 疯狂的H100:现代GPU体系结构浅析,从算力焦虑开始聊起
疯狂的H100:现代GPU体系结构浅析,从算力焦虑开始聊起
得益于 ChatGPT 引发的新一波 AI 浪潮,2023 年各大科技公司大量采购 NVIDIA 生产的 H100 等系列 GPU。据 NVIDIA 2024 财年第二季度财报[1],NVIDIA 收入创下纪录新高,达到 135.07 亿美元,远超分析师给出 110.4 亿美元预期。目前市场上对 H100 的需求在 43.2 万张左右,每张售价约 3.5 万美元,受限于台积电的产能,2023 年 NVIDIA H100 的产量早已销售一空,目前 GPU 的短缺或将持续到 2024 年[2]。
在 eBay 上,一张 NVIDIA H100 SXM 80GB 的 GPU 售价目前 (2023.10) 已经被炒到了 4.5 万美元[3]。于此同时,估值仅 20 亿美元的 CoreWeave 以 NVIDIA H100 为抵押,却拿到了 23 亿美元的债务融资[4]。要知道,CoreWeave 手上目前并没有这么多的等价 NVIDIA H100,它有的仅仅只是 NVIDIA 的 H100 供货承诺。仿佛过去二十年国内狂飙的土地财政一般,房地产商通过土地拍卖拿到的土地,又可以快速抵押拿到银行的贷款,NVIDIA H100 在当下也成为了如土地一般的硬通货。 本文尝试深入到硬件,从英伟达 H100 系列 GPU 入手,解析现代 GPU 体系结构,试图去理解在大模型继续狂飙的当下,为何卖的如此之贵的 H100 还能够卖的这么好。
01.TLDR
本文所有的资料来自于互联网公开信息,更多是从程序员的角度去理解现代 GPU 的体系结构,强烈推荐大家阅读本文附录的原始资料,文中的观点与本人雇主无关。
除了以 H100 为代表的英伟达 GPU,市场上同场竞争的还有很多其他类型的 GPU:比如来自 AMD、Intel 的 GPU,以华为昇腾 910 AI 加速芯片,Google 的 TPU,AWS 自研 Tranium 和 Inferentia,乃至来自壁仞等创业公司的 GPU 等。因为工作中主要使用的是英伟达的 GPU,本文目光也主要集中在英伟达的 H100。
随着时代的发展,最早源于图形渲染领域的 GPU,不断在 HPC、图形学和深度学习这三个领域游走,前几年还在加密货币中发挥了重要作用。本文不太会详细介绍其图形渲染方向的能力,更多侧重于像计算侧能力的演进与发展。受限于篇幅,本文暂时不会涉及 MIG 和机密计算等新特性,也不太介绍 NVLink 等通信能力。
作为一名软件工程师,本文作者对于硬件的理解也并不算深刻与全面,甚至可能会存在偏差与错误,在介绍相关方向的时候也肯定会存在遗漏,欢迎大家交流与指正。
本文相对较长,全文超过 10000 字,阅读预计需要 20 分钟左右。
在真正开始之前,这里先简单介绍下本文可能会碰到的技术缩略语,现在不需要深刻理解其含义,只需要有初步印象即可。
| FLOPS | Floating point Operations per Second | FLOPS 为每秒浮点数运算次数,FLOPs 则表示浮点运算次数 |
| DGX | Deep-learning GPU Accelerator | NVIDIA 推出的一系列专门用于加速深度学习工作负载的高性能计算平台 |
| HGX | High-Performance GPU Accelerator | NVIDIA 推出的服务器参照平台。OEM 厂商用于构建 4 GPU 或 8 GPU 服务器,由 Supermicro 等第三方 OEM 制造 |
| SXM[6] | Server PCI Express Module | NVIDIA 用于连接 GPU 的高带宽 socket 接口,相比 PCIe 具有高带宽、低延迟、高拓展性、直接互联等特点 |
| HBM | High Bandwidth Memory | 一种先进的内存技术,相对于 GDDR 等具有高带宽、低功耗、封装紧凑等特点 |
| CoWoS[7] | Chip on wafer on Substrate | 三维堆叠,相对于 GDDR 等具有高带宽、低功耗、封装紧凑等特点 |
| GPC | Graphics Processor Cluster | 图形处理集群,每个 GPC 包含若干个 TPC |
| TPC | Texture Processor Cluster | 纹理处理集群,每个 TPC 包含若干个 SM |
| SM | Streaming MultiProcessor | NVIDIA GPU 架构中的核心计算单元,负责执行并行计算任务 |
| SIMT | Single Instruction Multiple Thread | 单指令多线程,NVIDIA GPU 中的一种并行计算模型,将 SIMD 和多线程结合起来,使得多个线程可以同时执行相同的指令,但是处理不同的数据 |
| GEMM | General Matrix Multiplication | 通用矩阵乘,是一种广泛用于深度学习神经网络模型的计算操作 |
| MMA | Matrix Multiply-Accumulate | 矩阵乘加 |
| FMA | Fused Multiply-Accumulate | 融合矩阵乘加,通过单个指令实现矩阵乘加 |
| TMA | Tensor Memory Accelerator | 张量内存加速器 |
| MIG | Multi-Instance GPU | 多实例 GPU |
| TEE | Trusted Execution Environments | 可信执行环境 |
| SHARP | Scalable Hierarchical Aggregation and Reduction Protocol | 可扩展分层次聚合和归约协议,NVIDIA 推出的一种高性能集合通信协议,将聚合操作卸载到交换机,消除多次传输数据的需要 |
| DSA | Domain Specific Architecture | 领域专用架构,是一种针对特定应用场景进行优化的芯片架构,旨在提高芯片的性能和效率 |
| 英文 | 缩写 | 中文释义 |
03.算力需求膨胀,大模型训练需要多少卡
