 低功耗下,高能效AI加速器如何设计?
低功耗下,高能效AI加速器如何设计?
如果在数据中心和边缘设备中部署上人工智能(AI)加速器,那么它们将能够快速处理PB级的数据量,还能帮助克服传统的冯·诺依曼瓶颈。在Chat GPT、高级驾驶辅助系统(ADAS)、摄像头和传感器等智能边缘设备中,我们都能看到AI加速器的身影。
在半导体领域,实现出色的性能功耗比永远都是首要目标。AI加速器的能效比通用系统的能效通常会高出100倍甚至1000倍,但生成出色AI模型所需的算力资源每3.4个月就会翻一番。AI产生的能耗不容小觑,以GPT3为例,仅训练这一个深度学习模型所产生的二氧化碳就高达500吨,相当于一辆普通燃油车行驶100多万英里。
降低能耗不仅能够尽量减少对环境的影响,还能降低运营成本,并在有限的功耗预算内尽可能地提高性能,缓解热挑战。
本文将进一步讨论开发者们如何利用端到端功耗分析解决方案,打造新一代更高效节能的AI加速器。
为十亿门级以上设计优化功耗
AI加速器的端到端节能方法必须从设计流程的初始阶段开始,涵盖架构和微架构层面,并一直延续到签核阶段。因此,AI芯片开发者需要利用架构探索平台,对具体训练或推理应用的功耗、性能和面积(PPA)进行权衡分析和评估,并主动识别后续分析的关键矢量。
由于AI硬件通常包括多个由数千个处理单元组成的大型阵列,因此十亿门级以上设计需要进行多域软硬件功耗验证,尽可能降低能耗和漏电。然而,要想分析关键功耗模块和时间窗口,需要先进的硬件加速系统,以便运行数十亿个循环并快速精确地实现多次迭代。只有在完成这一步后,寄存器传输级(RTL)功耗分析和物理实现工具才能有效地优化动态(晶体管门开关)功耗和静态(漏电)功耗。
为了始终提供准确的结果,用于AI芯片设计的RTL功耗分析工具应具备以下功能:
时序驱动型快速综合:内部功耗计算错误通常是基于扇出的快速综合工具未能根据时序约束正确地确定单元大小。同后续的布局布线工具相同,RTL功耗分析工具中嵌入的快速综合功能必须由时序驱动。
物理感知型快速综合:RTL功耗分析工具应该具备“物理感知”能力,能够通过完成一次设计单元摆放以及全局布线就可以获得准确的连线电容值。与基于扇出的方法不同,基于物理感知的电容估算能够为每条连线提供唯一的准确值。
签核质量的功耗计算引擎:传统的RTL功耗分析工具使用word-level逻辑推理进行快速综合,这种方法只能采用启发式算法来计算毛刺功耗,因此并不准确。要准确计算毛刺功耗(可能高达芯片总功耗的40%)并减少高度重复的处理单元,RTL功耗分析工具必须具备签核质量功耗分析引擎、网表级设计表示并集成时序计算引擎。
在完成RTL功耗分析和优化后,便可使用物理实现(综合和布局布线)工具来进一步优化PPA。为确保可靠性、可扩展性以及良好的用户体验,这些实现工具应包含统一的集成式数据模型架构、交错式引擎和统一的命令界面。同样重要的是,实现工具应能对先进节点效应和毛刺功耗进行精确建模,从而加速工程变更命令(ECO)和最终设计收敛。
出色的能效与性能
