 Mara-pipelines:轻量级的数据转换框架
Mara-pipelines:轻量级的数据转换框架
Mara-pipelines 是一个轻量级的数据转换框架,具有透明和低复杂性的特点。其他特点如下:
- 基于非常简单的Python代码就能完成流水线开发。
- 使用 PostgreSQL 作为数据处理引擎。
- 有Web界面可视化分析流水线执行过程。
- 基于 Python 的 multiprocessing 单机流水线执行。不需要分布式任务队列。轻松调试和输出日志。
- 基于成本的优先队列:首先运行具有较高成本(基于记录的运行时间)的节点。
此外,在Mara-pipelines的Web界面中,你不仅可以查看和管理流水线及其任务节点,你还可以直接触发这些流水线和节点,非常好用:
1.安装
由于使用了大量的依赖,Mara-pipelines 并不适用于 Windows,如果你需要在 Windows 上使用 Mara-pipelines,请使用 Docker 或者 Windows 下的 linux 子系统。
使用pip安装Mara-pipelines:
pip install mara-pipelines
或者:
pip install git+https://github.com/mara/mara-pipelines.git
2.使用示例
这是一个基础的流水线演示,由三个相互依赖的节点组成,包括 任务1(ping_localhost), 子流水线(sub_pipeline), 任务2(sleep):
# 注意,这个示例中使用了部分国外的网站,如果无法访问,请变更为国内网站。
from mara_pipelines.commands.bash import RunBash
from mara_pipelines.pipelines import Pipeline, Task
from mara_pipelines.ui.cli import run_pipeline, run_interactively
pipeline = Pipeline(
id='demo',
description='A small pipeline that demonstrates the interplay between pipelines, tasks and commands')
pipeline.add(Task(id='ping_localhost', description='Pings localhost',
commands=[RunBash('ping -c 3 localhost')]))
sub_pipeline = Pipeline(id='sub_pipeline', description='Pings a number of hosts')
for host in ['google', 'amazon', 'facebook']:
sub_pipeline.add(Task(id=f'ping_{host}', description=f'Pings {host}',
commands=[RunBash(f'ping -c 3 {host}.com')]))
sub_pipeline.add_dependency('ping_amazon', 'ping_facebook')
sub_pipeline.add(Task(id='ping_foo', description='Pings foo',
commands=[RunBash('ping foo')]), ['ping_amazon'])
pipeline.add(sub_pipeline, ['ping_localhost'])
pipeline.add(Task(id='sleep', description='Sleeps for 2 seconds',
commands=[RunBash('sleep 2')]), ['sub_pipeline'])
可以看到,Task包含了多个commands,这些 commands会用于真正地执行动作。
而 pipeline.add 的参数中,第一个参数是其节点,第二个参数是此节点的上游。如:
pipeline.add(sub_pipeline, ['ping_localhost'])
则表明必须执行完 ping_localhost 才会执行 sub_pipeline.
