 STM32 LL库为什么比HAL库高效呢?
STM32 LL库为什么比HAL库高效呢?

概 述
有些应用要求MCU能高效处理,特别是跑一些算法时,对CPU执行效率要求较高。
网上有很多文章说STM32Cube HAL执行效率不高,代码量大等问题 ,导致很多还没有入门,或初学的读者就产生各种各样的疑惑。
说实话,HAL相对标准外设库来说确实存在代码效率不高、代码量大灯这些问题,那么与之对应的STM32Cube LL恰好避免了这样的问题。
LL能高效的原因
简单总结一下原因: 巧妙运用C语言静态、内联函数直接操作寄存器 。
当然,这是其中重要的原因,还有一些其它原因,这里暂不描述。
你会在LL库.h文件中发现大量类似,静态、内联函数直接读写寄存器的函数。
比如读写IO口:
__STATIC_INLINE uint32_t LL_GPIO_ReadOutputPort(GPIO_TypeDef *GPIOx)
{
return (uint32_t)(READ_REG(GPIOx- >ODR));
}
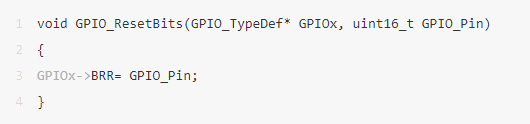
__STATIC_INLINE void LL_GPIO_SetOutputPin(GPIO_TypeDef *GPIOx, uint32_t PinMask)
{
WRITE_REG(GPIOx- >BSRR, (PinMask > > GPIO_PIN_MASK_POS) & 0x0000FFFFU);
}
其中 __STATIC_INLINE ,就是静态、内联:
#define __STATIC_INLINE static __inline
而读写位的定义:

这里面的 宏定义 ,在众多外设.h中都在调用。 比如使能USART :
LL库使能USART:
__STATIC_INLINE void LL_USART_Enable(USART_TypeDef *USARTx)
{
SET_BIT(USARTx- >CR1, USART_CR1_UE);
}
标准外设库使能USART:
void USART_Cmd(USART_TypeDef* USARTx, FunctionalState NewState)
{
/* Check the parameters */
assert_param(IS_USART_ALL_PERIPH(USARTx));
assert_param(IS_FUNCTIONAL_STATE(NewState));
if (NewState != DISABLE)
{
/* Enable the selected USART by setting the UE bit in the CR1 register */
USARTx- >CR1 |= USART_CR1_UE;
}
else
{
/* Disable the selected USART by clearing the UE bit in the CR1 register */
USARTx- >CR1 &= (uint16_t)~((uint16_t)USART_CR1_UE);
}
}
通过对比,你会明显发现: LL库的执行效率更高 。
什么是内联函数?
写到这里,就可能有读者会问:什么是内联函数?
内联函数是一种编程语言结构,用来建议编译器对一些特殊函数进行内联扩展。
通常,程序执行时,处理器从内存中读取代码执行。 当程序中调用一个函数时,程序跳到存储器中保存函数的位置 ,开始读取代码执行,执行完后再返回。
为了提高速度,C语言定义了inline函数,告诉编译器把函数代码在编译时 直接拷贝到程序中 ,这样就不用执行时另外读取函数代码。
**提示:**当内联函数很大时,会有相反的作用,因此一般比较小的函数才使用内联函数。
软件框架思维
LL之所以高效,是因为它巧妙运用了一些C语言知识,没有太多封装,直接或间接对寄存器进行操作。
而能这样实现, 归功于ST开发团队设计了这么一个中间层软件框架 。
对于有大型项目开发经验的人来说,一个项目的框架对整个项目影响很大。
就好比你建一栋楼,如果楼层框架都没造好,你觉得这栋楼质量会好吗?
所以,这里就提到,我们编程时,特别项目较大,需要考虑一下软件框架,一个好的框架能让你的项目达到事半功倍的效果。
-
STM32
+关注
关注
2313文章
11191浏览量
374580 -
C语言
+关注
关注
183文章
7646浏览量
146123 -
GPIO
+关注
关注
16文章
1333浏览量
56439 -
USART串口
+关注
关注
0文章
32浏览量
7320 -
HAL库
+关注
关注
1文章
121浏览量
7738
发布评论请先 登录
STM32标准库、HAL库和LL库介绍
STM32四种库对比 STM32标准库和HAL库有什么不同?
STM32之HAL库、标准外设库、LL库(STM32 Embedded Software)
STM32四种库对比:寄存器、标准外设库、HAL、LL

LL库串口+DMA

STM32的HAL库知识总结




评论