新思科技提供全面的端到端功耗解决方案,帮助AI芯片开发者以经济高效的方式达成或超越充满挑战性的性能和能效目标,同时缩短产品上市时间。新思科技的Platform Architect用于设计流程的初始阶段,能够为AI芯片开发者提供SystemC事务级建模(TLM)工具和高效方法,帮助开发者快速地对复杂的芯片架构进行建模、分析和优化。新思科技ZeBu Empower是一款快速的功耗分析工具,用于AI芯片设计流程的下一阶段:基于数亿个循环来分析和调试软件实际工作负载下的能耗。
许多业内领先的半导体公司借助新思科技ZeBu Empower大幅降低了功耗,其中包括美国硅谷的AI芯片初创公司SiMa.ai,该公司致力于为智能边缘设计高性能、低能耗的AI芯片。具体而言,该公司的SiMa.ai低功耗MLSoC实现了每瓦特帧率(FPS)提升2.5倍的成果。在2023年硅谷SNUG大会上,SiMa.ai公司的芯片开发总监Sounil Biswas指出,流片后验证结果表明,新思科技ZeBu Empower给出的数据与电路板的测量结果之间具有出色的相关性。
为了补充ZeBu Empower并助力实现低功耗RTL设计,新思科技提供了PrimePower RTL,这是一款RTL功耗分析与优化工具,通过将时序驱动型综合、物理感知型综合与集成式计算引擎相结合,可以持续获得准确的结果(与布线后实现的结果相比误差在+/- 15%以内)。新思科技PrimePower RTL还提供分步指导,帮助AI芯片开发者进一步减少毛刺并降低总功耗。
新思科技的Fusion Compiler是一款综合的集成式RTL-to-GDSII实现系统,可帮助实现进一步的PPA优化。在这之后,可以使用新思科技的黄金功耗签核解决方案PrimePower对AI设计进行分析。新思科技的PrimePower通过了全球多家领先代工厂的认证,3nm工艺能够在签核时实现高精度,同SPICE的芯片测量的误差极小。
为边缘AI推理设计差异化芯片
AI加速器使许多热门应用能够在几毫秒内快速分析海量信息并准确推断结果。与此同时,实现出色的性能功耗比依然是芯片开发者的首要目标。这一点在边缘领域尤为明显,在该领域,为了缩小芯片尺寸并尽可能地降低功耗,性能通常会受到限制。
然而,这些限制也为半导体公司创造了新的机遇,让半导体公司可以通过精确校准PPA来满足低延迟、高带宽应用的特定要求,从而设计出差异化芯片。例如,自主导航应用要求计算响应延迟时间限制在20μs以内,而语音和视频助手则要求能够在10μs之内理解语音关键词,并在几百毫秒内理解手势含义。要想成功实现PPA权衡,芯片开发者应该采用整体性方法,利用端到端解决方案,从早期架构探索到最后的黄金功耗签核,持续优化功耗。
审核编辑:刘清
-
加速器
+关注
关注
2文章
814浏览量
38375 -
晶体管
+关注
关注
77文章
9837浏览量
139500 -
人工智能
+关注
关注
1800文章
48083浏览量
242163 -
RTL
+关注
关注
1文章
386浏览量
60171 -
AI芯片
+关注
关注
17文章
1926浏览量
35406
原文标题:边缘端也要跑大模型:低功耗下,高能效AI加速器如何设计?