为了运行这个流水线,需要配置一个 PostgreSQL 数据库来存储运行时信息、运行输出和增量处理状态:
import mara_db.auto_migration
import mara_db.config
import mara_db.dbs
mara_db.config.databases
= lambda: {'mara': mara_db.dbs.PostgreSQLDB(host='localhost', user='root', database='example_etl_mara')}
mara_db.auto_migration.auto_discover_models_and_migrate()
如果 PostgresSQL 正在运行并且账号密码正确,输出如下所示(创建了一个包含多个表的数据库):
Created database "postgresql+psycopg2://root@localhost/example_etl_mara"
CREATE TABLE data_integration_file_dependency (
node_path TEXT[] NOT NULL,
dependency_type VARCHAR NOT NULL,
hash VARCHAR,
timestamp TIMESTAMP WITHOUT TIME ZONE,
PRIMARY KEY (node_path, dependency_type)
);
.. more tables
为了运行这个流水线,你需要:
from mara_pipelines.ui.cli import run_pipeline
run_pipeline(pipeline)

这将运行单个流水线节点及其 ( **sub_pipeline ** ) 所依赖的所有节点:
run_pipeline(sub_pipeline, nodes=[sub_pipeline.nodes['ping_amazon']], with_upstreams=True)
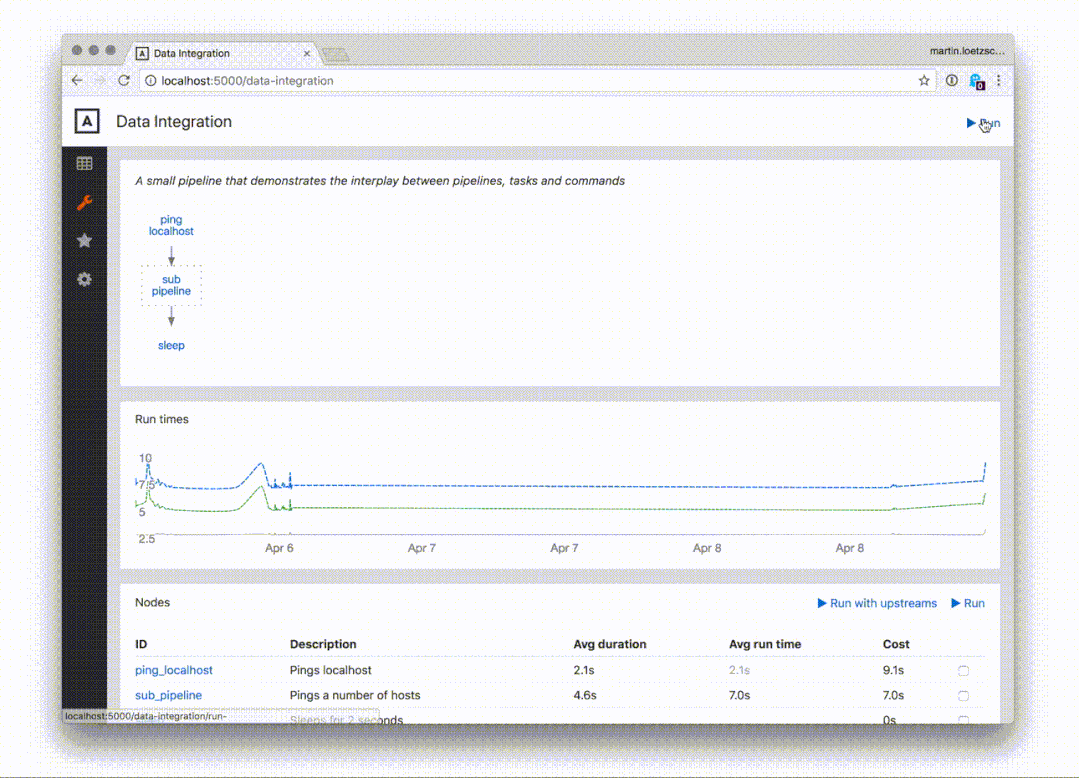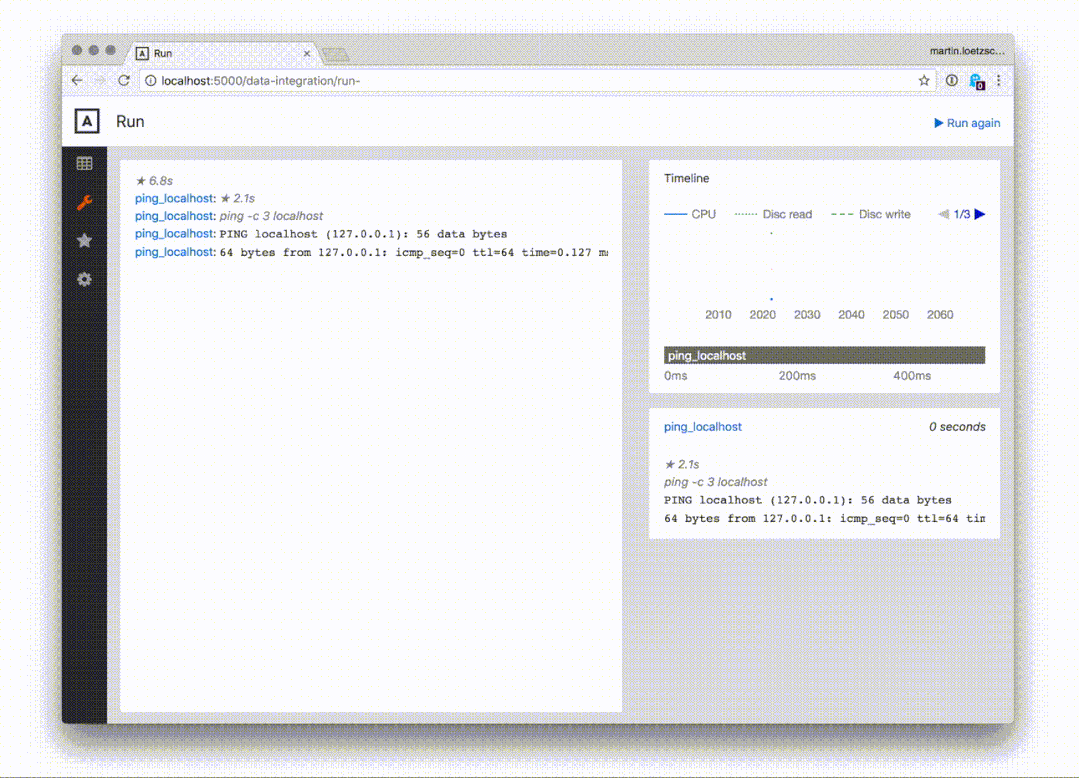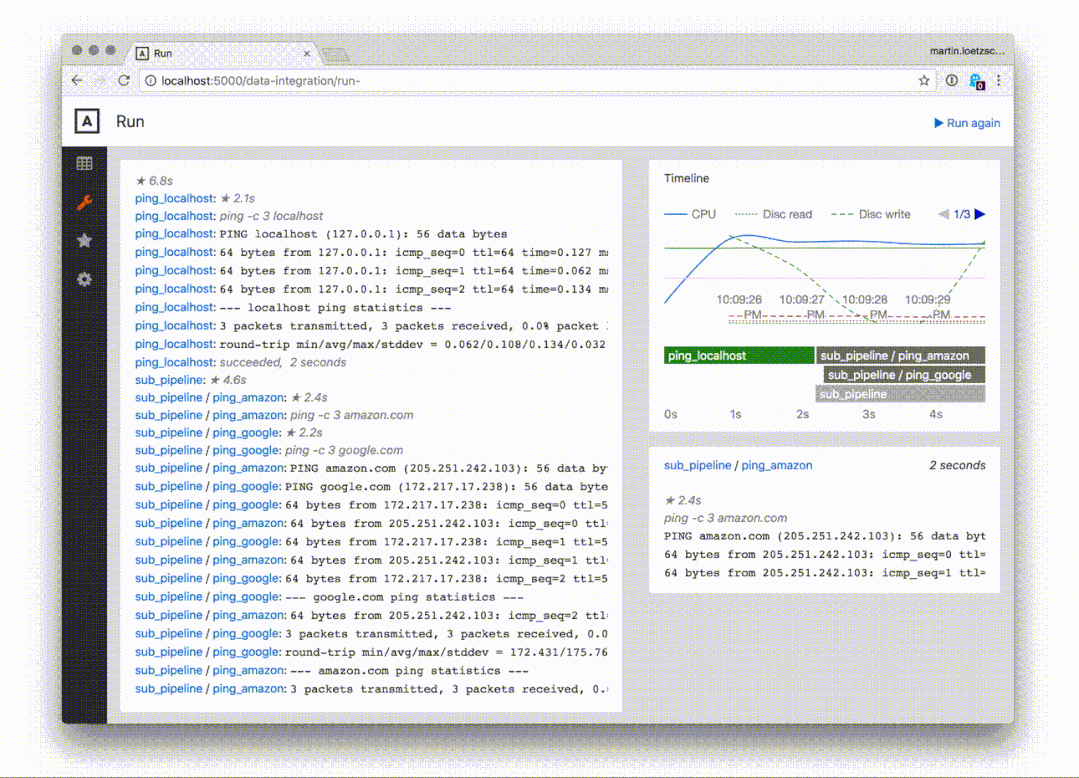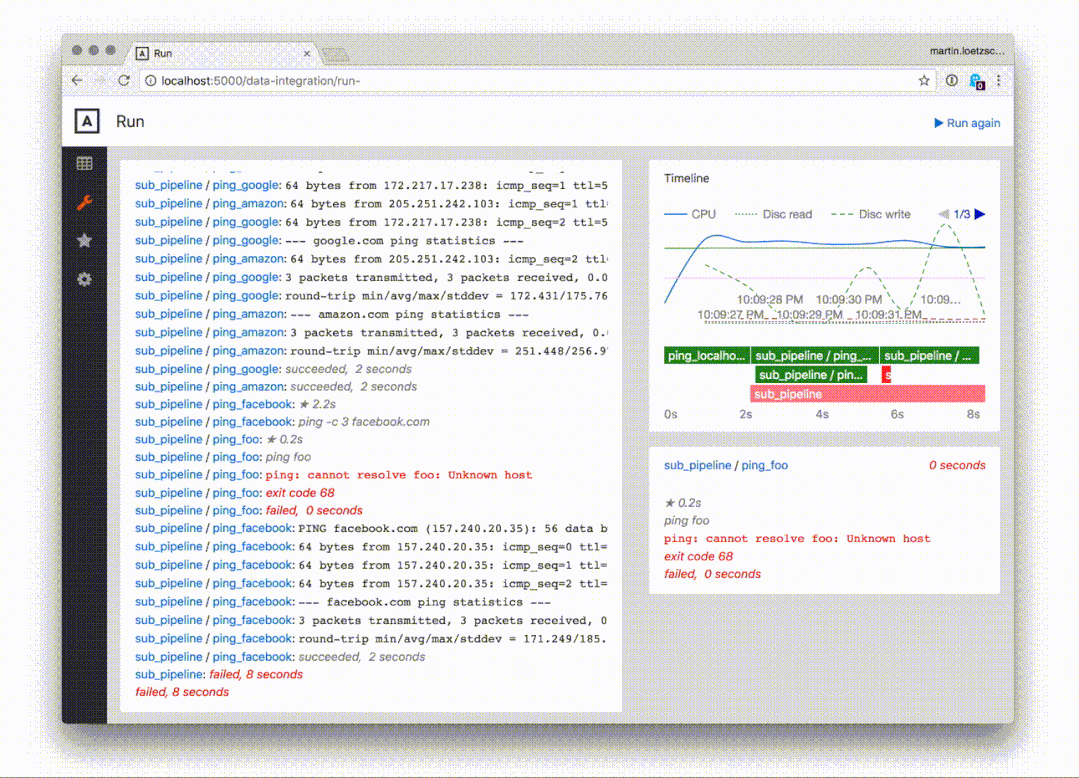
3.Web 界面
