 在英特尔开发套件上用OpenVIN实现中文图文检索
在英特尔开发套件上用OpenVIN实现中文图文检索
作者:卢雨畋英特尔边缘计算创新大使
本文演示了使用OpenVINO与Chinese-Clip进行中文图文相似性匹配任务:CLIP 模型以自监督的方式在数亿或数十亿(图像,文本)对上进行训练,它从输入图像和文本中提取特征向量 embedding,根据特征相似度匹配可完成图像分类和相似查找任务。CLIP 模型的 zero-shot 分类效果就能达到在 Imagenet 上监督训练的 ResNet 分类效果,且有更好的泛化和抽象能力。
得益于中文 Clip模型较小的计算开销与OpenVINO 的优化效果,我们能够在英特尔开发者套件 AIxBoard 上良好的复现这一推理流程。
本文不会展示所有的代码,所有资料和代码的在文末的下载链接给出。
英特尔开发者套件
AIxBoard(爱克斯板)
英特尔开发套件AIxBoard(爱克斯板)由 2023 年蓝蛙智能推出的人工智能嵌入式开发板,专为支持入门级人工智能应用和边缘智能设备而设计,是一款面向专业创客、开发者的功能强大的小型计算机。借助OpenVINO工具套件,能够实现 CPU + iGPU 的高效异构计算推理。
CLIP 原理
CLIP 模型(Contrastive Language-Image Pre-Training) 是来自 OpenAI 的经典图文表征模型,采用双塔模型结构(如下图),利用大规模图文对平行语料进行对比学习,从而能够实现图片和文本的跨模态语义特征抽取。
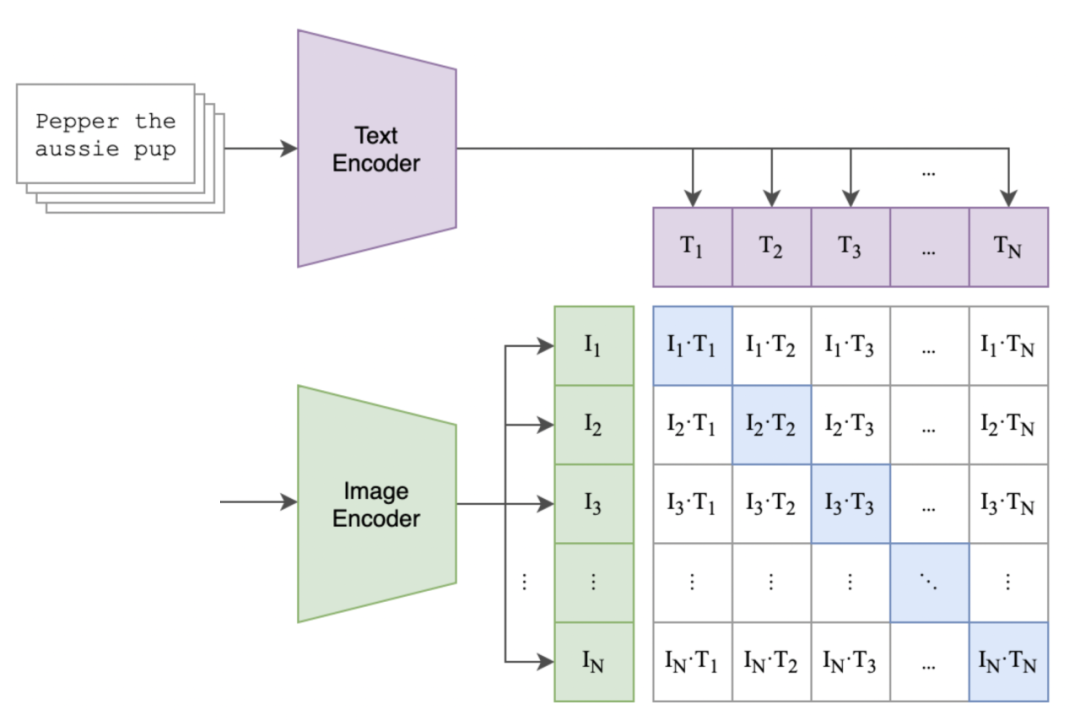
CLIP 模型基于英文图文语料,不能用于中文的图文表征提取场景。得益于达摩院的工作,达摩院的中文 CLIP 以英文 CLIP 视觉侧参数和中文 Roberta 参数,作为模型初始化值,使用大规模中文数据进行训练(~2 亿图文对);最终可用于中文场景下的图文检索和图像、文本的表征提取,应用于搜索、推荐等应用。
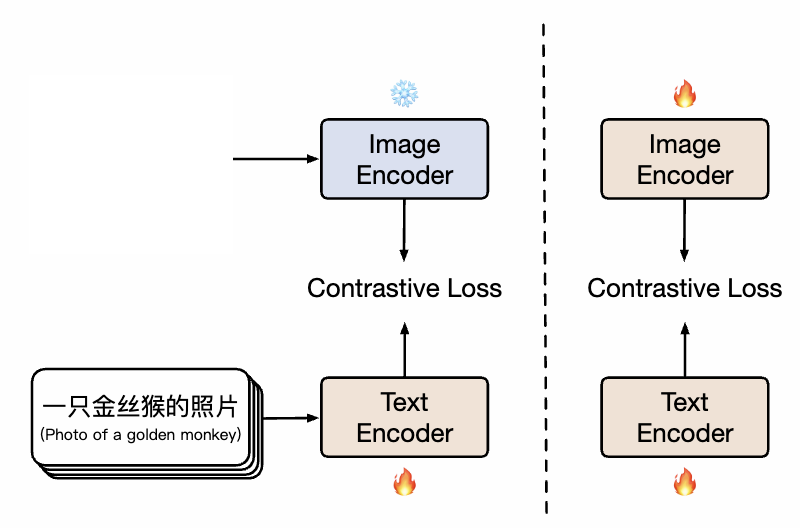
二阶段预训练策略(一阶段仅训练文本侧,二阶段同时训练)如下所示:
CLIP 应用
CLIP 可以应用于各类不同的场景:
Zero Shot分类
将图像与类别文本相比较,以得到最接近的分类结果。(例如:图像分类)
Retrieval
对于给定的输入文本和图像,在大量文本与图像数据中找到最匹配的结果。(例如:clip-retrieval)
CLIP Guidance
对于图像生成模型,结合生成结果与输入文本间的 CLIP 距离生成更好的图片(例如:VQGAN + CLIP)
CLIP Captioning
利用 CLIP encoding 提取特征,以该特征的映射结果结合 GPT2 生成 caption.(例如:ClipCap)
在本文中,你将学会如何使用中文Clip进行Zero Shot分类,以及处理简单的文字与图像检索任务。
模型下载
为节省时间,这里我直接提供了中文clip onnx模型;你也可以根据导出教程,自行导出onnx模型。值得注意的是,OpenVINO也支持Pytorch模型到 OpenVINO IR的转换方式,如果有兴趣你可以参考转换教程,与源码自行转换直接得到OpenVINO模型。
(注意:在这里我提前导出了base的模型,如果你发现在部分任务下效果不是很好,可以尝试large模型或者进行微调,中文 Clip的官方仓库中提供了所有的可参考资料。)
模型的加载与运行
01通用模型类
准备用于结果预测的通用模型类,包括模型的初始化与推理。
OpenVINO 模型初始化有四个主要步骤:
1.初始化 OpenVINO Runtime。
2.从模型文件中读取网络和权重(支持pytorch onnx paddle tensorflow vinoIR多种中间格式的直接读取)。
3.将模型编译为设备可用的形式。
4.获取并准备节点的输入和输出名称。
我们可以将它们放在一个类的构造函数中。为了让 OpenVINO 自动选择最佳设备进行推理,只需使用“AUTO”。大多数情况下,最佳设备是“GPU”(性能更好,但启动时间稍长)。
