 如何利用CLIP 的2D 图像-文本预习知识进行3D场景理解
如何利用CLIP 的2D 图像-文本预习知识进行3D场景理解
前言:
3D场景理解是自动驾驶、机器人导航等领域的基础。当前基于深度学习的方法在3D点云数据上表现出了十分出色的性能。然而,一些缺点阻碍了它们在现实世界中的应用。第一个原因是他们严重依赖大量的带注释点云,尤其是当高质量的3D注释获取成本高昂时。此外,他们通常不能识别训练数据中从未见过的新物体。因此,可能需要额外的注释工作来训练模型识别这些新的对象,这既繁琐又费时。
OpenAI的CLIP为缓解2D视觉中的上述问题提供了一个新的视角。该方法利用网站上大规模免费提供的图文对进行训练,建立视觉语言关联,以实现有前景的开放词汇识别。基于此,MaskCLIP做了基于CLIP的2D图像语义分割的扩展工作。在对CLIP预训练网络进行最小修改的情况下,MaskCLIP可以直接用于新对象的语义分割,而无需额外的训练工作。PointCLIP将CLIP的样本分类问题从2D图像推广到3D点云。它将点云框架透视投影到2D深度图的不同视图中,以弥合图像和点云之间的模态间隙。上述研究表明了CLIP在2D分割和3D分类性能方面的潜力。然而,CLIP是否可以及如何有利于3D场景理解仍有待探索。
本文探讨了如何利用 CLIP 的2D 图像-文本预习知识进行3D 场景理解。作者提出了一个新的语义驱动的跨模态对比学习框架,它充分利用 CLIP 的语义和视觉信息来规范3D 网络。
作者主要的贡献如下:
1、作者是第一个将CLIP知识提炼到3D网络中用于3D场景理解的。
2、作者提出了一种新的语义驱动的跨模态对比学习框架,该框架通过时空和语义一致性正则化来预训练3D网络。
3、作者提出了提出了一种新的语义引导的时空一致性正则化,该正则化强制时间相干点云特征与其对应的图像特征之间的一致性。
4、该方法首次在无注释的三维场景分割中取得了良好的效果。当使用标记数据进行微调时,本文的方法显著优于最先进的自监督方法。这里也推荐「3D视觉工坊」新课程《彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析》
相关工作:
三维零样本学习:
零样本学习(ZSL)的目标是识别训练集中看不见的对象。但是目前的方法主要都是基于2D识别的任务,对三维领域执行ZSL的研究特别有限。本文进一步研究了 CLIP 中丰富的语义和视觉知识对三维语义分割任务的影响。
自监督表征学习:
自我监督学习的目的是获得有利于下游任务的良好表现。主流的方法是使用对比学习来与训练网络。受CLIP成功的启发,利用CLIP的预训练模型来完成下游任务引起了广泛的关注。本文利用图像文本预先训练的CLIP知识来帮助理解3D场景。
跨模式知识蒸馏:
近年来,越来越多的研究集中于将二维图像中的知识转化为三维点云进行自监督表示学习。本文首先尝试利用 CLIP 的知识对一个三维网络进行预训练。
具体方法:
本文研究了用于3D场景理解的CLIP的跨模态知识转移,称为CLIP2Scene。本文的工作是利用CLIP知识进行3D场景理解的先驱。本文的方法由三个主要组成部分组成:语义一致性正则化、语义引导的时空一致性规则化和可切换的自我训练策略。
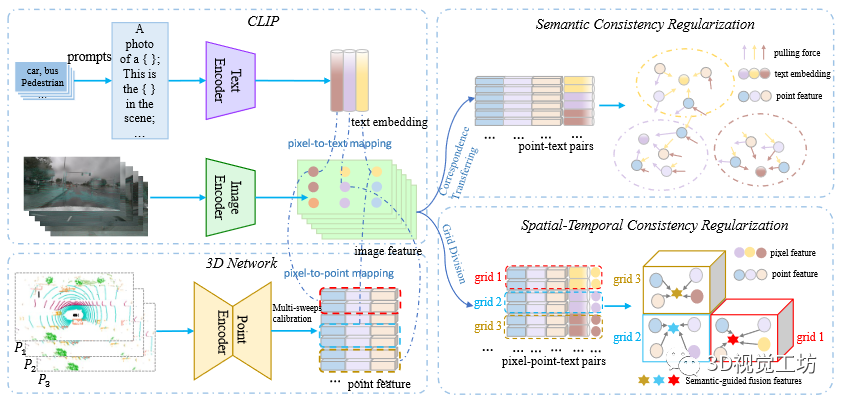
图1 语义驱动的跨模态对比学习图解。首先,本文分别通过文本编码器、图像编码器和点编码器获得文本嵌入、图像像素特征和点特征。本文利用CLIP知识来构建用于对比学习的正样本和负样本。这样就得到了点-文本对和短时间内的所有像素点文本对。因此,和分别用于语义一致性正则化和时空一致性规则化。最后,通过将点特征拉到其相应的文本嵌入来执行语义一致性正则化,并通过将时间上相干的点特征模仿到其对应的像素特征来执行时空一致性正则化。
CLIP2Scene
语义一致性正则化
由于CLIP是在2D图像和文本上预先训练的,作者首先关注的是2D图像和3D点云之间的对应关系。具体的,使用既可以获得图像和点云的因此,可以相应地获得密集的像素-点对应,其中和表示第i个成对的图像特征和点特征,它们分别由CLIP的图像编码器和3D网络提取。M是对数。

