。
但LLEMMA的出现改变了这一局面。它不仅在MATH基准测试上创下了新高,甚至超越了某些还未对外公开的顶尖模型,如Minerva。更让人欣喜的是,LLEMMA无需额外的调整,即可直接应用于工具和定理证明。
让我们一起了解下这个模型背后的技术吧!

Paper:Llemma: An Open Language Model For Mathematics
Link:https://arxiv.org/pdf/2310.10631.pdf
Code:https://github.com/EleutherAI/math-lm
->辅导界的小米带你冲刺ACL2024
数据集
LLEMMA是专为数学设计的大型语言模型,具有70亿和340亿参数。这一模型的训练方法是在Proof-Pile-2.2.1数据集上继续对Code Llama模型进行预训练。以下是关于该数据集的简要说明:
Proof-Pile-2:这是一个包含550亿令牌的综合数据集,融合了科学论文、数学相关的网络内容和数学代码,其知识截止于2023年4月(不包括特定的Lean证明步骤子集)。
代码:为了适应数学家日益重视的计算工具,如数值模拟和计算代数系统,研究团队创建了名为AlgebraicStack的源代码数据集。这个数据集涉及17种编程语言,包括数值、符号和正式的数学内容,共计110亿令牌。
网络数据:研究团队利用了OpenWebMath数据集,这是一个精选的、与数学相关的高质量网络页面集合,总计150亿令牌。
科学论文:使用了名为RedPajama的ArXiv子集,其中包含290亿令牌。
通用自然语言和代码数据:作为训练数据的补充,研究团队还融合了一些通用领域的数据,并以Proof-Pile-2为主,还融合了Pile数据集和RedPajama的GitHub子集。
模型训练
模型初始化:所有模型都从Code Llama初始化,随后在Proof-Pile-2上接受更多的训练。
训练量:
LLEMMA 7B:2000亿令牌的训练。
LLEMMA 34B:500亿令牌的训练。
训练工具和硬件:使用GPT-NeoX库在256个A100 40GB GPU上进行训练。使用了各种先进技术如Tensor并行、ZeRO Stage 1分片优化器状态、Flash Attention 2等以提高效率和减少内存需求。
训练细节:
LLEMMA 7B:经过42,000步训练,每个全局批次有400万令牌,上下文长度为4096令牌,占用A100大约23,000小时。学习率开始从1 × 10^(-4)渐温,然后逐渐减少。虽然计划是48,000步训练,但在42,000步时由于NaN损失中断了。
LLEMMA 34B:经过12,000步训练,每个全局批次有400万令牌,上下文长度为4096令牌,约占用47,000个A100小时。学习率从5 × 10^(-5)开始逐渐增加,然后逐渐减少。
RoPE调整:在训练LLEMMA 7B前,RoPE的基本周期从θ = 1,000,000减少到θ = 10,000,目的是为了在LLEMMA 7B上进行长上下文微调。而LLEMMA 34B维持了θ = 1,000,000的原始设置。
实验设置与评估结果
作者通过少样本评估对LLEMMA模型进行比较,并专注于没有进行微调的最新模型。具体来说,他们使用了使用思维链推理和多数投票,在MATH和GSM8k等基准上进行了评估。
评估范围:
数学问题求解:测试模型在思维链推理和多数投票的数学问题上的表现。
少样本工具使用和正式定理证明:研究模型在这些方面的表现。
记忆和数据混合的影响:分析这些因素如何影响模型的表现。
使用CoT解决数学任务
评估数据集和任务:
MATH:一个来自高中数学竞赛的问题集,模型必须生成一个LATEX的解决方案,且其答案需要与参考答案匹配。
GSM8k:包含中学数学问题的数据集。
OCWCourses:从MIT的开放课程Ware提取的STEM问题。
MMLU-STEM:MMLU基准中的18个子集,涵盖57个主题。
SAT:包含2023年5月的SAT考试中不包含图形的数学问题的数据集。
作者与以下模型进行了比较:
Minerva:这个模型在技术内容的数据集上继续预训练了PaLM语言模型。
Code Llama:LLEMMA继续预训练的初始化模型。
Llama 2:Code Llama在代码上继续预训练的初始化模型。
对于开源的模型,作者使用他们的评估套件来报告分数,该套件是Language Model Evaluation Harness的一个分支。对于Minerva模型,作者报告了Lewkowycz等人在2022年文章中的基准分数。
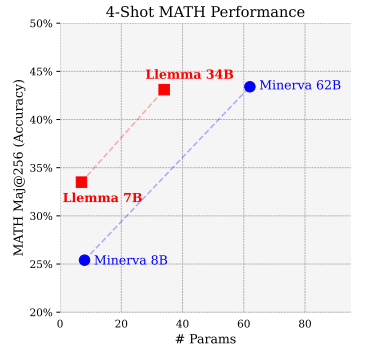
LLEMMA在Proof-Pile-2上的继续预训练提高了五个数学基准测试的少样本性能。LLEMMA 34B在GSM8k上比Code Llama提高了20个百分点,在MATH上提高了13个百分点;LLEMMA 7B的表现超过了专有的Minerva模型。到目前为止,LLEMMA在所有开放权重语言模型上均表现最佳。因此,可以得出结论,Proof-Pile-2上的继续预训练对于提高预训练模型的数学问题解决能力是有效的。
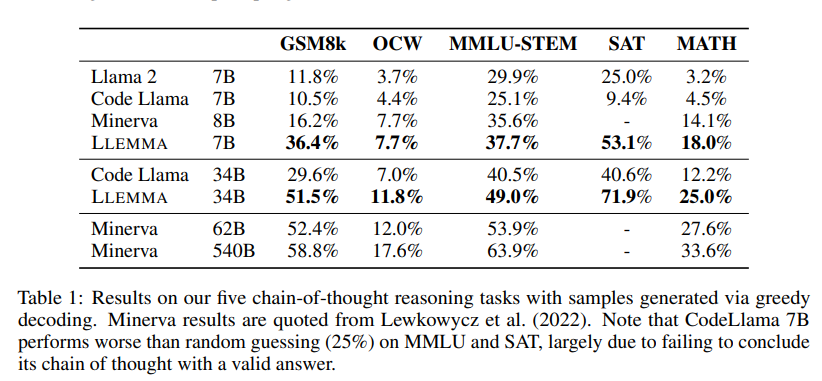
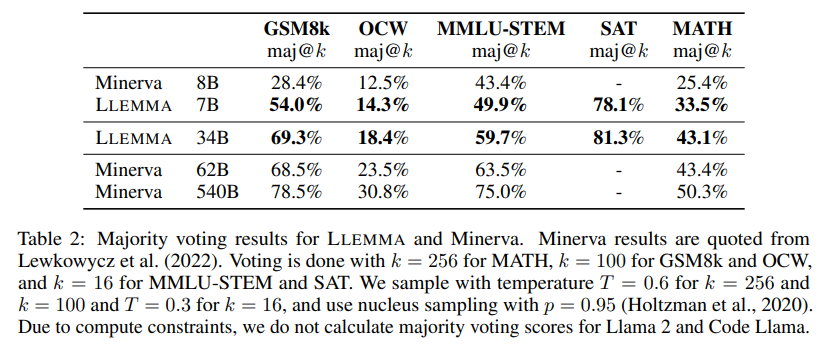
此外,LLEMMA是在与数学相关的多样化数据上预训练的,而不是为特定任务进行调优。因此,预期LLEMMA可以通过任务特定的微调和少样本提示适应许多其他任务。
调用计算工具解决数学任务
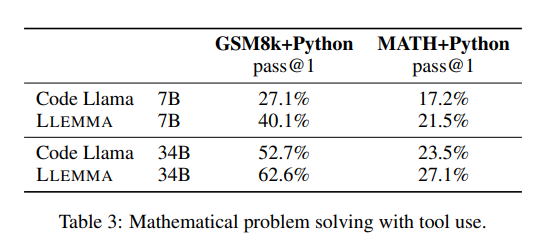
这些任务涉及在有计算工具的情况下解决问题,主要评估了以下内容:
MATH+Python:模型被提示以自然语言交替描述解决方案的步骤,然后使用代码执行该步骤。最后的答案是一个可以执行为数字类型或SymPy对象的程序。我们的少样本提示包括使用内置数字操作、math模块和SymPy的示例。
GSM8k+Python:通过编写一个执行为整数答案的Python程序来解决GSM8k单词问题。我们使用了Gao等人(2023)的提示。
如下表所示,LLEMMA在两个任务上都优于Code Llama。它在MATH和GSM8k上使用工具的性能也高于它在没有工具的这些数据集上的性能。
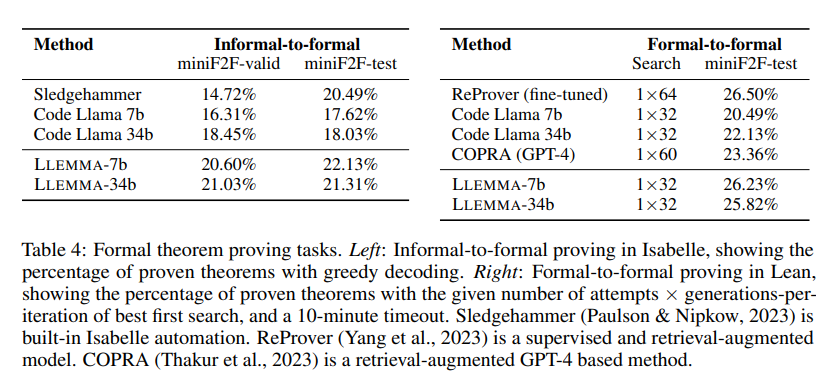
形式化数学(数学证明)
交互式证明助手,例如Lean和Isabelle,使用特殊的编程语言来帮助验证数学证明。但是,与常见的编程语言相比,这些特殊语言的数据非常少。
LLEMMA模型经过进一步的预训练,以处理与这些证明相关的任务。在给定问题、非正式证明和正式声明后,LLEMMA可以生成Isabelle代码的正式证明。此外,模型还可以根据证明助手给出的状态,生成证明的下一个步骤。

LLEMMA在Proof-Pile-2的预训练包括从Lean和Isabelle提取的正式数学数据,总计超过15亿个标记。作者对LLEMMA在两个任务上的少样本性能进行了评估:
非正式到正式的证明:根据非正式的说明,为数学问题生成正式的证明。
正式到正式的证明:在已知的证明步骤中,为下一个步骤生成代码。
结果显示,LLEMMA在Proof-Pile-2上的继续预训练提高了两个正式定理证明任务的少样本性能。