昂贵 H100 的一时洛阳纸贵,供不应求,大模型训练究竟需要多少张卡呢?GPT-4 很有可能是在 10000 到 20000 张 A100 的基础上训练完成的[8]。按照 Elon Musk 的说法,GPT-5 的训练可能需要 3 万到 5 万张 H100,尽管之后被 Sam Altman 否认,也可窥见大模型训练对于算力的巨大需求。 Inflection 公司宣布他们正在构建世界上最大的 AI 集群,包含 22000 张 NVIDIA H100,FP16 算力可以达到 22 exaFLOPS,如果更低精度的算力(也就是 FP8)得到使用,则可以获得更高算力 [9]。这是一个非常惊人的数字,要知道 Frontier 超级计算机是目前唯一达到 ExaFLOPS 算力量级的超级计算机。对比目前排名第七的神威太湖之光超级计算机,最大算力也只有 94.64 PetaFlOPS。Inflection 自豪地宣称,如果参与超级计算机 Top 500 排行[10],他们可以很轻松地排到第二名,并且逼近排名第一的 Frontier 超级计算机。
The deployment of 22,000 NVIDIA H100 GPUs in one cluster is truly unprecedented, and will support training and deployment of a new generation of large-scale AI models. Combined, the cluster develops a staggering 22 exaFLOPS in the 16-bit precision mode, and even more if lower precision is utilized. [9]
Inflection 基于超过 3500 张 NVIDIA H100 实现了在 C4 数据集下仅用了不到 11 分钟,即训练完 GPT-3 的模型[11]。对比 OpenAI 在 2020 年时使用数千张 NVIDIA V100 训练 GPT-3,花了一个月左右的时间,对比 V100,H100 算力显著增长。这里截图不全,只大致反映当前参与 Benchmark 的厂商与系统[12]。
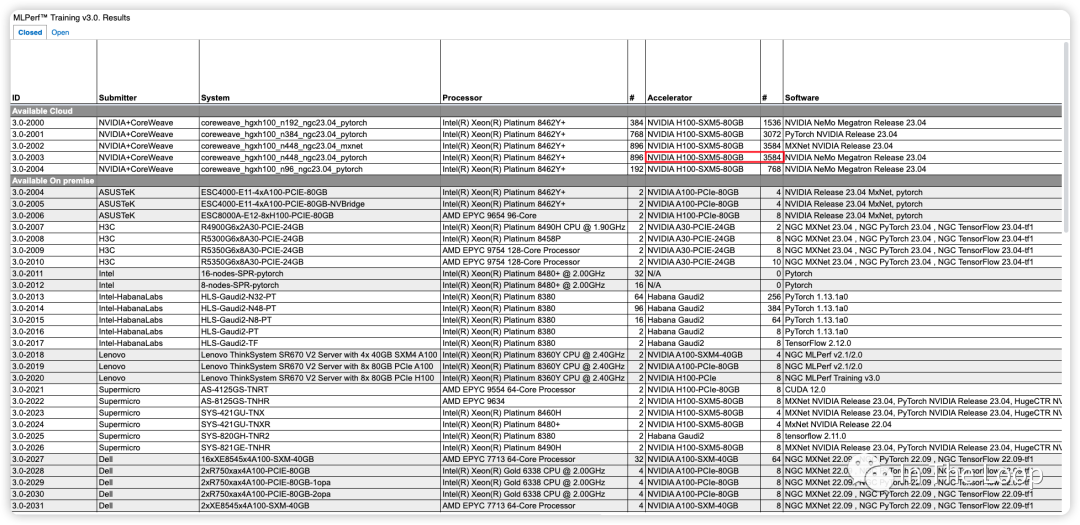
22000 张 NVIDIA H100 构成的 AI 集群,微软和英伟达投资给 Inflection 的 13 亿美元也许就要花去大半了。这一幕令人惊奇,也许存在泡沫,但真金白银不会骗人,我们也好好算算为什么需要这么多卡。OpenAI 早在 2020 年的 Scaling Laws[13] 论文中给我们提出了一个经验公式:
这里面:
C是训练一个 Transformer 模型所需要的算力,单位是 FLOPs
P是一个 Transformer 模型中参数的数量
D是训练数据集的大小,也就是用多少 tokens 来训练
π是指训练集群中所有硬件总的算力吞吐,单位是 FLOPs,计算方法为
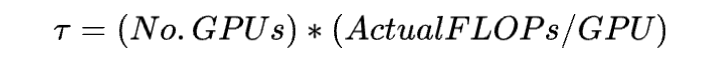
T是指训练这个模型需要的时间,单位是 seconds
Scaling Law 论文 Section 2.1 对于这个公式的做了简单的推导,在 forward pass需要的 FLOPs 数为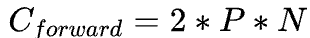 ,在 backward pass 需要的 FLOPs 数大致是 forward pass 的 2 倍,因此
,在 backward pass 需要的 FLOPs 数大致是 forward pass 的 2 倍,因此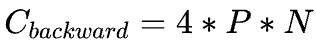 ,这即是系数 6 的来源。 之所以有这样简洁的公式,是因为无论是 bias vector addition,layer normalization,residual connections, non-linearities,还是 softmax,甚至是 attention 的计算都不是占算力的主要因素,最关键的还是 Transformer 中的矩阵运算。
,这即是系数 6 的来源。 之所以有这样简洁的公式,是因为无论是 bias vector addition,layer normalization,residual connections, non-linearities,还是 softmax,甚至是 attention 的计算都不是占算力的主要因素,最关键的还是 Transformer 中的矩阵运算。
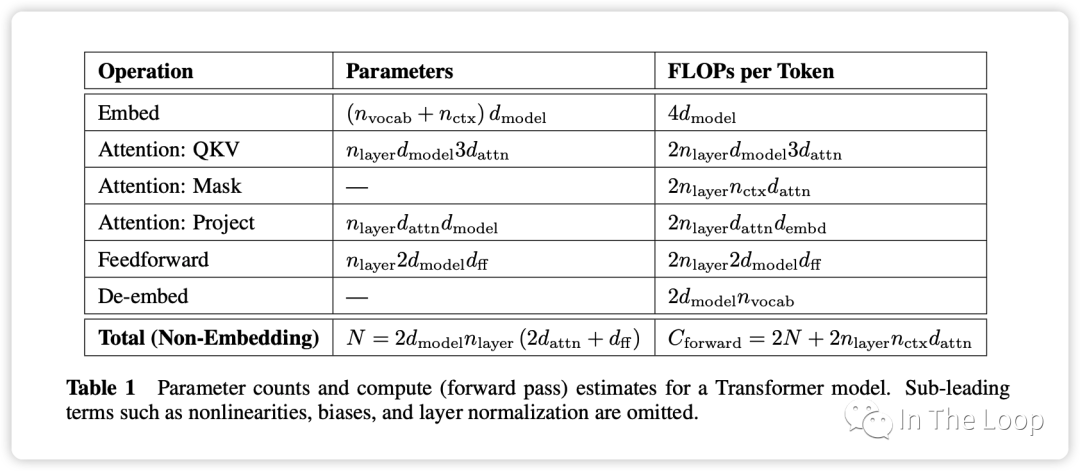
Parameter counts and compute (forward pass) for a transformer model, Source: Scaling Law Paper 记住上面的假设之后,我们就可以简单地算出这里的系数 6 了,前向 2 次,反向 4 次,如下图所示。
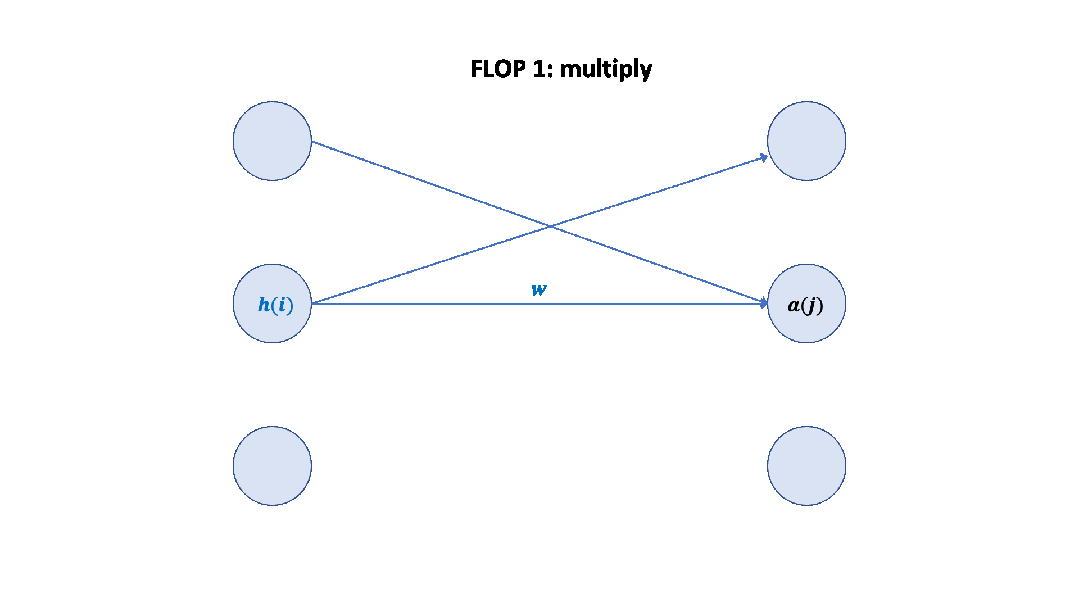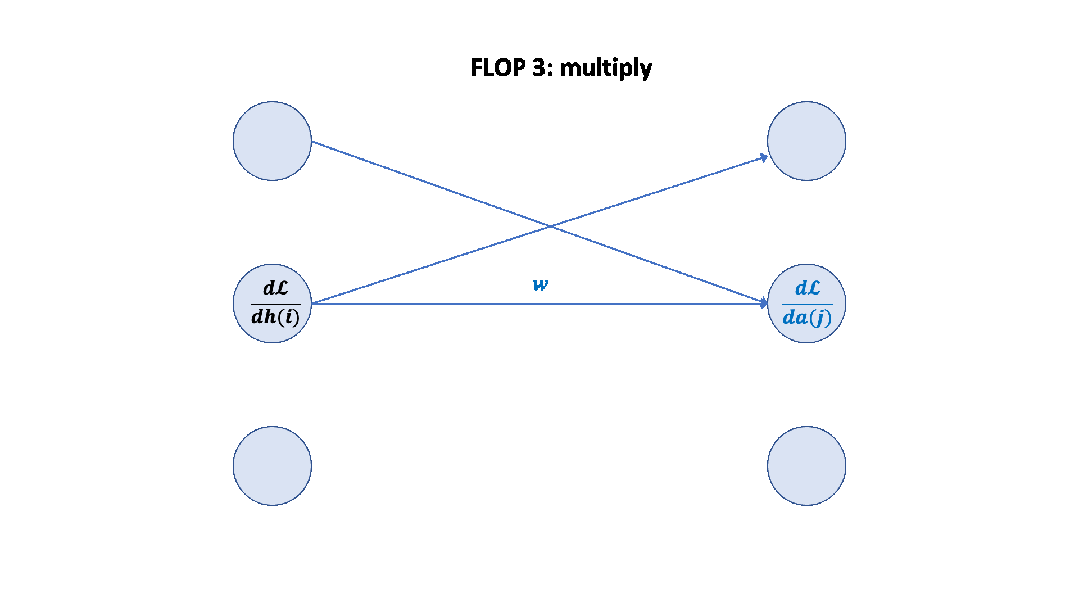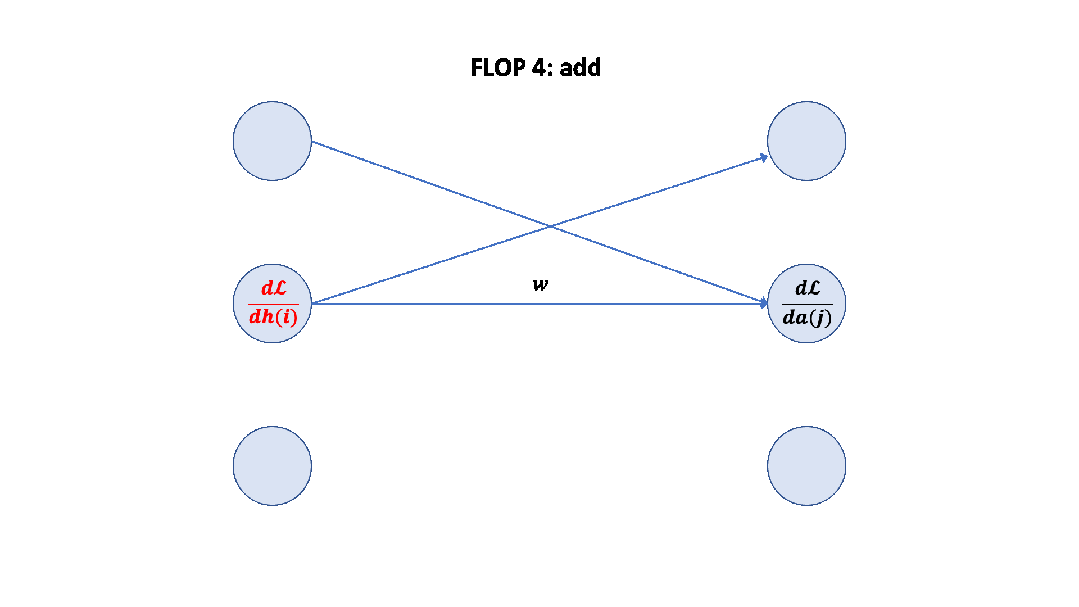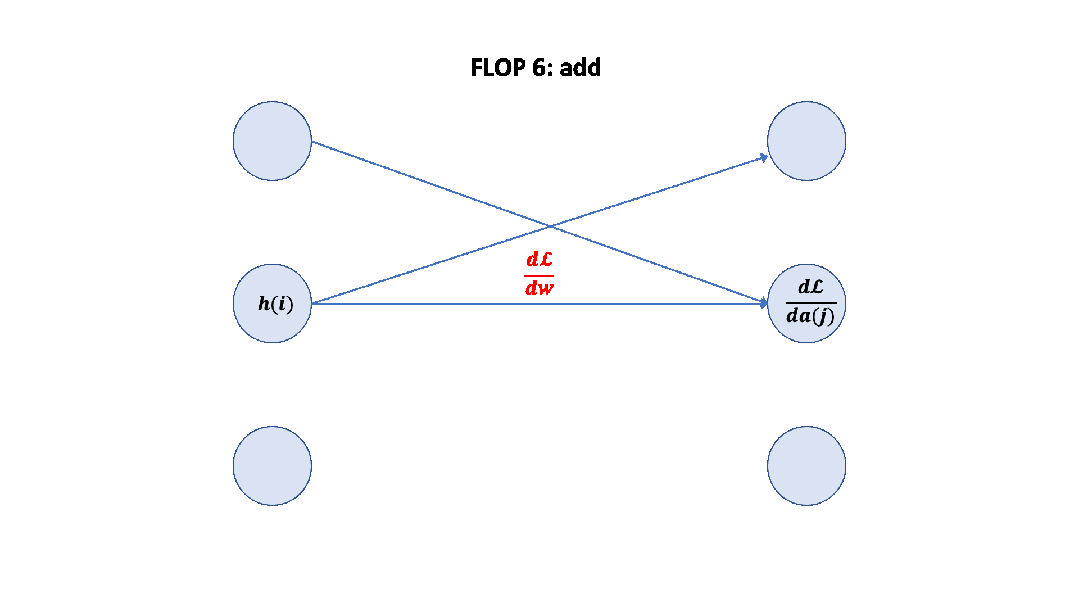
至此,基于上面的假设,我们已经推导出了经验经验公式中 6 的来源,至于为什么这个假设是正确的,可以参考 Scaling Law 的论文或者这篇文章[14]。
这个经验公式在 GPT-3 的论文中也再次得到了验证,可以看到对于 GPT-3 这种 decoder-only 结构的 transformer 模型,每个参数每个 token 所需要的 FLOPs 即为 6。而对于 T5 这种 encoder-decoder 结构的 transformer 模型,在 forward pass 和 backward pass,因为对每个 token 只有一半的参数是 active 的,因此这个经验公式里面的系数为 3。
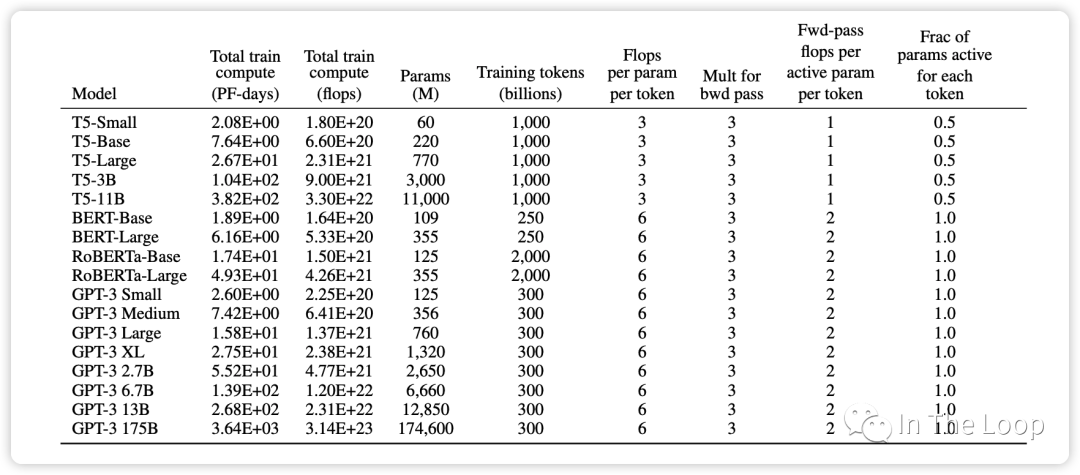
在计算所需算力的时候,我们刚才都是使用 FLOPS 这个单位,也就是 FLOP-seconds,Scaling Laws 论文中倾向于使用 PetaFLOP-days 的单位,这样能够更加直观的感受出训练一个模型需要多长时间。以 Meta 年初开源的 LLaMA-1 为例,65B 的模型基于 1.4T 的 tokens 训练,使用了 2048 块 NVIDIA A100 GPU,那么需要训练多久呢?
所需算力
NVIDIA A100 WhitePaper 中给出 BF16 Tensor Core 的算力为 312 TFLOPS[15],但是实际上算力一般在 130 到 180 TFLOPS 中间,这里我们取中间值 150 TFLOPS[16]
根据实际算力计算集群算力吞吐为
训练 LLaMA-1 所需耗时为
这一计算和 LLaMA-1 在论文中实际训练时间基本一致:
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.