图2 图像像素到文本映射的图示。密集像素-文本对应关系是通过MaskCLIP的方法提出的。
本文提出了一种利用CLIP的语义信息的语义一致性正则化。具体而言,本文通过遵循off-the-shelf方法MaskCLIP(图2)生成密集像素文本对,其中是从CLIP的文本编码器生成的文本嵌入。请注意,像素文本映射可从CLIP免费获得,无需任何额外的训练。然后,我们将像素文本对转换为点文本对,并利用文本语义来选择正点样本和负点样本进行对比学习。目标函数如下:其中,代表由第个类名生成,并且是类别的数量。表示标量积运算,是温度项()。由于文本是由放置在预定义的模板中的类名组成,因此文本嵌入表示相应的类的语义信息。因此那些具有相同语义的点将被限制在相同的文本嵌入附近,而那些具有不同语义的点将被推开。为此,语义一致性正则化会减少对比学习中的冲突。
语义引导的时空一致性正则化
除了语义一致性正则化之外,本文还考虑图像像素特征如何帮助正则化3D网络。自然替代直接引入点特征及其在嵌入空间中的对应像素。然而,图像像素的噪声语义和不完美的像素点映射阻碍了下游任务的性能。为此,提出了一种新的语义引导的时空一致性正则化方法,通过对局部空间和时间内的点施加软约束来缓解这一问题。
具体地,给定图像和时间相干LiDAR点云,其中,是秒内扫描的次数。值得注意的是图像与像素点对的点云第一帧进行匹配。本文通过校准矩阵将点云的其余部分配准到第一帧,并将它们映射到图像上(图3)。
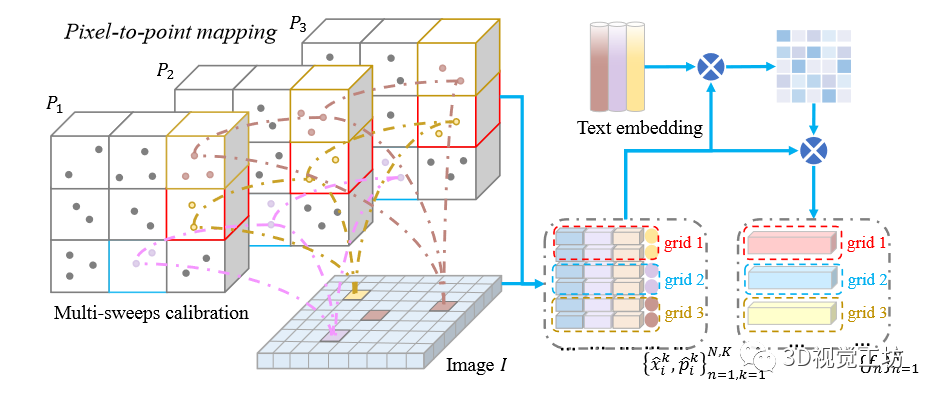
图3 图像像素到点映射(左)和语义引导的融合特征生成(右)示意图。本文建立了在秒内图像和时间相干激光雷达点云之间的网格对应关系,并且生成语义引到的融合特征。和用于执行时空一致性正则化。
因此,我们在短时间内获得所有像素点文本对。接下来,作者将整个缝合的点云划分为规则网格,其中时间相干点位于同一网格中。本文通过以下目标函数在各个网格内施加时空一致性约束:
其中,代表像素-点对位于第个网格。是一种语义引导的跨模态融合特征,由以下公式表示:
其中和是注意力权重是由以下来计算的:
其中代表温度项。实际上,局部网格内的那些像素和点特征被限制在动态中心附近。因此,这种软约束减轻了噪声预测和校准误差问题。同时,它对时间相干点特征进行了时空正则化处理。
实验
数据集的选择:两个室外数据集 SemanticKITTI 和 nuScenes一个室内数据集 ScanNet
无注释语义分割