数据混合
在训练语言模型时,经常会根据混合权重提高训练数据中高质量子集的样本频率。作者通过在多个手动选择的混合权重上进行短期训练,然后选择在高质量保留文本上(使用MATH训练集)最小化困惑度的权重。通过这种方法,确定了训练LLEMMA的最佳数据混合比例为21。
数据重叠和记忆
作者检查了测试问题或解决方案是否出现在语料库中。通过查找与测试序列中任何30-gram相匹配的文档确定匹配程度。作者发现大约7%的MATH测试问题陈述和0.6%的解决方案在语料库中有匹配。
在随机抽取的100个匹配中,作者详细检查了测试问题与OpenWebMath文档之间的关系。其中,41个案例没有解决方案,49个提供了与MATH基准解决方案不同但答案相同的解决方案,9个答案错误或缺失,而只有1个与基准解决方案相同。
作者进一步探索了语料库中的问题如何影响模型的性能。当将LLEMMA-34b应用于具有30-gram匹配的测试示例和没有30-gram匹配的测试示例时,模型在难题上的准确率仍然较低,例如在具有匹配的Level 5问题上的准确率为6.08%,而在没有匹配的问题上的准确率为6.39%。
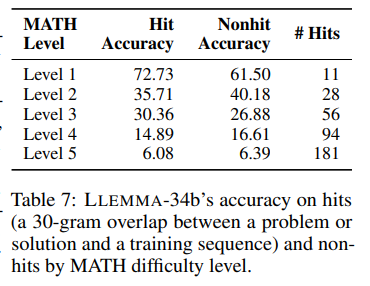
作者发现,30-gram匹配与各个难度级别的准确性之间没有明确的关系。这意味着测试示例和训练文档之间的重要匹配,并不意味着模型生成了一个记忆中的正确答案。
此外,作者还检查了LLEMMA在MATH生成中与OpenWebMath之间的30-gram匹配,发现了13个匹配,这些匹配发生在模型生成了一系列常见的数字序列时,例如斐波那契数列,以及一次多项式因式分解的情况。这些观察结果值得进一步研究。
结语
在这篇研究中,研究团队成功地推出了LLEMMA和Proof-Pile-2,这是专为数学语言建模设计的大语言模型和语料库。他们公开了模型、数据集和相关代码。
研究揭示,LLEMMA在开放权重模型的数学问题解决标准测试上的表现尤为出众,它不仅能通过Python代码娴熟地调用外部工具,还在定理证明中展示了少样本策略预测的高效实用性。此外,该团队深入探讨了模型在解决数学问题时的卓越性能。
LLEMMA的出现,为我们展现了数学与人工智能融合的新前景。随着LLEMMA和Proof-Pile-2的应用,期望在未来更能深化对语言模型的泛化能力、数据集结构的认知,探索将语言模型作为数学助手的可能性,并不断提升其处理数学问题的能力。
-
模型
+关注
关注
1文章
3254浏览量
48894 -
语言模型
+关注
关注
0文章
527浏览量
10287 -
python
+关注
关注
56文章
4797浏览量
84776
原文标题:开源LLEMMA发布:超越未公开的顶尖模型,可直接应用于工具和定理证明
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
应用于声音振动的高级信号处理算法-超越FFT pdf
MSO9000的偏斜校准可以直接应用于AUX BNC输出吗
开源指南针发布在即:估量有尺,开源有道
柔性射频滤波器,可直接应用于柔性电子无线射频通讯
到底该怎么将这些顶尖工具用到我的模型里呢?
基于定理证明的内存安全验证工具算法综述


线性电路的基本定理
搭载ESP32芯片,体积小巧,接口方便,上手简单,可直接应用于物联网低功耗项目
【开发实例】搭载ESP32芯片,体积小巧,接口方便,上手简单,可直接应用于物联网低功耗项目
清华等开源「工具学习基准」ToolBench,微调模型ToolLLaMA性能超越ChatGPT





 工商网监
工商网监
评论