LLM Training Cost, Source: https://karpathy.ai/stateofgpt.pdf
进一步计算,NVIDIA H100 WhitePaper 上给出 BF16 1979 TFLOPS,因为这个指标包含了 sparsity,实际稠密算力大约在 1000 TFLOPS[17]。对比 A100,差不多有 3 倍的增长,那么同样数目的 GPU,不考虑其他因素做最粗糙的计算,LLaMA-1 65B 的训练时长差不多可以减少到 10 天以下[18]。考虑到 H100 新推出的 FP8 Tensor Core 3,958 TFLOPS 的算力,以及新一代 NVLink Network 的通信带宽,训练速度可以进一步加快,GPT-3 175B 训练可以相比 A100 可以快 6 倍多。
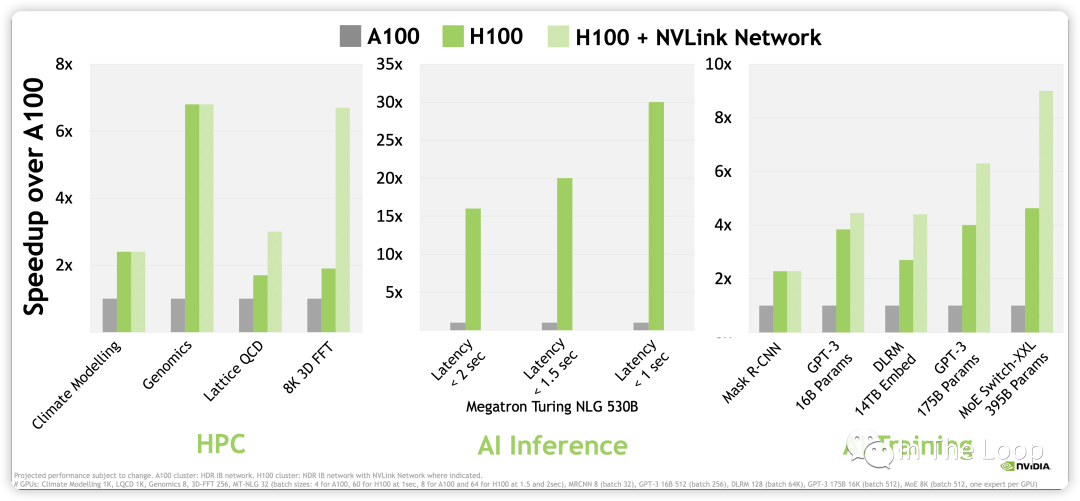
NVIDIA H100 vs A100 Performance, Source: NVIDIA WhitePaper
除了性能上相对于 A100 有明显优势,H100 在成本上也优于 A100。虽然 H100 在单位成本上是 A100 的 1.5 到 2 倍,但是效率上是 A100 的 3 倍,因此 H100 的每美元性能要比 A100 要更高。这就是老黄说的 「The More You Buy,The More You Save」,NVIDIA 赢麻了 。

Estimated times and cost for a 7B model on 8x NVIDIA H100 vs. 8x NVIDIA A100, Source: MosaicML
通过上面的计算,我们可以看到 LLM 训练对于 GPU 提出的巨大需求,也看到了 H100 相对于 A100 的巨大优势,这也是为何目前 H100 供不应求的原因之一。接下来,本文会尝试深入到 H100 硬件,看看 H100 比 A100 到底好在哪里。
04.H100 系列产品线长什么模样
NVIDIA 的产品线比较复杂,包括了数据中心,到专业工作站,以及消费级 GPU 和嵌入式等不同场景,其系列产品名称也比较复杂,你可以在这里[19]看到。
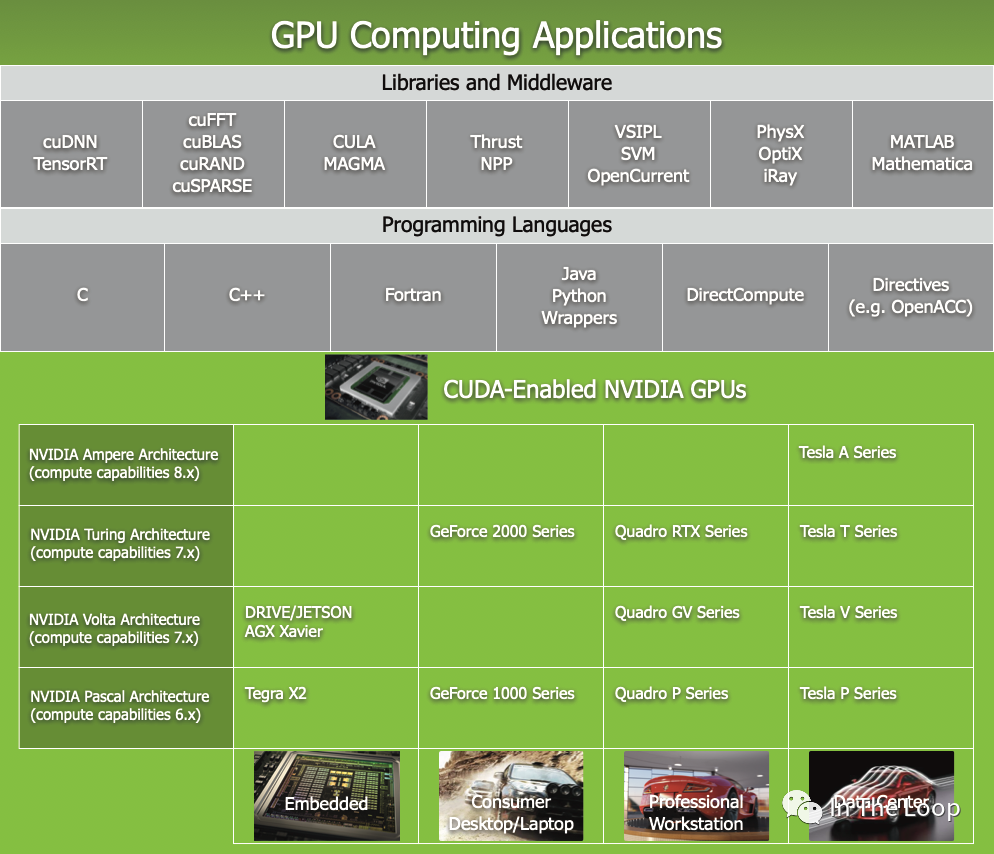
本文主要关注数据中心 H100 的系列产品线,在深入到具体硬件体系结构之前,我们先看看 NVIDIA 基于 H100 的系列产品线模样,对 HGX 和 DGX 先有一个粗略的印象。
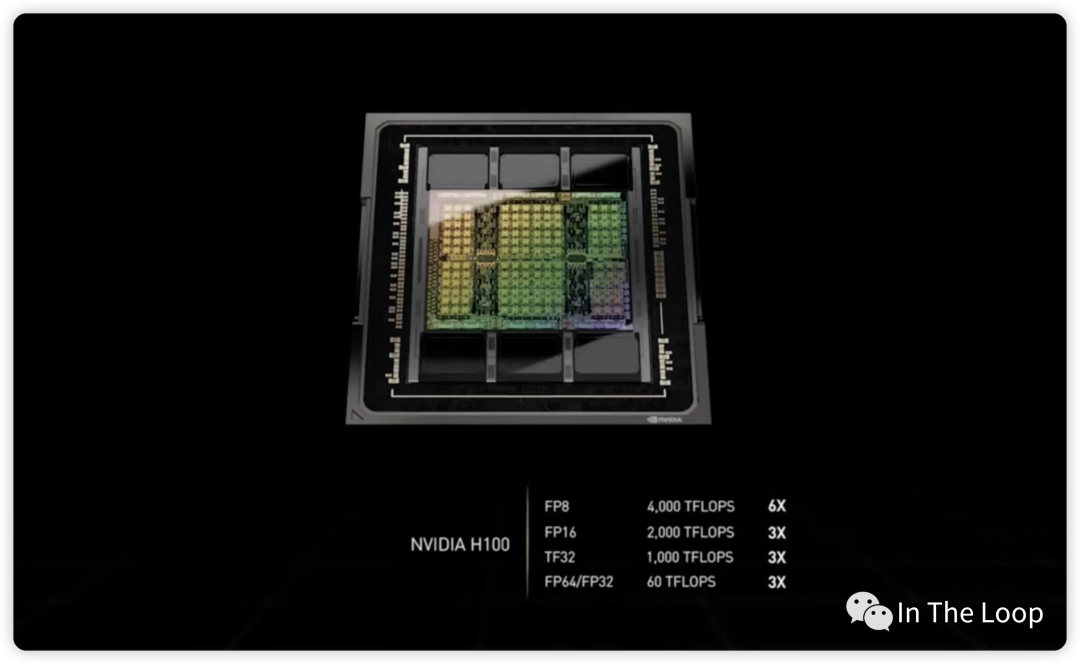
这个是 H100 GPU 芯片,包含 HBM3 高速显存,通过台积电的 CoWoS 技术封装在一起
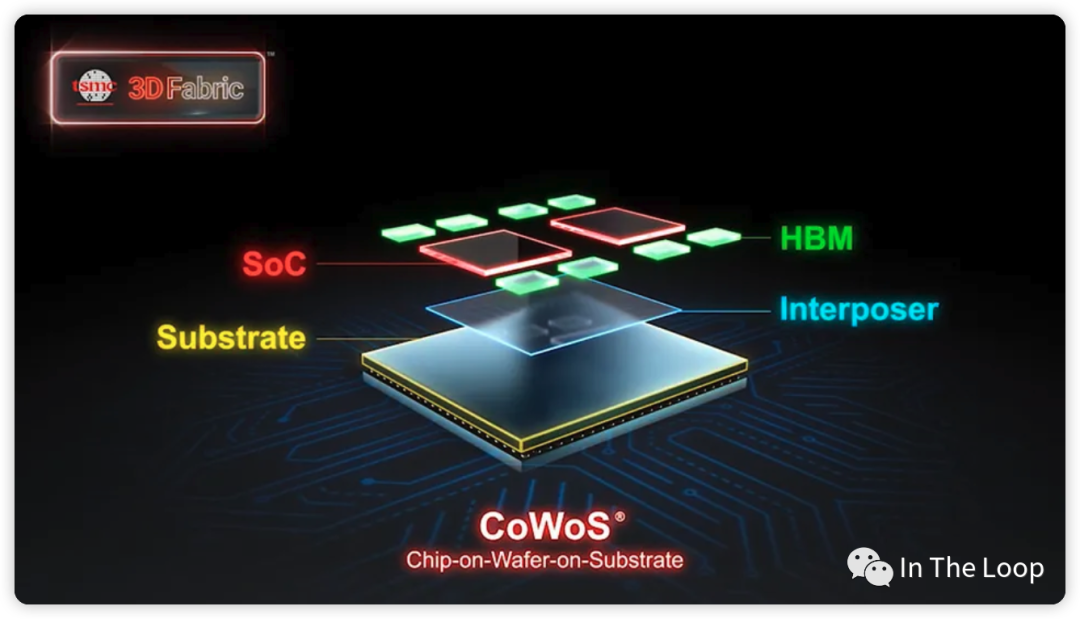
台积电的 CoWoS 技术大概是这样,Credit: TSMC

这是 H100 GPU 封装在 SXM5 模块中

NVIDIA HGX H100,由8个H100 SXM5 模块加上4个NVSwitch Chip 在同一个 system board 上
值得注意的是,这 4 个 NVSwitch Gen3 芯片总共具有 3.6 TFLOPS 的 SHARP In-Network Computing 计算能力,此处暂时不表,后面再写篇文章聊聊 SHARP。

DGX H100 在 HGX 100 的基础上,进一步配置了 CPU、存储与网卡

进一步 ScaleUp DXG H100,将32个 DGX 聚合到一起,形成 DGX H100 SuperPod

上个月 NVIDIA 又发布了 GH200,实际上就是 Grace CPU 加上 Hopper GPU
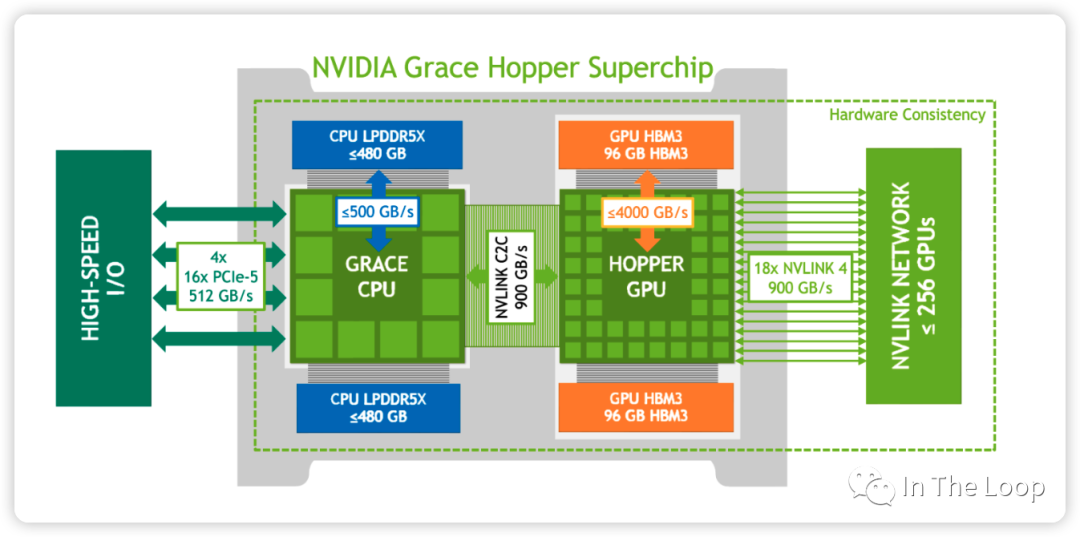
这是他们之间的逻辑链路
05.CUDA 编程模型与 H100 体系结构
本节将会结合 NVIDIA CUDA 的编程模型,对照分析 H100 GPU 体系结构。如下图所示,满配的 GH100 有 8 个 GPC,每个 GPC 有 9 个 TPC,每个 TPC 内有 2 个 SM,总共有 144 个 SM。基于 SXM5 的 H100 砍掉了 6 个 TPC,只有 66 个 TPC,总计 132 个 SM。
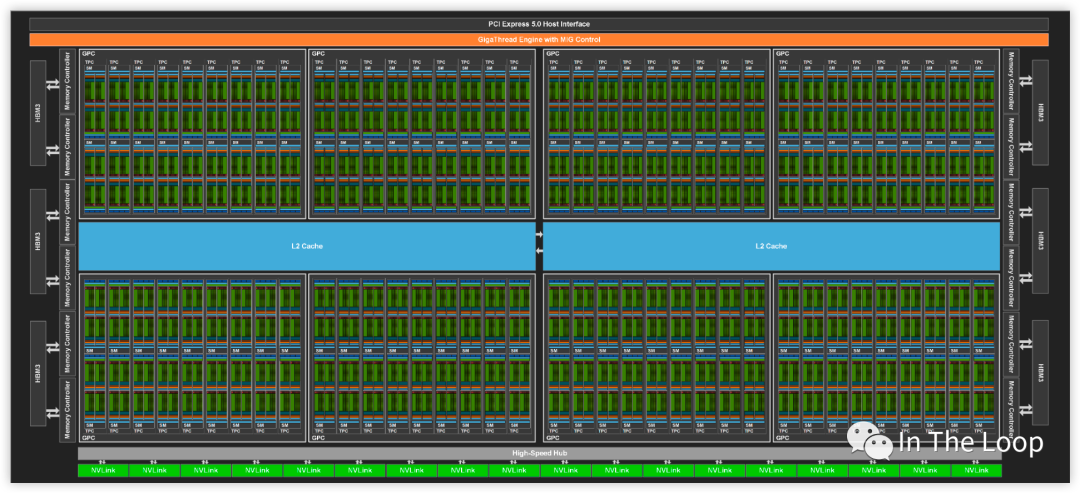
H100 支持第四代 NVLink 和 PCIe Gen5,支持 6 个 HBM3 Stacks,DRAM 带宽达到 3TB/s,L2 Cache 到 50MB。
