 知识图谱与大模型结合方法概述
知识图谱与大模型结合方法概述
本文作者 | 黄巍
《Unifying Large Language Models and Knowledge Graphs: A Roadmap》总结了大语言模型和知识图谱融合的三种路线:1)KG增强的LLM,可在LLMs的预训练和推理阶段引入KGs;2)LLM增强KG,LLM可用于KG构建、KG embedding、KG补全、基于KG的文本生成、KBQA(基于图谱的问答)等多种场景;3)LLM+KG协同使用,主要用于知识表示和推理两个方面。该文综述了以上三个路线的代表性研究,探讨了未来可能的研究方向。
知识图谱(KG)和大语言模型(LLM)都是知识的表示形式。KG是符号化的知识库,具备一定推理能力,且结果可解释性较好。但存在构建成本高、泛化能力不足、更新难等不足。LLM是参数化的概率知识库,具备较强语义理解和泛化能力,但它是黑盒模型,可能编造子虚乌有的内容,结果的可解释性较差。可见,将LLM和KG协同使用,同时利用它们的优势,是一种互补的做法。
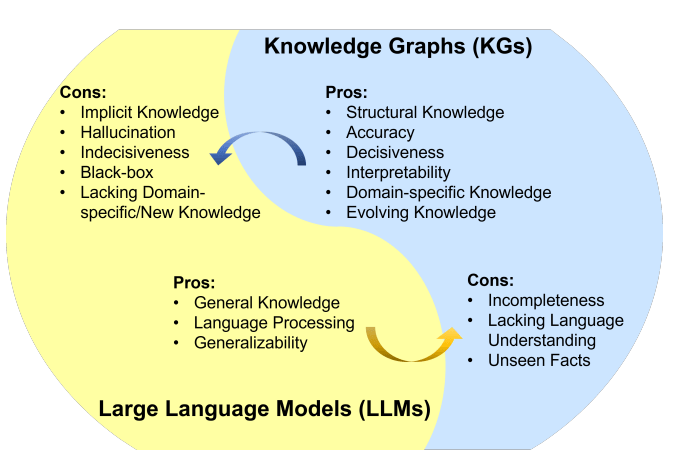
LLM和KG的融合路线,可分为以下类型:
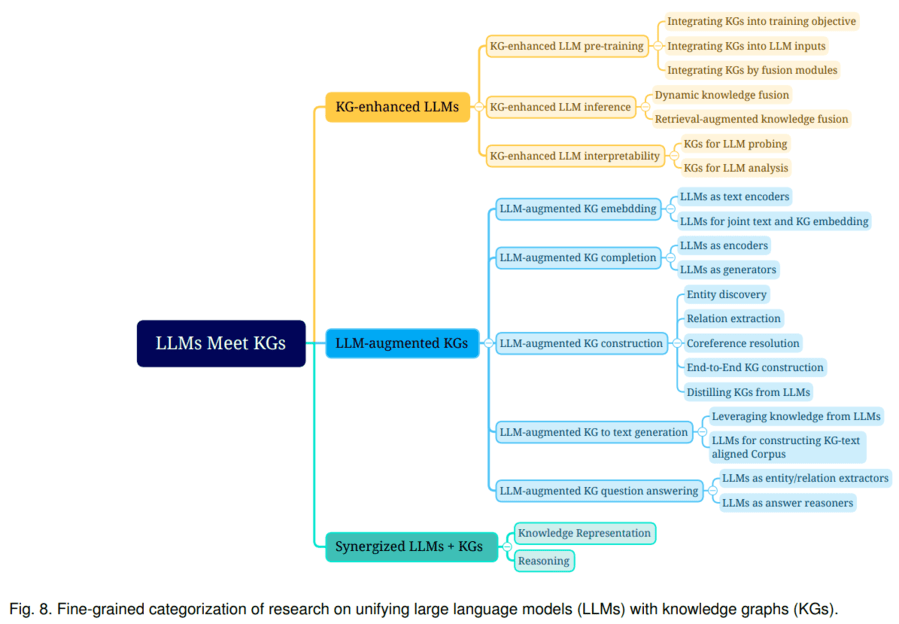
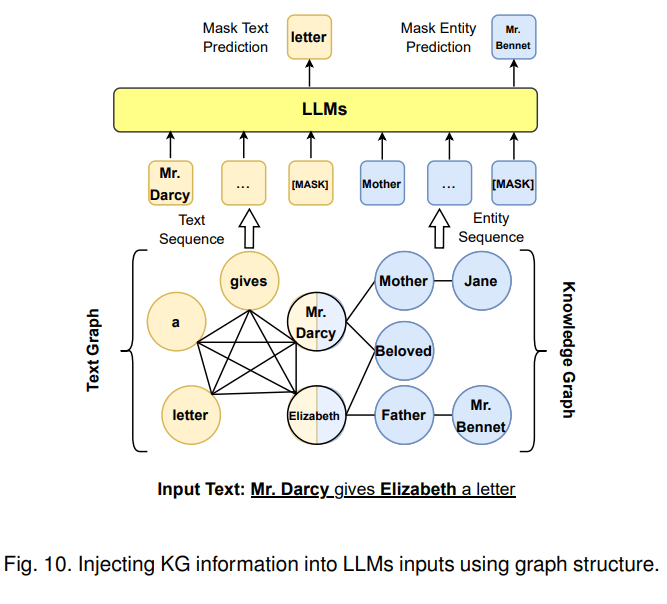
第一种融合路线是KG增强LLM,可在LLM预训练、推理阶段引入KG。以KG增强LLM预训练为例,一个代表工作是百度的ERNIE 3.0将图谱三元组转换成一段token文本作为输入,并遮盖其实体或者关系来进行预训练,使模型在预训练阶段直接学习KG蕴含的知识。
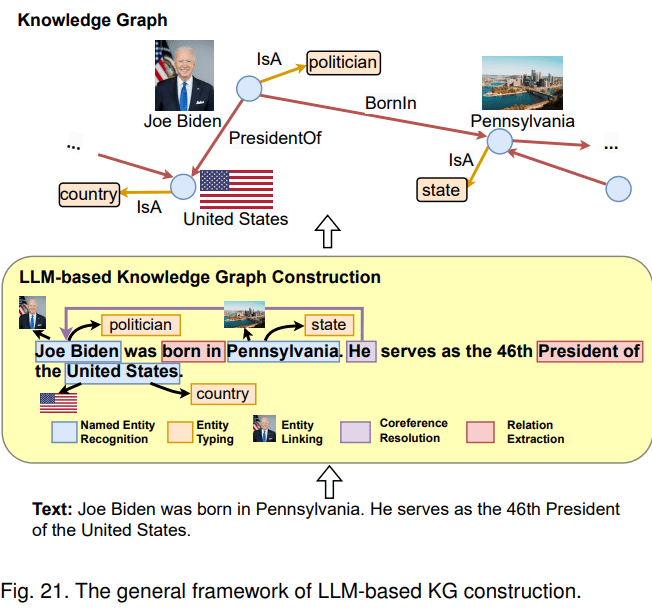