文章出处:【微信号:Synopsys_CN,微信公众号:新思科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
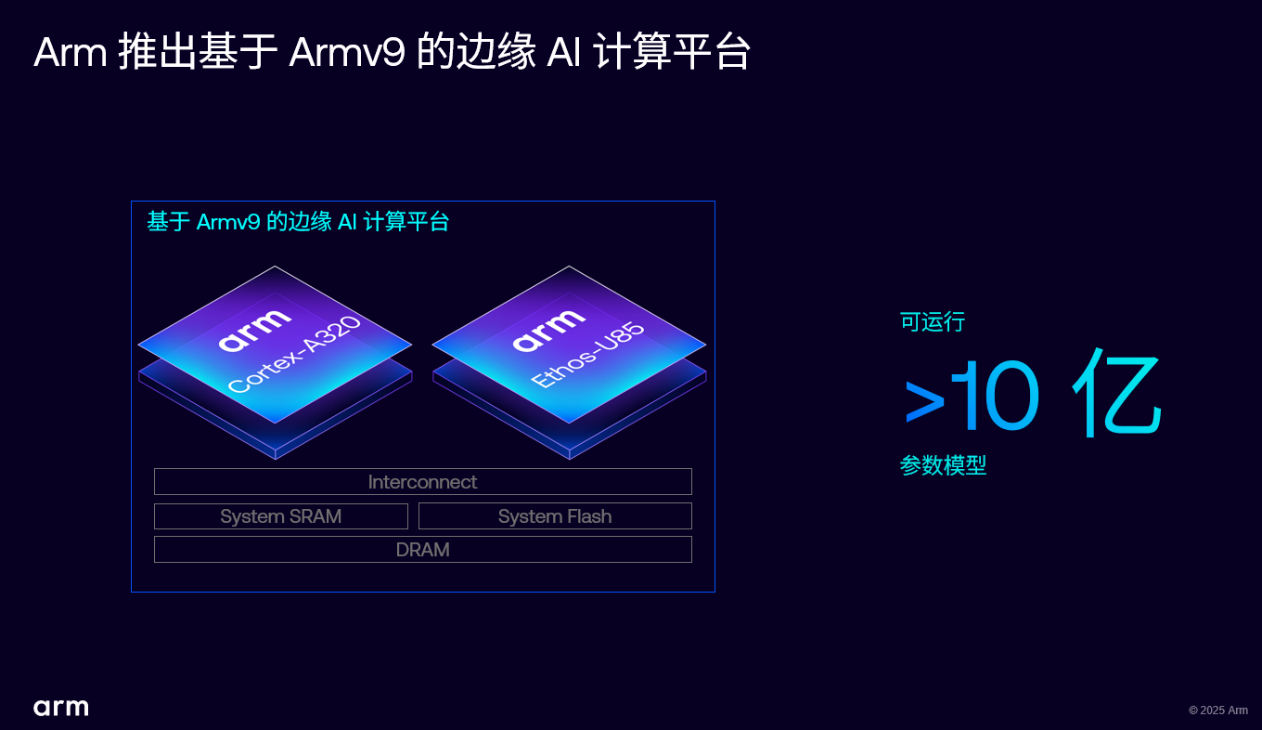
Arm 推出 Armv9 边缘 AI 计算平台,以超高能效与先进 AI 能力赋能物联网革新
当我问DeepSeek AI爆发时代的FPGA是否重要?答案是......
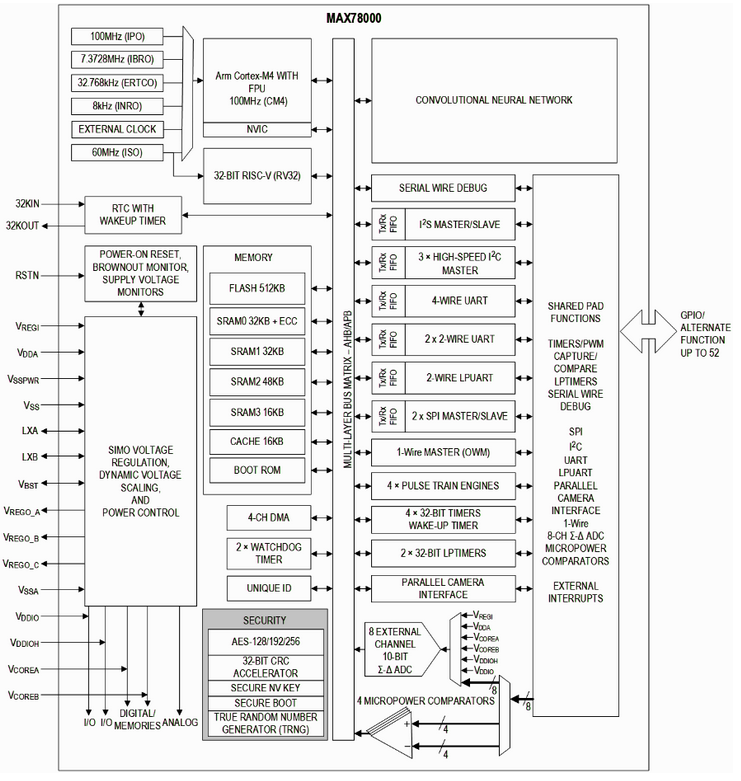
ADI 新型AI微控制器 # MAX78000 数据手册和芯片介绍

IBM与AMD携手部署MI300X加速器,强化AI与HPC能力
IBM将在云平台部署AMD加速器
瑞萨电子推出新一代高能效AI加速器DRP-AI3
什么是神经网络加速器?它有哪些特点?