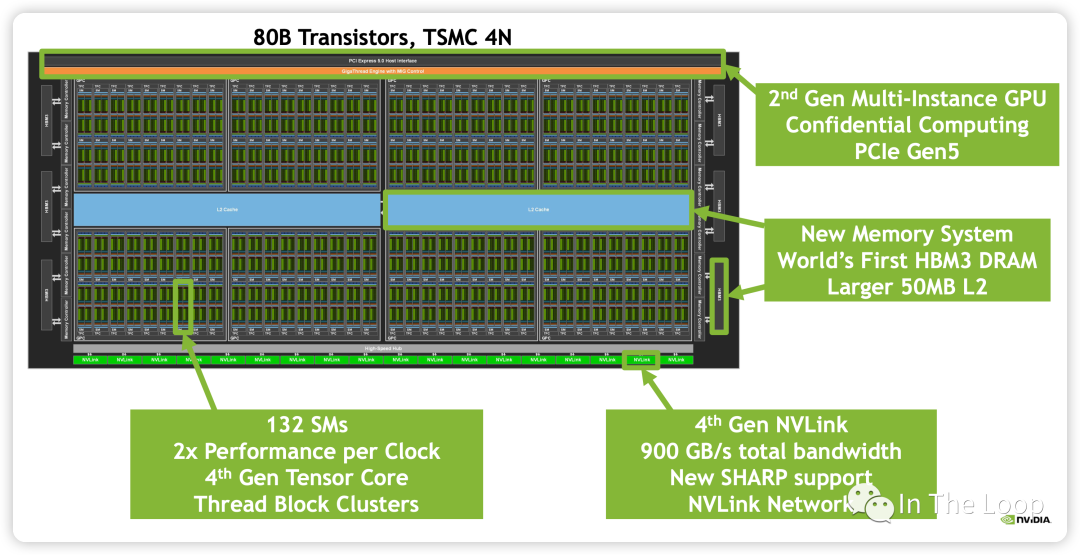
继续放大每一个 SM,查看其中组成:
| Computing | CUDA Core FP32 Unit | 128,分成四组,每组 32 个 |
| Computing | CUDA Core FP64 Unit | 64,分成四组,每组 16 个 |
| Computing | CUDA Core INT32 Unit | 64,分成四组,每组 16 个 |
| Computing | TensorCore Gen4 | 4,分成四组,每组 1 个 |
| Computing | SFU | 4,分成四组,每组 1 个 |
| Computing | Tex | 4,分成四组,每组 1 个 |
| Scheduling | WARP Scheduler | 4,分成四组,每组 1 个,32 thread/clk |
| Scheduling | Dispatch Unit | 4,分成四组,每组 1 个,32 thread/clk |
| Storage | Register File | 256KB,分成四组,每组 64 KB |
| Storage | L0 Instruction Cache | -- |
| Storage | L1 Data Cache/Shared Memory | 256KB |
| Storage | L1 Instruction Cache | -- |
| Storage | LD/ST | 32,分成四组,每组 8 个 |
| Storage+Computing | Tensor Memory Accelerator | 1 |
| Functions in SM | Component Name | Unit per SM |
包含 128 个 CUDA Core,分为 4 组,每组包含 16 个 FP64 Unit,16 个 INT32 Unit 和 32 个 FP32 Unit,这些 CUDA Core 单元可以用于超算、图形渲染等场景的计算。
包含第四代 Tensor Core,此处暂时略过,在 Tensor Core 那节会详细介绍。
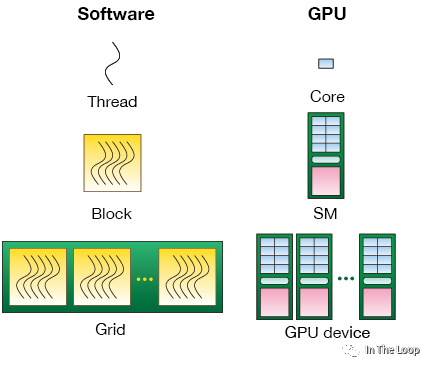
密集恐惧症者看到 SM 这密密麻麻的计算核心或许会有点害怕,为了更好的理解 NVIDIA GPU 的结构,我们看可以看下面的简化版本:
对于每一个 GPU,通过 GPC 和 TPC 的层级可以划分为很多的 SM
SM 进一步可以划分为 4 组,每组都有自己的 64KB Register File 和很多的计算核心,
同一个 SM 中所有运行的 thread 共享 256KB 的 Shared Memory 和 L1 Data Cache
同一个 GPU 内的所有 SM 共享 50MB L2 Cache 和 80GB HBM3 Memory
进一步向外看,同一个节点上的 GPU 通过 NVLink/NVSwitch 连接在一起
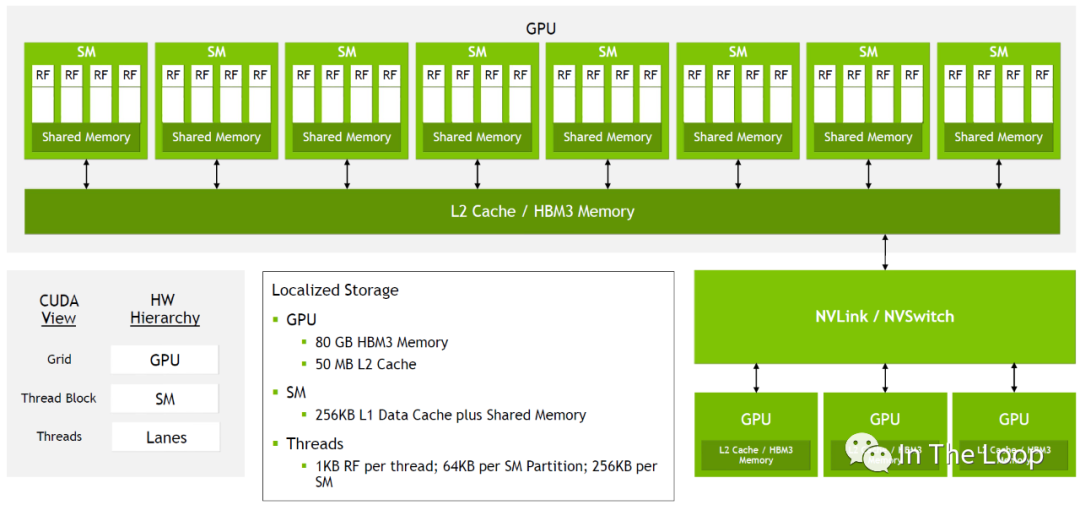
简化的 H100 结构
这张图里面我们已经看到了对应于硬件,从软件层面 CUDA 编程模型中的视角,我们进一步介绍 CUDA 编程模型。在 CUDA 编程模型中,CPU 和主存被称为 Host,GPU 和显存被称为 Device。CUDA 程序中既包含 Host 程序,又包含 Device 程序,它们分别在 CPU 和 GPU 上运行。
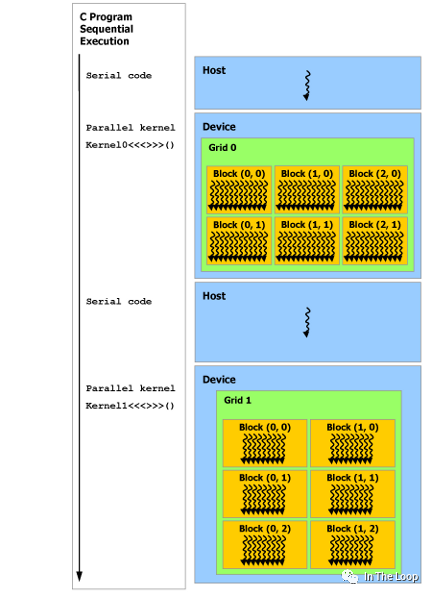
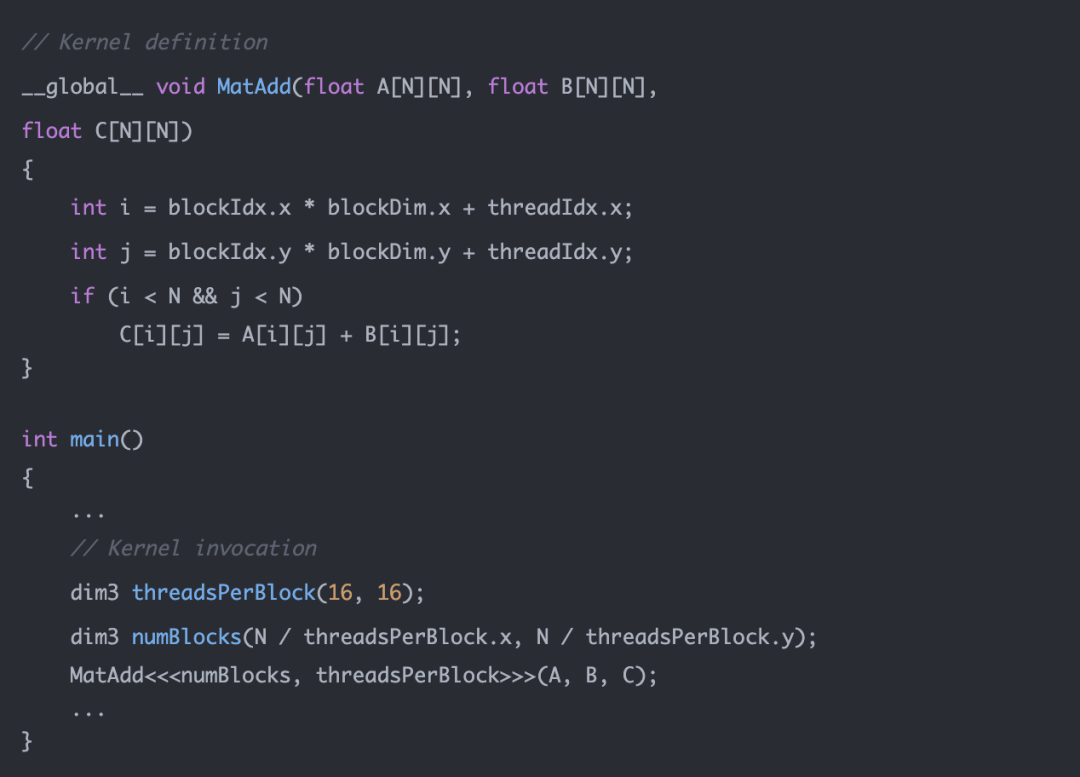
为了实现 GPU 并行加速计算,我们需要在 Host 上执行 kernel launch,让核函数在 Device 上的多个线程并发执行。CUDA 将核函数所定义的运算称为线程(Thread),多个线程组成一个块(Block),多个块组成网格(Grid)。具体的方式就是在调用核函数的时候通过 <<
为了进一步理解这里的 CUDA 编程模型概念与硬件结构,我们继续聊聊刚才没有提到的 WARP Scheduler。NVIDIA SM 采用 SIMT 架构[21],线程束 warp 是最基本的执行和调度单元,一个 warp 一般包含 32 threads,这些 threads 以不同的数据资源执行相同的指令。
| thread | 最小的计算单元,每个 thread 拥有自己的程序计数器和状态寄存器 | 对应于 Core, or lanes |