我认为 mara-pipelines 最有用的是他们提供了基于Flask管控流水线的Web界面。
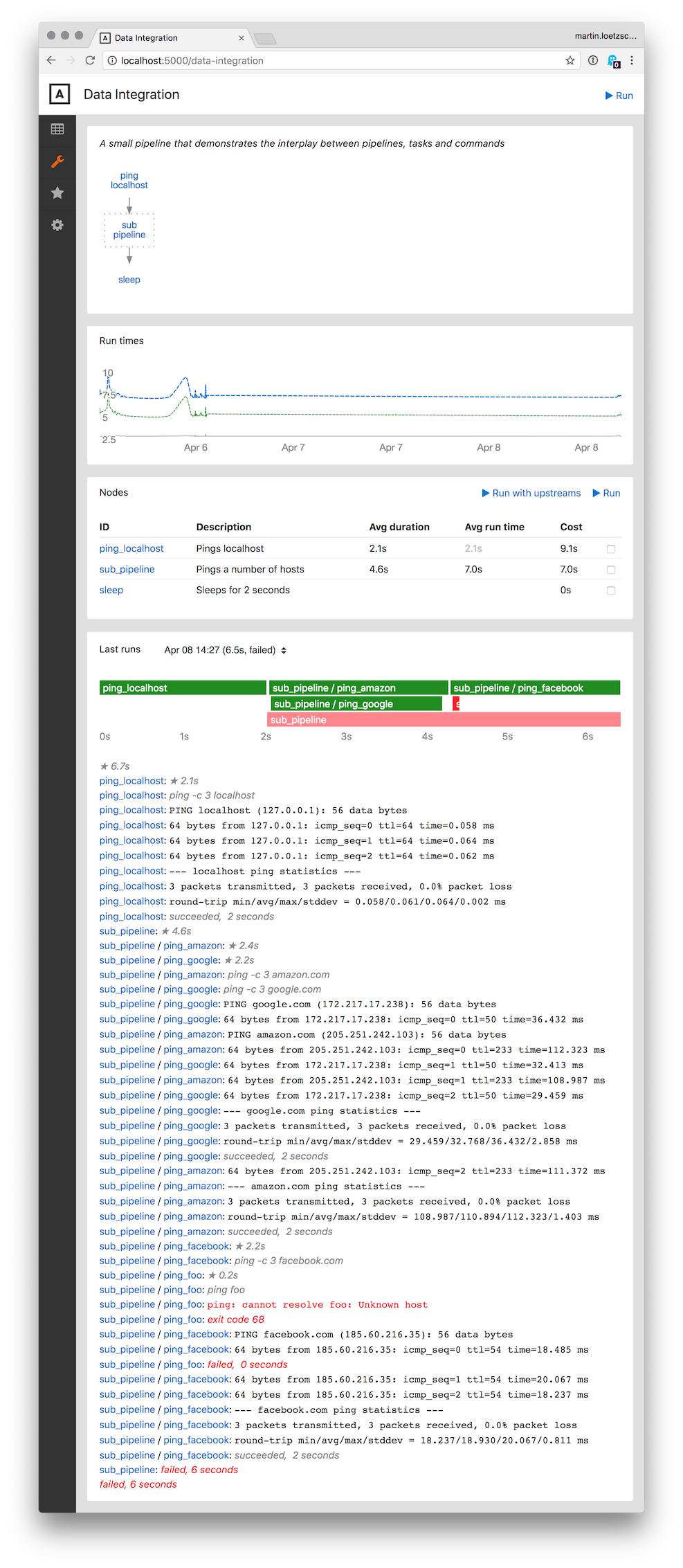
对于每条流水线,他们都有一个页面显示:
- 所有子节点的图以及它们之间的依赖关系
- 流水线的总体运行时间图表以及过去 30 天内最昂贵的节点(可配置)
- 所有流水线节点及其平均运行时间和由此产生的排队优先级的表
- 流水线最后一次运行的输出和时间线
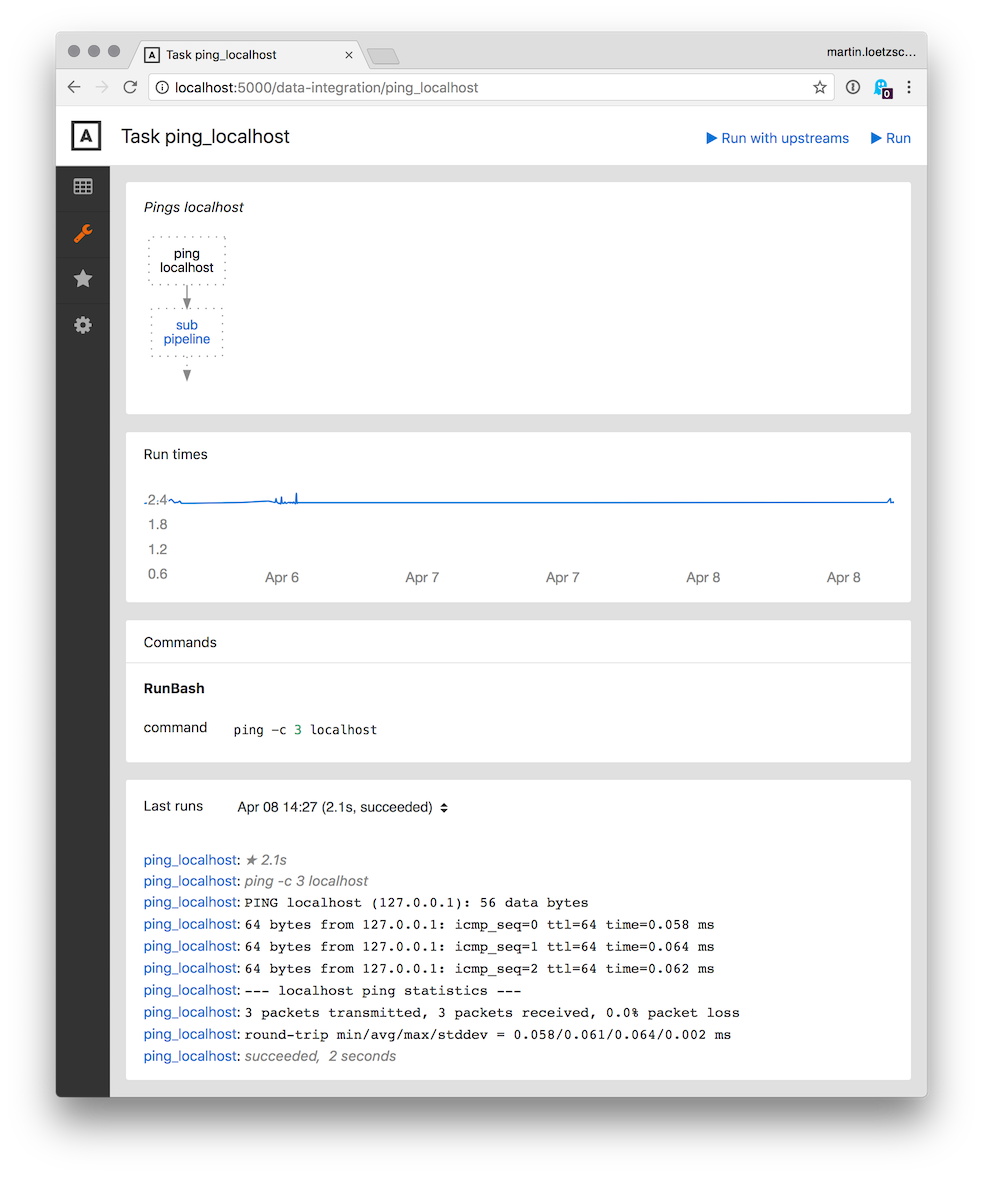
对于每个任务,都有一个页面显示
- 流水线中任务的上游和下游
- 最近 30 天内任务的运行时间
- 任务的所有命令
- 任务最后运行的输出
此外,流水线和任务可以直接从网页端调用运行,这是非常棒的特点:
-
数据转换
+关注
关注
0文章
86浏览量
17990 -
代码
+关注
关注
30文章
4747浏览量
68348 -
python
+关注
关注
56文章
4782浏览量
84452
发布评论请先 登录
相关推荐
一个面向嵌入式系统的轻量级框架
轻量级的ui框架如何去制作
Dllite_micro (轻量级的 AI 推理框架)
一种超轻量级的flashKV数据存储方案分享
原创分享:自制轻量级单片机UI框架

基于非常简单的Python代码就能完成流水线开发
测评分享 | 如何在先楫HPM6750上运行轻量级AI推理框架TinyMaix

轻量级数据库有哪些
一个轻量级的权限认证框架:Sa-Token
超级方便的轻量级Python流水线工具

基于Python 轻量级ORM框架





 工商网监
工商网监
评论