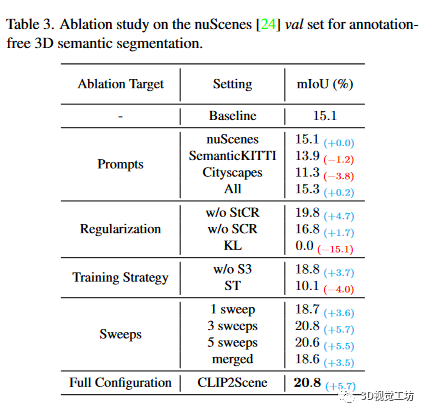
表2 是针对不同数据集的无注释的3D语义分割的性能表3 是无注释三维语义分割的nuScenes数据集消融研究。这里也推荐「3D视觉工坊」新课程《彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析》
高效注释的语义分割
如表1所示,当对1%和100%nuScenes数据集进行微调时,该方法显著优于最先进的方法,分别提高了8.1%和1.1%。与随机初始化相比,改进幅度分别为14.1%和2.4%,表明了本文的语义驱动跨模态对比学习框架的有效性。定性结果如图4所示。此外,本文还验证了该方法的跨域泛化能力。
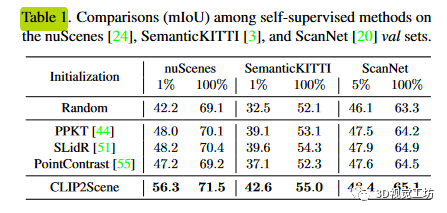
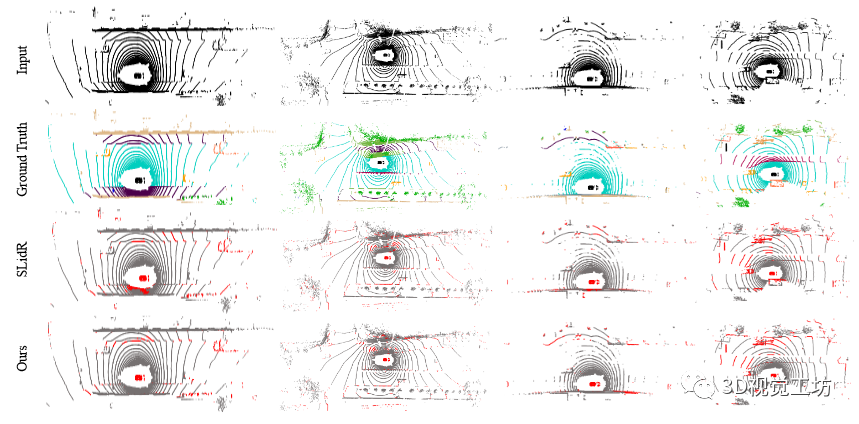
图4 对1%nuScenes数据集进行微调的定性结果。从第一行到最后一行分别是输入激光雷达扫描、真值、SLidR预测和我们的预测。请注意,我们通过误差图显示结果,其中红点表示错误的预测。显然,本文的方法取得了不错的性能。
结论
在这项名为CLIP2Scene的工作中,作者探讨了CLIP知识如何有助于3D场景理解。为了有效地将CLIP的图像和文本特征转移到3D网络中,作者提出了一种新的语义驱动的跨模态对比学习框架,包括语义正则化和时空正则化。作者的预训练3D网络首次以良好的性能实现了无注释的3D语义分割。此外,当使用标记数据进行微调时,我们的方法显著优于最先进的自监督方法。
-
3D
+关注
关注
9文章
2875浏览量
107486 -
模型
+关注
关注
1文章
3226浏览量
48809 -
Clip
+关注
关注
0文章
31浏览量
6664 -
深度学习
+关注
关注
73文章
5500浏览量
121113
原文标题:结论
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
UV光固化技术在3D打印中的应用
3D封装热设计:挑战与机遇并存

苏州吴中区多色PCB板元器件3D视觉检测技术

银牛微电子引领3D空间计算芯片前沿技术
NVIDIA Instant NeRF将多组静态图像变为3D数字场景
通过2D/3D异质结构精确控制铁电材料弛豫时间

Adobe Substance 3D整合AI功能:基于文本生成纹理、背景
有了2D NAND,为什么要升级到3D呢?

Nullmax提出多相机3D目标检测新方法QAF2D
Adobe提出DMV3D:3D生成只需30秒!让文本、图像都动起来的新方法!

高分工作!Uni3D:3D基础大模型,刷新多个SOTA!

如何搞定自动驾驶3D目标检测!

一种用于2D/3D图像处理算法的指令集架构以及对应的算法部署方法





 工商网监
工商网监
评论