| warp | 最小的执行和调度单元,一个 SM 的 CUDA Core 会分组成几个 warp | Warp Scheduler 一次调度一个 warp |
| block | 一个 block 中的 warp 只能在同一个 SM 调度 | 对应于 SM,一个 warp 中的 threads 必然在同一个 block |
| grid | 一个 GPU | 对应于 GPU |
| CUDA 视角 | 功能 | 硬件视角 |
虽然 warp 中的线程执行同一程序地址,但可能具有不同的行为,比如分支结构,因为 GPU 规定 warp 中所有线程在同一周期执行相同的指令,warp 发散会导致性能下降。一个 SM 同时并发的 warp 是有限的,因为资源限制,SM 要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器,所以 SM 的配置会影响其所支持的线程块和 warp 并发数量。
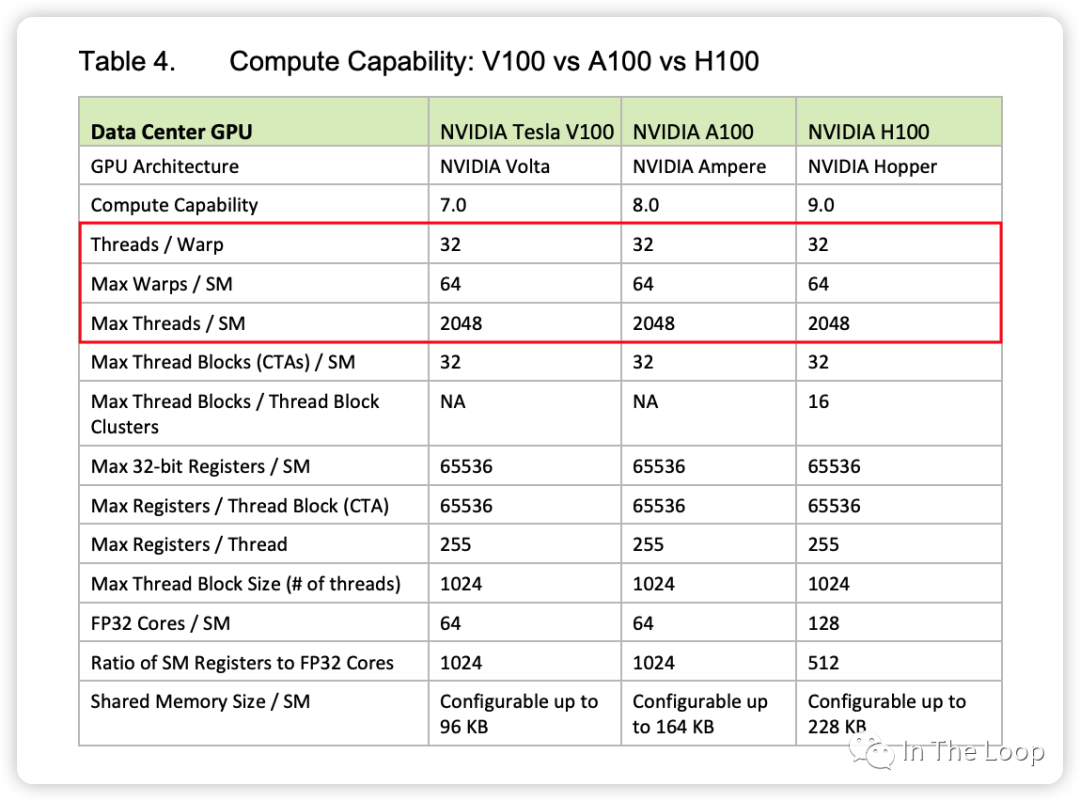
同一个 block 的 warp 只能在同一个 SM 调度运行,但是同一个 SM 可以容纳来自不同 block 的多个 warp。主流的架构中每个 SM 最大 2048 个 threads,也就是最多 64 个 warps。一个 SM 有 4 组 warp scheduler,哪个 warp ready 了就调度哪个。一般 warp 可能因为在等内存搬运、等计算 core 或者等 sync 之类的而没有 ready。warp 调度上了之后,就可以走到 dispatch unit。
到现在为止,前面介绍的 CUDA 编程模型实际上都是在 Hopper 架构以前的抽象,也就是 grid/block 两级调度,block 映射到 SM 上。随着 Cooperative Groups 的引入和异步编程的支持,多个 Kernel 之间以生产者和消费者的方式通信,SM 到 SM 之间的通信带宽也在增加。
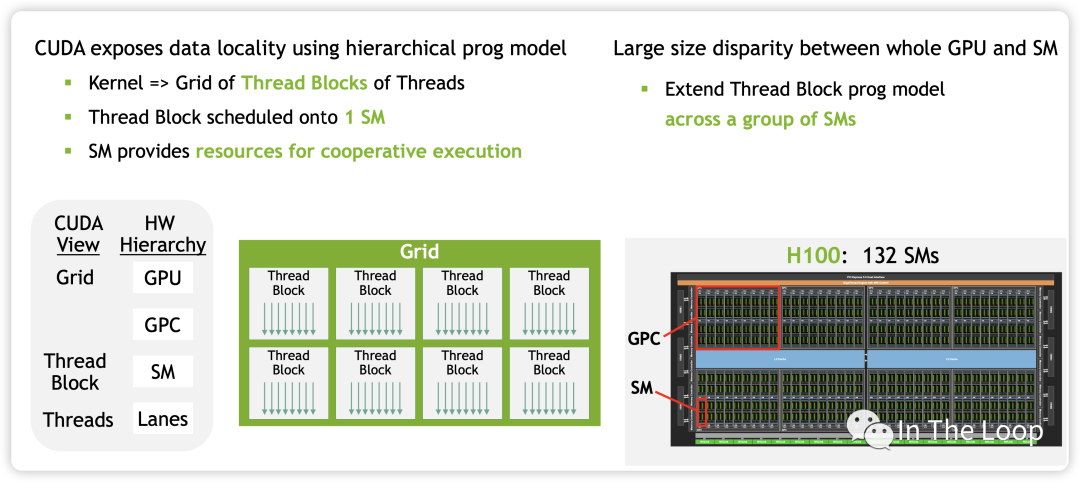
在 Hopper 架构中,新增了 Distributed Shared Memory (DSMEM) 的概念,在一个 GPC 内部的 SM 有了专用的通信带宽,因此 CUDA 上新增了一层 Cluster 的调度层次。
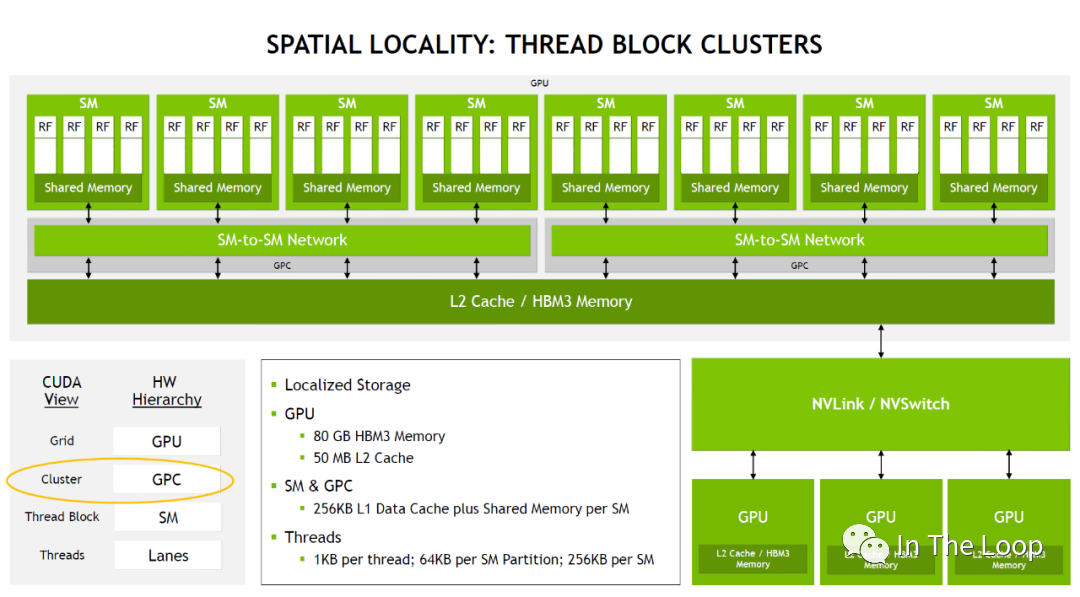
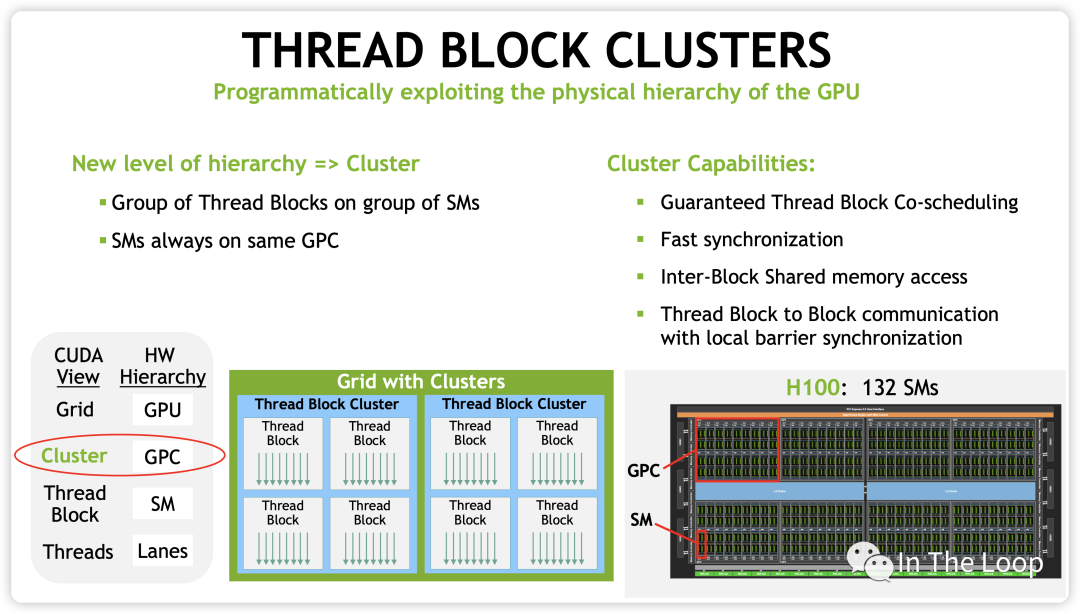
有了 cluster 这一层抽象之后,类似于同一个 block 的 threads 都会被调度到同一个 SM,同一个 cluster 的 thread blocks 都会被调度到同一个 GPC 中。
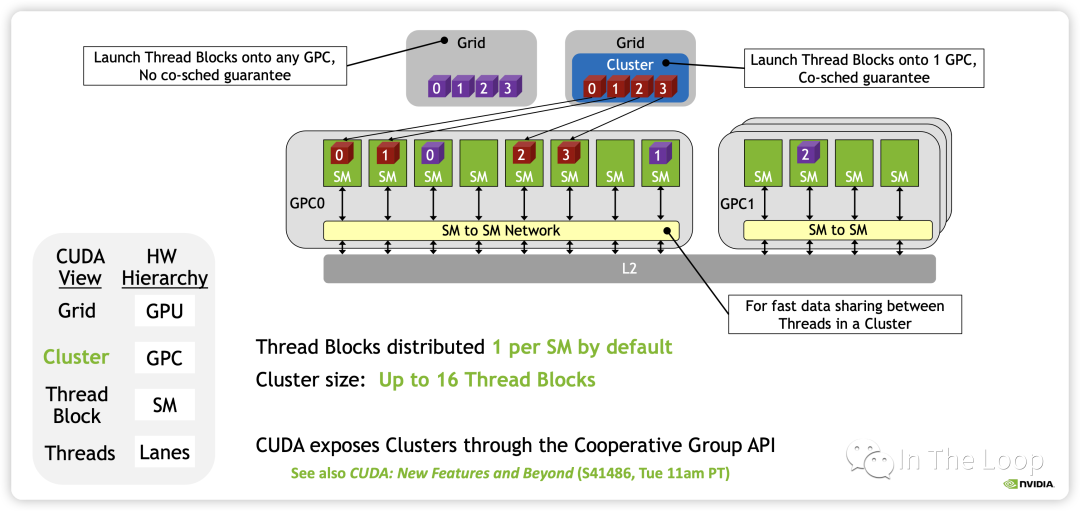
这样同一个 cluster 中不同 block 的 threads 可以通过 SM to SM Network 访问另一个 block 的 DSMEM。这样在一个 GPC 内部实现多个 SM 的 LD/ST,Atomic,Reduce 和异步 DMA 操作都变得非常的简洁。
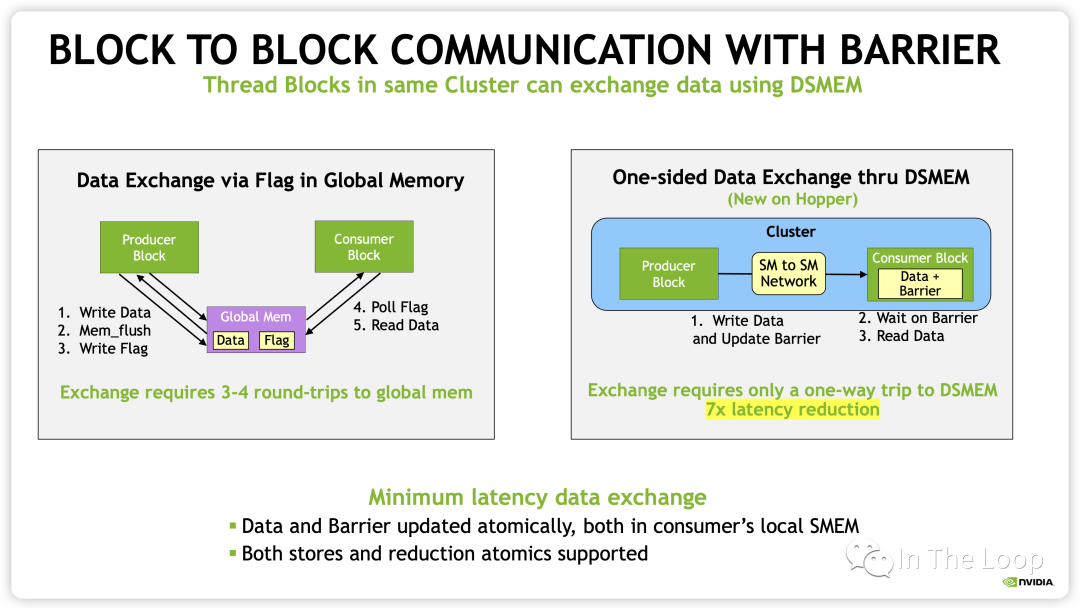
从 CUDA 编程模型的内存模型也就变成了下图所示:
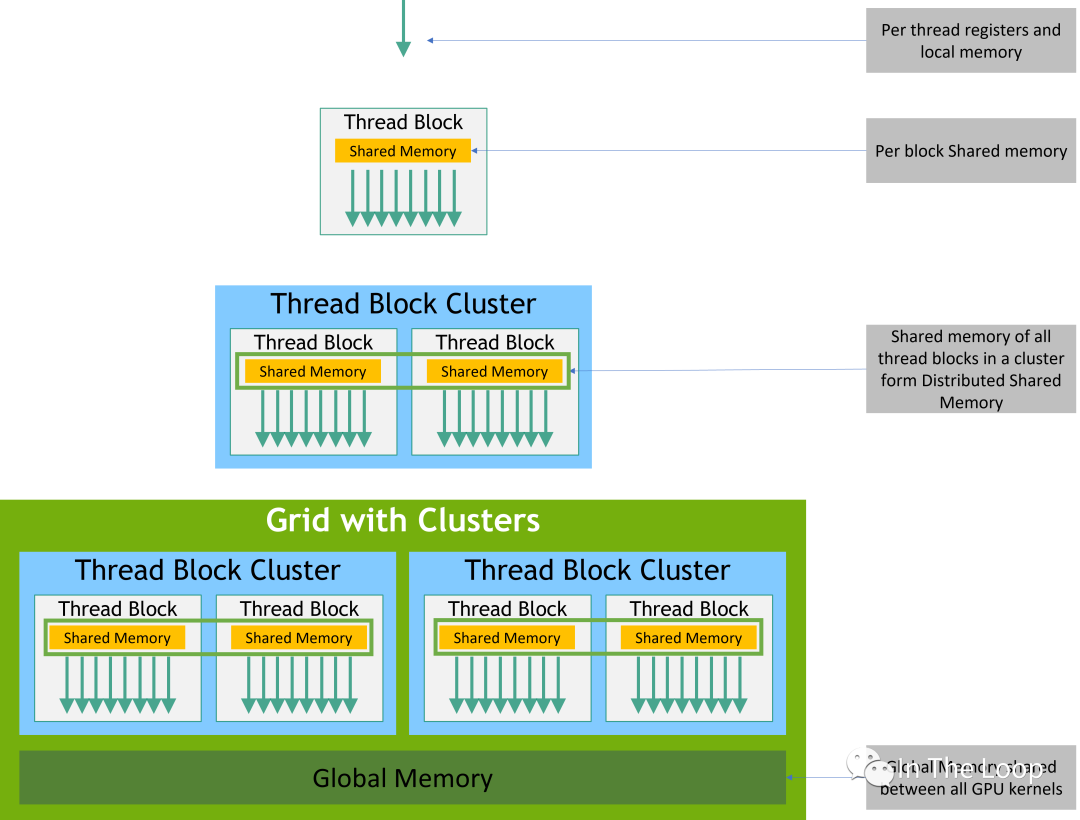
本质上看,CUDA 引入 block 和 cluster 的抽象,都是为了更好地利用空间局部性原理。Block 可以让所有的 threads 调度到同一个 SM,让 threads 可以通过 fast barriers 快速同步,并且通过 SM 的 Shared Memory 交换数据。随着 GPU 的 SM 越来越多,仅仅使用 Block 这一层抽象已经不能够更好地利用局部性原理,因此 Hopper 引入了 Cluster 这层抽象,让所有的 threads 运行在同一个 GPC 内部。
总结:本小节简单介绍了下 NVIDIA CUDA 编程模型与对应的 GPU 硬件体系结构。事实上,NVIDIA 的硬件体系结构是在不断变化的,从最早 Telsa 架构的 SIMT 模型,到 Volta 架构为每个 Thread 引入独立的程序计数器 PC,再到后面 Cooperative Groups 和异步编程 API 的引入,这些设计是经过了各种权衡和 tradeoff 做出的。关于 NVIDIA 系列 GPU 架构的演进,强烈推荐 zartbot 的系列文章[22]。