美国限制向中东AI加速器出口,审查国家安全
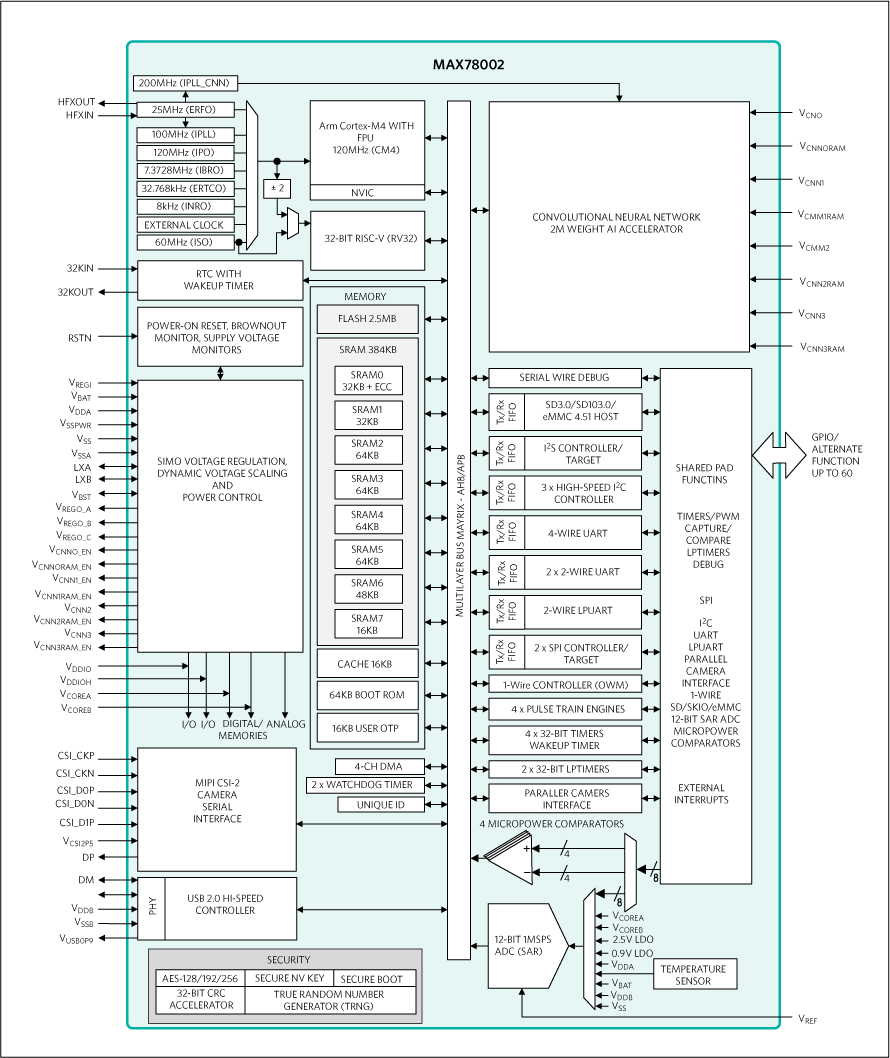
芯品#MAX78002 新型AI MCU,能够使神经网络以超低功耗运行
构建强大、高能效的i.MX 8ULP应用处理器合作生态体系


Arm推动生成式AI落地边缘!全新Ethos-U85 AI加速器支持Transformer 架构,性能提升四倍







 工商网监
工商网监
评论