 Nvidia 通过开源库提升 LLM 推理性能
Nvidia 通过开源库提升 LLM 推理性能

加利福尼亚州圣克拉拉——Nvidia通过一个名为TensorRT LLM的新开源软件库,将其H100、A100和L4 GPU的大型语言模型(LLM)推理性能提高了一倍。
正如对相同硬件一轮又一轮改进的基准测试结果所证明的那样,在从专用人工智能芯片中挤出尽可能好的性能时,软件往往与硬件一样重要。
“我们所做的很大一部分是硬件和软件的结合,如今英伟达的软件工程师比硬件工程师多,”英伟达超大规模和HPC计算业务副总裁兼总经理Ian Buck告诉《EE时报》。“这是回到最初的CUDA的决定的一部分,也是交付不仅是一个带有指令集的芯片,而且是一个完整的堆栈以满足开发者需求的动机。
他说:“这提供了一个在各个层面进行创新的机会:改变硬件架构、改变指令集、改变编译器、改变驱动程序、改变工具、库等等,这样我们就可以推动整个平台向前发展。”。“在过去20年的加速计算中,这种情况已经多次出现,人工智能推理也是如此。”
TensorRT-LLM是Nvidia原始深度学习软件库的演变,对LLM推理进行了优化。它旨在支持 H100,但也可以应用于 A100 和 L4 部署。
“[在TensorRT-LLM中,我们]确保我们为大型语言模型提供最佳的张量核心优化,”Buck说。“这允许人们采用任何大型语言模型并通过TensorRT-LLM传递,以获得Hopper的变压器引擎的好处,该引擎使Hopper的FP8计算能力成为可能。而且在生产工作流程中不会有任何准确性损失。
Nvidia 的 Hopper 架构引入了变压器引擎,这是一个软件库,可智能地管理训练和推理工作负载的精度,以实现最佳性能。Buck说,变压器引擎需要对所涉及的数学,统计数据和数据有深入的了解,并在Nvidia的编译器上进行大量工作。它有助于在模型投入生产后保持模型的预测准确性,这可能是一个挑战。
“你可以很容易地将32位或16位计算塞进FPGA中,但你可能会得到错误的答案,因为它没有你想要的生产级精度,”巴克说。“深思熟虑和谨慎地做到这一点,保持规模和偏差,在某些情况下将计算保持在只有8位的范围内 - 为模型的某些部分保留FP16 - 这是Nvidia已经努力了一段时间的事情。
TensorRT-LLM还包括一个称为动态批处理的新功能。
Buck解释说,LLM工作负载,甚至是同一模型的推理工作负载,都是多种多样的。LLM从情绪分析等更简单的用例开始,但今天的LLM可能正在回答问题,阅读长文本并总结它们,或者为电子邮件,文章,演示文稿等生成长文本或短文本。为LLM推理服务的数据中心也可以为许多不同的用户提供许多不同的服务。
与现有的AI工作负载相比,现有的AI工作负载在大小上更有可能相似,因此易于批处理,Buck表示,针对同一模型的LLM查询在大小方面可能会相差几个数量级,从需要几毫秒才能完成的查询到需要几秒钟的查询。模型也可以堆叠,使事情变得更加复杂。
“我们的标准批处理方法总是等待最长的查询完成,”他说。“图像查询大致花费相同的时间——从效率的角度来看,这不是问题,而且查询可以填充,所以没什么大不了的。
借助新的动态批处理功能,查询完成后,查询可以停用,软件可以插入另一个查询,而较长的查询仍在进行中。这有助于提高具有不同查询长度的 LLM 的 GPU 利用率。
“坦率地说,结果甚至让我感到惊讶,”巴克说。“它使Hopper的性能翻了一番。Hopper 是一个非常强大的 GPU,它可以在同一个 GPU 中并行处理大量查询,但如果没有动态批处理,如果你给它多样化的查询,它会等待最长的查询,而不会被充分利用。
TensorRT-LLM是开源的,以及Nvidia的所有LLM工作,包括许多LLM模型,如GPT,Bloom和Falcon,这些模型已经通过内核融合,更快的注意力,多头注意力等技术进行了优化。所有这些操作的内核都作为TensorRT-LLM的一部分开源。
“这使得对性能感兴趣的研究人员有一个起点,使其更快,”巴克说。“我们的客户和用户很欣赏,如果他们有一个想要部署的特定想法,他们可以针对他们的用例进一步优化一些东西。
创新来自学术界,也来自Meta、Microsoft和谷歌等公司。虽然 Nvidia 与他们合作优化推理,虽然优化可能会成为学术论文,但“世界没有一个好地方去获得这些优化,而且 Nvidia 工程师所做的工作没有得到一个可以帮助世界其他地方的地方分享,“巴克说。
Buck补充说,TensorRT-LLM的性能提升在下一轮MLPerf推理分数中应该是显而易见的,该分数将于明年春天到期。
审核编辑:彭菁
-
NVIDIA
+关注
关注
14文章
5696浏览量
110139 -
开源
+关注
关注
3文章
4368浏览量
46464 -
语言模型
+关注
关注
0文章
575浏览量
11345 -
LLM
+关注
关注
1文章
350浏览量
1397
发布评论请先 登录
NVIDIA扩大AI推理性能领先优势,首次在Arm服务器上取得佳绩

Arm KleidiAI助力提升PyTorch上LLM推理性能
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
NVIDIA打破AI推理性能记录
求助,为什么将不同的权重应用于模型会影响推理性能?
如何提高YOLOv4模型的推理性能?
NVIDIA发布最新Orin芯片提升边缘AI标杆
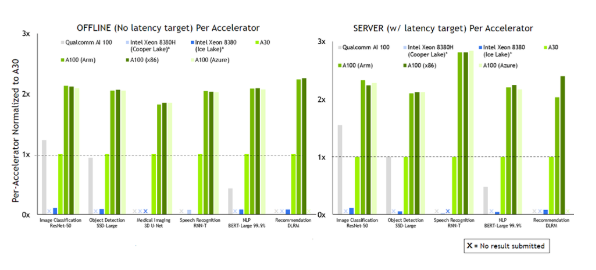
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理

用上这个工具包,大模型推理性能加速达40倍
自然语言处理应用LLM推理优化综述

魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
开箱即用,AISBench测试展示英特尔至强处理器的卓越推理性能





评论