06.CUDA Core 与 Tensor Core 的演进
在深度学习中有大量的
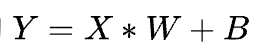
计算,然后通过激活函数传递到下一层神经网络。这是一个典型的 GEMM 操作,对于 GEMM 的优化是一个非常有意思的话题,从数学角度 Strassen 等算法的优化,到计算机角度利用访存局部性[23]等原理进行优化,乃至各种硬件层面的优化,都可以做的非常深。 2016 年 Google 发布 TPU[24],基于脉动阵列[25]这一古老技术从硬件上优化矩阵乘法,吹响了各类 DSA 的 AI 芯片挑战 NVIDIA GPU 的号角。在 SIMT 道路上一路前行的 NVIDIA 积极应战,在上一波深度学习喧嚣的高潮也就是 2017 年发布了 Volta 架构,开始走上 DSA 的路子,引入了 Tensor Core。

Volta Tensor Core vs Pascal CUDA Core
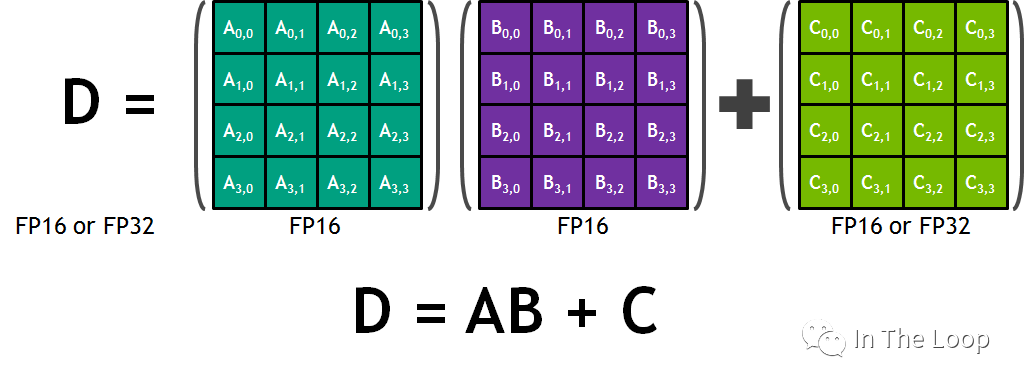
与 CUDA Core 在单位时钟周期只能执行一次浮点乘法计算不同,Tensor Core 在单位时间可以执行一次矩阵乘法。以 Volta 架构为例,Tensor Core 可以支持每个时钟周期 4 x 4 x 4 混合精度乘加,其中 A 矩阵和 B 矩阵都是 FP16 的精度,C 矩阵和 D 矩阵是 FP16 或者 FP32 的精度。
在深度学习中,相对于 HPC 领域标准 IEEE 浮点数计算,混合低精度计算更加常见。因此在 Volta 架构之后,NVIDIA 依次在之后的架构加入了更多低精度计算到 Tensor Core 中。
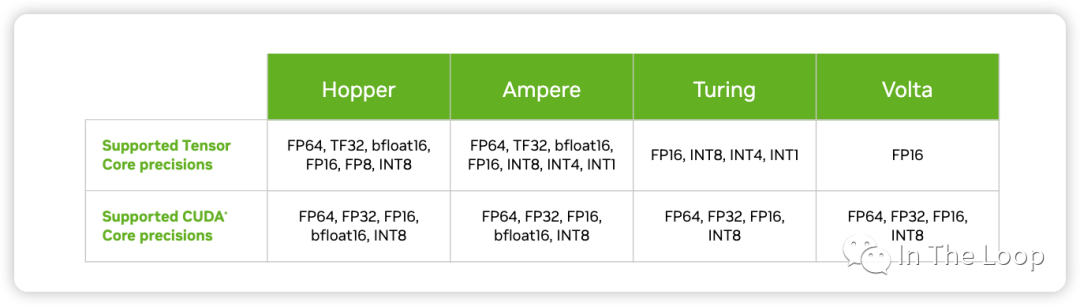
Turing 架构加入支持 INT8/INT4/INT1 的数据类型。Ampere 架构中加入新的 BF16 和 TF32 数据类型,并加入对于 Sparsity 的支持,并且每个 TensorCore 在每个时钟周期支持的混合精度矩阵乘加从 Volta 的 4 x 4 x 4 进化到 8 x 4 x 8。
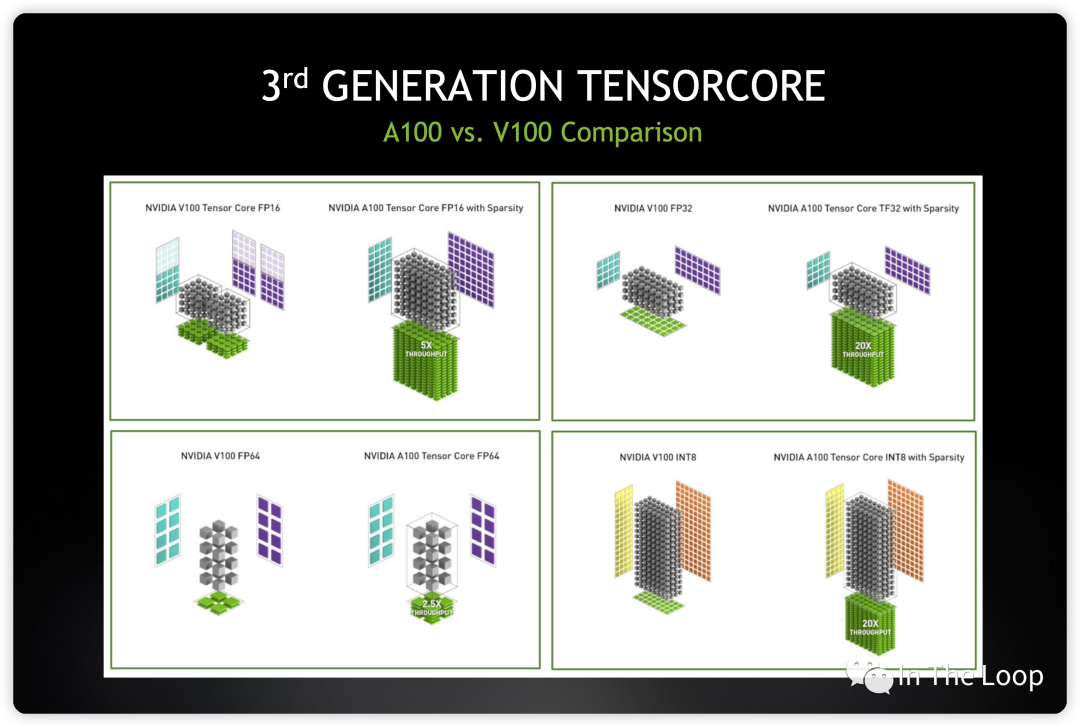
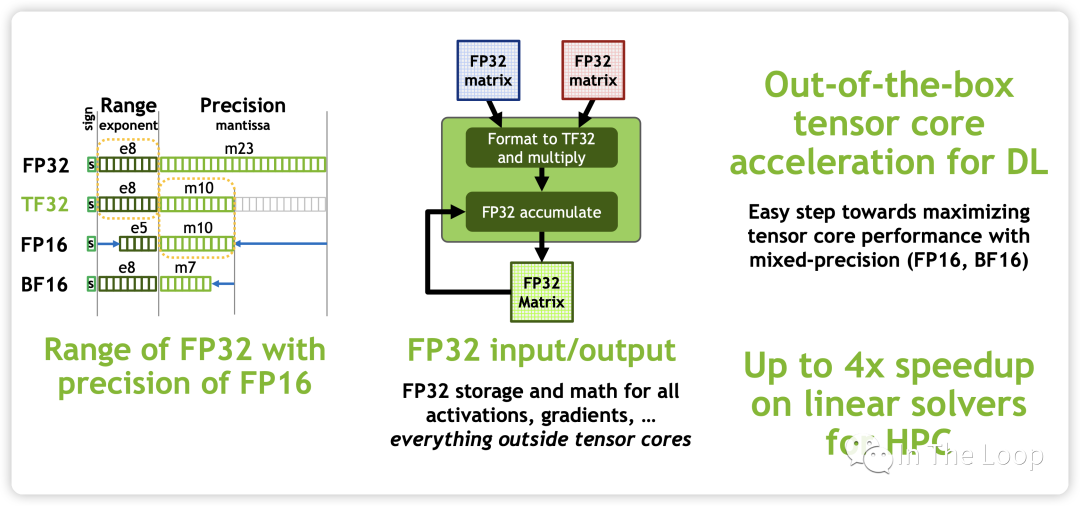
新增的 TF32 不会遇到 FP16 那样溢出的问题,同时配合新的 BF16 和 FP32 可以实现阶梯精度提升,而对于一个乘法器而言,又节省了芯片面积。BF16 数据格式是32位 IEEE 754单精度浮点格式(float32)的截断(16位)版本。它保留了32位浮点数的近似动态范围,保留了指数的8位,但只支持8位精度。Bfloat16用于降低存储需求,提高机器学习算法的计算速度[26]。
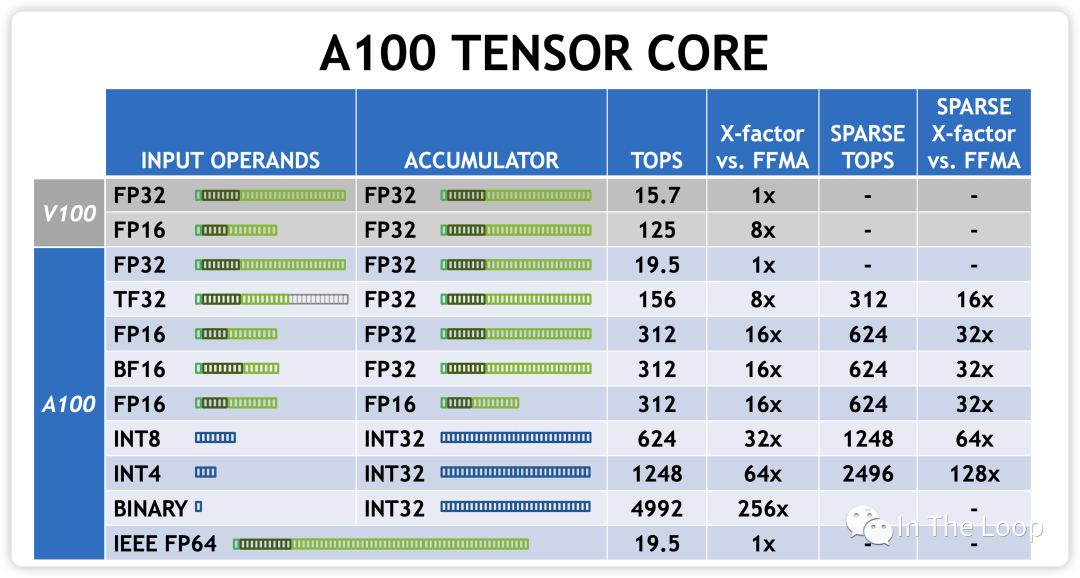
从而算力进一步增加:
到了 Hopper 架构,每个 TensorCore 在每个时钟周期支持的混合精度矩阵乘加进化到 4 x 8 x 16。TF32,FP64,INT8 Tensor Core 相对于 Ampere 有了 3 倍的性能提升。

同时,也加速了 Spare 张量计算:
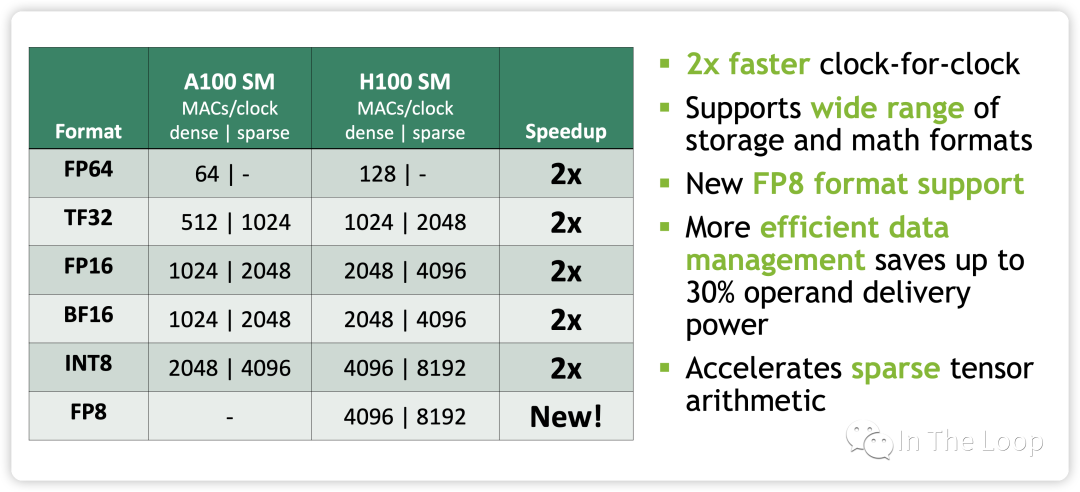
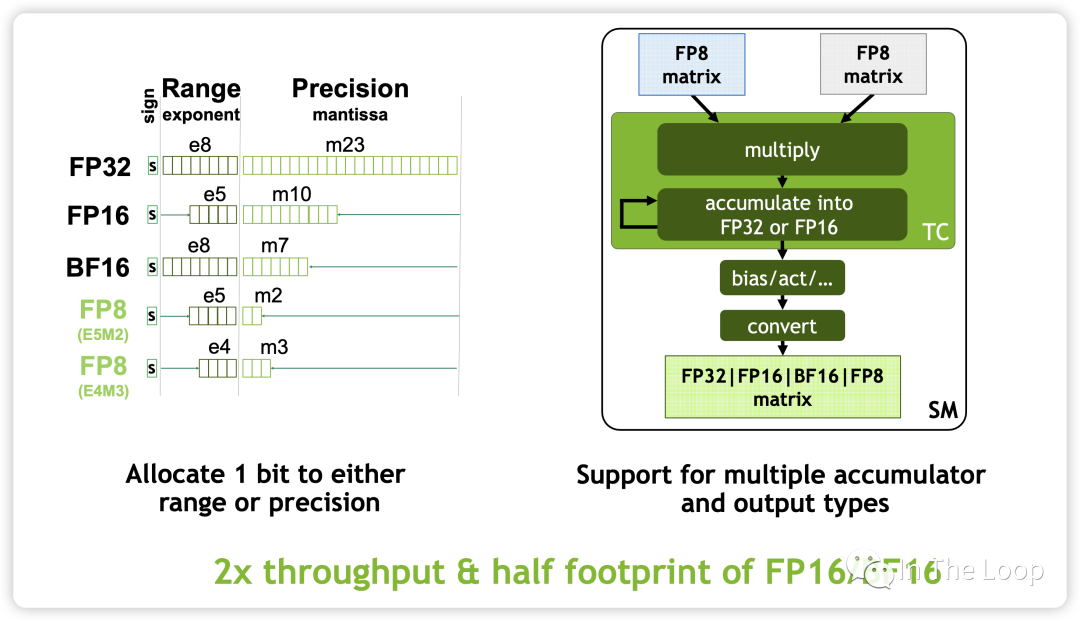
最重要的是,NVIDIA 在 Hopper 架构 TensorCore 引入了 FP8 的数据类型,并针对 Transformer 架构提出了 Transformer Engine 的技术,这个我们在下一小节会进一步阐述,此处暂时不表。
CUDA 提供了 WMMA (Warp MMA) 等底层 API 来利用 TensorCore 的硬件特性[27]。但是 TensorCore 编程并不容易,想要喂满太难了,因此 CUDA 进一步提供了类似于 CUTLASS 和 CUBLAS,CUDNN 等更上层的库来实现的,以后有机会可以进一步介绍其原理,此处暂时不表。
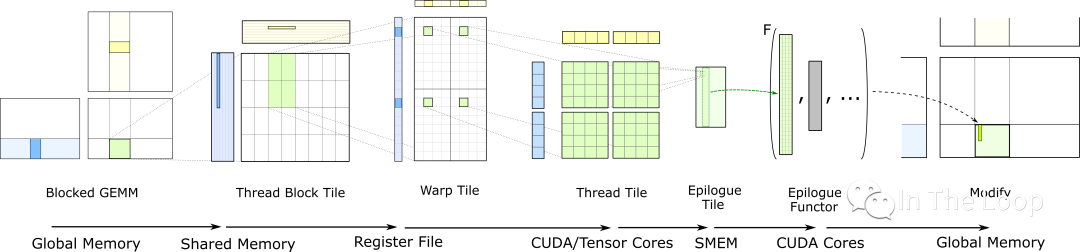
CUTLASS: GEMM Hierarchy with Epilogue
07.FP8 混合精度训练与 Transformer Engine
如前所述,Hopper 架构的一个重要特点就是 TensorCore 引入了 FP8 的数据类型,这也是 H100 相对于 A100 的一个巨大优势。
为什么要 FP8 的数据格式 ?