第二种融合路线是LLM增强KG。LLM可用于KG构建、KG embedding、KG补全、基于KG的文本生成、KBQA(基于图谱的问答)等多种场景。以KG构建为例,这是一项成本很高的工作,一般包含1) entity discovery 实体挖掘 2) coreference resolution 指代消解 3) relation extraction 关系抽取任务。LLM本身蕴含知识,且具备较强的语义理解能力,因此,可利用LLM从原始数据中抽取实体、关系,进而构建知识图谱。
第三种融合路线是KG+LLM协同使用,主要用于知识表示和推理两个方面。以知识表示为例,文本语料库和知识图谱都蕴含了大量的知识,文本中的知识通常是非结构化的,图谱里的知识则是结构化的,针对一些下游任务,需要将其对齐进行统一的表示。比如,KEPLER是一个统一的模型来进行统一表示,它将文本通过LLM转成embedding表示,然后把KG embedding的优化目标和语言模型的优化目标结合起来,一起作为KEPLER模型的优化目标,最后得到一个能联合表示文本语料和图谱的模型。示意图如下:
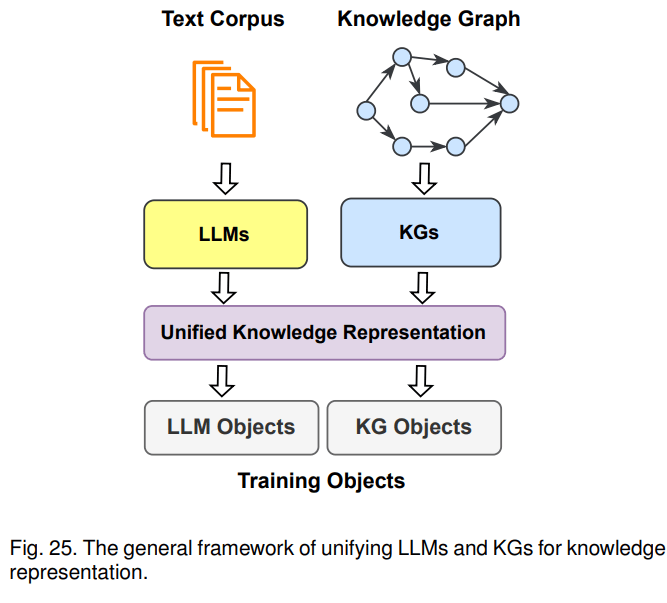

小结
上述方法都在尝试打破LLM和KG两类不同知识表示的边界,促使LLM这种概率模型能利用KG静态的、符号化的知识;促使KG能利用LLM参数化的概率知识。从现有落地案例来看,大模型对知识的抽象程度高,泛化能力强,用户开箱即用,体验更好。且如果采用大模型+搜索的方案,用户更新知识的成本也较低,往知识库加文档即可。在实际业务场景落地时,如果条件允许,优先考虑使用大模型。当前chatGPT火爆,也印证了其可用性更好。如遇到以下场景时,可以考虑将LLM和KG结合使用:
•对知识可信度和可解释性要求高的场景,比如医疗、法律等,可以考虑再建设知识图谱来降低大模型回答错误知识的概率,提高回答的可信度和可解释性。
•已经有一个蕴含丰富知识的图谱,再做大模型建设时。可以参考KG增强LLM的方法,将其知识融合到LLM中。
•涉及基于图谱的多条推理能力的场景。
•涉及基于图谱可视化展示的场景,比如企查查、天眼查等。
参考文献:
1.Unifying Large Language Models and Knowledge Graphs: A Roadmaphttps://arxiv.org/abs/2306.08302
原文标题:知识图谱与大模型结合方法概述
文章出处:【微信公众号:华为DevCloud】欢迎添加关注!文章转载请注明出处。
-
华为
+关注
关注
216文章
34634浏览量
253673
原文标题:知识图谱与大模型结合方法概述
文章出处:【微信号:华为DevCloud,微信公众号:华为DevCloud】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
渊亭KGAG升级引入“高级策略推理”
微软发布《GraphRAG实践应用白皮书》助力开发者
利智方:驱动企业知识管理与AI创新加速的平台
传音旗下人工智能项目荣获2024年“上海产学研合作优秀项目奖”一等奖

三星自主研发知识图谱技术,强化Galaxy AI用户体验与数据安全
【《大语言模型应用指南》阅读体验】+ 基础篇
【《大语言模型应用指南》阅读体验】+ 俯瞰全书
三星电子将收购英国知识图谱技术初创企业
知识图谱与大模型之间的关系
Al大模型机器人
大模型应用之路:从提示词到通用人工智能(AGI)
澳鹏入选亿欧大模型基础层图谱,以优质数据赋能AGI智能涌现






 工商网监
工商网监
评论