core = ov.Core() class VinoModel: def init(self, model_path, device=“AUTO”): self.model = core.read_model(model=model_path) self.input_layer = self.model.input(0) self.input_shape = self.input_layer.shape self.height = self.input_shape[2] self.width = self.input_shape[3] print(“input shape:”,self.input_layer.shape) print(“input names:”,self.input_layer.names) self.compiled_model = core.compile_model(model=self.model, device_name=device) self.output_layer = self.compiled_model.output(0) print(“output names:”,self.output_layer.names) def predict(self, input): result = self.compiled_model(input)[self.output_layer] return result img_model = VinoModel(“image_model.onnx”) txt_model = VinoModel(“text_model.onnx”)
左滑查看更多
02预处理
在输入OpenVINO引擎推理之前,我们需要对数据进行适当的预处理操作,数据预处理函数改变输入数据的布局和形状以适配网络输入格式。
def preprocess(image:np.ndarray): image = cv2.resize(image, (224, 224), interpolation=cv2.INTER_CUBIC).astype(np.float32) / 255.0 mean = np.array([0.48145466, 0.4578275, 0.40821073]) std = np.array([0.26862954, 0.26130258, 0.27577711]) image = (image - mean) / std image = np.transpose(image, (2, 0, 1)) image = np.expand_dims(image,axis=0).astype(np.float32) return image
左滑查看更多
03核心函数
在核心处理函数中,我们需要分别提取图像和文本的Embedding特征,归一化后一一匹配得到最接近的特征结果。
def run_clip(image:np.ndarray,input_strs:List[str]): image_features = _img_feature(preprocess(image)) text_features = _text_feature(input_strs) logits_per_image = 100 * np.dot(image_features, text_features.T) exp_logits = np.exp(logits_per_image - np.max(logits_per_image, axis=-1, keepdims=True)) max_logit = exp_logits / np.sum(exp_logits, axis=-1, keepdims=True) max_str = input_strs[max_logit.argmax()] max_str_logit = max_logit.max() return max_str, max_str_logit
左滑查看更多
接下来我们将进行Clip模型的推理,我们选择一个青蛙的图片作为推理对象。
我们可以初始化一个字符串列表,从而得到该图最匹配的一个文本信息。
你可以构建一个自己想要进行分类的字符串列表,从而达到在不同任务上分类的目的。
text = [“大象”, “猴子”, “长颈鹿”, “青蛙”]
max_str, max_str_logit = run_clip(image,text)
print(f”最大概率:{max_str_logit}, 对应类别:{max_str}“)
左滑查看更多
结果显示为:
最大概率:0.9436781406402588, 对应类别:青蛙
左滑查看更多
你可以根据自己的需求构建不同的分类文本标签,达到zero shot分类的目的。
除此之外,我们还可以利用OpenVINO提供的Benchmark工具,来更好的观察Clip模型运行的吞吐量与效率
(注意:你可以将AUTO显式指定为GPU观察结果的区别,你也可以尝试把之前加载的模型重新编译到GPU观察性能和结果是否有所区别。)
!benchmark_app-mimage_model.onnx-dAUTO-apisync-t30
左滑查看更多
图文检索
接下来,我们将结合之前的推理Embedding结果,利用端到端机器学习Embedding开源库Towhee以及Meta向量数据库Faiss,构建一个高效的文图检索与图图检索引擎。通过在边缘设备上部署检索引擎,我们能够有效地筛选和总结推理检测结果,从而更好地进行综合统计分析。