加速 math-intensive 操作:因为精度低,相对于 16-bits 的 TensorCore,FP8 快 2 倍。
加速 memory-intensive 操作:因为只占用一个字节,FP8 相对于 16-bits 能够大幅减少访问存储 traffic,也可以减少模型的内存占用
更加方便推理:在推理中使用 FP8 已经是非常流行的选择,当使用 FP8 格式训练时可以更加方便推理部署,不再需要对模型进一步量化
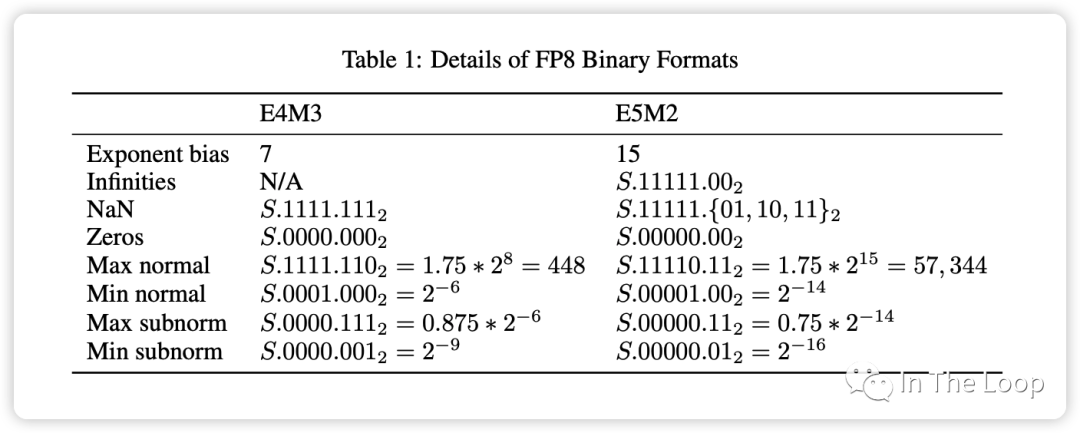
Source: FP8 Formats for Deep Learning Tensor Core 中 FP8 支持两种数据格式:
E4M3
不遵循 IEEE 754 标准,支持 NaN 和 Zero 的编码,但不支持 Inf
数据精度相对更高,可用于 fwd pass 和 inference
E5M2:
遵循 IEEE 754 标准,支持 Inf、NaN 和 Zero 的编码
数据范围更广,可用于混合精度训练的梯度表示

下图展示了 FP8 GEMM 计算的主要过程示意图:
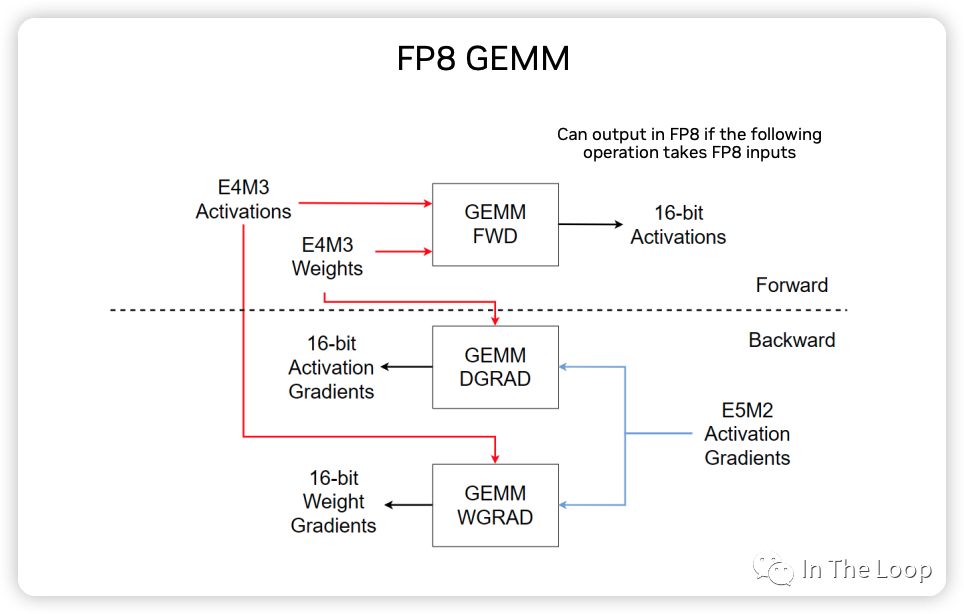
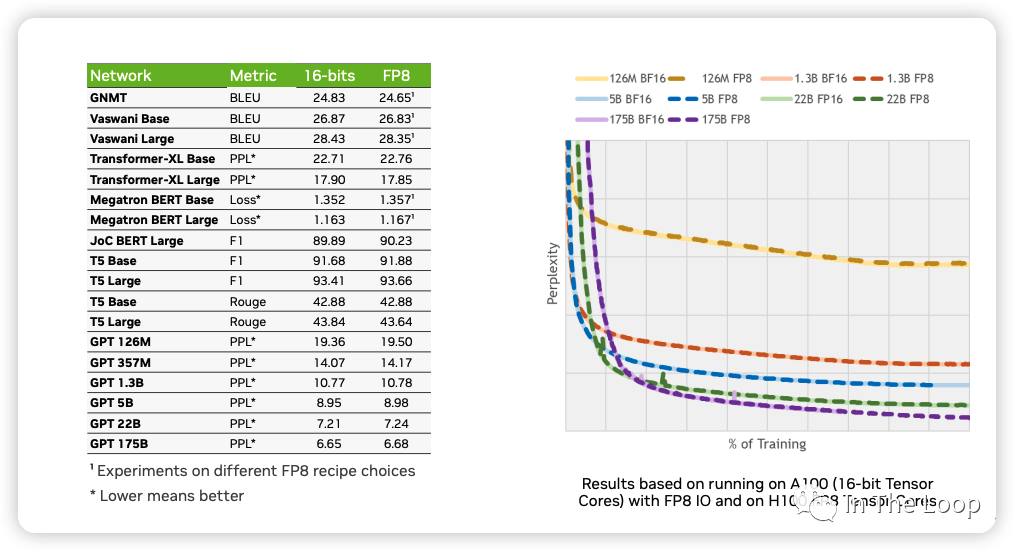
NVIDIA,ARM 和 Intel 在这篇论文[28] 中,利用 FP8 混合精度训练,在基于 Transformer 的语言模型和基于 CNN 的视觉模型等不同网络结构下进行验证,证明了 FP8 可以达到与 BF16 基本一致的效果。
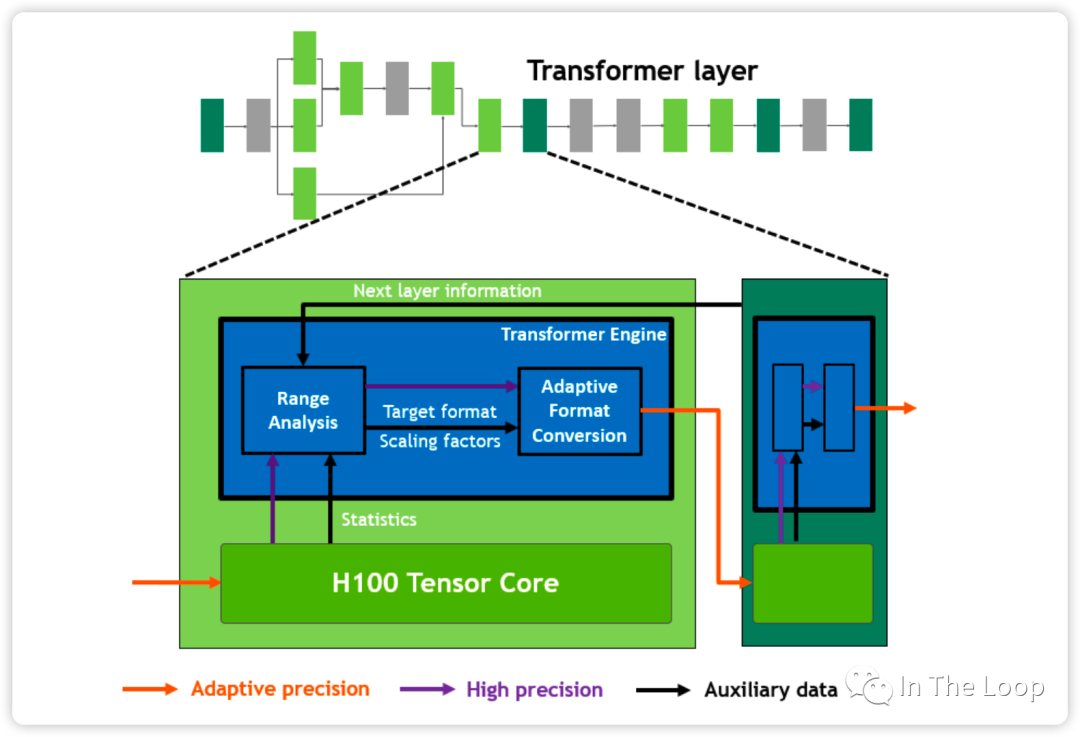
说了这么多的 FP8 混合精度训练,那么 H100 白皮书里面的 Transformer Engine 又是什么呢?实际上,Transformer Engine 并不是涉及专用的硬件结构,而是一个软件层面加速 Transformer 训练的库[29],其中提供了 FP8 混合精度训练的加速方案。Transformer Engine 本质上可以通过 label 输出的值域动态调整浮点精度,这里不再详细论述,可以参考 Transformer Engine 的官方文档[30]。
08.英伟达帝国大厦已成,头上仅剩几朵乌云
30 年前,NVIDIA 公司成立,30 年后 NVIDIA 公司市值超过万亿美元,构建了自己的庞大帝国。站在 2023 的今天回看过去三十年 GPU 市场的发展,令人感慨万千:
1983 美国电子游戏的大萧条[31] 和 80 年代个人电脑的推出,让游戏从原来的家用游戏机转移到 PC 平台,从而引发了 PC 平台下图形卡的需求。1993 年成立初期的 NVIDIA 步履维艰,正是靠着日本街机游戏公司世嘉 Sega 的资助,以及押注微软公司的 DirectX 接口,推出的 RIVA 迅速得到市场认可,并进一步推出世界第一款 GPU GeForce 256,彻底站稳市场。在那个群魔乱舞的 1990 到 2000 时代:
显卡先驱 3DFX 最终被 NVIDIA 收购
S3 被 VIA 收购逐渐沉寂
Intel 最终放弃独显专攻集显,这个剧情在 2000 年代再次重现,直到 2018 年 Intel 才真正意识到他们失去了什么,重新开始生产独立显卡
ATI 继续和 NVIDIA 争斗,最终被 AMD 收购,经过一番整合后 AMD 今日仍在竞争的一线
2000 到 2010 年代,NVIDIA 与 ATI 争霸可编程 GPU。NVIDIA 在 2006 年推出极其灵活可编程的 CUDA 架构,并坚定地在这条路上走了下去,构建了其如今最大的护城河。
2010 年代,移动互联网浪潮的到来,NVIDIA 推出 TEGRA 移动处理器尝试染指这一市场却最终平淡收场。所幸的是,2012 年之后深度学习开始崛起,NVIDIA 快速抓住了这波机会,CUDA 最终统治了这一市场,直到如今 AMD 的 ROCm 仍在苦苦维持。这十年 NVIDIA 继续高歌猛进,抓住包括加密货币和自动驾驶等在内每一个市场机会,在数据中心、HPC、专业图形等市场取得统治地位。
2020 年后,NVIDIA 收购了 Mellanox,强大的算力结合高速通信网络,NVIDIA 又讲起了 DPU 的故事,并继续慢慢培育其 DOCA 平台,试图重演 CUDA 的故事。可惜的是,NVIDIA 收购 ARM 最终没有被批准,ARM 独立上市,不然手握 CPU、GPU 和 DPU 的英伟达真的可以完全定义下一个世代的计算平台。
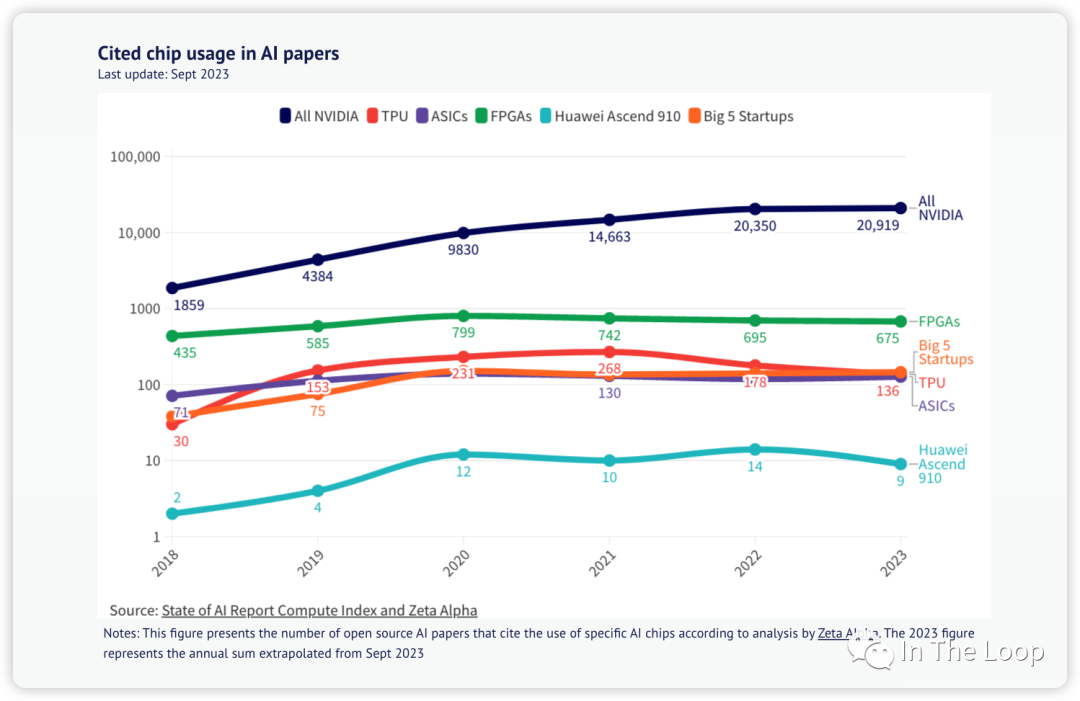
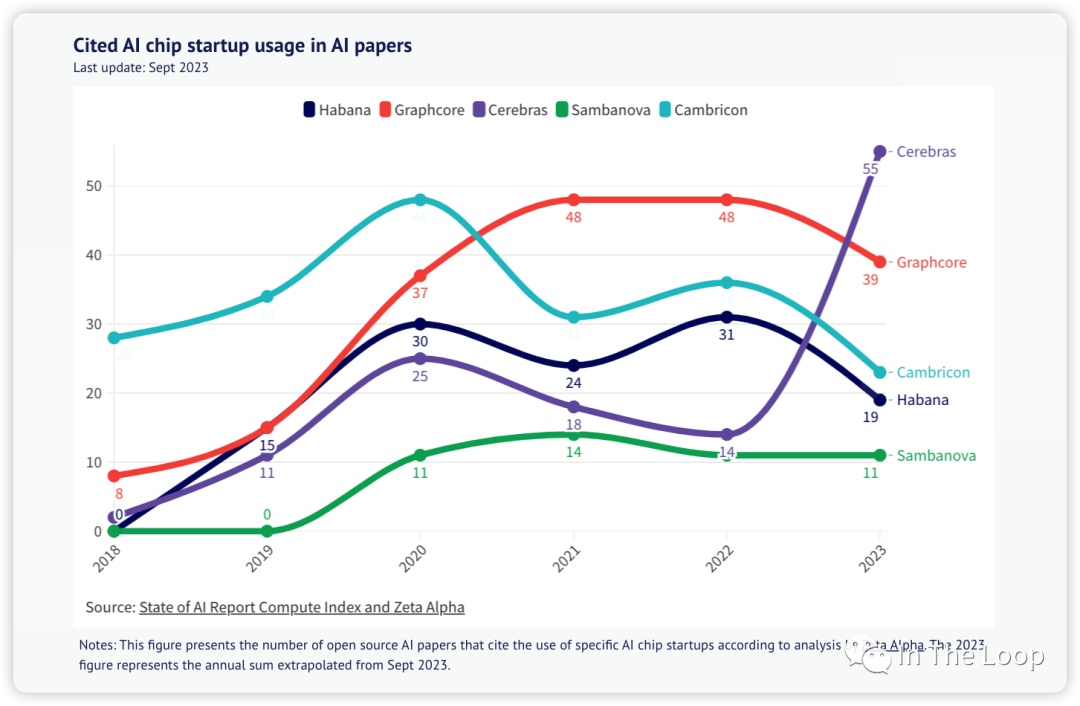
Cited chip usage in AI papers, Source: State of AI Report Compute Index 老黄的刀法让大家又爱又恨,曾经的屠龙者成为了新的巨龙。H100 如今这么贵却又卖的如此好,华为鲲鹏的夏晶老师分析了 H100 的成本[32],售价超过 3 万美元的 H100 实际物理成本可能才不到 3000 美元,这也与海外投研机构 Raymond James 分析的 3,320 美元基本一致[33],纯从物理成本上看 H100 利润率接近 1000%。虽然这样抛开研发成本看利润率不太公允,但是也可以看出 NVIDIA 的底气了。这真的是做 Infra 的最牛存在了,我可以卖的贵,我可以自己定义平台,而你还不得不抢着来用我的。恶龙仍在,天下苦英伟达久矣,仍有新的少年想要战胜恶龙。 今年 6 月,AMD 发布了 Instinct MI300 系列,其中 MI300X 直接对标 NVIDIA H100,苏妈在接受采访时,面对 CUDA 这一难以逾越的护城河问题的回答[34]反映了业界对于 LLM 领域强依赖于 NVIDIA 的问题的急切。
Q: If you look at what Wall Street thinks Nvidia’s mode is, it’s CUDA... You have ROCm, which is a little different. Do you think that that’s a moat that you can overcome with better products or with a more open approach? Lisa Su: I’m not a believer in moats when the market is moving as fast as it is... When you look at going forward, actually what you find is everyone’s looking for the ability to build hardware-agnostic software because people want choice. Frankly, people want choice... Things like PyTorch, for example, which tends to be that hardware-agnostic capability.
Q:PyTorch is a big deal, right? This is the language that all these models are actually coded in. I talk to a bunch of cloud CEOs. They don’t love their dependency on Nvidia as much as anybody doesn’t love being dependent on any one vendor. Is this a place where you can go work with those cloud providers and say, “We’re going to optimize our chips for PyTorch and not CUDA,” and developers can just run on PyTorch and pick whichever is best optimized? Lisa Su: That’s exactly it. PyTorch really is trying to be that sort of hardware-agnostic layer — one of the major milestones that we’ve come up with is on PyTorch 2.0. But our goal is “may the best chip win.” And the way you do that is to make the software much more seamless. And it’s PyTorch, but it’s also Jax. It’s also some of the tools that OpenAI is bringing in with Triton.
CUDA 确实非常优秀,但它是不是优秀到你要为它支付过多的成本,包括实际的金钱成本和各种隐形成本。基于 PyTorch 或者 Jax 这些新一代的中间层,新的解决方案正在形成。「AMD AI Software Solved – MI300X Pricing, Performance, PyTorch 2.0, FlashAttention, OpenAI Triton」 这篇文章[35] 展示了基于 PyTorch 2.0 和 OpenAI Triton, MosaicML 能够基本不做代码修改,在 AMD 硬件平台上实现与 NVIDIA A100 基本一致的性能。
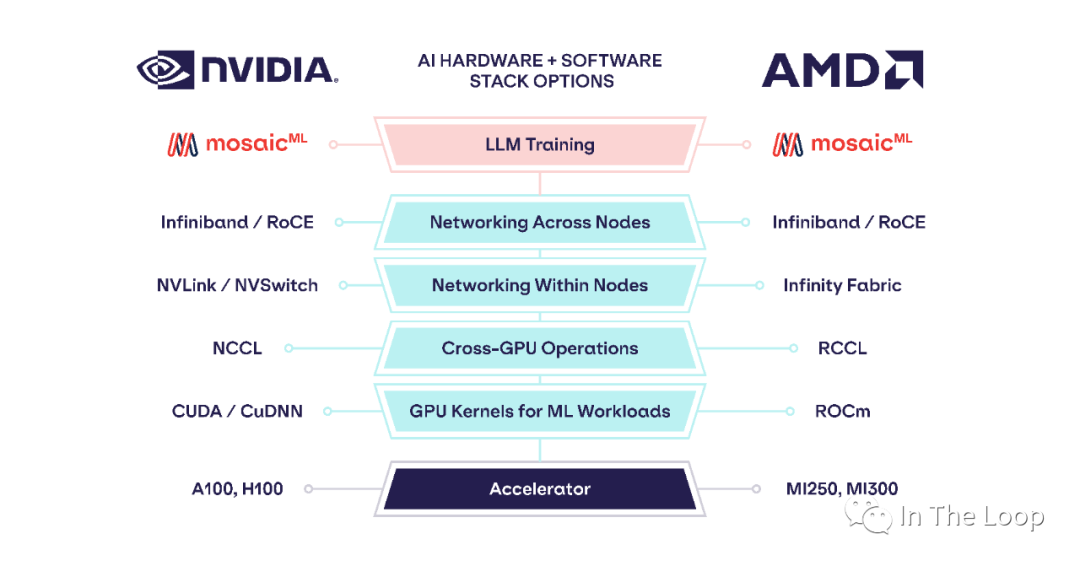
We profiled training throughput of MPT models from 1B to 13B parameters and found that the per-GPU-throughput ofMI250 was within 80% of the A100-40GB and within 73% of the A100-80GB. Abhi Venigalla, MosaicML[36]
今年 7 月,Intel 在国内发布 Habana Gaudi 2 AI 芯片,期望在国内禁售英伟达 H100/A100 的当下,分到这一波生成式人工智能浪潮的蛋糕。Habana Gaudi 2,正是 Intel 在 2019 年收购 Habana Labs 之后的作品,也是 Intel 在收购 Nervana 浪费 3 年时间后的再次尝试。 除了 NVIDIA,AMD,Intel 这三个在 CPU/GPU/DPU 等各个领域打成一片的老冤家,还有 GraphCore、Cerebras 这样的 AI Chip 创业公司仍在继续。
与此同时,云服务巨头家大业大,自然不甘心受制于人,纷纷投入自研 AI 芯片。前不久,AWS 投资 40 亿美元到 Anthropic[37],目标之一就是让 AWS 自研 Trainium 和 Inferentia 得到大量应用[38]。8 月底,Google Cloud 的 H100 实例 A3 终于姗姗来迟,但是也许这并不是他们的重点,重点是他们发布了 TPUv5e[39]。作为 AI 芯片的先行者,Google 的 TPU 相对于 AWS 的 Trainium/Inferentia 要成熟的多,TPU 也是应对 NVIDIA H100 的有力竞争对手[40]。 英伟达帝国大厦已经建立,只是头上还有几朵乌云。在美国禁售 A100/H100 的当下,如华为昇腾 910 这样的国产 AI芯片也开始慢慢得到应用。30 年前,面对个人电脑这个新计算平台的范式转移,诞生了像 Intel,Microsoft 和 NVIDIA 这样的巨头。30 年后的今天,新一波生成式人工智能或将迎来新的计算范式转移,这一次面对巨龙,又将会是怎样的故事呢。
-
gpu
+关注
关注
28文章
4830浏览量
129774 -
AI芯片
+关注
关注
17文章
1926浏览量
35403 -
算力
+关注
关注
1文章
1043浏览量
15098
原文标题:疯狂的 H100:现代 GPU 体系结构浅析,从算力焦虑开始聊起
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英伟达a100和h100哪个强?英伟达A100和H100的区别
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
浅析PCI体系结构
LTE体系结构
NVIDIA发布新一代产品—NVIDIA H100

NVIDIA发布最新Hopper架构的H100系列GPU和Grace CPU超级芯片
蓝海大脑服务器全力支持NVIDIA H100 GPU
利用NVIDIA HGX H100加速计算数据中心平台应用
关于NVIDIA H100 GPU的问题解答

传英伟达新AI芯片H20综合算力比H100降80%
英伟达H100,没那么缺货了 !RTX 4090 ,大涨
英伟达A100和H100比较






 工商网监
工商网监
评论