除此之外,Chinese-Clip同时提供了微调的接口,通过对指定商品数据的微调,你可以结合检索引擎实现一个商品检索装置,抑或是端侧商品推荐系统。
(注意:这里只是一个范例,你可以使用端侧设备得到Embedding但使用云端数据库进行匹配,又或者是利用它减少端侧数据的筛选时间。)
from towhee.operator import PyOperator from towhee import ops, pipe, DataCollection,register import glob @register class img_embedding(PyOperator): def call(self, path): image = np.array(Image.open(path).convert(‘RGB’)) return _img_feature(preprocess(image))[0] @register class text_embedding(PyOperator): def call(self, input_strs): return _text_feature(input_strs)[0]
左滑查看更多
通过构建自定义 Towhee ops 进行 pipeline 推理,我们可以很容易进行文图检索:
decode = ops.image_decode.cv2(‘rgb’) text_pipe = ( pipe.input(‘text’) .map(‘text’, ‘vec’, ops.text_embedding()) # faiss op result format: [[id, score, [file_name], …] .map(‘vec’, ‘row’, ops.ann_search.faiss_index(‘./faiss’, 5)) .map(‘row’, ‘images’, lambda x: [decode(item[2][0]) for item in x]) .output(‘text’, ‘images’) ) DataCollection(text_pipe([‘吃东西的人’])).show()
左滑查看更多
我们输出了topk前 5 的结果,你可以根据自己的需求修改需要展示多少相关图片。
不局限于文图搜索,我们也可以实现图图检索的功能:
image_pipe = ( pipe.input(‘img’) .map(‘img’, ‘vec’, ops.img_embedding()) # faiss op result format: [[id, score, [file_name], …] .map(‘vec’, ‘row’, ops.ann_search.faiss_index(‘./faiss’, 5)) .map(‘row’, ‘images’, lambda x: [decode(item[2][0]) for item in x]) .output(‘img’, ‘images’) ) DataCollection(image_pipe(‘images/000000005082.jpg’)).show()
左滑查看更多
是不是觉得很神奇?即使是小型边缘设备也能够运行Clip这样的大型模型,快通过下方链接获取所有资料,与我一起感受中文Clip与OpenVINO共同带来的便捷体验。
审核编辑:汤梓红
-
英特尔
+关注
关注
61文章
9949浏览量
171692 -
人工智能
+关注
关注
1791文章
47183浏览量
238241 -
开发套件
+关注
关注
2文章
154浏览量
24271 -
OpenVINO
+关注
关注
0文章
92浏览量
196
原文标题:在英特尔开发套件上用 OpenVINO™ 实现中文图文检索 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【Intel Edison试用体验】+Intel Edison开发套件资料
英特尔82801HM IO控制器开发套件

英特尔QM57高速芯片组开发套件

英特尔酷睿2双核处理器SL9380和英特尔3100芯片组开发套件

英特尔凌动N270处理器和移动式英特尔945GSE高速芯片组开发套件

英特尔BOOT Loader开发套件-高级嵌入式开发基础

英特尔945GME高速芯片组开发套件

最新版英特尔® SoC FPGA 嵌入式开发套件(SoC EDS)全面的工具套件
英特尔开源WebRTC开发套件OWT 带来巨大的潜在商业回报
基于OpenVINO在英特尔开发套件上实现眼部追踪
基于英特尔开发套件的AI字幕生成器设计
基于英特尔® QuickAssist的®EP80579集成处理器开发套件

英特尔开发套件『哪吒』在Java环境实现ADAS道路识别演示 | 开发者实战






 工商网监
工商网监
评论